前言
由于工厂、车厂的任务需求场景非常明确,加之自今年年初以来,我司在机器人这个方向的持续大力度投入(包括南京、长沙两地机器人开发团队的先后组建),使得近期我司七月接到了不少来自车厂/工厂的订单,比如其中的三个例子:柔性上料、物料分拣、RL仿真平台搭建
也让我们越来越坚定在机器人方向发力具身智能 和工业协作机器人,且细分为如下三大场景
- 初级,面向教学场景,即高校实验室的具身「教学机器人」,及给青年少年小孩的「教育机器人」
- 中级,面向科研场景,帮一系列公司或高校复现世界最顶级的开源机器人,使其最终落地于小工厂或家务,硬件成本十来万到几十万
- 高级,面向工业场景,即协作机器人——南京那边几个月前便已在弄
而既然在机器人这个行业,故我们对该领域的各种前沿进展始终保持极高关注(毕竟在这种高科技领域,那关注世界级前沿 是必不可少的),从而
- 注意到了李飞飞团队提出的这个ReKep(全称为Relational Keypoint Constraints)
其对应的论文为《ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation》,其作者团队为:Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, Li Fei-Fei
- 当然,你在阅读ReKep这篇论文时,欢迎使用我司七月开发的基于大模型的翻译系统(目前已上线七月官网,左边英文 右边中文,如此中英文对照下的阅读效率奇快无比)
如我司机器人技术合伙人姚博士所说,“ReKep的方法基于大模型,增加运动限制,而我们之前做的更多基于端到端的专用数据模型”
至于什么叫做所谓的空间智能呢?
- 比如对于现有的大模型,你让它倒杯茶,它能很快给你推理出来第一步干什么、第二步干什么、第三步干什么
- 但这毕竟是理论,等到真实世界中实际泡茶时,会遇到各种问题,比如要握好茶壶、移动茶壶的时候不要洒出、倒茶的时候要把茶嘴与杯子对齐
这些都需要对整个物理空间有感知,且每一步的运动都有一定的约束,这就叫空间智能 - 那没有空间智能,机器人能不能完成倒茶这类任务呢?
能,比如通过额外的训练 比如基于人类示教,然后让机器人模仿人类行为——即所谓的模仿学习,便可以
那如果不进行额外的训练 只单纯靠大模型推理 + 机器人自身的运动控制能力呢?理论上也可以,但可能不够稳定、不够丝滑、不够精准
我司会在大模型和机器人这两个方向不断深挖,就像深海挖井,为达预期 虽两万里亦往矣,期待与更多大模型开发者、机器人开发者一路前行
第一部分 ReKep的提出背景与其关键架构、实现细节、完整示例
1.1 初步印象:ReKep的提出背景——是什么以及有何不同
1.1.1 ReKep是什么
机器人操作涉及与环境中物体的复杂交互,这些交互通常可以在空间和时间域中表示为约束
考虑下图中的倒茶任务:首先,机器人必须抓住把手;其次,在运输过程中保持杯子直立;最后对齐壶嘴与目标容器,并以正确的角度倾斜杯子进行倒茶
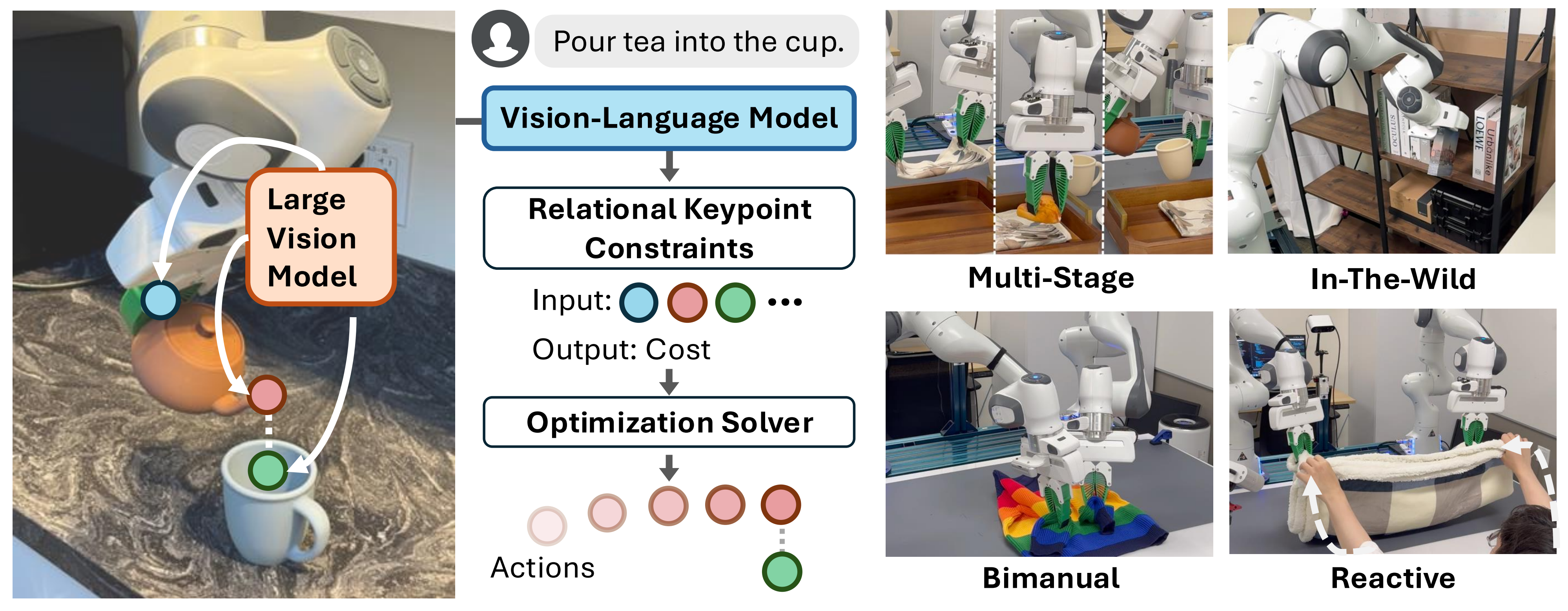
在这里,这些约束不仅编码了中间的子目标(例如,对齐壶嘴),还编码了过渡行为(例如,在运输过程中保持杯子直立),这些约束共同决定了机器人在环境中行动的空间、时间和其他组合要求
然而,有效地为各种现实任务制定这些约束条件面临着重大挑战,之前有不少相关的工作,而李飞飞团队则提出了关系关键点约束——ReKep,具体来说
- ReKep 将约束表示为 Python 函数,这些函数将一组关键点映射到一个数值成本,其中每个关键点都是场景中特定任务和语义上有意义的三维点
ReKep repre-sents constraints as Python functions that map a set of keypoints to a numerical cost, where eachkeypoint is a task-specific and semantically meaningful 3D point in the scene - 每个函数由关键点上的(可能是非线性的)算术运算组成,并编码了它们之间的期望“关系”,这些关键点可能属于环境中的不同实体,例如机器人手臂、物体部件和其他代理
- 虽然每个关键点仅包含其在世界坐标系中的三维笛卡尔坐标,但如果关键点之间的刚性rigidity得到保证,多个关键点可以共同指定线、面和/或三维旋转
他们在顺序操作问题的背景下研究 ReKep,其中每个任务涉及具有时空依赖关系的多个阶段——例如,上述示例中的“抓取”(当然,准确来讲,还包含“移动)、“对齐”、“倒入”
虽然约束通常是根据任务手动定义的[kpam: Keypoint affordances for categorylevel robotic manipulation],但ReKep的特定形式具有独特的优势
- 即可以通过预训练的大型视觉模型LVM [Dinov2: Learning robust visual features without supervision]和视觉-语言模型VLM[比如GPT4]实现自动化「they can be automated by pre-trained large vi-sion models (LVM) [5] and vision-language models (VLM) [6]」
- 从而能够从RGB-D观测和自由形式的语言指令中进行自然环境下的ReKep规范(enabling in-the-wild specificationof ReKep from RGB-D observations and free-form language instructions)
具体来说
- 利用LVM来提出场景中细粒度且语义上有意义的关键点,并使用VLM比如GPT-4o将这些约束写成「基于视觉输入并叠加了关键点的」Python函数
Specifically, we leverage LVM to propose fine-grained and semantically meaningful keypoints in the scene and VLM to write the constraints as Python functions from visual input overlaid with proposed keypoints.
