一、基于 Flink 的 Kafka 消息生产者
- Kafka 生产者的创建与配置:
- 代码通过
FlinkKafkaProducer创建 Kafka 生产者,用于向 Kafka 主题发送消息。
- 代码通过
- Flink 执行环境的配置:
- 配置了 Flink 的检查点机制,确保消息的可靠性,支持"精确一次"的消息交付语义。
- 模拟数据源:
- 通过
env.fromElements()方法创建了简单的消息流,发送了三条消息"a","b", 和"c"。
- 通过
package com.example.kafka_flink.service;
import com.example.kafka_flink.util.MyNoParalleSource;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.Properties;
@Service
public class SimpleKafkaProducer {
public static void main(String[] args) throws Exception {
// 创建 SimpleKafkaProducer 的实例
SimpleKafkaProducer kafkaProducer = new SimpleKafkaProducer();
// 调用 producer 方法
kafkaProducer.producer();
}
public void producer() throws Exception {
// 设置 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置检查点机制,设置检查点模式为 "Exactly Once"(精确一次)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 启用检查点机制,设置检查点时间间隔为 5000 毫秒(5 秒)
env.enableCheckpointing(5000);
// 配置 Kafka 属性,包括身份验证信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "xxxx");
properties.setProperty("security.protocol", "SASL_PLAINTEXT");
properties.setProperty("sasl.mechanism", "SCRAM-SHA-512");
properties.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"xxx\" password=\"xxx\";");
// 创建 Kafka 生产者实例,并设置目标主题和序列化模式
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(
"WJ-TEST",
// 使用 SimpleStringSchema 进行字符串序列化
new SimpleStringSchema(),
properties
);
// 模拟数据源,生产一些简单的消息,并将消息写入 Kafka
env.fromElements("a", "b", "c")
.addSink(producer);
// 启动 Flink 作业
env.execute("Kafka Producer Job");
}
}
二、基于 Flink 的 Kafka 消息消费者
2.1 消费一个Topic
-
设置 Flink 执行环境:
- 使用
StreamExecutionEnvironment.getExecutionEnvironment()创建执行环境。
- 使用
-
启用检查点机制:
- 调用
env.enableCheckpointing(5000),设置检查点时间间隔为 5 秒。 - 配置检查点模式为
EXACTLY_ONCE,确保数据一致性。
- 调用
-
配置 Kafka 属性:
- 设置 Kafka 服务器地址(
bootstrap.servers)。 - 指定消费组 ID(
group.id)。 - 配置安全协议和认证机制(
SASL_PLAINTEXT和SCRAM-SHA-512)。
- 设置 Kafka 服务器地址(
-
创建 Kafka 消费者:
- 使用
FlinkKafkaConsumer<String>指定单个 Kafka Topic(如"WJ-TEST")。 - 设置消息反序列化方式为
SimpleStringSchema。 - 配置消费者从最早偏移量开始消费(
setStartFromEarliest())。
- 使用
-
将 Kafka 消费者添加到 Flink 数据流:
- 调用
env.addSource(consumer)添加 Kafka 消费者作为数据源。 - 使用
FlatMapFunction处理消息,将其打印或进一步处理。
- 调用
-
启动 Flink 作业:
- 使用
env.execute("start consumer...")启动 Flink 作业,开始消费 Kafka 的消息流。
- 使用
//消费单个topic
public static void consumerOneTopic() throws Exception {
// 设置 Flink 执行环境
// 创建一个流处理的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 启用检查点机制,设置检查点的时间间隔为 5000 毫秒(5 秒)
env.enableCheckpointing(5000);
// 配置检查点模式为 "Exactly Once"(精确一次)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 配置 Kafka 属性,包括身份验证信息
Properties properties = new Properties();
// 设置 Kafka 集群地址
properties.setProperty("bootstrap.servers", "xxxx");
// 设置消费组 ID,用于管理消费偏移量
properties.setProperty("group.id", "group_test");
// 设置安全协议为 SASL_PLAINTEXT
properties.setProperty("security.protocol", "SASL_PLAINTEXT");
// 设置 SASL 认证机制为 SCRAM-SHA-512
properties.setProperty("sasl.mechanism", "SCRAM-SHA-512");
// 配置 SASL 登录模块,包含用户名和密码
properties.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"xxx\" password=\"xxx\";");
// 创建一个 Kafka 消费者实例
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
// 设置要消费的 Kafka 主题名称
"WJ-TEST",
// 使用 SimpleStringSchema 将 Kafka 的消息反序列化为字符串
new SimpleStringSchema(),
// 传入 Kafka 的配置属性
properties
);
// 设置消费者从 Kafka 的最早偏移量开始消费消息
consumer.setStartFromEarliest();
// 将 Kafka 消费者作为数据源添加到 Flink 的执行环境中
env.addSource(consumer).flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
// 打印消费到的消息内容到控制台
System.out.println(s);
// 收集消费到的消息,供后续处理
collector.collect(s);
}
});
// 启动并执行 Flink 作业,作业名称为 "start consumer..."
