##2017.10.30收集
面试技巧
1) 一般而言,小公司做笔试题;大公司面谈项目经验;做地图的一定考算法
2) 面试官喜欢什么样的人
ü 技术好、自信、谦虚、善于沟通、表达。
ü 喜欢追究原理
5.2 面试内容
1.2.1简历上的项目
ü 介绍下你的项目吧?
1) 第一步:介绍你项目是干嘛的
2) 第二步:介绍下你负责的是哪块
3) 第三步:介绍下里面都有什么功能,你是怎么实现的,怎么分层的?
1.2.2非技术=处事方法+表达+态度+忠诚度
ü 请你做一下自我介绍
ü 你在找工作时,最重要的考虑因素是什么?
ü 你对我们公司了解多少?你为什么想来我们公司工作?
ü 请谈谈你的优点和缺点?
ü 你为什么离开上一家公司?
ü 工作中曾面临的最大困难是什么?如何解决的?
ü 你的职业目标是什么?(短期和长期)
ü 你是应届生,缺乏经验,如何胜任这份工作?
ü 你对加班的看法?
ü 你对薪资的要求?
ü 你最擅长的技术方向是什么?谈谈你之前做的项目?
ü 你有什么问题要问我?(参考下面思路)
n 我们公司有哪些项目要做了?
n 项目中使用什么技术来开发?
n 我们公司上班时间是怎样的?
n 前端开发目前有多少人在做?
5.3 面试技巧
Ø 1靠的是技术 2靠技巧 3玩的是心理
Ø 怎么回答问题
Ø 知道的问题正面回答,用案例去展示
Ø 不知道的问题说解决思路
Ø 原理性的知识,必须背下来,代码不需要会写,没人要求写原理、底层的代码(这是一个空子,可以钻)
Ø 面试始终保持平静,冷静,镇静,面试再刁难也要保持端坐,面带一丝微笑
Ø 对喜欢的公司最好能表现出对加入目标公司的渴望,对技术的追求
Ø 不能说不知道,可以说:之前了解过,做过这种练习,但没有拿到项目中来用。如果你回答了不知道,那面试官直接就否定你了
Ø 面试官给你出题时,回答问题要思考一段时间,提出思路(这样表现出你是善于思考,交流,有思路)。间接性的试探答案,要的就是这种交互性,注意交流很重要
Ø 加分的地方:对简历上的项目很熟悉,技术点都有所研究,包括封装,细节实现,以及自己编写的小工具
Ø 回答问题后,可再加一些个人看法~比如:json用过吗?怎么用?回答时,可把jsonp也叙述一下
Ø 不想去的公司(小公司,刚刚组建开发团队……)也尽量去面试,为的是积累经验。不同公司会问不同类型的问题,经历多了,你会发现面试很爽,尤其是秒杀他们的时候。
Ø 主管和你谈话~是探测你这个人是否可用……,回答问题要表现良好的一面,一般会问~你将来怎么规划的?回答:三年达到技术总监的水平。技术总监需要做到什么?1.技术过硬2.沟通交流,带领团队……
Ø 你在工作中遇到了哪些难题?? 一定要提前准备两道,忽悠他!