这个过程可以理解为通过视觉引用表达,将细粒度的空间关系——通常是那些难以用自然语言明确表达的关系,在VLM支持的输出模式(代码)中进行落地(使用大型视觉模型和视觉-语言模型自动指定关键点和约束)
This processcan be interpreted as grounding fine-grained spatial relations, often those not easily specified with natural language, in an output modality supported by VLM (code) using visual referral expressions. - 通过生成的约束条件,可以使用现成的求解器,通过重新评估基于跟踪关键点的约束来生成机器人动作
With the generated constraints, off-the-shelf solvers can be used to produce robot actions by re-evaluating the constraints based on tracked keypoints. - 受[7,Sequence-of-constraints mpc: Reactive timing-optimal control of sequential manipulation]的启发,采用分层优化程序——将操作任务表述为具有关系关键点约束的分层优化问题(Inspired by [7], we employ a hierarchical optimization procedure)
比如

1.1.2 ReKep与先前关于操作视觉提示的工作的比较
- 任务自由度
ReKep专注于需要6自由度(单臂)或12自由度(双臂)运动的挑战性任务
然而,这对于现有的VLMs来说并不简单,因为它们在2D图像上操作——正如MOKA [97]所引用的,“当前的VLMs无法可靠地预测6自由度的运动”,以及PIVOT [98]所说的,“推广到更高维度的空间,如旋转姿态,甚至带来了额外的挑战”
为了解决这个问题,ReKep的一个关键见解是,VLMs只需要通过推理关键点在(x, y, z)笛卡尔坐标中的位置来隐式地指定完整的3D旋转
one key insight from ReKep is that VLMs only need to implicitly specify full 3D rotations by reasoning about keypoints in (x, y, z) Cartesian coordinates
在此之后,实际的3D旋转由高精度和高效的数值求解器解决,有效地避开了显式预测3D旋转的挑战
After this, actual 3D rotations are solved by high-precision and efficient numerical solvers, effectively sidestepping the challenge of explicitly predicting 3D rotations
因此,相同的思路/公式也自然地推广到控制多个机械臂 - 高级规划
许多研究也通过语言相关的任务规划器来处理多阶段任务(这些任务规划器与具体的方法无关),ReKep的公式从TAMP中汲取灵感,并在统一的连续数学程序中有机地将高级任务规划与低级动作集成在一起
因此,该方法可以自然地考虑跨阶段的几何依赖关系,并以实时频率进行处理。当发生故障时,它会回溯到其条件仍然可以满足的前一阶段
例如,在“倒茶”任务中,只有当茶壶嘴与杯口对齐时,机器人才能开始倾斜茶壶。然而,如果在此过程中杯子被移动,它应该将茶壶保持水平并重新与杯子对齐。或者,如果茶壶被从夹持器中取出,它应该重新抓住茶壶 - 低级执行
使用VLMs的一个常见问题是运行计算成本高,这阻碍了许多操作任务中经常需要的高频率感知-行动反馈循环。因此,大多数现有工作要么考虑在视觉感知仅在开始时使用的开环设置,要么只考虑可以接受慢速执行的任务