env.execute("start consumer...");
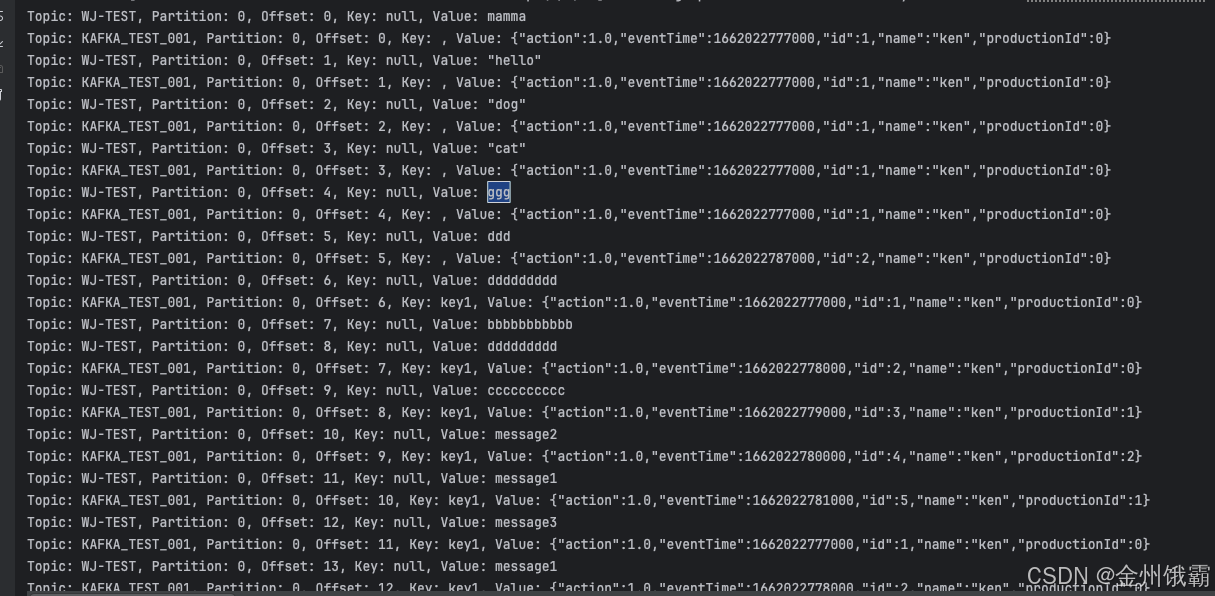
}生产消息结果:
2.2 消费多个Topic
-
设置 Flink 执行环境:
- 使用
StreamExecutionEnvironment.getExecutionEnvironment()创建执行环境。
- 使用
-
启用检查点机制:
- 配置检查点模式为
EXACTLY_ONCE,确保数据一致性。 - 调用
env.enableCheckpointing(5000)设置检查点时间间隔为 5 秒。
- 配置检查点模式为
-
配置 Kafka 属性:
- 设置 Kafka 服务器地址(
bootstrap.servers)。 - 指定消费组 ID(
group.id)。 - 配置安全协议和认证机制(
SASL_PLAINTEXT和SCRAM-SHA-512)。
- 设置 Kafka 服务器地址(
-
定义 Kafka Topic 列表:
- 创建一个
List<String>,添加多个 Kafka Topic 名称(如"WJ-TEST"和"KAFKA_TEST_001")。
- 创建一个
-
创建 Kafka 消费者:
- 使用
FlinkKafkaConsumer,传入 Kafka Topic 列表和自定义反序列化器(CustomDeSerializationSchema)。 - 配置消费者从最早偏移量开始消费(
setStartFromEarliest())。
- 使用
-
将 Kafka 消费者添加到 Flink 数据流:
- 调用
env.addSource(consumer)添加 Kafka 消费者作为数据源。 - 使用
FlatMapFunction处理消息,打印消息的 Topic、分区、偏移量、键和值,并收集消息值进行进一步处理。
- 调用
-
启动 Flink 作业:
- 使用
env.execute("start consumer...")启动 Flink 作业,开始消费 Kafka 的多个主题消息流。
- 使用
//消费多个topic
public static void consumerTopics() throws Exception {
// 设置 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置检查点机制,设置检查点模式为 "Exactly Once"(精确一次)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 启用检查点机制,设置检查点时间间隔为 5000 毫秒(5 秒)
env.enableCheckpointing(5000);
// 配置 Kafka 属性,包括身份验证信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "xxxx");
properties.setProperty("group.id", "group_test");
properties.setProperty("security.protocol", "SASL_PLAINTEXT");
properties.setProperty("sasl.mechanism", "SCRAM-SHA-512");
properties.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"xxx\" password=\"xxx\";");
// 定义需要消费的 Kafka 主题列表
List<String> topics = new ArrayList<>();
topics.add("WJ-TEST");
topics.add("KAFKA_TEST_001");
// 使用自定义反序列化器创建 Kafka 消费者实例
FlinkKafkaConsumer<ConsumerRecord<String, String>> consumer = new FlinkKafkaConsumer<>(
topics,
new CustomDeSerializationSchema(),
properties
);
// 设置消费者从 Kafka 的最早偏移量开始消费消息
consumer.setStartFromEarliest();
// 将 Kafka 消费者作为数据源添加到 Flink 的执行环境中
env.addSource(consumer).flatMap(new FlatMapFunction<ConsumerRecord<String, String>, Object>() {
@Override
