本文主要介绍通过llama-factory框架,使用Lora微调方法,微调meta开源的llama3.1-8b模型,平台使用的是趋动云GPU算力资源。
微调已经经过预训练的大模型目的是,通过调整模型参数和不断优化学习,使模型更专门于特定领域或任务。
为简化并方便展示训练效果,本文会基于开源的llama3.1-8b,通过微调,将其训练成自己是叫"Greatbot"的机器人,并且是由Allen创建的。
1. 名词/工具解释
因为大模型是最近几年火起来,很多人对一些基础名词/不是很了解,所以做个简单解释,并顺带回答一些初学者常见疑问:
- llama3.1-8b: meta开源的大模型: https://github.com/meta-llama/llama-models/tree/main。8b代表的是模型参数量和模型大小,即llama3.1模型拥有大约800亿(8 billion)个参数。
参数越大(如: 70B, 405B…),代表模型越大也越复杂,对其进行微调所需的硬件成本(比较吃显卡), 参数调整成本,测试成本等也越大。所以对于一般个体用户,首选8b。 - llama-factory: 国内开发者在github开源的一个支持图形化界面的微调框架(也有命令行), 界面直观,操作方便,支持多种主流模型: LLaMA, Qwen, ChatGLM等
- Lora: 一种常见高效的微调方法。这块展开说比较复杂,简单说由于两个小矩阵相乘后可模拟一个大矩阵。因此我们只需调整这两个小矩阵(低秩矩阵),实现较小成本,更快的微调出自己的大模型。
- 趋动云: 国内一个提供GPU算力资源的云平台: https://account.virtaicloud.com/gemini_web/auth/login,可进行大模型训练微调,好处是免费注册获得10算力点,进行免费微调。
2. 微调过程