相反,ReKep的公式通过将VLMs与点追踪器结合,原生支持高频率感知-行动循环,这有效地通过闭环执行实现了反应行为——尽管利用了非常大的基础模型 - 视觉提示方法Visual Prompting Methods
ReKep独特地考虑使用视觉提示进行代码生成,其中代码可能包含通过视觉引用表达式对一组关键点进行任意算术运算
尽管单个点在捕捉复杂几何结构方面有限制,但多个点及其关系甚至可以指定向量、表面、体积及其时间依赖性
虽然概念上简单,但这提供了更高的灵活性,可以完全指定6自由度甚至12自由度的运动
1.2 ReKep总览:关键方法与其架构
1.2.1 什么是关系关键点约束
ReKep 的一个实例是一个函数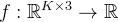
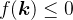
- 函数
实现为一个无状态的 Python 函数,包含对关键点进行的 NumPy [123] 操作,这些操作可能是非线性和非凸的
- 本质上,ReKep 的一个实例编码了关键点之间的一种期望的空间关系,这些关键点可能属于机器人手臂、物体部件和其他代理
- 然而,一个操作任务通常涉及多个空间关系,并且可能具有多个时间上相互依赖的阶段,每个阶段都包含不同的空间关系
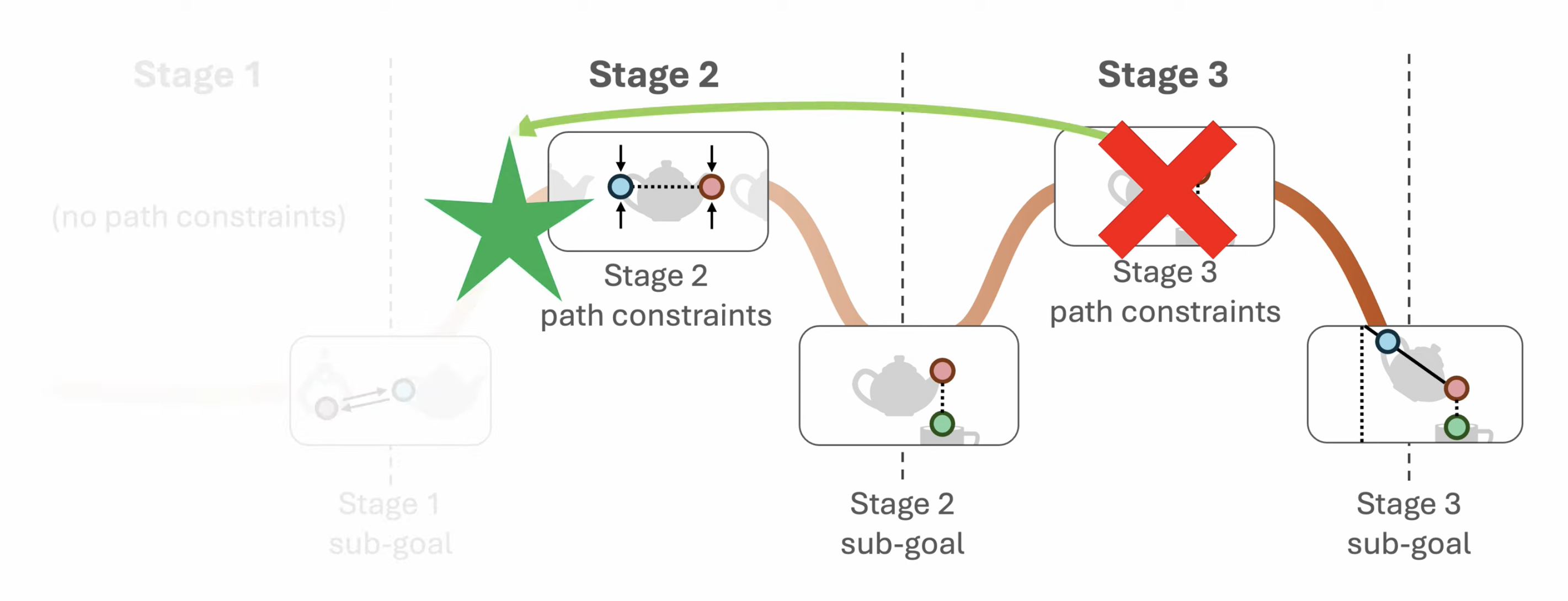
为此,我们将任务分解为N个阶段,并使用ReKep为每个阶段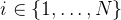
- 一组子目标约束
其中,编码了在阶段
结束时要实现的一个关键点关系,相当于是阶段目标
- 一组路径约束
其中,编码了在阶段
考虑下图中的倒水任务,它包括三个阶段:抓取、对齐和倒水
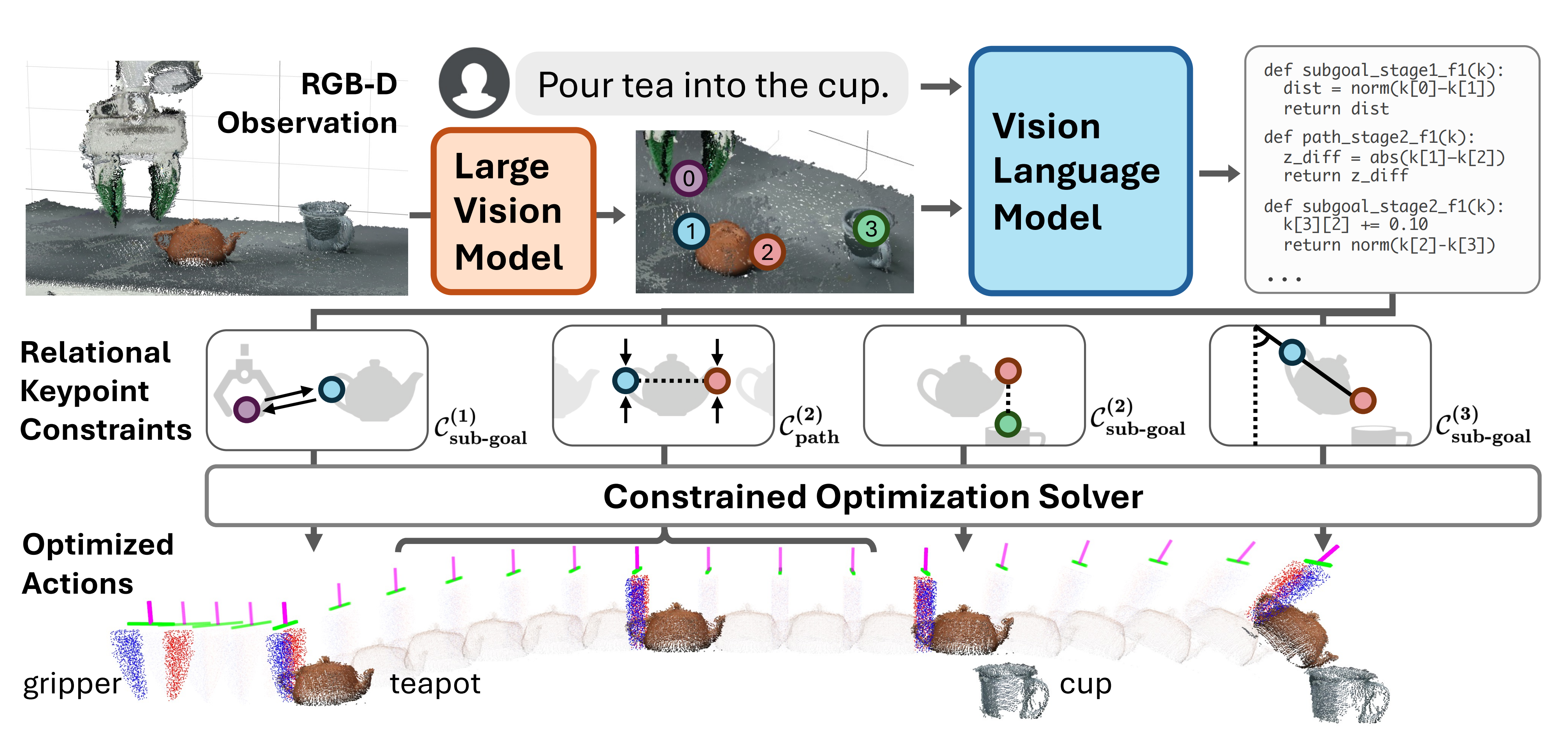
- 阶段1的子目标约束(sub-goal constraint),将末端执行器拉向茶壶把手
- 然后阶段2的子目标约束指定茶壶嘴需要在杯口上方
此外,阶段2的路径约束(path constraint),确保茶壶保持直立,以避免在运输过程中洒出 - 最后,阶段3的子目标约束指定了理想的倒水角度
1.2.2 通过ReKep将操作任务视为带约束的优化问题
使用ReKep作为表示约束的一般工具,采用[7,Sequence-of-constraints mpc: Reactive timing-optimal control of sequential manipulation]中的公式,并展示如何将操作任务表述为涉及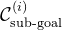
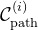
将末端执行器姿态表示为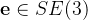
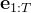
- 其中 ,
表示在时间
的末端执行器姿态,
是从阶段
的转换时间
where et denotes end-effector pose at time t, gi ∈ {1, . . . , T } are the timings of the transition from stage i to i + 1是时间
是关键点的前向模型
和
是子目标和路径问题的辅助成本函数(例如,碰撞避免)
- 即,对于每个阶段
,以实现该子目标,并满足给定的ReKep约束和辅助代价
Namely, for each stage i, the optimization shall find an end-effector pose as next sub-goal, along with its timing, and a sequence of poses egi−1:gi that achieves the sub-goal, subject to the given set of ReKep constraints and auxiliary costs.