public void flatMap(ConsumerRecord<String, String> record, Collector<Object> collector) throws Exception {
// 打印消费到的消息内容到控制台
System.out.println("Topic: " + record.topic() +
", Partition: " + record.partition() +
", Offset: " + record.offset() +
", Key: " + record.key() +
", Value: " + record.value());
// 收集消费到的消息,供后续处理
collector.collect(record.value());
}
});
// 启动并执行 Flink 作业
env.execute("start consumer...");
}2.3 消费Topic的总体代码
package com.example.kafka_flink.service;
import com.example.kafka_flink.util.CustomDeSerializationSchema;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* @author wangjian
*/
@Service
public class SimpleKafkaConsumer {
public static void main(String[] args) throws Exception {
// SimpleKafkaConsumer.consumerOneTopic();
SimpleKafkaConsumer.consumerTopics();
}
//消费单个topic
public static void consumerOneTopic() throws Exception {
// 设置 Flink 执行环境
// 创建一个流处理的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 启用检查点机制,设置检查点的时间间隔为 5000 毫秒(5 秒)
env.enableCheckpointing(5000);
// 配置检查点模式为 "Exactly Once"(精确一次)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 配置 Kafka 属性,包括身份验证信息
Properties properties = new Properties();
// 设置 Kafka 集群地址
properties.setProperty("bootstrap.servers", "xxxx");
// 设置消费组 ID,用于管理消费偏移量
properties.setProperty("group.id", "group_test");
// 设置安全协议为 SASL_PLAINTEXT
properties.setProperty("security.protocol", "SASL_PLAINTEXT");
// 设置 SASL 认证机制为 SCRAM-SHA-512
properties.setProperty("sasl.mechanism", "SCRAM-SHA-512");
// 配置 SASL 登录模块,包含用户名和密码
properties.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"xxx\" password=\"xxx\";");
// 创建一个 Kafka 消费者实例
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
// 设置要消费的 Kafka 主题名称
"WJ-TEST",
// 使用 SimpleStringSchema 将 Kafka 的消息反序列化为字符串
new SimpleStringSchema(),
// 传入 Kafka 的配置属性
properties
);
// 设置消费者从 Kafka 的最早偏移量开始消费消息
consumer.setStartFromEarliest();
// 将 Kafka 消费者作为数据源添加到 Flink 的执行环境中
env.addSource(consumer).flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
// 打印消费到的消息内容到控制台
System.out.println(s);
// 收集消费到的消息,供后续处理
collector.collect(s);
}
});
// 启动并执行 Flink 作业,作业名称为 "start consumer..."
