点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(正在更新…)
章节内容
上节我们完成了如下的内容:
- 监督学习算法
- KNN 近邻 代码实现 Python
scikit-learn 算法库实现
scikit-learn 自 2007 年以来,已经成为python 中重要的机器学习库了,简称 sklearn,支持了包括:分类、回归、降维、聚类四大机器学习的算法,以及特征提取、数据预处理和模型评估三大模块。
在工程应用中,用 Python 手写代码来从头实现一个算法的可能性非常低,这样不仅耗时费力,还不一定能够写出架构清晰、稳定性强的模型。
更多情况下,采集到的数据,根据数据特征选择适合的算法,在工具包中调用算法,调整算法的参数,获取所需要的信息,从而实现算法效率和效果之间的平衡。而 sklearn,正是这样一个可以帮助我们高效实现算法应用的工具包。
设计原则
一致性
所有对象共享一个简单一致的界面(接口)
- 估算器:fit()方法,基于数据估算参数的任意对象,使用的参数是一个数据集(对应 X,有监督算法还需要一个Y),引导估算过程的任意其他参数成为超参数,必须被设置为实例变量。
- 转换器:transform()方法,使用估算器转换数据集,转换过程依赖于学习参数,可以使用便捷方式:fit_transform(),相当于先 fit()再 transform(),有时优化过速度更快。
- 预测器:predict()方法,使用估算器预测新数据,返回包含预测结果的数据,还有 score()方法:用于度量给定测试集的预测效果的好坏(连续 y 使用 R 方,分类 y 使用准确率 accuracy)