1.3 深入约束:子目标约束与路径约束的实现
为了解实时解决方程1,可以对整个问题进行分解,只优化紧接着的下一个子目标及其到达下一个子目标的相应路径——算法1中的伪代码,如下图所示(其中的Eq.2 是求解子目标,Eq.3是求解对应的路径,下文马上会详述)

- 所有优化问题——包含子目标约束问题与路径约束问题,均使用SciPy [ Scipy 1.0: fundamental algorithms for scientific computing in python ] 实现和解决,决策变量归一化到 [0, 1]
注意,SciPy 已成为利用 Python 编程语言中的科学算法的事实标准,拥有 600 多个唯一代码贡献者、数千个依赖包、超过 100,000 个依赖存储库以及每年数百万次下载,其中包括 GitHub 上几乎一半的机器学习项目使用 SciPy - 它们最初使用双重退火 [126] 和 SLSQP [127] 作为局部优化器(大约1秒)解决,然后基于先前的解决方案仅使用局部优化器以大约10 Hz1的频率解决
1.3.1 子目标求解器的实现细节
首先,解决子目标问题以获得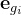
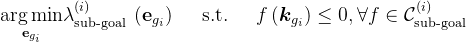
- 其中,
包含辅助控制成本,比如场景碰撞避免、可达性reachability、姿态正则化、解决方案一致性,以及双手设置的自碰撞
- 即,方程2试图找到一个「满足子目标约束
的同时,最小化辅助成本」的子目标
另,如果一个阶段涉及抓取,还包括一个抓取度量——则可以使用AnyGrasp「其对应论文为《Anygrasp:Robust and efficient grasp perception in spatial and temporal domains》,即此文《视觉语言机器人的大爆发:从RT2、VoxPoser、OK-Robot到Figure 01、清华CoPa》中“4.2.2 机器人对现实世界物体的抓握”提到的AnyGrasp」
总之,子目标问题使用SciPy [125]实现并解决
- 决策变量是单臂机器人在 R6中的单个末端执行器姿态(位置和欧拉角),以及双手机器人在 R12中的两个末端执行器姿态
- 位置项的界限是预定义的工作空间界限,旋转项的界限是末端执行器朝下的半球(由于Franka机械臂的关节限制,当末端执行器朝上时,往往容易达到关节限制)
The bounds for the position terms are the pre-defined workspace bounds, and the bounds for the rotation terms are that the half hemisphere where the end-effector faces down (due to the joint limits of the Franka arm, it is often likely to reach joint limit when a end-effector pose faces up)
根据界限,决策变量被归一化到 [−1,1]
在第一次求解迭代中,初始猜测选择为当前的末端执行器姿态。在第一次迭代中使用基于采样的全局优化双重退火 [126] 快速搜索整个空间
随后使用基于梯度的局部优化器SLSQP [127] 来优化解决方案 - 整个过程在这一迭代中大约需要1秒钟
在随后的迭代中,使用前一阶段的解决方案,并且只使用局部优化器,因为它可以快速调整小的变化
优化在固定的时间预算内截止,表示为目标函数调用的次数,以保持系统高频运行
接下来,讨论下目标函数中的成本项
- 约束违反
在优化问题中将约束实现为成本项,其中ReKep函数返回的成本乘以较大的权重 - 场景碰撞避免
使用nvblox [149] 和 PyTorch 包装器 [58] 在一个以20 Hz运行的单独节点中计算场景ESDF
ESDF计算聚合了来自所有可用摄像头的深度图,并使用cuRobo排除机器人手臂和任何被抓取的刚性物体「通过一个被遮罩的跟踪模型Cutie [136]进行跟踪)」
然后使用ESDF计算一个碰撞体素网格,并由系统中的其他模块使用
在子目标求解模块中,我们首先使用最远点采样将夹持器点和被抓取物体点下采样到最多30个点
然后我们使用带有线性插值的ESDF体素网格计算碰撞成本,阈值为 15厘米 - 可达性
由于我们的决策变量是末端执行器姿态,而机器人手臂可能无法总是到达这些姿态,特别是在狭小空间内,需要添加一个成本项,以鼓励找到具有有效关节配置的解决方案
因此,我们在子目标求解器的每次迭代中使用PyBullet [133,「《Pybullet, a python module for physics simulation for games, robotics and machine learning》中的IK求解器」]解决一个逆运动学问题,并使用其残差作为可达性的代理
顺带说一下,关于逆运动学,这篇论文《A survey of inverse kinematics techniques for 6-DOF manipulators》值得读一下
这篇综述论文系统回顾了用于6自由度机械臂的多种逆运动学求解技术,包括解析法、数值法和优化方法。论文对比了这些方法的优缺点,并根据应用场景提供了选择指导。它还讨论了逆运动学在机器人操作中的实际挑战,例如奇异性和冗余自由度处理
发现这大约占用了完整目标函数时间的40%。或者,可以在关节空间中解决问题,这将通过强制执行边界来确保解决方案在关节限制范围内
且发现,由于约束在任务空间中进行评估,而基于Python的实现效率较低——因为需要在路径求解器中计算大量的正向运动学
为了解决这个问题并确保效率,未来的工作可以考虑使用硬件加速的实现来解决关节空间中的问题 [58] - 姿态正则化
还添加了一个小成本,鼓励子目标接近当前的末端执行器姿态 - 一致性
由于求解器以高频率迭代解决问题,并且感知管道中的噪声可能传播到求解器,且发现包含一致性成本是有用的,这鼓励解决方案接近先前的解决方案 - (仅双臂) 自碰撞避免
为了避免两只手臂相互碰撞,他们计算了两组点之间的成对距离,每组包括夹持器点和抓取物体点
1.3.2 路径求解器的实现细节
其次,对于路径问题:在获得子目标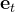
的轨迹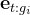
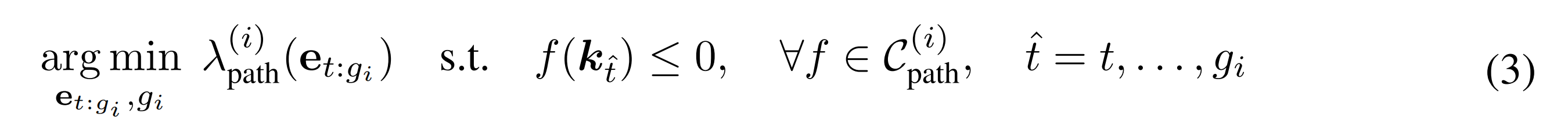
- 其中
包含以下辅助控制成本:场景碰撞避免、可达性、路径长度、解决方案一致性,以及在双手设置情况下的自碰撞
- 如果到子目标的距离在一个小容差范围内 ϵ,将进入下一个阶段 i+ 1
if the distance to the sub-goal egi is within a small tolerance ϵ, we progress to the next stage i+1
总之,路径问题使用 SciPy [125] 实现和解决。决策变量的数量是根据当前末端执行器姿态和目标
末端执行器姿态之间的距离计算的,具体来说
- 定义了一个固定的步长(20厘米和 45度),并线性近似所需的“中间姿态”数量,这些数量被用作决策变量。如在子目标问题中一样,它们同样使用位置和欧拉角表示,并具有相同的边界
- 对于第一次求解迭代,初始猜测选择为起点和目标之间的线性插值
同样在第一次迭代中使用基于采样的全局优化,然后是基于梯度的局部优化器,并且在后续迭代中仅使用局部优化器
在获得解决方案后,该解决方案表示为若干中间姿态,使用当前姿态、中间姿态和目标姿态拟合样条,然后对其进行密集采样以由机器人执行
在目标函数中,首先对决策变量进行反归一化并使用分段线性插值来获得表示路径的密集离散姿态序列(下文称为“密集样本”)
In the objective function, we first unnormalize the decision variables and use piecewise linear in-terpolation to obtain a dense sequence of discrete poses to represent the path (referred to as “dense samples” below)
样条插值将与他们后处理和执行解决方案的方式保持一致,但他们发现线性插值在计算上更为高效
下面讨论目标函数中的各个成本项
- 约束违反
类似于子目标问题,检查路径上每个密集样本的ReKep约束违反情况,并给予大权重惩罚 - 场景碰撞避免
计算方法类似于子目标问题,只是针对每个密集样本进行计算且忽略了起始和目标姿态附近 5厘米半径内的碰撞计算,因为在高频率求解时,由于各种现实世界的噪声,这有助于稳定解决方案
另外添加了一个桌面清除成本,以惩罚路径穿透桌面(或轮式单臂机器人工作空间的底部) - 路径长度
通过取密集样本的差值之和来近似路径长度。鼓励更短的路径 - 可达性
在目标函数中为每个中间姿态解决一个逆运动学问题,就像在子目标问题中一样 - 一致性