env.execute("start consumer...");
}
//消费多个topic
public static void consumerTopics() throws Exception {
// 设置 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置检查点机制,设置检查点模式为 "Exactly Once"(精确一次)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 启用检查点机制,设置检查点时间间隔为 5000 毫秒(5 秒)
env.enableCheckpointing(5000);
// 配置 Kafka 属性,包括身份验证信息
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "xxxx");
properties.setProperty("group.id", "group_test");
properties.setProperty("security.protocol", "SASL_PLAINTEXT");
properties.setProperty("sasl.mechanism", "SCRAM-SHA-512");
properties.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"xxx\" password=\"xxx\";");
// 定义需要消费的 Kafka 主题列表
List<String> topics = new ArrayList<>();
topics.add("WJ-TEST");
topics.add("KAFKA_TEST_001");
// 使用自定义反序列化器创建 Kafka 消费者实例
FlinkKafkaConsumer<ConsumerRecord<String, String>> consumer = new FlinkKafkaConsumer<>(
topics,
new CustomDeSerializationSchema(),
properties
);
// 设置消费者从 Kafka 的最早偏移量开始消费消息
consumer.setStartFromEarliest();
// 将 Kafka 消费者作为数据源添加到 Flink 的执行环境中
env.addSource(consumer).flatMap(new FlatMapFunction<ConsumerRecord<String, String>, Object>() {
@Override
public void flatMap(ConsumerRecord<String, String> record, Collector<Object> collector) throws Exception {
// 打印消费到的消息内容到控制台
System.out.println("Topic: " + record.topic() +
", Partition: " + record.partition() +
", Offset: " + record.offset() +
", Key: " + record.key() +
", Value: " + record.value());
// 收集消费到的消息,供后续处理
collector.collect(record.value());
}
});
// 启动并执行 Flink 作业
env.execute("start consumer...");
}
}2.4 自定义的 Kafka 反序列化器 (CustomDeSerializationSchema)
实现了一个自定义的 Kafka 反序列化器 (CustomDeSerializationSchema),主要功能是将从 Kafka 中消费到的消息(字节数组格式)解析为包含更多元数据信息的 ConsumerRecord<String, String> 对象。以下是其作用的具体说明:
-
解析 Kafka 消息:
- 消息的
key和value由字节数组转换为字符串格式,便于后续业务逻辑处理。 - 同时保留 Kafka 消息的元数据信息(如主题名称
topic、分区号partition、偏移量offset)。
- 消息的
-
扩展 Flink 的 Kafka 数据处理能力:
- 默认的反序列化器只处理消息内容(
key或value),而该自定义类将消息的元数据(如topic和partition)也作为输出的一部分,为复杂业务需求提供了更多上下文信息。
- 默认的反序列化器只处理消息内容(
-
控制流数据的结束逻辑:
- 实现了
isEndOfStream方法,返回false,表示 Kafka 的数据流是持续的,Flink 不会主动终止数据消费。
- 实现了
-
定义 Flink 数据类型:
- 使用
getProducedType方法,明确告诉 Flink 输出的数据类型是ConsumerRecord<String, String>,便于 Flink 在运行时正确处理流数据。
- 使用
package com.example.kafka_flink.util;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.nio.charset.StandardCharsets;
/**
* @author wangjian
*/
public class CustomDeSerializationSchema implements KafkaDeserializationSchema<ConsumerRecord<String, String>> {
// 是否表示流的最后一条元素
// 返回 false,表示数据流会源源不断地到来,Flink 不会主动停止消费
@Override
public boolean isEndOfStream(ConsumerRecord<String, String> stringStringConsumerRecord) {
return false;
}
// 反序列化方法
// 将 Kafka 消息从字节数组转换为 ConsumerRecord<String, String> 类型的数据
// 返回的数据不仅包括消息内容(key 和 value),还包括 topic、offset 和 partition 等元数据信息
@Override
public ConsumerRecord<String, String> deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) throws Exception {
// 检查 key 和 value 是否为 null,避免空指针异常
String key = consumerRecord.key() == null ? null : new String(consumerRecord.key(), StandardCharsets.UTF_8);
String value = consumerRecord.value() == null ? null : new String(consumerRecord.value(), StandardCharsets.UTF_8);
// 构造并返回一个 ConsumerRecord 对象,其中包含反序列化后的 key 和 value,以及其他元数据信息
return new ConsumerRecord<>(
// Kafka 主题名称
consumerRecord.topic(),
// 分区号
consumerRecord.partition(),
// 消息偏移量
consumerRecord.offset(),
// 消息的 key
key,
// 消息的 value
value
);
}
// 指定数据的输出类型
// 告诉 Flink 消费的 Kafka 数据类型是 ConsumerRecord<String, String>
@Override
public TypeInformation<ConsumerRecord<String, String>> getProducedType() {
return TypeInformation.of(new TypeHint<ConsumerRecord<String, String>>() {
});
}
}