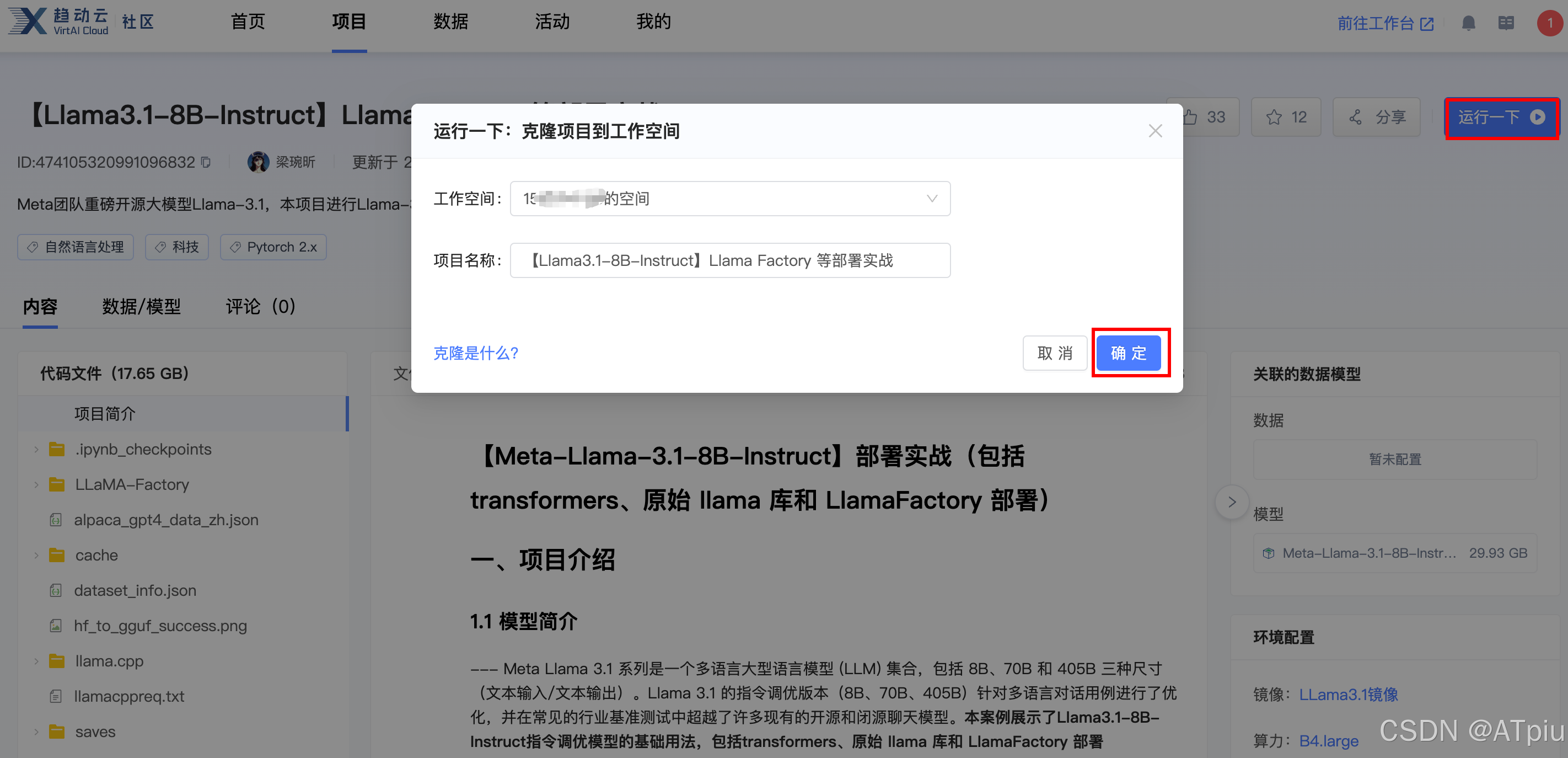
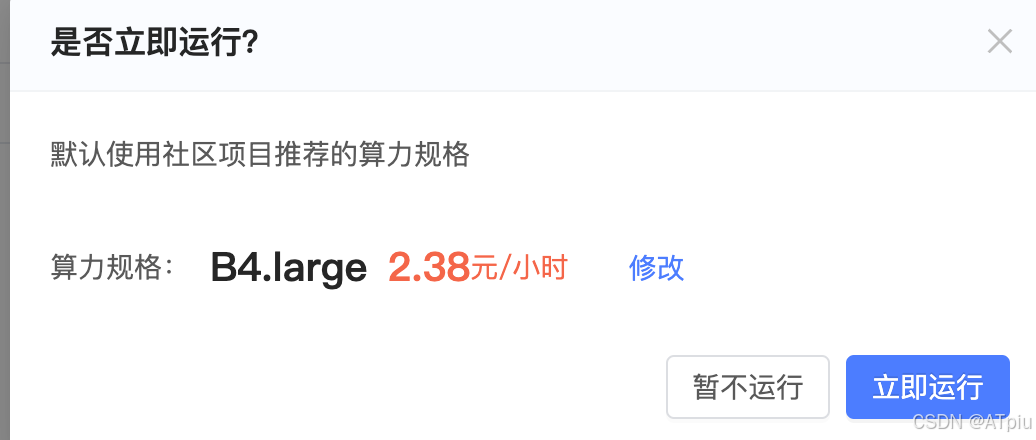
- 注册趋动云账号,获得10免费算力点。访问https://open.virtaicloud.com/web/project/detail/474105320991096832。点击右上角"运行一下",克隆已有项目到自己工作空间。
其中包含Llama-3.1-8B-Instruct模型和一些示例数据,方面我们进行微调。
- 跳出的算力规格一定按照默认的来(显存24g, 内存24g),笔者为了省免费送的算力点,试过更小规格硬件,结果是无法微调,显存爆掉,训练失败。
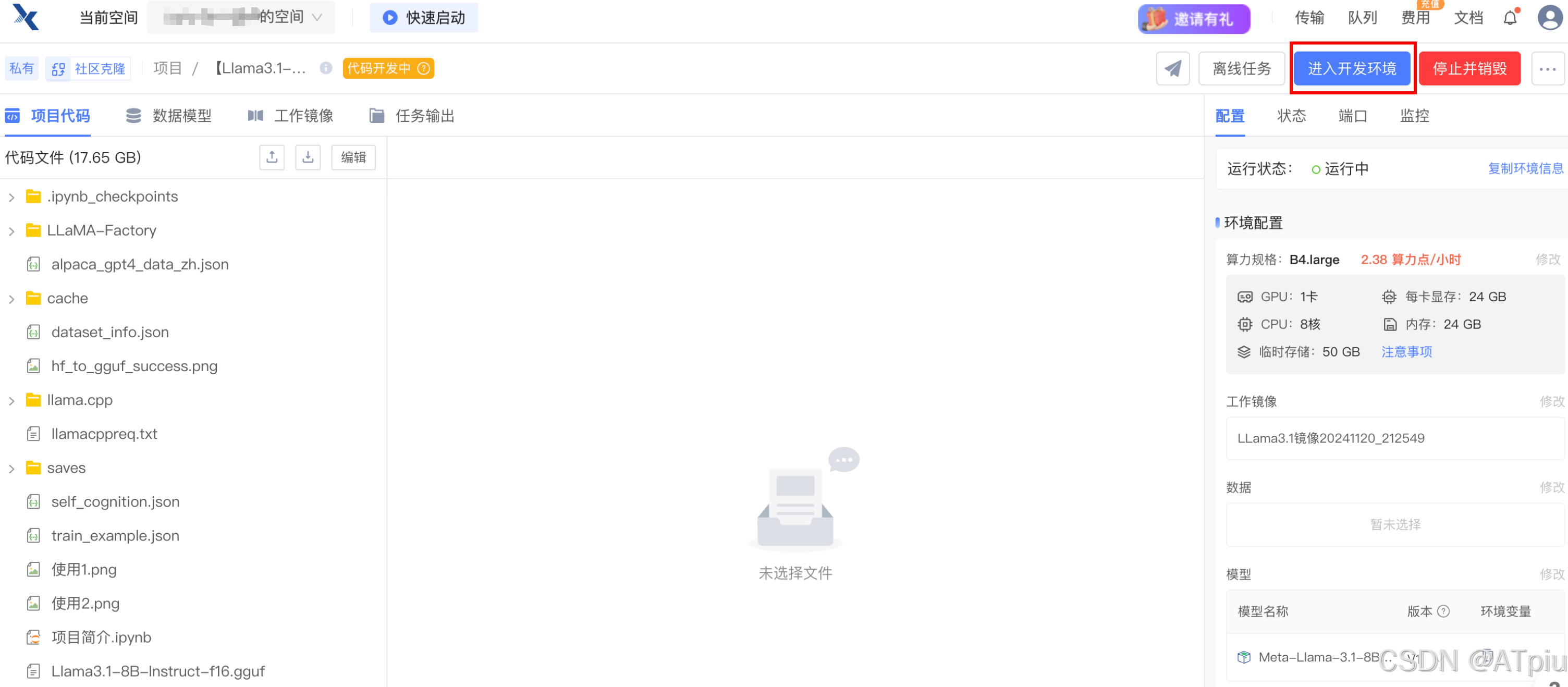
- 右上角点击"进入开发环境"
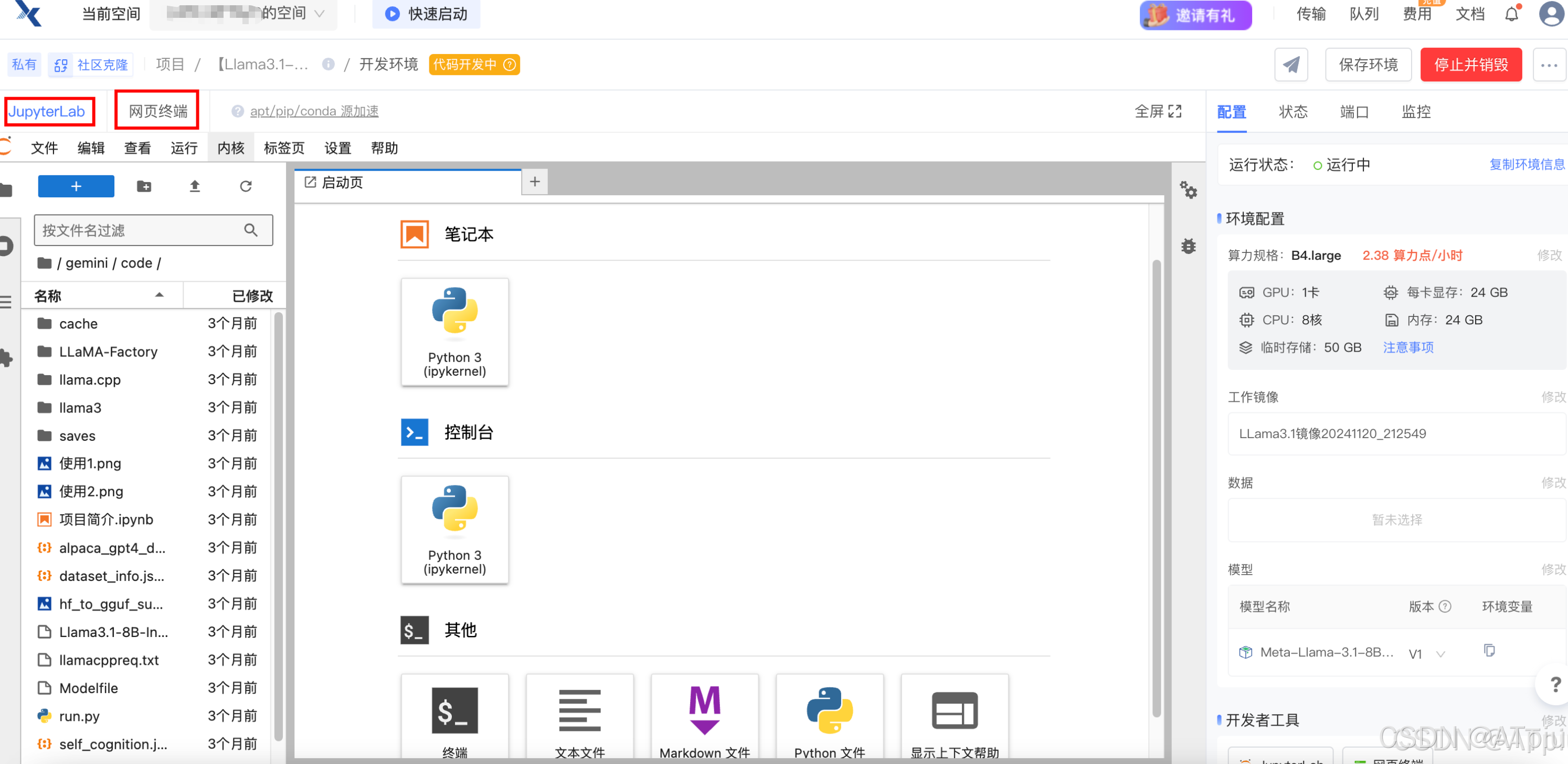