与子目标问题一样,鼓励解决方案接近前一个。具体来说,存储了前一次迭代的密集样本。为了计算解决方案的一致性,使用两个序列(视为两个集合)之间的成对距离作为有效的代理
或者,可以使用Hausdorff距离 - (仅限双臂) 自碰撞避免
同样为双臂平台计算自碰撞避免,就像在子目标问题中一样,还使用两个序列之间的成对距离来有效地计算此成本
1.3.3 回溯与关键点的前向模型
接着,再看回溯: 尽管子问题可以在实时频率下解决,以在一个阶段内对外部干扰做出反应,但如果最后一个阶段的任何子目标约束不再成立(例如,在倒茶任务中,杯子被从夹持器中取出),系统必须能够跨阶段重新规划
具体来说,在每个控制循环中,检查是否违反了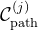
然后,再看关键点的前向模型
为了解决方程2和方程3,在优化过程中必须利用一个前向模型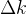
- 如同之前的工作——kpam,使刚性末端执行器和“抓取关键点”(属于同一物体或部分的刚性关键点组;从分割模型中获得,下一节 即将介绍)之间的假设(we make the rigidity assumption between the end-effector and the “grasped keypoints”)
即给定末端执行器姿态的变化,可以通过应用相同的相对刚性变换
来计算关键点位置的变化,同时假设其他关键点保持静止
Namely, given a change in the end-effector pose ∆e, we can calculate the change in keypoint positions by applying the same relative rigid transformation k′[grasped] = T∆e · k[grasped], while assuming other keypoints stay static. - 且注意到,这是一个“局部”假设,因为它仅假设在解决问题的短期(0.1秒)内成立
We note that this is a “local” assumption in that it is only assumed to hold for the short horizon (0.1s) that the problem is solved.
实际的关键点位置使用20 Hz的视觉输入进行跟踪,并在每个新问题中使用
Actual keypoint positions are tracked using visual input at 20 Hz and used in every new problem.
至于对于更具挑战性的场景(例如,动态或接触丰富的任务),可以使用学习或基于物理的模型
For more challenging scenarios(e.g., dynamic or contact-rich tasks), a learned or physics-based model may be used.
1.4 完整实现:ReKep关键点提议的实现细节和ReKep生成
为了使系统能够在野外执行任务并给出自由形式的任务指令,设计了一个使用大型视觉模型和视觉-语言模型的管道,用于关键点提议和ReKep生成,分别讨论如下:
1.4.1 关键点提议:最终选中DINOv2来提取特征
给定一个RGB图像
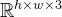
- 首先从DINOv2 [Dinov2: Learning robust visual features without supervision]中提取逐块特征
- 然后执行双线性插值,将特征上采样到原始图像大小,
- 为了确保提案覆盖场景中的所有相关对象,他们使用Segment Anything (SAM) 「其对应论文为:Segment anything,且此文《SAM(分割一切)——图像分割的大变革:从SAM、FastSAM、MobileSAM到SAM2》有介绍]」提取场景中的所有掩码
- 对于每个掩码
,使用k-均值聚类算法对掩码特征
进行聚类,k= 5,使用余弦相似度度量
聚类的质心用作关键点候选,通过校准的RGB-D相机投影到世界坐标R3,距离其他候选点在8厘米以内的候选点会被过滤掉
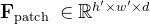
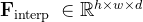
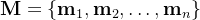
总体而言,他们发现该过程能够识别出大量细粒度和语义上有意义的对象区域
总之,对于每个平台,使用安装的RGB-D相机之一捕捉尺寸为 h × w × 3的图像,具体取决于哪台相机具有最佳的整体视图,因为所有关键点都需要在第一帧中出现以便使用所提出的方法。给定捕捉的图像
- 首先使用带有寄存器的DINOv2 (ViT-S14) [5, 137] 提取补丁特征
- 然后执行双线性插值,将特征上采样到原始图像大小,
- 为了确保提案覆盖场景中的所有相关对象,使用 Segment Anything (SAM) [132] 提取场景中的所有掩码
- 在每个掩码mi中,应用 PCA 将特征投影到三维,
发现应用 PCA 改善了聚类,因为它通常会去除与纹理相关的细节和伪影——这些对的任务没有用处
- 对于每个掩码j,使用k-均值聚类算法对掩码特征
请注意,还存储了哪些关键点候选来自同一个掩码,这在第1.3节描述的优化循环中的刚性假设部分会用到。超出工作空间边界的候选会被过滤掉
为了避免在小区域内出现许多杂乱的点,还使用均值漂移[138, 139] (带宽为8厘米)来过滤彼此接近的点,最后,质心被作为最终候选
值得一提的是,可能有的读者好奇,李飞飞他们为何选DINOv2?其实,他们做了不同方法的关键点提议比较:

- SAM + DINOv2
- SAM + CLIP(视觉-语言对比预训练)
- SAM + ViT(监督预训练)
- 仅DINOv2,自监督预训练
可以看到,得到的结果为
- SAM提供的对象性先验对于将关键点提议约束在场景中的物体上而不是背景上至关重要
- 虽然大多数视觉基础模型可以提供有用的指导,但DINOv2产生的特征更为清晰,可以更好地区分物体的细粒度区域
比如CLIP在不同物体部件之间提供了不同的特征,但这些特征不如DINOv2的清晰(颜色从一个部件到另一个部件逐渐饱和) - 另一方面,ViT在物体部件之间产生的特征最不明显。物体部件,尤其是当纹理相似时
总体而言,观察结果与其他也应用DINOv2进行细粒度物体理解的工作一致
1.4.2 ReKep生成
在获得关键点候选后
- 将它们覆盖在原始RGB图像上,并用数字标记(After obtaining the keypoint candidates, we overlay them on the original RGB image with numerical marks)
- 结合任务的语言指令,然后使用视觉提示来查询GPT-4o,以生成所需阶段的数量和相应的子目标约束
值得注意的是,这些函数不会直接操作关键点位置的数值。相反,利用VLM的优势,通过算术运算(如关键点之间的L2距离或点积)来指定空间关系,这些运算仅在使用专门的3D跟踪器跟踪的实际关键点位置时才会实例化
Notably,the functions do not directly manipulate the numerical values of the keypoint positions. Rather, we exploit the strength of VLM to specify spatial relations as arithmetic operations, such as L2 distance or dot product between keypoints, that are only instantiated when invoked with actual keypoint po-sitions tracked by a specialized 3D tracker. - 此外,使用一组关键点位置进行算术运算的一个重要优势是,当提供足够的点并在相关点之间强制刚性时,它可以在完整的SO(3)中指定3D旋转,但这仅在根据任务语义需要时才会进行
Furthermore, an important advantage of using arithmetic operations on a set of keypoint positions is that it can specify 3D rotations in full SO(3) when suf-ficient points are provided and rigidity between relevant points is enforced, but this is done only when needed depending on task semantics3.