监控
检查所有参数,所有估算器的超参数可以通过公共实例变量访问,所有估算器的学习参数都可以通过有下划线后缀的公共实例变量访问。
防止类扩散
对象型固定,数据集被表示为 Numpy 数组或 Scipy 稀疏矩阵,超惨是普通的 Python字符或数字。
合成
现有的构建尽可能重用,可以轻松创建一个流水线 Pipline。
合成默认值
大多参数提供合理默认值,可以轻松搭建一个基本的工作系统。
案例1:红酒
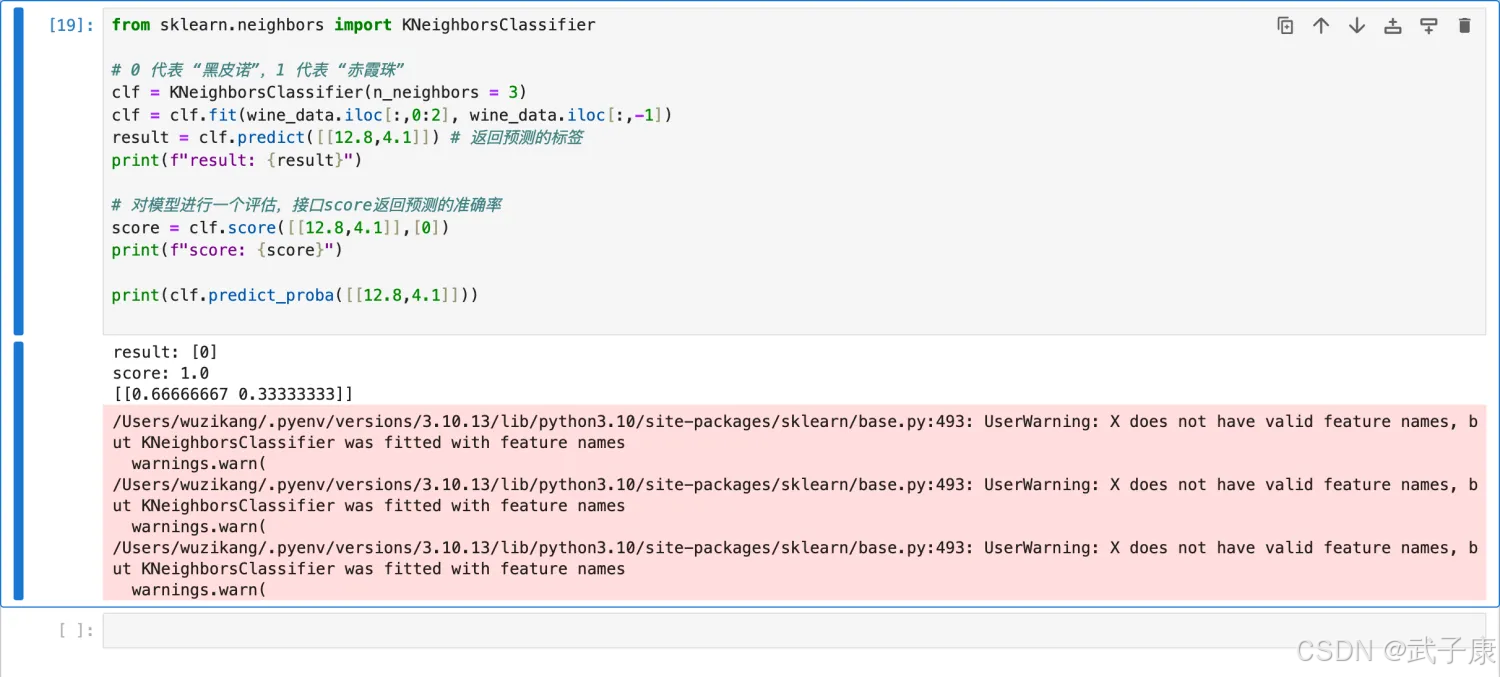
from sklearn.neighbors import KNeighborsClassifier
# 0 代表 “黑皮诺”,1 代表 “赤霞珠”
clf = KNeighborsClassifier(n_neighbors = 3)
clf = clf.fit(wine_data.iloc[:,0:2], wine_data.iloc[:,-1])
result = clf.predict([[12.8,4.1]]) # 返回预测的标签
print(f"result: {result}")
# 对模型进行一个评估,接口score返回预测的准确率
score = clf.score([[12.8,4.1]],[0])
print(f"score: {score}")
print(clf.predict_proba([[12.8,4.1]]))
执行结果如下图是:
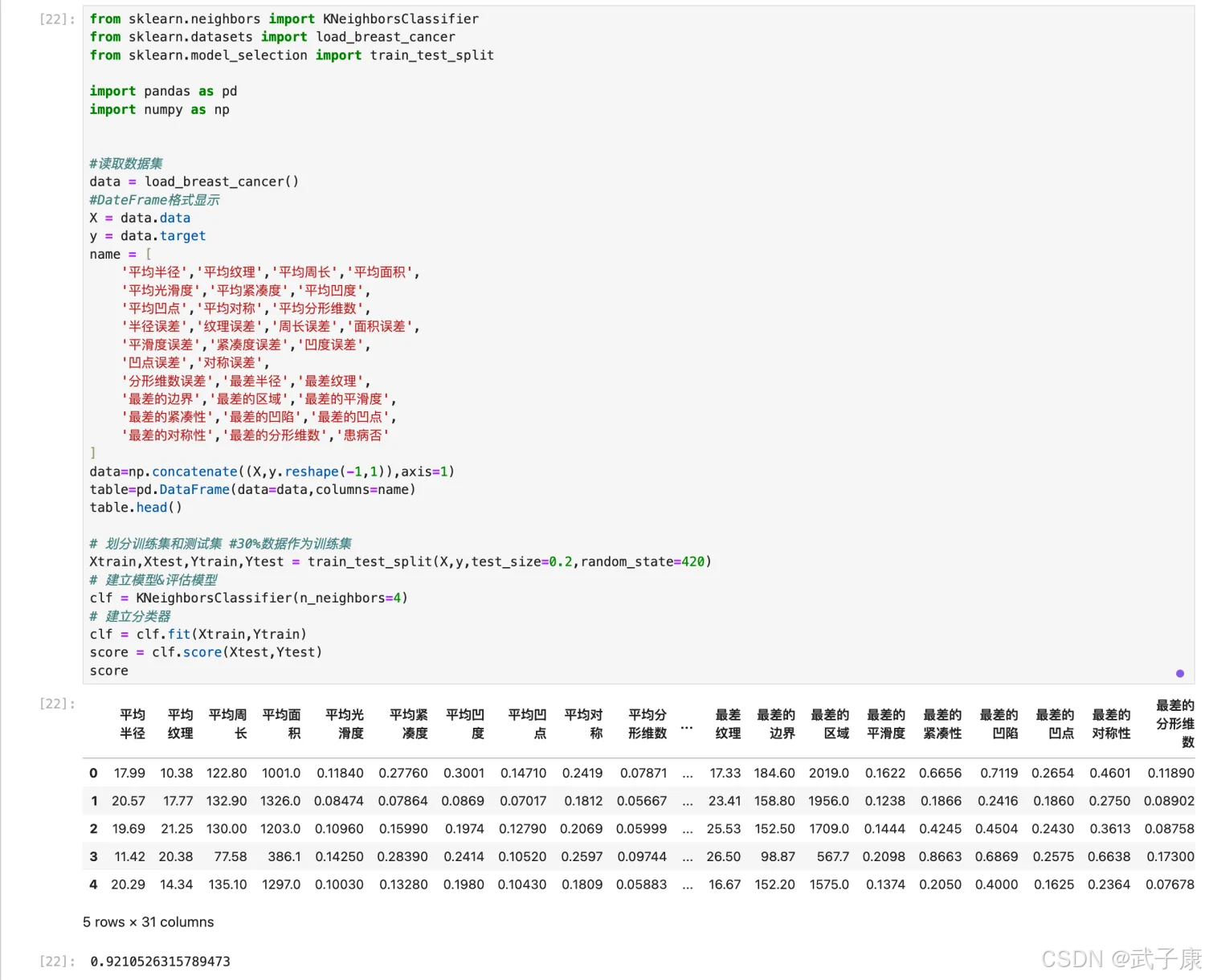
案例2:乳腺癌
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
#读取数据集
data = load_breast_cancer()
#DateFrame格式显示
X = data.data
y = data.target
name = ['平均半径','平均纹理','平均周长','平均面积',
'平均光滑度','平均紧凑度','平均凹度',
'平均凹点','平均对称','平均分形维数',
'半径误差','纹理误差','周长误差','面积误差',
'平滑度误差','紧凑度误差','凹度误差',
'凹点误差','对称误差',
'分形维数误差','最差半径','最差纹理',
'最差的边界','最差的区域','最差的平滑度',
'最差的紧凑性','最差的凹陷','最差的凹点',
'最差的对称性','最差的分形维数','患病否']
data=np.concatenate((X,y.reshape(-1,1)),axis=1)
table=pd.DataFrame(data=data,columns=name)
table.head()
# 划分训练集和测试集 #30%数据作为训练集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=420)
# 建立模型&评估模型
clf = KNeighborsClassifier(n_neighbors=4)
# 建立分类器
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score
执行结果如下图所示:
如何用上面分类器拟合结果找出离 Xtest 中第 20 行和第 30 行最近的 4 个“点”?
