在训练过程中有时会出现显卡爆了的情况,导致无法进行训练,本文总结一下处理这种情况的三种方法。
1. 方法一:减小batch size
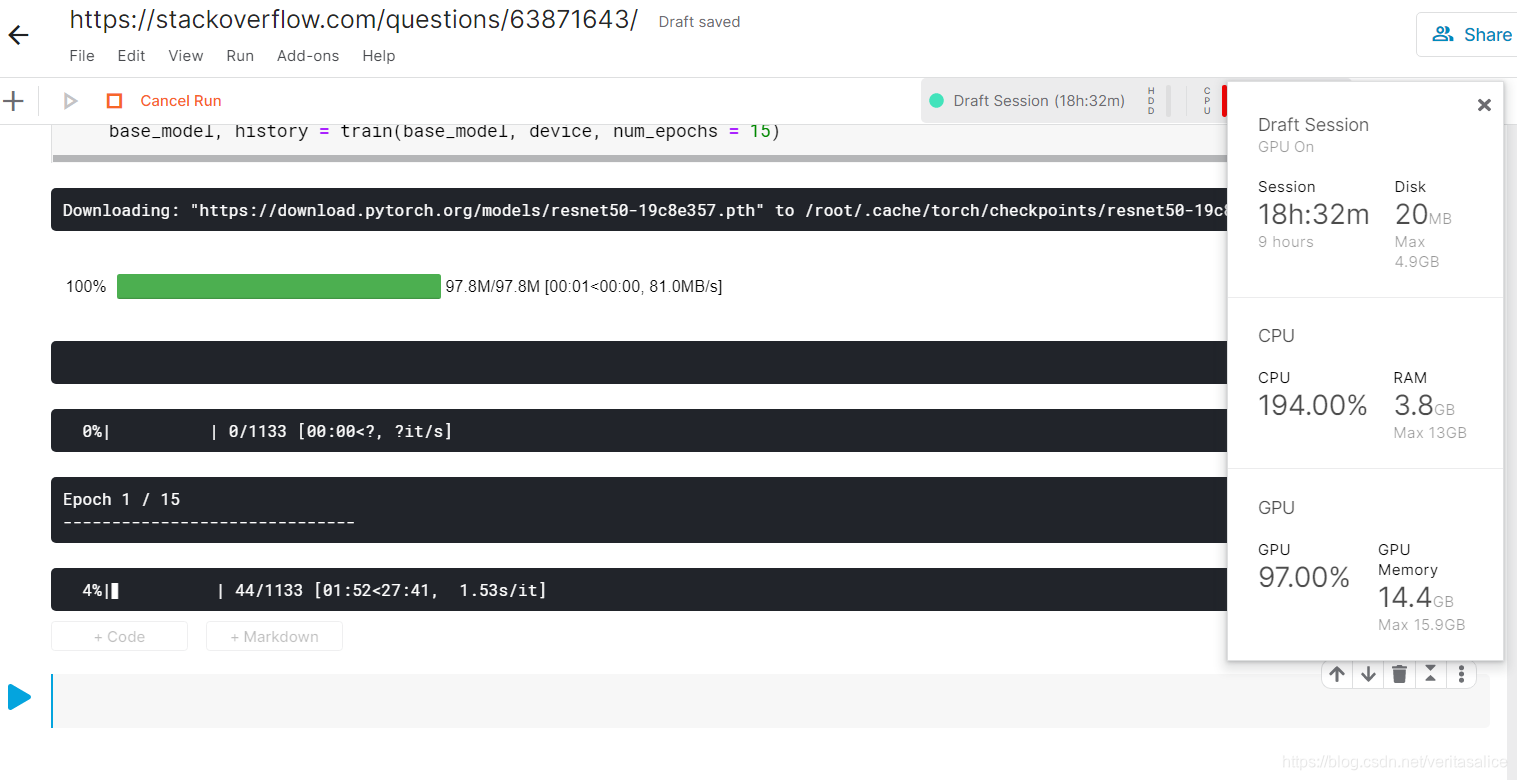
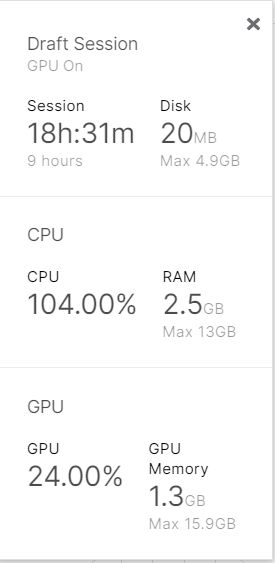
减小batch size是最直接方法,有人做过对比:
batch size是48的时候,GPU使用量为14.4G,batch size=1的时候就变成1.3G了。
2. 方法二:修改网络结构
- 修改隐层节点数,尽量让linear层的结点数变小
- 加dropout,pooling
- 检查有迭代的地方的迭代深度,迭代深度大也会增加GPU使用
3. 方法三:清掉GPU中不用的进程
如果像我一样实在不能调整batch size和网络结构,那就清除掉GPU中无用的进程
输入下面代码,查看GPU中的process:
ps -elf | grep python
kill掉没有用的进程
kill -9 [pid]