Ø 为什么离开上家公司?业务单一,太闲了,项目太少,想要更大的提升空间,这时对方肯定会想~你喜欢忙一些是吧,我们这里好多项目让你忙个够。你最好也表现出来~你要努力提升自己,不断超越的念头。
Ø 要有底线别把自己的底线出卖了,要有底气。面试官可能一个劲的谈你的弱点,打击你的心里,这时千万不要乱了阵脚,不要把底线出卖了。既然面试官一直和你聊,那就证明你在他眼中是有价值的。薪资方面该怎么要就怎么要。
Ø 你给自己评个等级,初,中,高,你最次也要说中级,好一点说中级偏上。
Ø 谈薪资:这一步你能多拿1000-2000元,你想:对方都和你谈薪资了,证明你这个人有可用价值。 Eg.对方说给你8K,你完全能再多要1-2K,公司不差那点钱,只要你能给公司带来N多K的利益。
Ø 态度很重要:没人查个人背景(这点不用太担心,大不了重新找);上班后勤勉工作,最好不要泡在QQ上,不懂赶紧问,别拖延时间,转正期也是适应期多,花点时间在工作上,工作态度非常非常重要
Ø 不见得你会这项技术就录用你,也不见得你不会某项技术就不录用你。面试中要注意和面试官交流,在交流中让对方感触到你基础不错,你有潜力,你逻辑思维不错。以上这些你做到了,如果不是那家公司只招一个某个专项技术的人,那你百分之八九十会被录用的。
5.4 面试中需要注意的问题
Ø 音量大小
Ø 语速控制
Ø 不说“我想想”,“好像是”,“可能”,“应该”,“估计”。。。等不肯定的语汇
Ø 用讲故事的方式主导面试官司的思维
Ø 面试的基本流程
1) 自我介绍
姓名、年龄、哪年毕业、哪年哪月入职第一家公司第一个项目开始介绍。。。
为何离职?介绍到最后一个项目的时候开始拿出来演示
2) 技术面试
用项目中的实例来回答面试官的问题
3) 谈薪
上家公司的薪资是多少?期望薪资是多少?
常见排序算法的时间复杂度,空间复杂度

移动端性能优化
▪ 尽量使用css3动画,开启硬件加速。
▪ 适当使用touch事件代替click事件。
▪ 避免使用css3渐变阴影效果。
▪ 可以用transform: translateZ(0)来开启硬件加速。
▪ 不滥用Float。Float在渲染时计算量比较大,尽量减少使用
▪ 不滥用Web字体。Web字体需要下载,解析,重绘当前页面,尽量减少使用。
▪ 合理使用requestAnimationFrame动画代替setTimeout
▪ CSS中的属性(CSS3 transitions、CSS3 3D transforms、Opacity、Canvas、WebGL、Video)会触发GPU渲染,请合理使用。过渡使用会引发手机过耗电增加
▪ PC端的在移动端同样适用,相关阅读:如何做到一秒渲染一个移动页面
1:为何选择前端这个方向和对前端的理解
为什么:
第一的话就是对前端很感兴趣,之前也接触过其他的语言,但是直到接触到前端才发现真的有兴趣做下去,兴趣是一个人最好的老师,
第二的话前端很有前途,像现在nodejs,rn,微信小程序这类工具和框架可以让前端进行后端和移动开发,所以我觉得前端的前途会更多一点。
理解:
首先前端工程师最核心的技能还是:Html、CSS、JS。前端负责的是用户可以看到的部分,所以也是最接近用户的工程师。同时在产品研发流程中前端要同时与产品、设计、后端等很多人合作。
对自己未来的规划是怎样的
对于刚毕业的人来说,前两年是很重要的,先打好基础,多提升js能力。三至四年在提升JS能力的同时,开始要往多方面发展,前端工程师远远不仅是JS而已。制作一个性能高、交互好、视觉美的页面,需要从前端框架选型、架构设计、构建工具,到后端通信机制、设计与交互、网络和浏览器优化等各方面的知识。一专多长才是前端工程师的终极目标。
(内容2)——————
HTML+CSS
1.对WEB标准以及W3C的理解与认识
标签闭合、标签小写、不乱嵌套、提高搜索机器人搜索几率、使用外链css和js脚本、结构行为表现的分离、文件下载与页面速度更快、内容能被更多的用户所访问、内容能被更广泛的设备所访问、更少的代码和组件,容易维护、改版方便,不需要变动页面内容、提供打印版本而不需要复制内容、提高网站易用性;
2.xhtml和html有什么区别
HTML是一种基本的WEB网页设计语言,XHTML是一个基于XML的置标语言
最主要的不同:
XHTML 元素必须被正确地嵌套。
XHTML 元素必须被关闭。
标签名必须用小写字母。
XHTML 文档必须拥有根元素。
3.Doctype? 严格模式与混杂模式-如何触发这两种模式,区分它们有何意义?