这使得VLM能够在3D笛卡尔空间中通过算术运算来推理3D旋转,有效地避免了处理替代3D旋转表示和执行数值计算的需要
This enables VLM to reason about 3D rotations with arithmetic operations in 3D Cartesian space, effectively circumventing the need for dealing with alternative 3D rotation representation and the need for performing numerical computation
总之,在获得关键点候选后
- 它们被覆盖在捕获的RGB图像上,并用数字标记
- 然后将图像和任务指令输入到带有以下描述提示的视觉语言模型中。提示仅包含通用指令,没有图像-文本上下文示例,尽管提供了一些基于文本的示例来具体解释所提出的方法和模型的预期输出
请注意,大多数研究的任务在提供的提示中没有讨论。因此,VLM的任务是利用其内化的世界知识生成ReKep约束- 在本研究中进行的实验中,使用了GPT-4o [6],因为它是实验时可用的最新模型之一
然而,由于该领域的快速进展,该流程可以直接从具有更好视觉语言推理能力的更新模型中受益
相应地,观察到不同的模型在给定相同提示时表现出不同的行为(观察到更新的模型通常需要更少的细粒度指令)
因此,他们不再致力于为本工作的任务套件开发最佳提示,而是专注于展示一个全栈管道,该管道包含一个关键组件,可以通过未来的开发实现自动化和持续改进
1.5 ReKep完整示例:针对「1.4节关键点提议和ReKep生成」
1.5.1 倒茶等任务的阶段动作及其对应的子目标约束、路径约束
以下是倒茶、折叠袖子、折叠夹克等任务的阶段目标,及其对应的子目标约束、路径约束
## 说明
假设你通过编写Python约束函数来控制机器人执行操作任务。操作任务以环境图像的形式给出,图像上覆盖了标有索引的关键点,以及文本说明。
说明以括号开头,指示机器人是单臂还是双手。对于每个给定的任务,请执行以下步骤:
- 确定任务涉及多少个阶段。抓取必须是一个独立的阶段。一些例子:
- "(单臂)从茶壶倒茶":
- 3个阶段:"抓住茶壶","将茶壶对准杯口",和"倒液体"
- "(单臂)将红色积木放在蓝色积木上":
- 3个阶段:“抓住红色积木”、“将红色积木对齐在蓝色积木上方”和“释放红色积木”
- “(双手)将袖子折叠到中间”:
- 2个阶段:“左臂抓住左袖子,右臂抓住右袖子”和“两臂将袖子折叠到中间”
- “(双手)折叠夹克”:
- 3个阶段:“左臂抓住左袖子,右臂抓住右袖子”、“两臂将袖子折叠到中间”和“一只手抓住领口(另一只手保持原位)”,以及“将领口对齐到底部”
- 对于每个阶段,写出两种约束,“子目标约束”和“路径约束”。“子目标约束”是在阶段结束时必须满足的约束,而“路径约束”是在阶段内必须满足的约束。一些例子:
- “(单臂)从茶壶倒液体”:
- "抓住茶壶"阶段:
- 子目标约束: "将末端执行器与茶壶把手对齐"
- 路径约束: 无
- "将茶壶与杯口对齐"阶段:
- 子目标约束: "茶壶嘴需要在杯口上方10厘米"
- 路径约束: "机器人正在抓住茶壶", 并且"茶壶必须保持直立以避免洒出"
- "倒液体"阶段:
- 子目标约束: "茶壶嘴需要在杯口上方5厘米", "茶壶嘴必须倾斜以倒出液体"
- 路径约束: "茶壶嘴直接在杯口上方"
- “(双手)将袖子折叠到中间”:
- "左臂抓住左袖,右臂抓住右袖"阶段:
- 子目标约束: "左臂抓住左袖", "右臂抓住右袖"
- 路径约束: 无
- "双臂将袖子折叠到中心"阶段:
- 子目标约束: "左袖与中心对齐", "右袖与中心对齐"
- 路径约束: 无1.5.2 约束的注意事项
注意:
- 每个约束接受一个虚拟末端执行器点和一组关键点作为输入,并返回一个数值成本,当成本小于或等于零时,约束被满足。
- 对于每个阶段,你可以编写0个或多个子目标约束和0个或多个路径约束。
- 在你的约束中避免使用“if”语句。
- 在操作可变形物体(例如,衣物、毛巾)时避免使用路径约束。
- 你不需要考虑碰撞避免。专注于完成任务所需的内容。
- 约束的输入如下:
- `end_effector `: np.array of shape `(3,) ` 表示末端执行器的位置。
- `keypoints `: np.array of shape `(K, 3) ` 表示关键点的位置。
- 在每个函数内部,你可以使用原生Python函数和NumPy函数。
- 对于抓取阶段,你应该只编写一个将末端执行器与关键点关联的子目标约束。不需要路径约束。
- 对于非抓取阶段,不应参考末端执行器的位置。
- 为了移动一个关键点,其关联的物体必须在前一个阶段之一被抓取。
- 机器人一次只能抓取一个物体。
- 抓取必须是独立于其他阶段的阶段。
- 您可以使用两个关键点形成一个向量,该向量可用于指定旋转(通过指定向量与固定轴之间的角度)。
- 您可以使用多个关键点来指定一个表面或体积。
- 您也可以使用多个关键点的中心来指定一个位置。
- 单个折叠动作应包括两个阶段:一个抓取和一个放置1.5.3 将ReKep生成转化成Python代码
其对应的代码如下
Structure your output in a single python code block as follows for single-arm robot:
```python
# Your explanation of how many stages are involved in the task and what each stage is about.
# ...
num_stages = ?
