
paper:FFA-Net: Feature Fusion Attention Network for Single Image Dehazing
1、Feature Attention
在现有的图像去雾网络中,通常平等对待通道特征和像素特征,但这无法有效处理图像中雾气分布不均和不同通道特征权重差异的情况。而且雾气分布不均,薄雾区域和厚雾区域的权重应明显不同,不同通道特征包含的加权信息也完全不同。这篇论文提出一种 特征注意力(Feature Attention)。
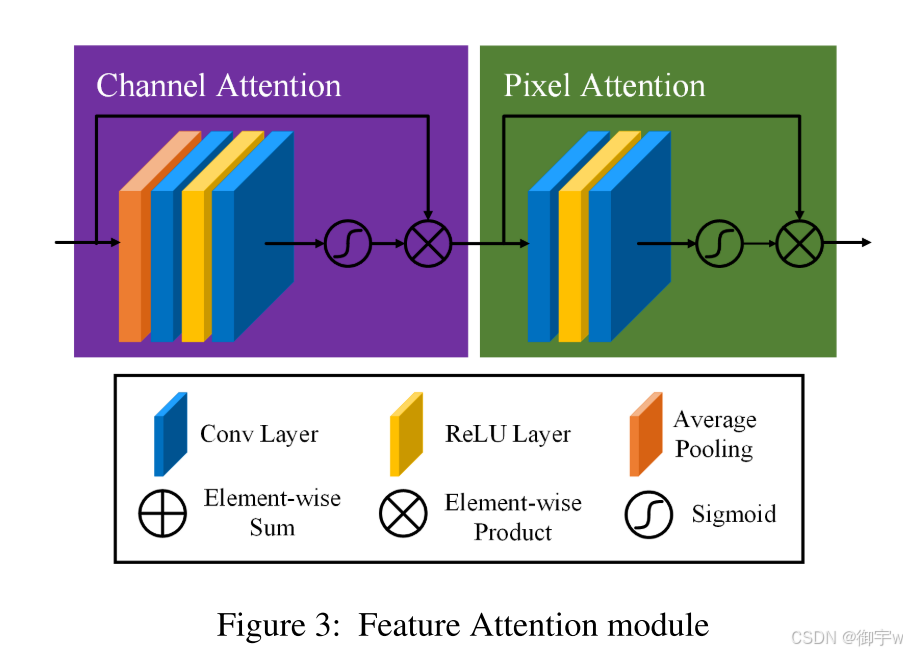
FA 的核心思想是通过结合 通道注意力 (CA) 和 像素注意力 (PA) 机制,为不同类型的信息处理提供额外的灵活性,并扩展 CNN 的表示能力。其中,CA 关注不同通道特征,PA 关注不同像素特征,分别赋予它们不同的权重。通过这种方式,FA 模块可以更加关注厚雾区域、高频纹理和重要通道信息,从而提高去雾效果。
对于输入X,FA 的实现过程:
Channel Attention (CA):
- 对通道特征进行全局平均池化,得到通道描述符。
- 通过两个卷积层和 Sigmoid 激活函数,生成不同通道的权重。
- 将输入特征与通道权重进行逐元素乘法,得到增强的通道特征
Pixel Attention (PA):
- 将 CA 输出作为输入,通过两个卷积层和 Sigmoid 激活函数,生成像素注意力图。
- 将输入特征与像素注意力图进行逐元素乘法,得到最终的增强特征。
Feature Attention 与 之前的注意力相比,主要有以下优势:
- 提高灵活性:通过分别关注通道和像素特征,FA 模块可以更灵活地处理不同类型的信息,从而提高网络的泛化能力。
- 增强表示能力:FA 模块可以学习到更丰富的特征表示,从而提高去雾效果。
- 关注重要信息:FA 模块可以更加关注厚雾区域、高频纹理和重要通道信息,从而提高去雾效果。
Feature Attention 结构图:
2、代码实现
import torch
import torch.nn as nn
class PALayer(nn.Module):
def __init__(self, channel):
super(PALayer, self).__init__()
self.pa = nn.Sequential(
nn.Conv2d(channel, channel // 8, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 8, 1, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.pa(x)
return x * y
class CALayer(nn.Module):
def __init__(self, channel):
super(CALayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.ca = nn.Sequential(
nn.Conv2d(channel, channel // 8, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 8, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.ca(y)
return x * y
class FA(nn.Module):
def __init__(self, channel):
super(FA, self).__init__()
self.calayer = CALayer(channel)
self.palayer = PALayer(channel)
def forward(self, x):
x = self.calayer(x)
res = self.palayer(x)
return res
if __name__ == '__main__':
x = torch.randn(4, 512, 7, 7)
model = FA(512)
output = model(x)
print(output.shape)