# 查找点的K邻居。返回每个点的邻居的与之的距离和索引值。
clf.kneighbors(Xtest[[20,30],:],return_distance=True)
查询结果如下图所示:

选择最优K值
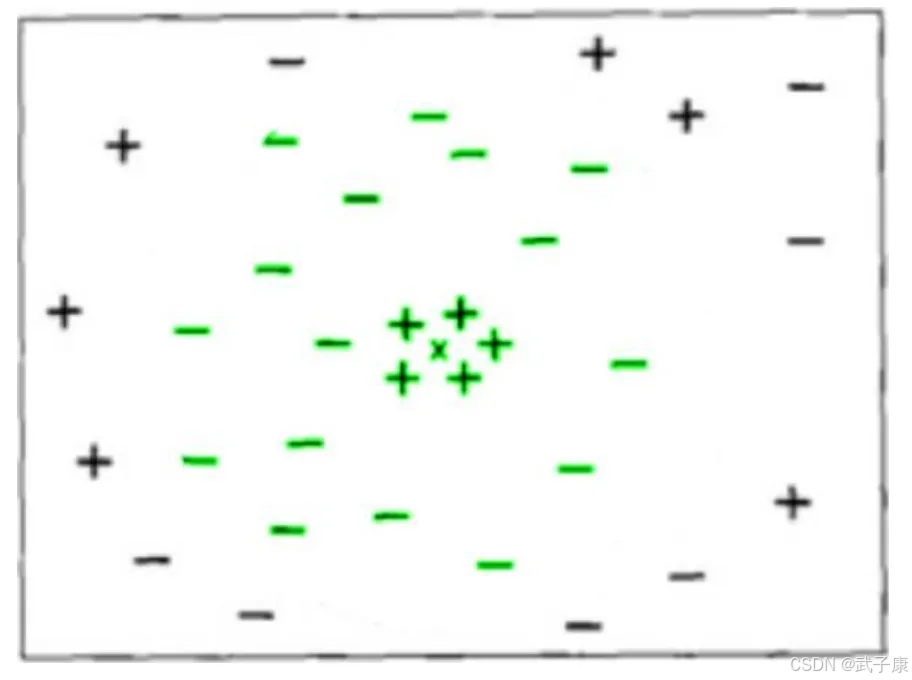
KNN 中的一个超参数,所谓“超参数”,就是需要人为输入,算法不能通过直接计算得出这个参数,KNN 中的 K 代表的是距离需要分类的测试点 X 最近的 K 个样本,如果不输入这个值,那么算法中重要部分“选出 K 个最近邻”就无法实现。
从 KNN 的原理中可见,是否能够确认合适的 K 值对算法有极大的影响。
如果选择的 K值较小,就相当于较小的领域中的训练实例进行预测,这时候只有与输入实例较近的训练实例才会对预测结果起作用,但缺点是预测结果会对近邻的实例点非常敏感,如果近邻的实例点恰好是噪声,预测就会出错。
