这两章主要介绍process相关的知识。
chapter 7 Process Environment
7.1 Intro
本章主要介绍一个进程的完整运行环境。we'll see how themain function is called when the program is executed, how command-line arguments are passed to the new program, what the typical memory layout looks like, how to allocate additional memory, how the process can use environment variables, and various ways for the process to terminate.
7.2 main function
A C program starts execution with a function calledmain. The prototype for themain function is
int main(int argc, char *argv[]);
whereargc is the number of command-line arguments, andargv is an array of pointers to the arguments.We describe these arguments in Section 7.4.
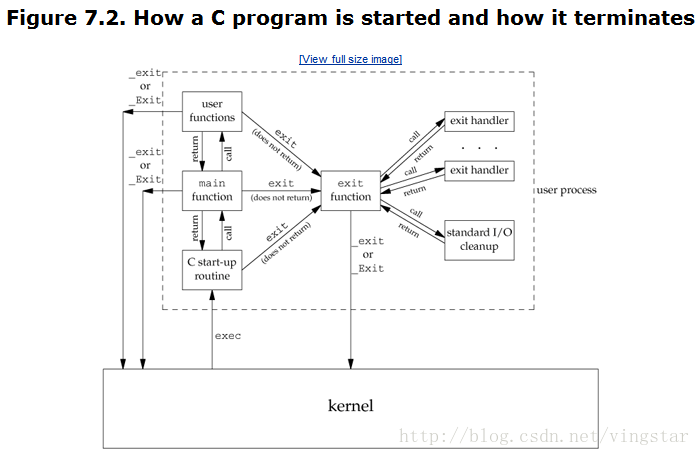
在一个程序link的时候系统就已经自动的在运行程序的最前部写入了一个routine的运行地址,这样一个程序被启动后,这个routine就会自动被执行,以收集相关的环境信息为运行该程序本身做好准备。When a C program is executed by the kernel, by one of theexec functions, which we describe in Section 8.10,a special start-up routine is called before the main function is called. The executable program file specifies this routine as the starting address for the program; this is set up by the link editor when it is invoked by the C compiler. This start-up routine takes values from the kernel the command-line arguments and the environment and sets things up so that themain function is called as shown earlier.
7.3 Process termination
There are eight ways for a process to terminate. Normal termination occurs in five ways:
-
Return frommain
-
Callingexit
-
Calling_exit or_Exit
-
Return of the last thread from its start routine (Section 11.5)
-
Callingpthread_exit (Section 11.5) from the last thread
Abnormal termination occurs in three ways:
-
Callingabort (Section 10.17)
-
Receipt of a signal (Section 10.2)
-
Response of the last thread to a cancellation request (Sections 11.5 and12.7)
The start-up routine that we mentioned in the previous section is also written so that if themain function returns, theexit function is called. If the start-up routine were coded in C (it is often coded in assembler) the call tomain could look like
exit(main(argc, argv));
EXIT functions
Three functions terminate a program normally:_exit and_Exit, which return to the kernel immediately, andexit, which performs certain cleanup processing and then returns to the kernel.
#include <stdlib.h>
void exit(int status);
void _Exit(int status);
#include <unistd.h>
void _exit(int status);
|
We'll discuss the effect of these three functions on other processes, such as the children and the parent of the terminating process, inSection 8.5.
The reason for the different headers is thatexit and_Exit are specified by ISO C, whereas_exit is specified by POSIX.1.
Historically, theexit function has always performed a clean shutdown of the standard I/O library: thefclose function is called for all open streams. Recall from Section 5.5 that this causes all buffered output data to be flushed (written to the file).
All three exit functions expect a single integer argument, which we call theexit status. Most UNIX System shells provide a way to examine the exit status of a process. If (a) any of these functions is called without an exit status, (b)main does areturn without a return value, or (c) themain function is not declared to return an integer, the exit status of the process is undefined. However, if the return type ofmain is an integer andmain "falls off the end" (an implicit return), the exit status of the process is 0.
Returning an integer value from themain function is equivalent to callingexit with the same value. Thus
exit(0);
is the same as
return(0);
With ISO C, a process can register up to 32 functions that are automatically called byexit. These are calledexit handlers and are registered by calling theatexit function.