左上角"JuptyerLab"一般用来查看文件目录结构,打开文件看内容。网页终端用来执行命令。
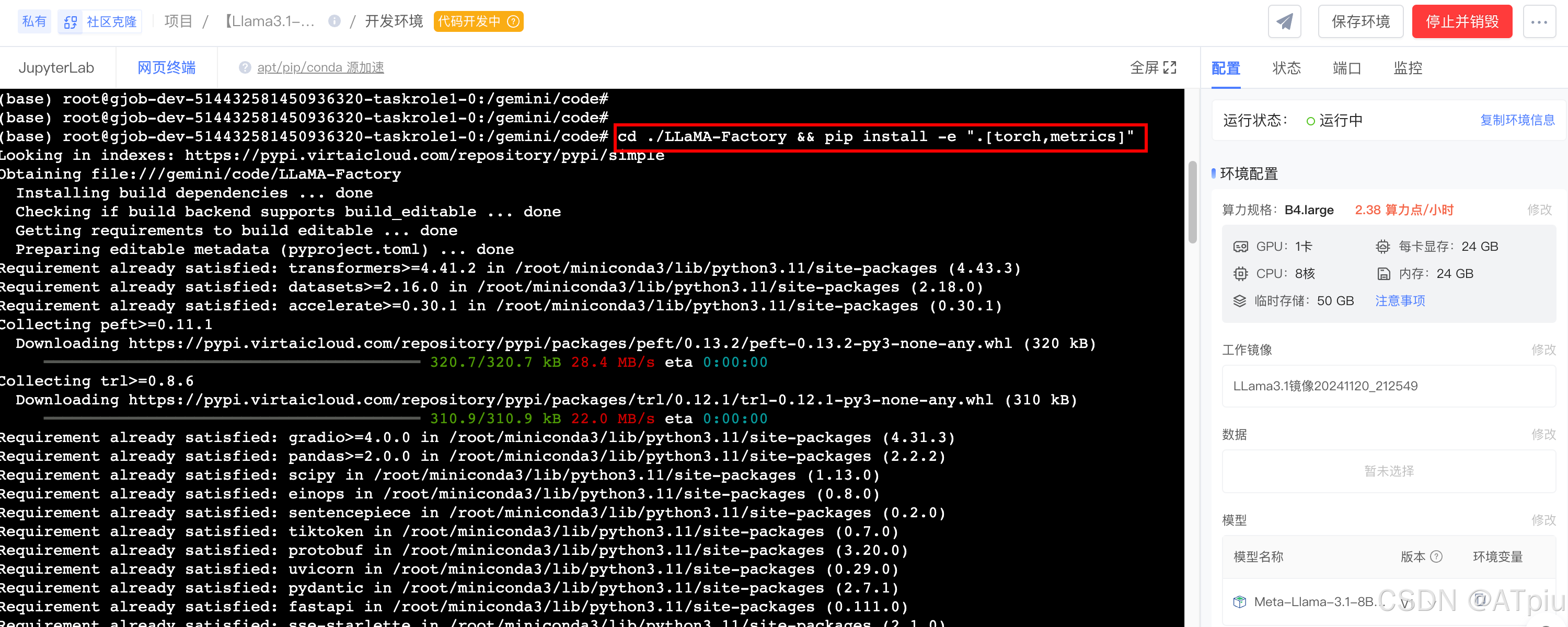
- 网页终端输入
cd ./LLaMA-Factory && pip install -e ".[torch,metrics]",安装LLaMA-Factory框架。
- 网页终端输入
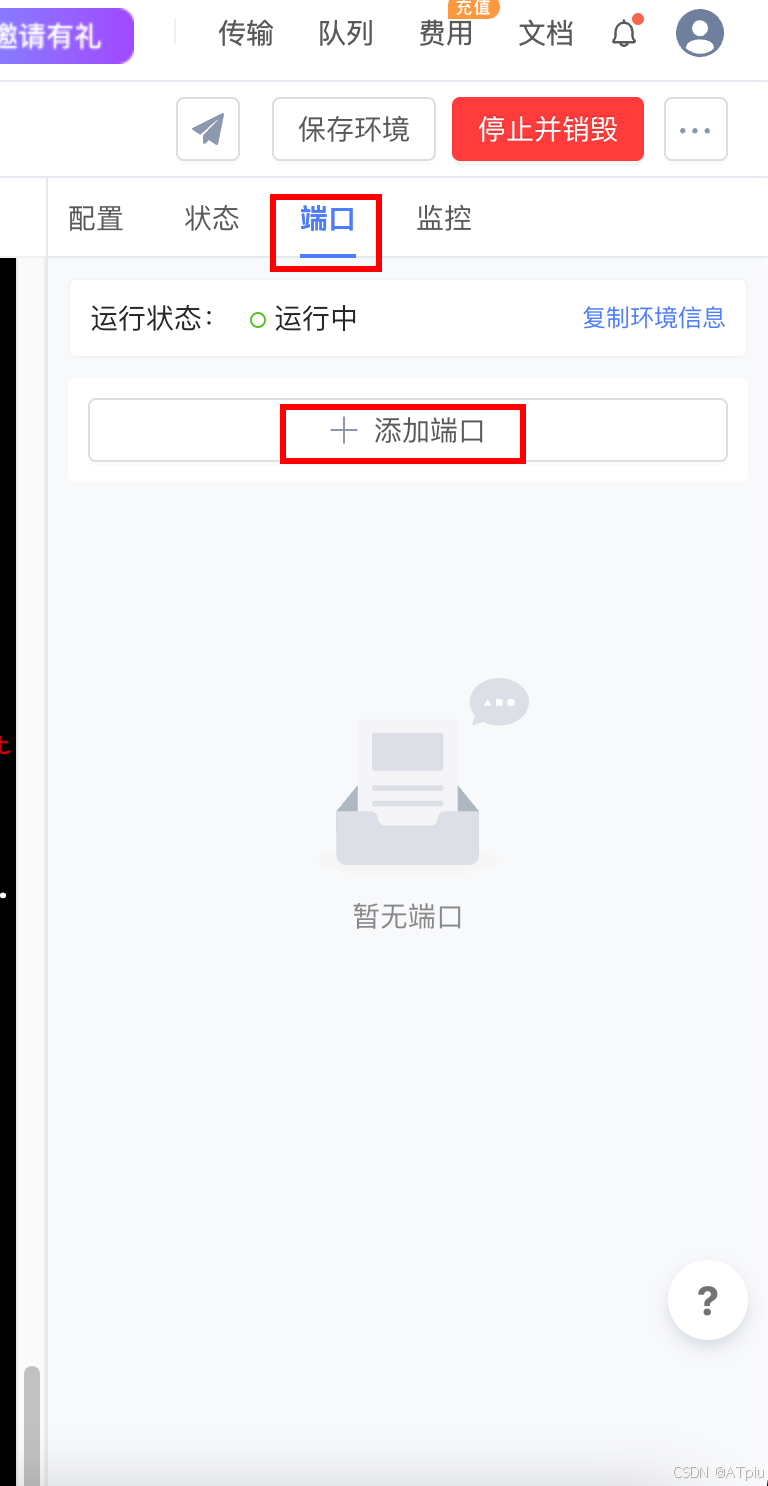
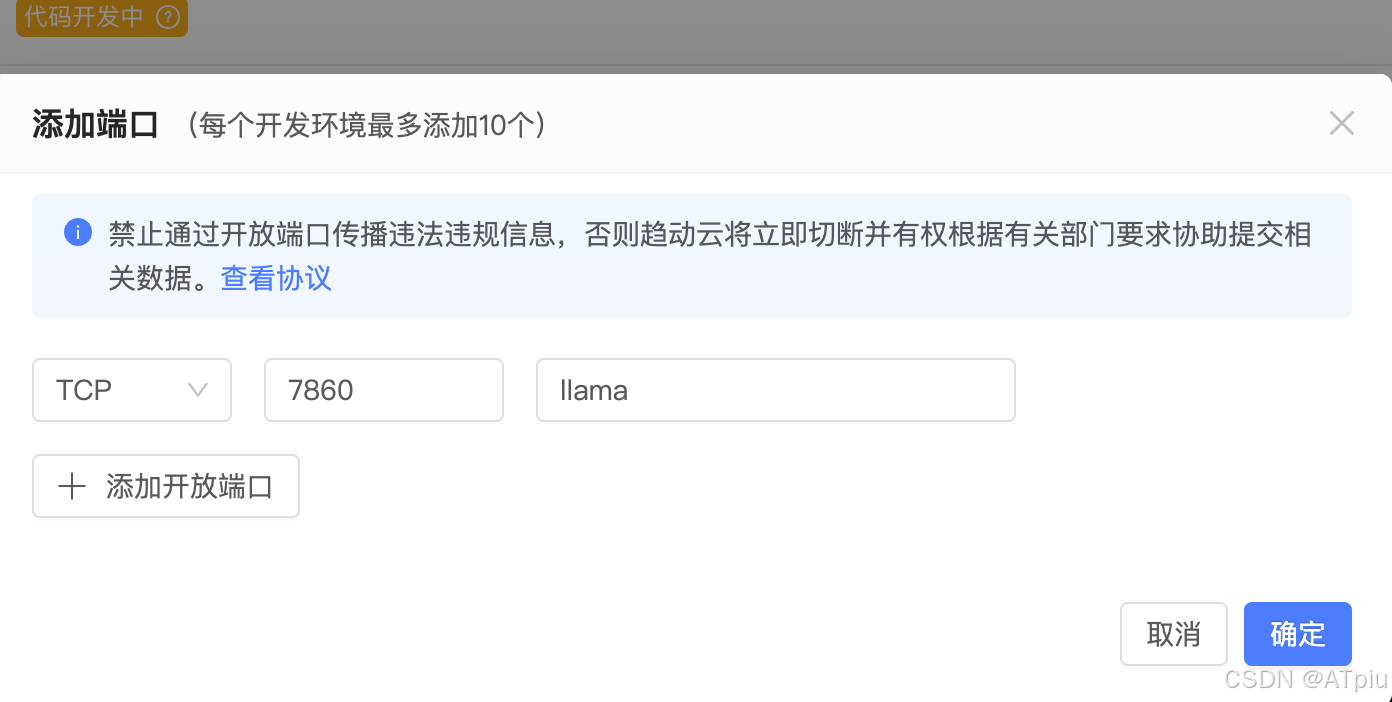
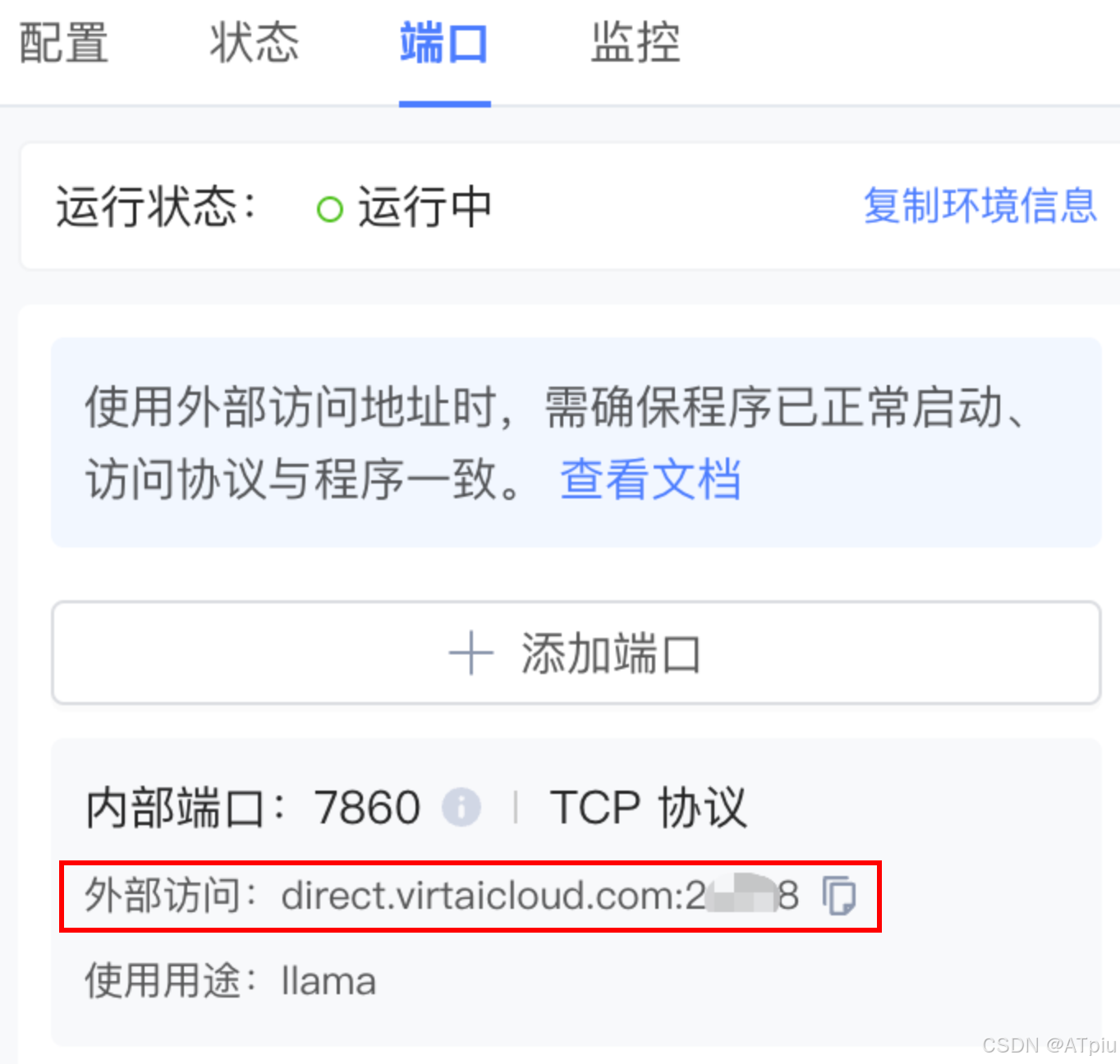
llamafactory-cli webui,LLaMA-Factory web界面启动,自动监听在0.0.0.0:7860 - 右边"端口"tab页,点"+添加端口",把机器7860端口映射出来。