感觉编码有三个部分组成:
生成字节数组的方法。
字节数组本身。
解析字节数组的方法。
一般情况下乱码的产生就是第三部分出错了,也就是用错误的方式解析字节数组。比如下面的例子:
public static void test_4(){
try{
String str1 = "我们";
String str2 = new String(str1.getBytes("UTF-8"), "GBK");
String str3 = new String(str2.getBytes("GBK"), "UTF-8");
System.out.println(str1);
System.out.println(str2);
System.out.println(str3);
print(str1.getBytes("UTF-8"));
print(str2.getBytes("GBK"));
print(str3.getBytes("UTF-8"));
}catch(Exception e){
}
}
输出:
----------------------------------------------------------------------------------
我们
鎴戜滑
我们
-26, -120, -111, -28, -69, -84,
-26, -120, -111, -28, -69, -84,
-26, -120, -111, -28, -69, -84,
但是这种来回的转换并不总是会成功,因为GBK表示一个汉字需要两个字节,而UTF-8则需要3个字节,这样如果是奇数个汉字的时候转换成的UTF-8就得对齐,然后再转回来当然就不一样了。通过这个例子也看到了方法getBytes和new String都做了些什么工作。
先来看ISO-8859-1编码,也就是这几天最闹心的一种编码。它是大多数浏览器的默认字符集,前128个字符对应ASCII字符集,后128个字符包含了一些被西欧国家使用的字符以及一些常用的特殊字符,是ASCII的超集。编码表如下:
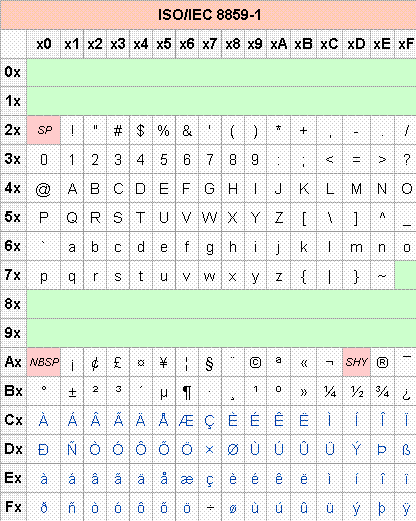
在网上捞到的一段从ISO-8859-1到UTF-8的转换的代码如下:
public static byte[] code8859toUTFNew(byte[] src){
byte [] dest = new byte[src.length*2 +1];
int i = 0, j = 0;
int value;
for(i =0; i < src.length;i++){
value = src[i]& 0xFF;
if (value <= 0x7F){
dest[j++] = src[i];
}else if(value >0x7F && value <= 0xFF){
dest[j++] = (byte)((value>>6)& 0x1F|0xC0);
dest[j++] = (byte)(value&0x3F|0x80);
}
}
byte [] end = new byte[j];
System.arraycopy(dest, 0, end, 0, j);
return end;
}
UTF-8编码:
UTF-8是一宗针对Unicode的可变长字符编码,也是一种前缀码,可用来表示Unicode标准中任何字符,且其编码中的第一个字节与ASCII相容。UTF-8的规则如下:
128个US-ASCII字符只需要一个字节编码(从U+0000到U+007F)。
带有符号的拉丁文,希腊文,西里尔字母,亚美尼亚语,希伯来文,阿拉伯文,叙利亚文与他拿字母需要两个字节编码(Unicode范围从U+0080到U+07FF)。
其他基于多文种平面中的字符使用三个字节编码。
其他极少使用的Unicode辅助平面的字符使用四个字节编码。
IETF要求所有的互联网协议都必须支持UTF-8编码。编码中的规则如下:
代码范围
UTF-8
注释
000000-00007F
0ZZZZZZZ
ASCII字符范围,字节由0开始
000080-0007FF
110YYYYY10ZZZZZZ
第一个字节110开始,接着的字节由10开始
000800-00D7FF
00E000-00FFFF
1110XXX10YYYYYY10ZZZZZZ
第一个字节由1110开始,接下来的字节由10开始
010000-10FFFF
11110WWW10XXXXXX10YYYYYY10ZZZZZZ
第一个字节由11110开始,接下来的由10开始