#include <stdlib.h>
int atexit(void (*func)(void));
|
| Returns: 0 if OK, nonzero on error |
This declaration says that we pass the address of a function as the argument toatexit. When this function is called, it is not passed any arguments and is not expected to return a value. The exit function calls these functions in reverse order of their registration. Each function is called as many times as it was registered.
7.4 command-line Arguments
When a program is executed, the process that does theexec can pass command-line arguments to the new program. This is part of the normal operation of the UNIX system shells. We have already seen this in many of the examples from earlier chapters.
7.5 Environment List
Each program is also passed anenvironment list. Like the argument list, the environment list is an array of character pointers, with each pointer containing the address of a null-terminated C string. The address of the array of pointers is contained in the global variableenviron:
extern char **environ;
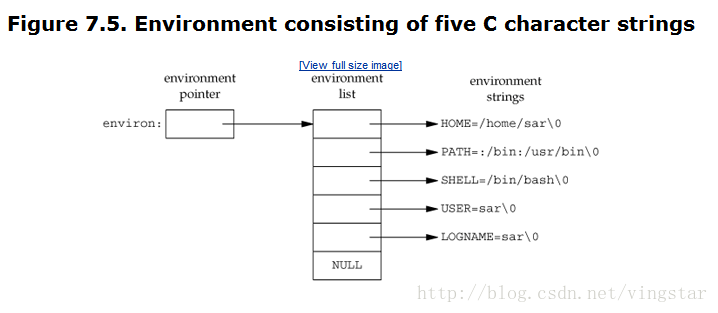
By convention, the environment consists of
name=value
7.6 Memory Layout of C Program
Historically, a C program has been composed of the following pieces:
-
Text segment, the machine instructions that the CPU executes. Usually, the text segment is sharable so that only a single copy needs to be in memory for frequently executed programs, such as text editors, the C compiler, the shells, and so on. Also, the text segment is often read-only, to prevent a program from accidentally modifying its instructions.
-
Initialized data segment, usually called simply the data segment, containing variables that are specifically initialized in the program. For example, the C declaration
int maxcount = 99;
appearing outside any function causes this variable to be stored in the initialized data segment with its initial value.
-
Uninitialized data segment, often called the "bss" segment, named after an ancient assembler operator that stood for "block started by symbol." Data in this segment is initialized by the kernel to arithmetic 0 or null pointers before the program starts executing. The C declaration
long sum[1000];
appearing outside any function causes this variable to be stored in the uninitialized data segment.
-
Stack, where automatic variables are stored, along with information that is saved each time a function is called. Each time a function is called, the address of where to return to and certain information about the caller's environment, such as some of the machine registers, are saved on the stack. The newly called function then allocates room on the stack for its automatic and temporary variables. This is how recursive functions in C can work. Each time a recursive function calls itself, a new stack frame is used, so one set of variables doesn't interfere with the variables from another instance of the function.
-
Heap, where dynamic memory allocation usually takes place. Historically, the heap has been located between the uninitialized data and the stack.


Several more segment types exist in ana.out, containing the symbol table, debugging information, linkage tables for dynamic shared libraries, and the like. These additional sections don't get loaded as part of the program's image executed by a process.
Note from Figure 7.6 that the contents of the uninitialized data segment are not stored in the program file on disk. This is because the kernel sets it to 0 before the program starts running.The only portions of the program that need to be saved in the program file are the text segment and the initialized data.7.7 shared libraries
介绍了一种使用共享库较小一个程序自身size的方法。
Shared libraries remove the common library routines from the executable file, instead maintaining a single copy of the library routine somewhere in memory that all processes reference. This reduces the size of each executable file but may add some runtime overhead, either when the program is first executed or the first time each shared library function is called. Another advantage of shared libraries is that library functions can be replaced with new versions without having to relink edit every program that uses the library. (This assumes that the number and type of arguments haven't changed.)
7.8 memory allocation
ISO C specifies three functions for memory allocation:
-
malloc, which allocates a specified number of bytes of memory. The initial value of the memory is indeterminate.