相反的,如果选择的 K 值较大,就相当于较大的领域中的训练实例进行预测,这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。因此,超参数 K 的选定是 KNN 的头号问题。
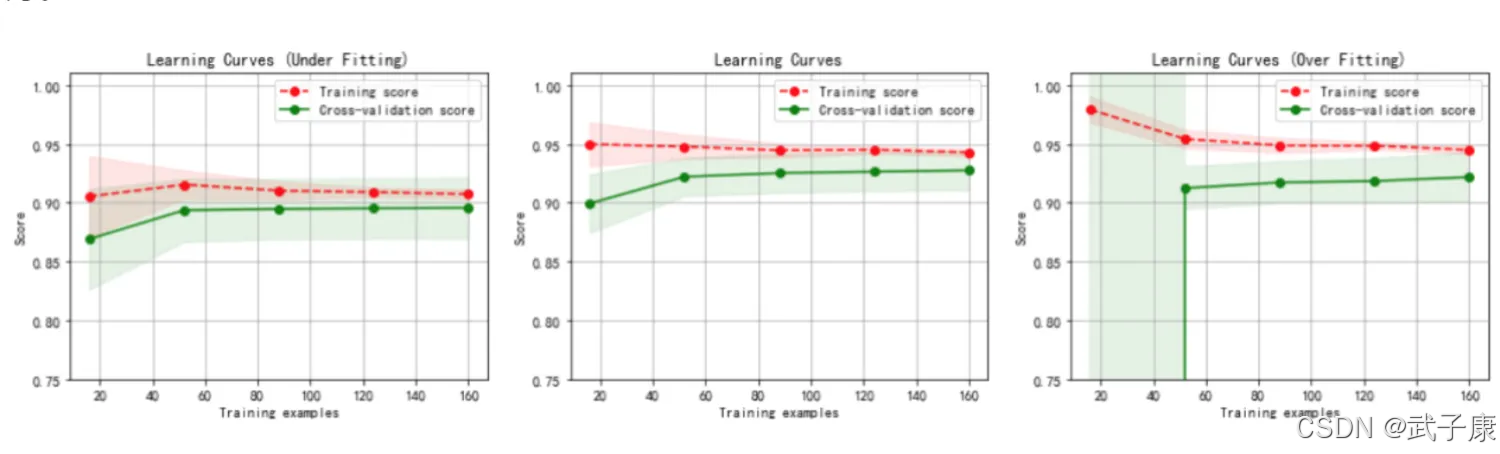
学习曲线
我们怎么样选择一个最佳的 K 值?在这里要使用机器学习中的神器:参数学习曲线,参数学习曲线是一条以不同的参数取值为横坐标,不同参数取值下的模型结果为纵坐标的曲线,我们往往选择模型表现最佳点的参数取值作为这个参数的取值。
# 更换不同的n_neighbors参数的取值,观察结果的变化
clf = KNeighborsClassifier(n_neighbors=7)
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score
查看结果如下:
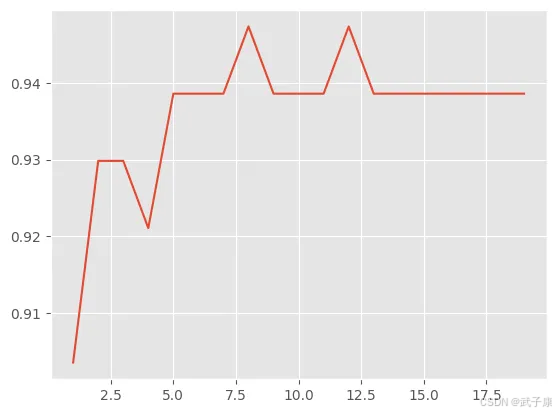
绘制学习曲线:

score = []
krange = range(1,20)
for i in krange:
clf = KNeighborsClassifier(n_neighbors=i)
clf = clf.fit(Xtrain,Ytrain)
score.append(clf.score(Xtest,Ytest))
plt.plot(krange,score)
plt.show()
执行结果如下:
图像如下所示:
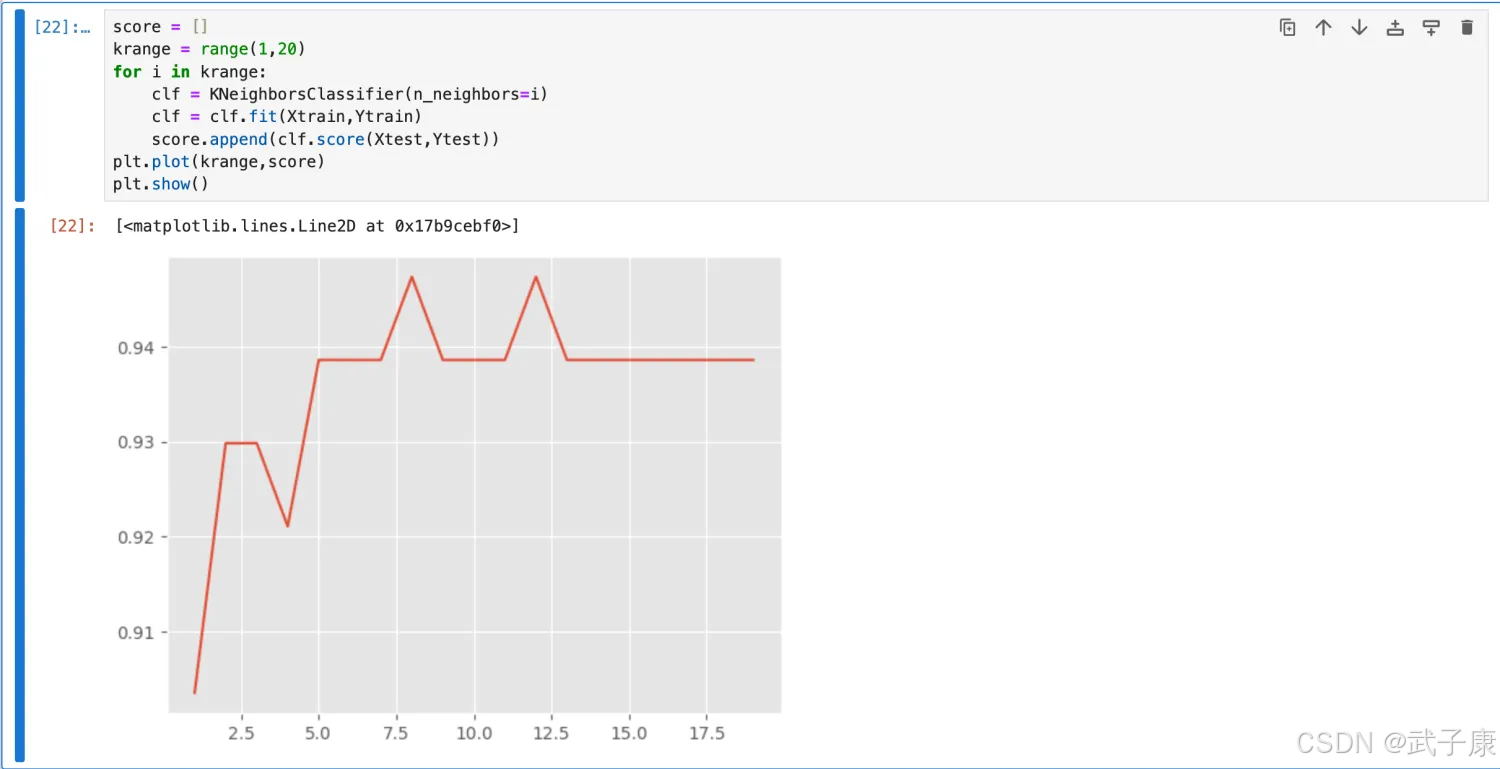
那么上图中 K 为多少的时候分值最高呢?
score.index(max(score))+1
执行结果如下所示:
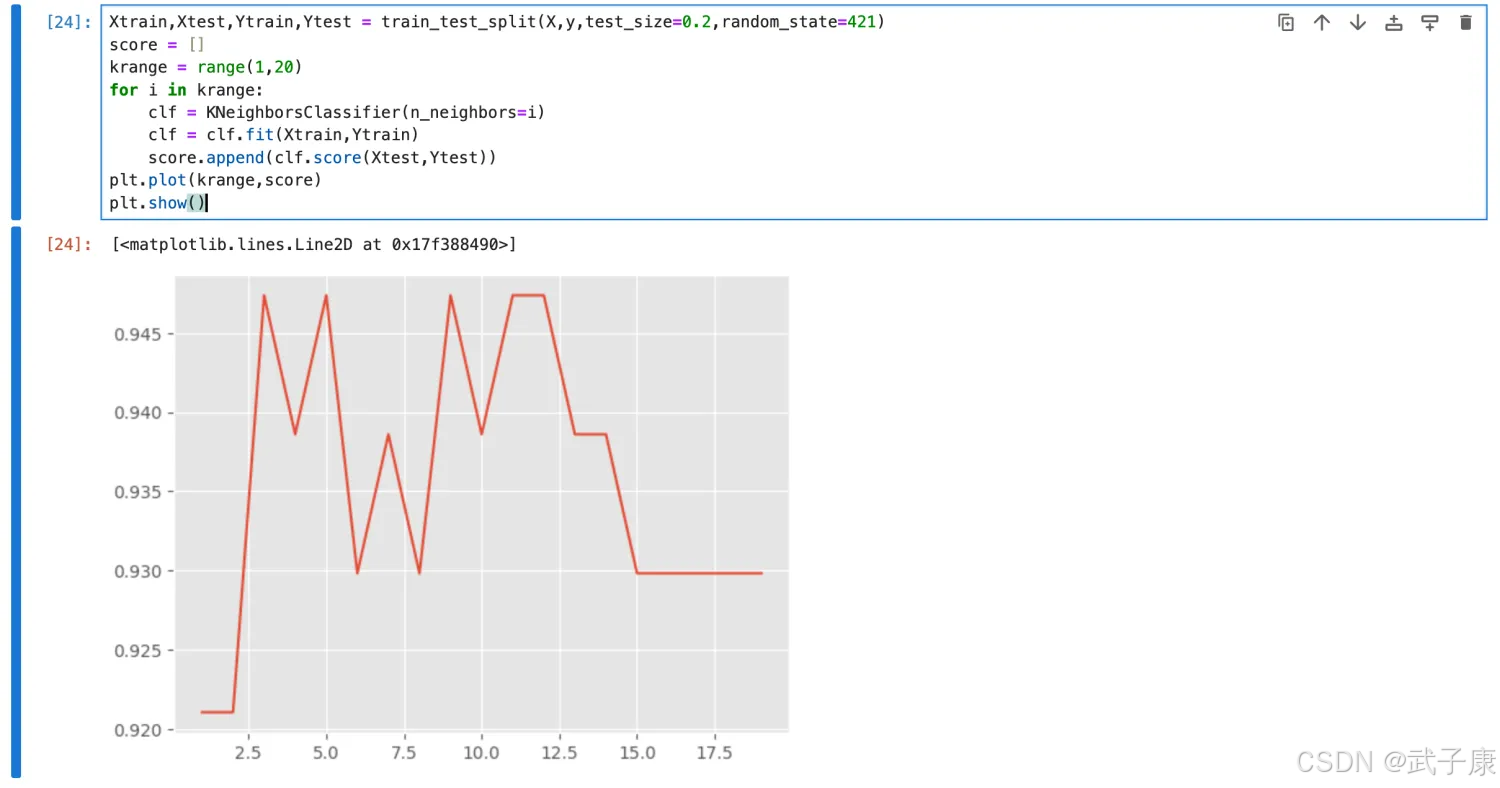
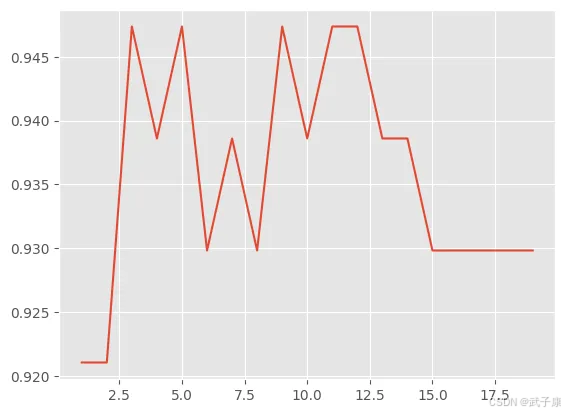
但是这个时候也会有问题,如果随机划分的数据集变化的话,得分最高的K 值也会发生变化。

Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=421)
score = []
krange = range(1,20)
for i in krange:
clf = KNeighborsClassifier(n_neighbors=i)
clf = clf.fit(Xtrain,Ytrain)
score.append(clf.score(Xtest,Ytest))
plt.plot(krange,score)
plt.show()
执行结果如下所示:
输出的图片的是:
此时的K 为多少分值最高?
score.index(max(score))+1
执行结果如下所示:
此时就无法确定最佳的 K 值了,就无法进行下面的建模工作,怎么办?
