迅投指数计算规则的说明
指数数据计算规则说明
迅投指数的计算规则为
- 普通代码上市超过20个交易日后加入计算,债券为5个交易日。
- 涨停打开超过3个交易日后加入计算。
- 复牌股涨跌幅超25%不加入计算。
- 指数成分等权进行计算。
#获取沪深指数数据
#获取指数代码列表
提示
为了获取指数合约列表,首先需要使用函数get_sector_list来获取需要查询的指数索引。具体的索引信息可以通过键入您感兴趣的索引名(例如:"沪深指数"或"上证指数")等获得。接下来,通过调用函数get_stock_list_in_sector并输入指定的索引名称,你就可以返回相应的指数合约列表。这部分合约列表包含了所有与特定指数相关的现有合约,这对于投资者在进行投资策略分析和决策时具有重要参考价值。
调用方法
python
# coding=utf-8
from xtquant import xtdata
# 获取板块列表
xtdata.get_sector_list()
# 根据板块列表找查询指数索引名称
xtdata.get_stock_list_in_sector(sector_name)
参数

返回
- 列表,包含指定板块成分代码。
示例返回值(板块列表)返回值(板块数据)
# coding=utf-8
from xtquant import xtdata
# 获取板块列表
ret_sector_list = xtdata.get_sector_list()
print(f'获取板块目录: {ret_sector_list}')
# 根据板块列表找查询指数索引名称
ret_sector_data = xtdata.get_stock_list_in_sector('沪深指数')
print(f'获取板块合约: {ret_sector_data}')
#获取指数成份股权重
如果你的本地环境中缺少合约权重数据,那么可以先通过函数download_index_weight进行数据下载。下载后,再使用get_index_weight函数来取得相关指数下各个合约的权重信息。这两步操作能帮助你获得详尽而全面的权重数据,进一步增强你对投资环境的理解和掌握,帮助做出更明智的投资决策。
调用方法
python
# coding=utf-8
from xtquant import xtdata
# 下载权重相关信息
xtdata.download_index_weight()
# 获取权重相关信息
xtdata.get_index_weight(index_code)
参数
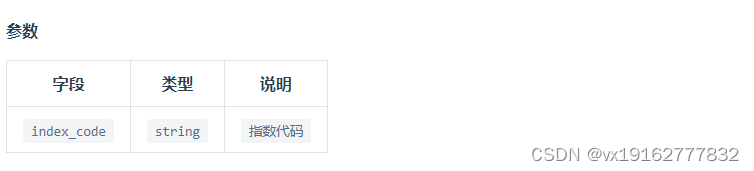
- index_code:字符串格式,指数代码,例如 000300.SH
返回
- 字典, key为成分代码, value为权重
示例返回值
# coding=utf-8
from xtquant import xtdata
# 下载权重相关信息
xtdata.download_index_weight()
# 获取权重相关信息
ret_weight_data = xtdata.get_index_weight('000300.SH')
print(ret_weight_data)
#获取指数行情数据
获取行情数据,最新行情需要数据订阅subscribe_quote。如果您需要获取历史数据,可以使用download_history_data函数下载相关数据,然后使用get_market_data_ex函数提取所需的信息。这样,使用者就能获得最新和详细的合约最新数据,有助于做出更精准的投资决策。
调用方法
python
# coding=utf-8
from xtquant import xtdata
# 订阅指定合约最新行情
xtdata.subscribe_quote(stock_code, period='', start_time='', end_time='', count=0, callback=None)
# 下载指定合约历史行情
xtdata.download_history_data(stock_code, period, start_time='', end_time='')
# 获取指定合约历史行情
xtdata.get_market_data_ex(field_list = [], stock_list = [], period = '', start_time = '', end_time = '', count = -1, dividend_type = 'none', fill_data = True)
参数
- xtdata.subscribe_quote
| 字段 | 类型 | 说明 |
|---|---|---|
stock_code | str | 股票代码 |
start_time | str | 开始时间格式YYYYMMDD/YYYYMMDDhhmmss |
end_time | str | 结束时间 |
count | int | 数量 -1全部/n: 从结束时间向前数n个 |
period | str | 周期 分笔"tick" 分钟线"1m"/"5m" 日线"1d" |
- xtdata.get_market_data_ex
| 参数名称 | 类型 | 描述 |
|---|---|---|
field_list | list | 表示所有字段。不同的数据周期,取值范围有所不同。 |
stock_list | list | 合约代码列表 |
period | str | 数据周期,默认是当前主图周期。可选值如下: 'tick' (分笔线), '1d' (日线), '1m' (1分钟线), '5m' (5分钟线), '15m' (15分钟线), 'l2quote' (Level2行情快照), 'l2quoteaux' (Level2行情快照补充), 'l2order' (Level2逐笔委托), 'l2transaction' (Level2逐笔成交),'l2transactioncount' (Level2大单统计), 'l2orderqueue' (Level2委买委卖队列) |
start_time | str | 开始时间。为空时默认为最早时间。时间格式为'20201231'或'20201231093000' |
end_time | str | 结束时间。为空时默认为最新时间。时间格式为'20201231'或'20201231235959' |
count | int | 数据最大个数。-1表示不做个数限制 |
dividend_type | str | 复权方式,默认是当前主图复权方式。可选值包括: 'none' (不复权), 'front'(前复权), 'back' (后复权), 'front_ratio' (等比前复权), 'back_ratio' (等比后复权) |
fill_data | bool | 停牌填充方式 |
返回值
- period为
1m5m1dK线周期时- 返回dict { field1 : value1, field2 : value2, ... }
- value1, value2, ... :pd.DataFrame 数据集,index为stock_list,columns为time_list
- 各字段对应的DataFrame维度相同、索引相同
- period为
tick分笔周期时- 返回dict { stock1 : value1, stock2 : value2, ... }
- stock1, stock2, ... :合约代码
- value1, value2, ... :np.ndarray 数据集,按数据时间戳
time增序排列
示例返回值
# coding=utf-8
from xtquant import xtdata
# 获取迅投板块指数代码列表
xt_sector_index_list = xtdata.get_stock_list_in_sector("迅投一级行业板块加权指数")
# 获取迅投板块指数合约信息
xt_sector_index_info = xtdata.get_instrument_detail(xt_sector_index_list[0])
xt_sector_index = xt_sector_index_list[0]
print(xt_sector_index_info)
# 订阅合约数据
xtdata.subscribe_quote(xt_sector_index, period='1d', start_time='', end_time='20231026', count=1, callback=None)
# 下载指定合约历史行情
xtdata.download_history_data(xt_sector_index, '1d', '20231020', '20231026')
# 获取指定合约历史行情
day_data = xtdata.get_market_data_ex(field_list=[], stock_list=[xt_sector_index], period='1d', start_time='',end_time='20231026', count=5, dividend_type='none', fill_data=True)
print(day_data)