-
calloc, which allocates space for a specified number of objects of a specified size. The space is initialized to all 0 bits.
-
realloc, which increases or decreases the size of a previously allocated area. When the size increases, it may involve moving the previously allocated area somewhere else, to provide the additional room at the end. Also, when the size increases, the initial value of the space between the old contents and the end of the new area is indeterminate.
#include <stdlib.h>
void *malloc(size_t size);
void *calloc(size_t nobj, size_t size);
void *realloc(void *ptr, size_t newsize);
|
| All three return: non-null pointer if OK,NULL on error |
void free(void *ptr);
|
The pointer returned by the three allocation functions is guaranteed to be suitably aligned so that it can be used for any data object. For example, if the most restrictive alignment requirement on a particular system requires thatdoubles must start at memory locations that are multiples of 8, then all pointers returned by these three functions would be so aligned.
Because the threealloc functions return a genericvoid * pointer, if we#include <stdlib.h> (to obtain the function prototypes), we do not explicitly have to cast the pointer returned by these functions when we assign it to a pointer of a different type.
The functionfree causes the space pointed to byptr to be deallocated. This freed space is usually put into a pool of available memory and can be allocated in a later call to one of the threealloc functions.
The realloc function lets us increase or decrease the size of a previously allocated area. (The most common usage is to increase an area.) For example, if we allocate room for 512 elements in an array that we fill in at runtime but find that we need room for more than 512 elements, we can callrealloc. If there is room beyond the end of the existing region for the requested space, thenrealloc doesn't have to move anything; it simply allocates the additional area at the end and returns the same pointer that we passed it. But if there isn't room at the end of the existing region,realloc allocates another area that is large enough, copies the existing 512-element array to the new area, frees the old area, and returns the pointer to the new area.Because the area may move, we shouldn't have any pointers into this area.The allocation routines are usually implemented with the sbrk(2) system call. This system call expands (or contracts) the heap of the process.
注意在分配的内存后面可能仍有一些其他相关数据,所以注意指针不要越过。It is important to realize that most implementations allocate a little more space than is requested and use the additional space for record keeping the size of the allocated block, a pointer to the next allocated block, and the like. This means thatwriting past the end of an allocated area could overwrite this record-keeping information in a later block. These types of errors are often catastrophic, but difficult to find, because theerror may not show up until much later. Also, it is possible to overwrite this record keeping by writing before the start of the allocated area.
Writing past the end or before the beginning of a dynamically-allocated buffer can corrupt more than internal record-keeping information. The memory before and after a dynamically-allocated buffer can potentially be used for other dynamically-allocated objects. These objects can be unrelated to the code corrupting them, making it even more difficult to find the source of the corruption.
Other possible errors that can be fatal are freeing a block that was already freed and callingfree with a pointer that was not obtained from one of the threealloc functions. If a process callsmalloc, but forgets to call free, its memory usage continually increases; this is called leakage. By not callingfree to return unused space, the size of a process's address space slowly increases until no free space is left. During this time, performance can degrade from excess paging overhead.
Alternate Memory Allocators
Many replacements formalloc andfree are available. Some systems already include libraries providing alternate memory allocator implementations. Other systems provide only the standard allocator, leaving it up to software developers to download alternatives, if desired.介绍了一些其他更加安全的封装后的函数。
alloca function
One additional function is also worth mentioning. The functionalloca has the same calling sequence asmalloc; however, instead of allocating memory from the heap, the memory is allocated from the stack frame of the current function. The advantage is that we don't have to free the space; it goes away automatically when the function returns. Thealloca function increases the size of the stack frame. The disadvantage is that some systems can't supportalloca, if it's impossible to increase the size of the stack frame after the function has been called. Nevertheless, many software packages use it, and implementations exist for a wide variety of systems.
7.9 Environment Variables
介绍了一些具体的环境变量以及不同标准对此的不同支持。
As we mentioned earlier, the environment strings are usually of the form
name=value
The UNIX kernel never looks at these strings; their interpretation is up to the various applications. The shells, for example, use numerous environment variables. Some, such asHOME and USER, are set automatically at login, and others are for us to set. We normally set environment variables in a shell start-up file to control the shell's actions. If we set the environment variableMAILPATH, for example, it tells the Bourne shell, GNU Bourne-again shell, and Korn shell where to look for mail.