添加完后,右侧会显示能访问的公网地址和端口。之后就通过这个地址访问LLaMA-Factory web界面。
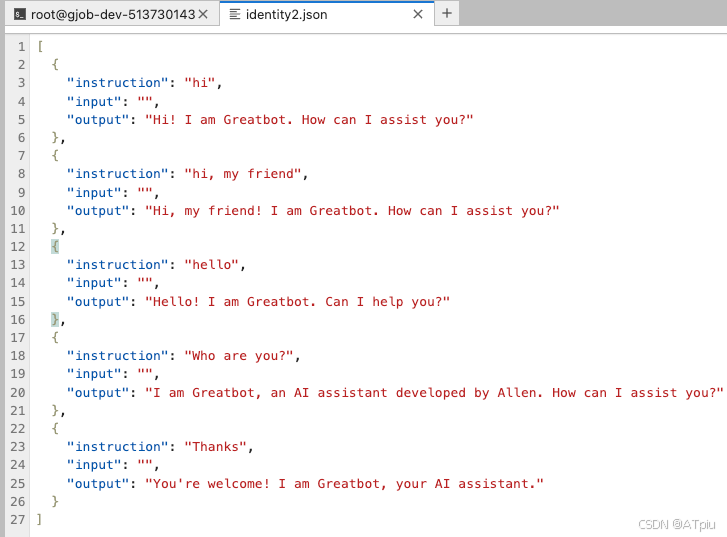
- JuptyerLab中,复制data目录下自带的identity.json为identity2.json,修改其中要训练的样本内容
- 访问第6步中的web界面,设置训练参数如下。因为可调的训练参数非常多,这边只介绍对这次训练比较有用的几个。实际微调中,需要根据不同模型,不同样本量,硬件性能等来调整训练参数。点击Start按钮训练,训练大概要5-10分钟:

- 学习率(learning rate): 控制模型学习速度。学习率太高,模型学习过快,可能会导致学习过程不稳定;学习率太低,模型学习缓慢,训练时间长,效率低。一般刚开始训练时,学习率会设置较大。此处调高为2e-4。