### stage 1 sub-goal constraints (if any)
def stage1_subgoal_constraint1(end_effector, keypoints):
"""Put your explanation here."""
...
return cost
# Add more sub-goal constraints if needed
### stage 1 path constraints (if any)
def stage1_path_constraint1(end_effector, keypoints):
"""Put your explanation here."""
...
return cost
# Add more path constraints if needed
# repeat for more stages
...
```
Structure your output in a single python code block as follows for bimanual robot:
```python
# Your explanation of how many stages are involved in the task and what each stage is about.
# ...
num_stages = ?
### left-arm stage 1 sub-goal constraints (if any)
def left_stage1_subgoal_constraint1(end_effector, keypoints):
"""Put your explanation here."""
...
return cost
### right-arm stage 1 sub-goal constraints (if any)
def right_stage1_subgoal_constraint1(end_effector, keypoints):
"""Put your explanation here."""
...
return cost
# Add more sub-goal constraints if needed
### left stage 1 path constraints (if any)
def left_stage1_path_constraint1(end_effector, keypoints):
"""Put your explanation here."""
...
return cost
### right stage 1 path constraints (if any)
def right_stage1_path_constraint1(end_effector, keypoints):
"""Put your explanation here."""
...
return cost
# Add more path constraints if needed
# repeat for more stages
...
```
## Query
Query Task: "[INSTRUCTION]"
Query Image: [IMAGE WITH KEYPOINTS以上代码对应的翻译如下
将您的输出结构化为如下所示的单臂机器人单个python代码块:
``` python
# 您对任务涉及的阶段数量及每个阶段内容的解释。
# ...
num_stages = ?
### 阶段1子目标约束(如果有)
def stage1_subgoal_constraint1(end_effector, keypoints):
"""在这里放置你的解释。"""
...
返回成本
# 如果需要,添加更多子目标约束
### 阶段1路径约束(如果有的话)
def stage1_path_constraint1(end_effector, keypoints):
"""在这里放置你的解释。"""
...
返回成本
# 如果需要,添加更多路径约束
# 重复更多阶段
...
```
将你的输出结构化为如下的双手机器人代码块:
``` python
# 您对任务涉及的阶段数量及每个阶段内容的解释。
# ...
num_stages = ?
### 左臂阶段1子目标约束(如果有的话)
def left_stage1_subgoal_constraint1(end_effector, keypoints):
"""在这里放置你的解释。"""
...
返回成本
### 右臂阶段1子目标约束(如果有的话)
def right_stage1_subgoal_constraint1(end_effector, keypoints):
"""在这里放置你的解释。"""
...
返回成本
# 如果需要,添加更多子目标约束
### 左臂阶段1路径约束(如果有的话)
def left_stage1_path_constraint1(end_effector, keypoints):
"""在这里放置你的解释。"""
...
返回成本
### 右臂阶段1路径约束(如果有的话)
def right_stage1_path_constraint1(end_effector, keypoints)
"""在这里放置你的解释。"""
...
返回成本
# 如果需要,添加更多路径约束
# 重复更多阶段
...
```
## 查询
查询任务: "[指令]"
查询图像: [带有关键点的图像]第二部分 从硬件操作平台、实验效果及表现到ReKep的完整示例
2.1 轮式单臂平台和固定双臂平台
2.1.1 轮式单臂平台
ReKep研究的平台之一是一个安装在用Vention框架构建的轮式底座上的Franka机械臂,如下图左侧所示
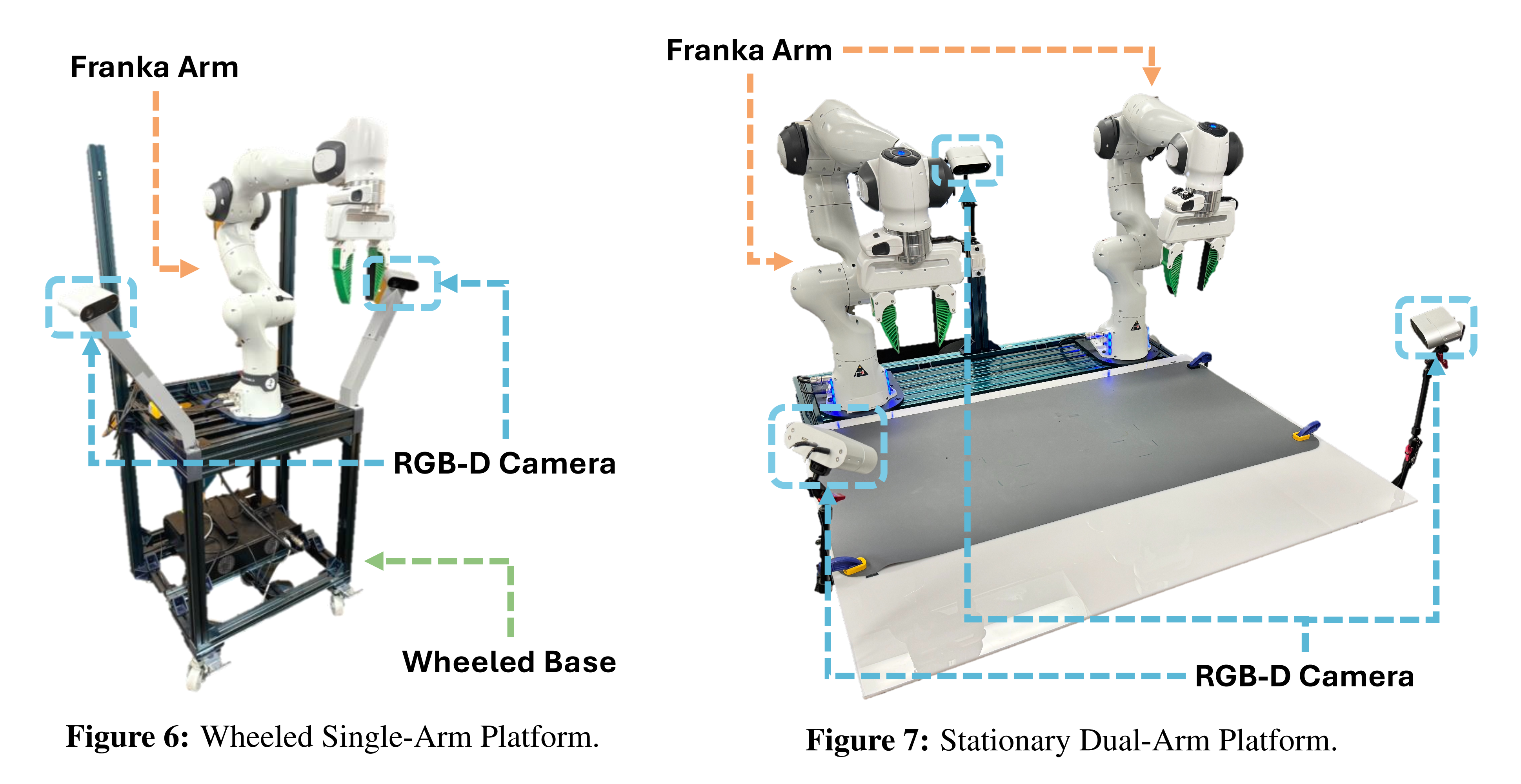
请注意,底座没有电机,因此无法自主移动,但其机动性仍然使得能够在实验室环境之外研究所提出的方法
由于他们的流水线生成了一系列6自由度末端执行器姿态,他们在所有实验中都使用位置控制,运行频率固定为 20Hz
具体来说,一旦机器人在世界坐标系中获得目标末端执行器姿态
- 他们首先将姿态裁剪到预定义的工作空间
- 然后以 5毫米的位置步长和 1度的旋转步长从当前姿态线性插值到目标姿态
- 为了移动到每个插值姿态,首先计算逆运动学,以根据当前关节位置获得目标关节位置(使用PyBullet
To move to each interpolated pose, we first calculate inverse kinematics to obtain the target joint positions based on current joint positions (IK solver from PyBullet [133])