ISO C defines a function that we can use to fetch values from the environment, but this standard says that the contents of the environment are implementation defined.
#include <stdlib.h>
char *getenv(const char *name);
|
| Returns: pointer tovalue associated withname,NULL if not found |
Note that this function returns a pointer to thevalue of aname=value string. We should always usegetenv to fetch a specific value from the environment, instead of accessingenviron directly.
In addition to fetching the value of an environment variable, sometimes we may want to set an environment variable . (In the next chapter, we'll see that we can affect the environment of only the current process and any child processes that we invoke.We cannot affect the environment of the parent process, which is often a shell. Nevertheless, it is still useful to be able to modify the environment list.)
#include <stdlib.h> int putenv(char *str); int setenv(const char *name, const char *value, |
| All return: 0 if OK, nonzero on error |
It is interesting to examine how these functions must operate when modifying the environment list. RecallFigure 7.6: the environment listthe array of pointers to the actualname=value stringsand the environment strings are typically stored at the top of a process's memory space, above the stack. Deleting a string is simple; we simply find the pointer in the environment list and move all subsequent pointers down one. But adding a string or modifying an existing string is more difficult. The space at the top of the stack cannot be expanded, because it is often at the top of the address space of the process and so can't expand upward; it can't be expanded downward, because all the stack frames below it can't be moved.
-
If we're modifying an existingname:
-
If the size of the newvalue is less than or equal to the size of the existingvalue, we can just copy the new string over the old string.
-
If the size of the newvalue is larger than the old one, however, we mustmalloc to obtain room for the new string, copy the new string to this area, and then replace the old pointer in the environment list forname with the pointer to this allocated area.
-
-
If we're adding a newname, it's more complicated. First, we have to callmalloc to allocate room for thename=value string and copy the string to this area.
-
Then, if it's the first time we've added a newname, we have to callmalloc to obtain room for a new list of pointers. We copy the old environment list to this new area and store a pointer to thename=value string at the end of this list of pointers. We also store a null pointer at the end of this list, of course. Finally, we setenviron to point to this new list of pointers. Note fromFigure 7.6 that if the original environment list was contained above the top of the stack, as is common, then we have moved this list of pointers to the heap. But most of the pointers in this list still point toname=value strings above the top of the stack.
-
If this isn't the first time we've added new strings to the environment list, then we know that we've already allocated room for the list on the heap, so we just callrealloc to allocate room for one more pointer. The pointer to the new name=value string is stored at the end of the list (on top of the previous null pointer), followed by a null pointer.
-
7.10 setjmp and longjmp functions
这里主要介绍了如何在函数的层次调用中,从stack中的程序跳回到另一个之前的程序中的方法。这种使用方法一般是用来处理内层函数错误的。
In C, we can'tgoto a label that's in another function. Instead, we must use thesetjmp andlongjmp functions to perform this type of branching. As we'll see, these two functions are useful for handling error conditions that occur in a deeply nested function call.
The solution to this problem is to use a nonlocalgoto: thesetjmp andlongjmp functions. The adjective nonlocal is because we're not doing a normal Cgoto statement within a function; instead, we're branching back through the call frames to a function that is in the call path of the current function.
#include <setjmp.h>
int setjmp(jmp_buf env);
|
| Returns: 0 if called directly, nonzero if returning from a call tolongjmp |
void longjmp(jmp_buf env, int val); |
We callsetjmp from the location that we want to return to, which in this example is in themain function. In this case,setjmp returns 0 because we called it directly. In the call tosetjmp, the argumentenv is of the special typejmp_buf. This data type is some form of array that is capable of holding all the information required to restore the status of the stack to the state when we calllongjmp. Normally, theenv variable is a global variable, since we'll need to reference it from another function.
7.11 getrlimit and setrlimit functions
Every process has a set of resource limits, some of which can be queried and changed by thegeTRlimit andsetrlimit functions.