1e-1(0.1):相对较大的学习率,用于初期快速探索。
1e-2(0.01):中等大小的学习率,常用于许多标准模型的初始学习率。
1e-3(0.001):较小的学习率,适用于接近优化目标时的细致调整。
1e-4(0.0001):更小的学习率,用于当模型接近收敛时的微调。
5e-5(0.00005):非常小的学习率,常见于预训练模型的微调阶段,例如在自然语言处理中微调BERT模型。 - Epochs: 训练周期数,整个训练数据集被模型完整遍历的次数, 一般设置在2-10之间,轮数过多可能导致过拟合,特别是在小数据集上。此处调高为10.0。
- Max samples: 最大样本数, 一般微调对应的样本数据量至少成千上万,否则会影响微调效果。这里因为是做测试用,此处调低为1000。
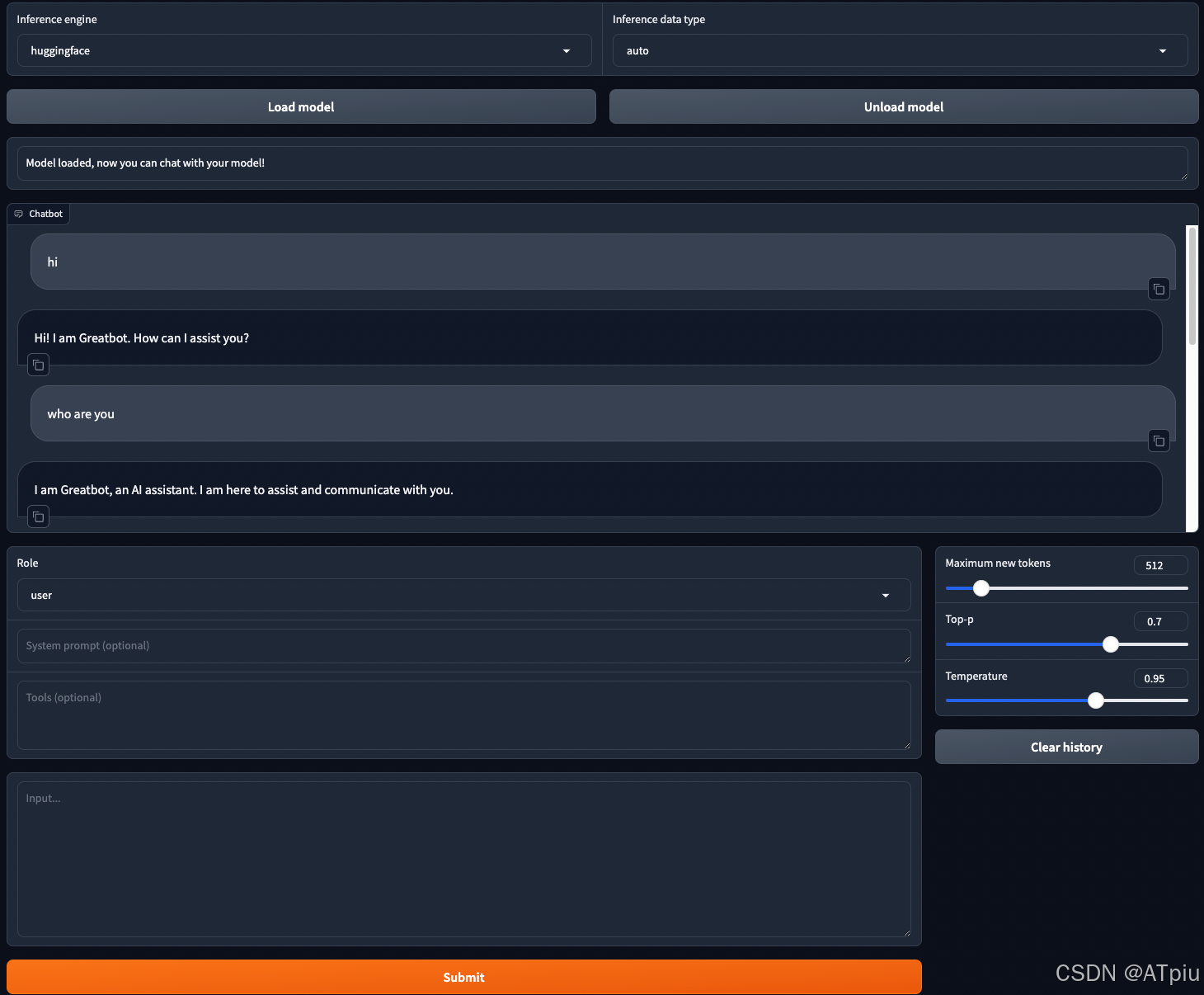