然后使用Deoxys [Viola: Imitation learning for vision-based manipulation with object proposal priors]中的关节阻抗控制器来达到目标关节位置
Then we use the joint impedance controller from Deoxys [134] to reach to the target joint positions
此外,两个RGB-D相机,Orbbec Femto Bolt,安装在机器人两侧,面向工作空间中心。相机以固
定频率捕捉RGB图像和点云,频率为 20 Hz
2.1.2 固定双臂平台
他们还在一个固定的双臂平台上研究了该方法,该平台由两个Franka机械臂组成,安装在
桌面工作空间前,如下图右侧所示
与轮式单臂平台共享相同的控制器,不同之处在于两个机械臂以20Hz的频率同时控制
- 具体来说,该管道共同解决了两个6自由度末端执行器姿态序列,这些序列一起发送到低级控制器
控制器随后计算两只手臂的逆运动学,并使用关节阻抗控制移动手臂 - 此外,三个RGB-D相机,Orbbec Femto Bolt,安装在这个平台上。两个相机安装在左右两侧,一个相机安装在后方,相机同样以固定频率 20 Hz捕捉RGB图像和点云
2.2 实验效果及其表现
2.2.1 与基线VoxPoser的比较
他们使用VoxPoser 「其论文为《Voxposer: Composable 3d value maps for robotic manipulation with language models 》,且在此文《视觉语言机器人的大爆发:从RT2、VoxPoser、OK-Robot到Figure 01、清华CoPa》的第二部分 李飞飞团队:具身智能VoxPoser,有介绍」作为主要的基线方法,因为它做出了类似的假设,即不需要任务特定数据或预定义的运动原语
且他们对VoxPoser进行了某些修改以适应ReKep的设置,以确保比较的公平性
- 具体来说,使用相同的VLM,GPT-4o [6],它接受相同的摄像头输入。还通过本文中使用的提示来增强论文中的原始提示,以确保它具有足够的上下文
- 且只使用可供性、旋转和夹持器动作值图,并忽略避免和速度值图,因为它们对我们的任务不是必需的
- 也只考虑“感兴趣的实体”是机器人末端执行器而不是场景中的物体的情况,毕竟后者是为推动任务量身定制的,而本工作不研究这一任务
- 使用 OWL-ViT [ Simple open-vocabulary object detection
with vision transformers] 进行开放词汇的物体检测,使用 SAM 进行初始帧分割,并使用 Cutie [Putting the object back into video object segmentation] 进行掩码跟踪
2.2.2 双臂机器人折叠衣物
双臂机器人负责折叠八种不同类别的衣物,他们使用两个指标进行评估:“策略成功”和“执行成功”,前者评估是否适当地提出了关键点和编写了约束,后者评估在策略成功的情况下机器人系统的执行情况
- 为了评估“策略成功”,衣物被初始化在工作区的中心附近。一个背装的RGB-D相机捕捉RGB图像
- 然后,关键点提议模块使用捕捉到的图像生成关键点候选,并将其与数字标记 {0,. . . , K − 1}叠加在原始图像上
- 叠加图像与相同的通用提示一起被输入到GPT-4 [6]中以生成ReKep约束
由于折叠衣物本身是一个没有真实策略的开放性问题,他们手动判断所提议的关键点和生成的约束是否正确
请注意,由于约束是由双手机器人执行的,并且约束几乎总是连接(折叠)两个关键点以使其对齐,正确性是通过机器人是否可以(潜在地)执行而不会导致自我碰撞(手臂交叉到对侧),以及折叠策略是否可以将衣物折叠到其原始表面积的一半以下来衡量的
- 为了评估“执行成功”,他们采用上一节中标记为每件衣物成功的生成策略,并在双臂平台上执行该序列,每件衣物进行10次试验
To evaluate “Execution Success,” we take the generated strategies in the previous section that are marked as successful for each garment and execute the sequence on the dual-arm platform, with a total of 10 trials for each garment - 由于他们发现当衣物可能被多次折叠时,点追踪器会预测不稳定的轨迹,因此禁用了点追踪功能,至于成功的衡量标准是衣物是否折叠到其表面积最多为原始表面积的一半
Point tracking is disabled as we observe that our point tracker predicts unstable tracks when the garment is potentially folded many times. Success is measured by whether the garment is folded such that its surface area is at most half of its original surface area
以下是点追踪器的实现细节
他们基于DINOv2 (ViT-S14) [5] 实现了一个简单的点追踪器,该追踪器利用了多个RGB-D相机的存在,并且DINOv2能够高效地以实时频率运行
- 在初始化时,给定一个3D关键点位置数组 k ∈ R
首先从每个现有的相机获取RGB-D捕捉。对于每个RGB图像,按照「1.4 ReKep关键点提议的实现细节和ReKep生成节」中的相同程序获取像素级的DINOv2特征,并使用校准相机记录其关联的3D世界坐标
对于每个3D关键点位置,从所有相机中聚合距离在2厘米以内的点的所有特征
聚合特征的均值被记录为每个关键点的参考特征,并在整个任务过程中保持固定- 初始化后,在每个时间步,同样从所有相机获取带有3D世界坐标的DINOv2像素级特征为了跟踪关键点,计算所有像素与参考特征之间的余弦相似度。每个关键点选择前 100个匹配,截断相似度为 0.6
- 然后,通过计算中位数偏差(m= 2)来拒绝选定匹配中的异常值
此外,由于跟踪的关键点可能在小区域内振荡
在最后应用窗口大小为 10的均值滤波器。整个过程以固定频率 20 Hz运行请注意,实现的点跟踪器是从[118]简化而来的实时跟踪。建议读者参考[118],以获取关于使用自监督视觉模型(如DINOv2)进行点跟踪的更全面讨论。或者,可以使用更专业的点跟踪器[141–148]
第三部分 ReKep源码剖析
// 待更