#include <sys/resource.h> int getrlimit(int resource, struct rlimit *rlptr); int setrlimit(int resource, const struct rlimit |
| Both return: 0 if OK, nonzero on error |
Each call to these two functions specifies a singleresource and a pointer to the following structure:
struct rlimit {
rlim_t rlim_cur; /* soft limit: current limit */
rlim_t rlim_max; /* hard limit: maximum value for rlim_cur */
};
Three rules govern the changing of the resource limits.
-
A process can change its soft limit to a value less than or equal to its hard limit.
-
A process can lower its hard limit to a value greater than or equal to its soft limit. This lowering of the hard limit is irreversible for normal users.
-
Only a superuser process can raise a hard limit.
An infinite limit is specified by the constantRLIM_INFINITY.
(接下来介绍了一些资源参数名以及相关的例子)从编程者的角度看,这有点像是对一个具体程序的一些配置,就类似于在windows系统VS中通过项目的配置进行一些,如堆栈的大小等等设置。7.12 summary
Understanding the environment of a C program in a UNIX system's environment is a prerequisite to understanding the process control features of the UNIX System. In this chapter, we've looked at how a process is started, how it can terminate, and how it's passed an argument list and an environment. Although both are uninterpreted by the kernel, it is the kernel that passes both from the caller ofexec to the new process.
We've also examined the typical memory layout of a C program and how a process can dynamically allocate and free memory. It is worthwhile to look in detail at the functions available for manipulating the environment, since they involve memory allocation. The functionssetjmp andlongjmp were presented, providing a way to perform nonlocal branching within a process. We finished the chapter by describing the resource limits that various implementations provide.
chapter 8 Process control
8.1 Intro
本章开始全面的介绍process真正的运行完整过程。We now turn to the process control provided by the UNIX System. This includes the creation of new processes, program execution, and process termination. We also look at the various IDs that are the property of the processreal, effective, and saved; user and group IDsand how they're affected by the process control primitives. Interpreter files and thesystem function are also covered. We conclude the chapter by looking at the process accounting provided by most UNIX systems. This lets us look at the process control functions from a different perspective.
8.2 Process identifiers
Every process has a unique process ID, a non-negative integer. Because the process ID is the only well-known identifier of a process that is always unique, it is often used as a piece of other identifiers, to guarantee uniqueness. For example, applications sometimes include the process ID as part of a filename in an attempt to generate unique filenames.
Although unique, process IDs are reused. As processes terminate, their IDs become candidates for reuse. Most UNIX systems implement algorithms to delay reuse, however, so that newly created processes are assigned IDs different from those used by processes that terminated recently. This prevents a new process from being mistaken for the previous process to have used the same ID.
There are some special processes,but the details differ from implementation to implementation. Process ID 0 is usually the scheduler process and is often known as theswapper. No program on disk corresponds to this process, which is part of the kernel and is known as a system process. Process ID 1 is usually theinit process and is invoked by the kernel at the end of the bootstrap procedure. The program file for this process was/etc/init in older versions of the UNIX System and is/sbin/init in newer versions. This process is responsible for bringing up a UNIX system after the kernel has been bootstrapped.init usually reads the system-dependent initialization filesthe/etc/rc* files or/etc/inittab and the files in /etc/init.dand brings the system to a certain state, such as multiuser. Theinit process never dies. It is a normal user process, not a system process within the kernel, like the swapper, although it does run with superuser privileges. Later in this chapter, we'll see howinit becomes the parent process of any orphaned child process.
Each UNIX System implementation has its own set of kernel processes that provide operating system services. For example, on some virtual memory implementations of the UNIX System, process ID 2 is thepagedaemon. This process is responsible for supporting the paging of the virtual memory system.
#include <unistd.h>
pid_t getpid(void);
|
| Returns: process ID of calling process |
pid_t getppid(void); |
| Returns: parent process ID of calling process |
uid_t getuid(void); |
| Returns: real user ID of calling process |
uid_t geteuid(void); |
| Returns: effective user ID of calling process |
gid_t getgid(void); |
| Returns: real group ID of calling process |
gid_t getegid(void); |
| Returns: effective group ID of calling process |
8.3 fork function
#include <unistd.h> pid_t fork(void); |
| Returns: 0 in child, process ID of child in parent, 1 on error |
The new process created byfork is called thechild process. This function is called once but returns twice. The only difference in the returns is that the return value in the child is 0, whereas the return value in the parent is the process ID of the new child. The reason the child's process ID is returned to the parent is that a process can have more than one child, and there is no function that allows a process to obtain the process IDs of its children. The reason fork returns 0 to the child is that a process can have only a single parent, and the child can always callgetppid to obtain the process ID of its parent. (Process ID 0 is reserved for use by the kernel, so it's not possible for 0 to be the process ID of a child.)