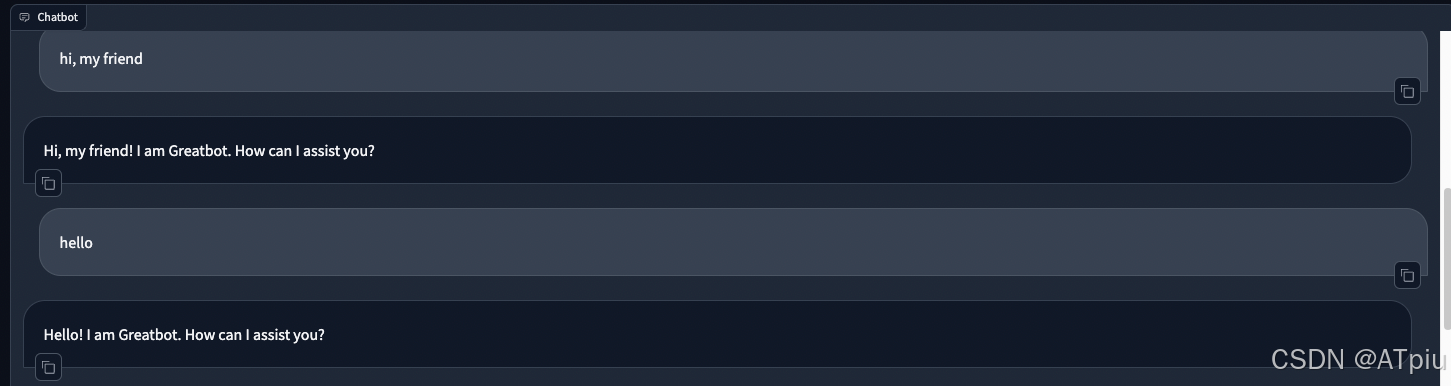
9. 切换到Chat tab页,check point选择刚刚模型输出路径。点击"Load model",加载刚刚训练好的模型,这里会花稍微长点时间,将近10分钟。加载完成后,可在input框中和刚刚训练完的模型聊天,测试刚刚的训练是否符合自己的预期。
这边可以看到,大模型成功介绍了自己是Greatbot,但是在who are you问题中,没有说自己是created by Allen. 说明模型参数仍然有进一步优化空间。
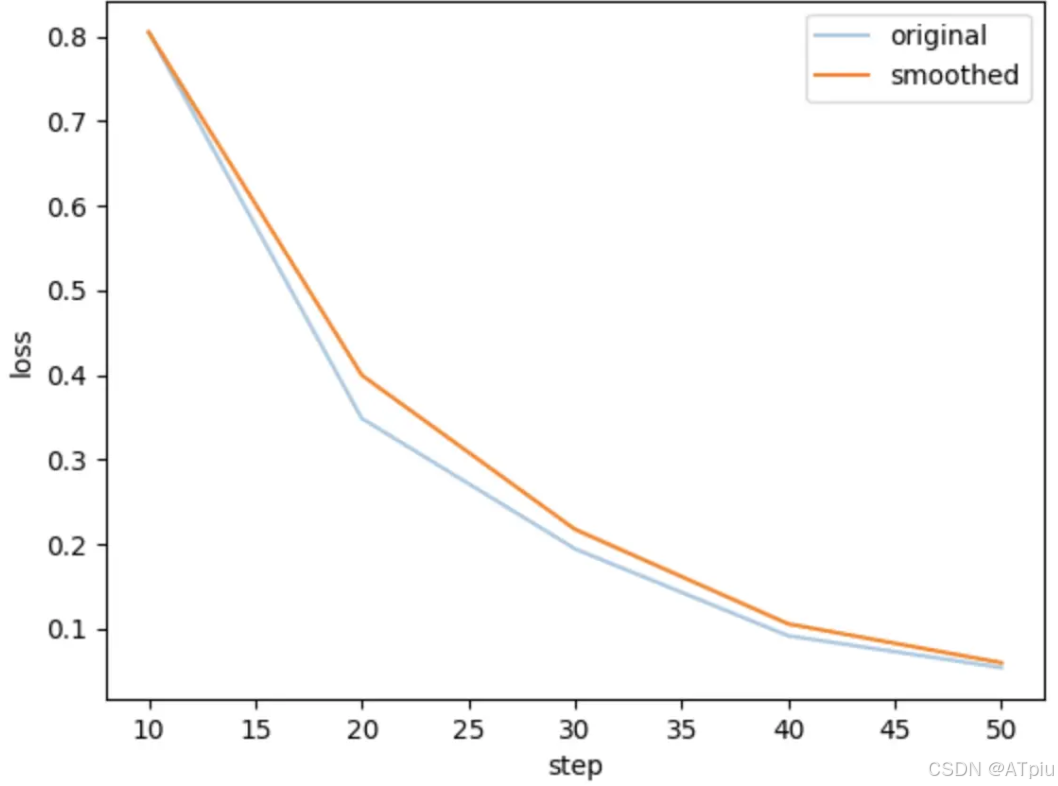
- 在训练页面Train tab页,如果训练数据够多,会显示损失曲线,它指每个训练批次损失值随训练轮次的变化。这个图像可以用来解读训练过程中模型的收敛情况和学习进展,是非常重要的训练情况观察图表。
一般初始阶段的损失值较高,随着训练的进行,损失值会逐渐下降。如果损失值低且趋向稳定,说明模型已经收敛,训练效果不错。
如果损失初始值或损失最终值(如大于1)过大,如果这个曲线趋近于直线,如果损失值突然大幅上升或下降,这些现象都说明训练过程存在严重问题,需要调整训练参数或数据。
3. 总结
实际工作中的大模型微调,影响微调结果有多个因素,而且训练数据至少上万。此处为了展示训练效果,仅用了少量数据:
- 基座大模型质量
- 训练数据质量,训练数据数量…
- 微调方法:full, freeze, lora
- 微调参数:learning rate,Epochs,Max samples,量化等级等
- 测试方法,覆盖度等
微调不是件容易的事,需要大量硬件成本,时间成本,精力投入,反复调整训练参数和数据,并没有所有模型通用的标准固定训练参数或数据。部分参数,只能说根据过往经验和参数本身意义,有一个相对合理的范围。