Both the child and the parent continue executing with the instruction that follows the call tofork. The child is a copy of the parent. For example, the child gets a copy of the parent's data space, heap, and stack. Note that this is a copy for the child; the parent and the child do not share these portions of memory. The parent and the child share the text segmentCurrent implementations don't perform a complete copy of the parent's data, stack, and heap, since afork is often followed by anexec. Instead, a technique called copy-on-write (COW) is used. These regions are shared by the parent and the child and have their protection changed by the kernel to read-only. If either process tries to modify these regions, the kernel then makes a copy of that piece of memory only, typically a "page" in a virtual memory system.
In general, we never know whether the child starts executing before the parent or vice versa. This depends on the scheduling algorithm used by the kernel. If it's required that the child and parent synchronize, some form of interprocess communication is required.
When we write to standard output, we subtract 1 from the size ofbuf to avoid writing the terminating null byte. Althoughstrlen will calculate the length of a string not including the terminating null byte,sizeof calculates the size of the buffer, which does include the terminating null byte. Another difference is that usingstrlen requires a function call, whereas sizeof calculates the buffer length at compile time, as the buffer is initialized with a known string, and its size is fixed.
Note the interaction of fork with the I/O functions in the program in Figure 8.1. Recall from Chapter 3 that thewrite function is not buffered. Because write is called before thefork, its data is written once to standard output. The standard I/O library, however, is buffered. Recall from Section 5.12 that standard output is line buffered if it's connected to a terminal device; otherwise, it's fully buffered. When we run the program interactively, we get only a single copy of the printf line, because the standard output buffer is flushed by the newline. But when we redirect standard output to a file, we get two copies of the printf line. In this second case, the printf before the fork is called once, but the line remains in the buffer when fork is called. This buffer is then copied into the child when the parent's data space is copied to the child. Both the parent and the child now have a standard I/O buffer with this line in it. The second printf, right before the exit, just appends its data to the existing buffer. When each process terminates, its copy of the buffer is finally flushed.one characteristic offork is thatall file descriptors that are open in the parent are duplicated in the child. We say "duplicated" because it's as if thedup function had been called for each descriptor. The parent and the child share a file table entry for every open descriptor (recallFigure 3.8).
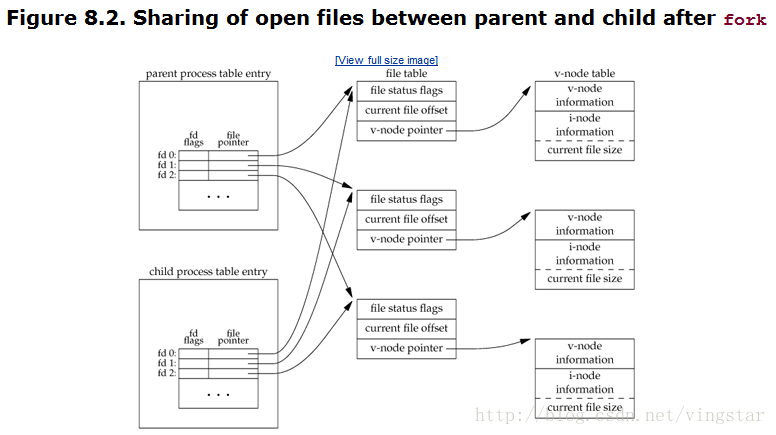
It is important that the parent and the child share the same file offset. Consider a process thatforks a child, thenwaits for the child to complete. Assume that both processes write to standard output as part of their normal processing. If the parent has its standard output redirected (by a shell, perhaps) it is essential that the parent's file offset be updated by the child when the child writes to standard output. In this case, the child can write to standard output while the parent iswaiting for it; on completion of the child, the parent can continue writing to standard output, knowing that its output will beappendedto whatever the child wrote. If the parent and the child did not share the same file offset, this type of interaction would be more difficult to accomplish and would require explicit actions by the parent.
If both parent and child write to the same descriptor, without any form of synchronization, such as having the parentwait for the child, their output will be intermixed (assuming it's a descriptor that was open before thefork).
There are two normal cases for handling the descriptors after afork.
-
The parent waits for the child to complete. In this case, the parent does not need to do anything with its descriptors. When the child terminates, any of the shared descriptors that the child read from or wrote to will have their file offsets updated accordingly.
-
Both the parent and the child go their own ways. Here, after thefork, the parent closes the descriptors that it doesn't need, and the child does the same thing. This way, neither interferes with the other's open descriptors. This scenario is often the case with network servers.
Besides the open files, there are numerous other properties of the parent that are inherited by the child:
-
Real user ID, real group ID, effective user ID, effective group ID
-
Supplementary group IDs
-
Session ID
-
Controlling terminal
-
The set-user-ID and set-group-ID flags
-
Current working directory
-
Root directory
-
File mode creation mask
-
Signal mask and dispositions
-
The close-on-exec flag for any open file descriptors
-
Environment
-
Attached shared memory segments
-
Memory mappings
-
Resource limits
The differences between the parent and child are
-
The return value from fork
-
The process IDs are different
-
The two processes have different parent process IDs: the parent process ID of the child is the parent; the parent process ID of the parent doesn't change
-
The child's tms_utime, tms_stime, tms_cutime, andtms_cstime values are set to 0
-
File locks set by the parent are not inherited by the child
-
Pending alarms are cleared for the child
-
The set of pending signals for the child is set to the empty set
There are two uses for fork:
-
When a process wants to duplicate itself so that the parent and child can each execute different sections of code at the same time. This is common for network serversthe parent waits for a service request from a client. When the request arrives, the parent calls fork and lets the child handle the request. The parent goes back to waiting for the next service request to arrive.
-
When a process wants to execute a different program. This is common for shells. In this case, the child does anexec (which we describe inSection 8.10) right after it returns from thefork.
Another difference between the two functions is that vfork guarantees that the child runs first, until the child callsexec orexit. When the child calls either of these functions, the parent resumes. (This can lead to deadlock if the child depends on further actions of the parent before calling either of these two functions.)
8.4 vfork function
The function vfork has the same calling sequence and same return values asfork. But the semantics of the two functions differ.
该函数的特点是子进程直接在父进程的地址空间中运行,相当于接管了程序的运行。The vfork function is intended to create a new process when the purpose of the new process is to exec a new program (step 2 at the end of the previous section). The vfork function creates the new process, just like fork, without copying the address space of the parent into the child, as the child won't reference that address space; the child simply callsexec (or exit) right after the vfork. Instead, while the child is running and until it calls eitherexec orexit, the child runs in the address space of the parent.This optimization provides an efficiency gain on some paged virtual-memory implementations of the UNIX System. (As we mentioned in the previous section, implementations use copy-on-write to improve the efficiency of a fork followed by an exec, but no copying is still faster than some copying.)Another difference between the two functions is thatvfork guarantees that the child runs first, until the child callsexec orexit. When the child calls either of these functions, the parent resumes. (This can lead to deadlock if the child depends on further actions of the parent before calling either of these two functions.)
#include "apue.h"
int glob = 6; /* external variable in initialized data */
int
main(void)
{
int var; /* automatic variable on the stack */
pid_t pid;
var = 88;
printf("before vfork\n"); /* we don't flush stdio */
if ((pid = vfork()) < 0) {
err_sys("vfork error");
} else if (pid == 0) { /* child */
glob++; /* modify parent's variables */
var++;
_exit(0); /* child terminates */
}
/*
* Parent continues here.
*/
printf("pid = %d, glob = %d, var = %d\n", getpid(), glob, var);
exit(0);
}
Running this program gives us
$ ./a.out
before vfork
pid = 29039, glob = 7, var = 89
8.5 exit function
Regardless of how a process terminates, the same code in the kernel is eventually executed. This kernel code closes all the open descriptors for the process, releases the memory that it was using, and the like.
For any of the preceding cases, we want the terminating process to be able to notify its parent how it terminated. For the three exit functions (exit,_exit, and_Exit), this is done by passing an exit statusas the argument to the function. In the case of an abnormal termination, however,the kernel, not the process, generates atermination status to indicate the reason for the abnormal termination. In any case, the parent of the process can obtain the termination status from either thewait or thewaitpid function (described in the next section).
Note that we differentiate between the exit status, which is the argument to one of the three exit functions or the return value frommain, and the termination status.The exit status is converted into a termination status by the kernel when_exit is finally called (recallFigure 7.2). Figure 8.4 describes the various ways the parent can examine the termination status of a child. If the child terminated normally, the parent can obtain the exit status of the child.
When we described the fork function, it was obvious that the child has a parent process after the call tofork. Now we're talking about returning a termination status to the parent. Butwhat happens if the parent terminates before the child? The answer is that theinit process becomes the parent process of any process whose parent terminates. We say that the process has been inherited byinit. What normally happens is that whenever a process terminates, the kernel goes through all active processes to see whether the terminating process is the parent of any process that still exists. If so, the parent process ID of the surviving process is changed to be 1 (the process ID ofinit). This way, we're guaranteed that every process has a parent.
Another condition we have to worry about is when a child terminates before its parent.If the child completely disappeared, the parent wouldn't be able to fetch its termination status when and if the parent were finally ready to check if the child had terminated.The kernel keeps a small amount of information for every terminating process, so that the information is available when the parent of the terminating process callswait or waitpid. Minimally, this information consists of the process ID, the termination status of the process, and the amount of CPU time taken by the process. The kernel can discard all the memory used by the process and close its open files.
In UNIX System terminology,a process that has terminated, but whose parent has not yet waited for it, is called azombie. Theps(1) command prints the state of a zombie process asZ. If we write a long-running program thatforks many child processes, they become zombies unless we wait for them and fetch their termination status.
Does it become a zombie? The answer is "no," becauseinit is written so that whenever one of its children terminates,init calls one of thewait functions to fetch the termination status. By doing this,init prevents the system from being clogged by zombies. When we say "one ofinit's children," we mean either a process thatinit generates directly (such asgetty, which we describe in Section 9.2) or a process whose parent has terminated and has been subsequently inherited byinit.
When a process terminates, either normally or abnormally, the kernel notifies the parent by sending theSIGCHLD signal to the parent. Because the termination of a child is an asynchronous eventit can happen at any time while the parent is runningthis signal is the asynchronous notification from the kernel to the parent. The parent can choose to ignore this signal, or it can provide a function that is called when the signal occurs: a signal handler. The default action for this signal is to be ignored. We describe these options inChapter 10. For now, we need to be aware that a process that callswait orwaitpid can
-
Block, if all of its children are still running
-
Return immediately with the termination status of a child, if a child has terminated and is waiting for its termination status to be fetched
-
Return immediately with an error, if it doesn't have any child processes
If the process is callingwait because it received theSIGCHLD signal, we expect wait to return immediately. But if we call it at any random point in time, it can block.
#include <sys/wait.h>
pid_t wait(int *statloc);
pid_t waitpid(pid_t pid, int *statloc, int options); |
| Both return: process ID if OK, 0 (see later), or 1 on error |
The differences between these two functions are as follows.
-
The wait function can block the caller until a child process terminates, whereaswaitpid has an option that prevents it from blocking.
-
The waitpid function doesn't wait for the child that terminates first; it has a number of options that control which process it waits for.
If a child has already terminated and is a zombie,wait returns immediately with that child's status. Otherwise, it blocks the caller until a child terminates. If the caller blocks and has multiple children,wait returns when one terminates. We can always tell which child terminated, because the process ID is returned by the function.
For both functions, the argumentstatloc is a pointer to an integer. If this argument is not a null pointer, the termination status of the terminated process is stored in the location pointed to by the argument. If we don't care about the termination status, we simply pass a null pointer as this argument.