用于声明文档使用那种规范(html/Xhtml)一般为 严格 过度 基于框架的html文档
加入XMl声明可触发,解析方式更改为IE5.5 拥有IE5.5的bug
4.行内元素有哪些?块级元素有哪些?CSS的盒模型?
块级元素:div p h1 h2 h3 h4 form ul
行内元素: a b br i span input select
Css盒模型:内容,border ,margin,padding
5.CSS引入的方式有哪些? link和@import的区别是?
内联 内嵌 外链 导入
区别 :同时加载
前者无兼容性,后者CSS2.1以下浏览器不支持
Link 支持使用javascript改变样式,后者不可
6.CSS选择符有哪些?哪些属性可以继承?优先级算法如何计算?内联和important哪个优先级高?
标签选择符 类选择符 id选择符
继承不如指定 Id>class>标签选择
后者优先级高
7.前端页面有哪三层构成,分别是什么?作用是什么?
结构层 Html 表示层 CSS 行为层 js
8.css的基本语句构成是?
选择器{属性1:值1;属性2:值2;……}
9.你做的页面在哪些流览器测试过?这些浏览器的内核分别是什么?
Ie(Ie内核) 火狐(Gecko) 谷歌(webkit) opear(Presto)
10.写出几种IE6 BUG的解决方法
1.双边距BUG float引起的 使用display
2.3像素问题 使用float引起的 使用dislpay:inline -3px
3.超链接hover 点击后失效 使用正确的书写顺序 link visited hover active
4.Ie z-index问题 给父级添加position:relative
5.Png 透明 使用js代码 改
6.Min-height 最小高度 !Important 解决’
7.select 在ie6下遮盖 使用iframe嵌套
8.为什么没有办法定义1px左右的宽度容器(IE6默认的行高造成的,使用over:hidden,zoom:0.08 line-height:1px)
11.<img>标签上title与alt属性的区别是什么?
Alt 当图片不显示是 用文字代表。
Title 为该属性提供信息
12.描述css reset的作用和用途。
Reset重置浏览器的css默认属性 浏览器的品种不同,样式不同,然后重置,让他们统一
13.解释css sprites,如何使用。
Css 精灵 把一堆小的图片整合到一张大的图片上,减轻服务器对图片的请求数量
14.浏览器标准模式和怪异模式之间的区别是什么?
盒子模型 渲染模式的不同
使用 window.top.document.compatMode 可显示为什么模式
15.你如何对网站的文件和资源进行优化?期待的解决方案包括:
文件合并
文件最小化/文件压缩
使用CDN托管
缓存的使用
16.什么是语义化的HTML?
直观的认识标签 对于搜索引擎的抓取有好处
17.清除浮动的几种方式,各自的优缺点
浮动的表现,元素排成了一行
元素内容超出了容器边框,高度坍塌
1.在浮动元素后给空标签清除浮动 clear:both(理论上能清除任何浮动,弊端是增加无意义的标签),或者用afert伪元素+clear:both组合法清除浮动(用于非IE浏览器)
2.给浮动元素添加样式float:none
3.通过使父标签浮动也可以清理子类浮动,将空间撑开。例如让父标签生成BFC(IE8+),display:block、overflow:auto/hidden、zoom:1(触发haslayout(IE6/IE7) 兼容IE)
zoom:1的作用: 触发IE下的hasLayout。zoom是IE浏览器专有属性,可以设置或检索对象的缩放比例。 当设置了zoom的值之后,所设置的元素就会扩大或缩小,高度宽度就会重新计算了,这里一旦改变zoom值时其实也会发生重新渲染,运用这个原理,也就解决了ie下子元素浮动时候父元素不随着自动扩大的问题。
4.父元素设置适合的height
浮动有什么用?
浮动是让某个div元素脱离标准流,漂浮在标准流之上,常用来文字环绕或布局效果。
浮动过程原理就一句话:浮动元素会脱离文档流并向左/向右浮动,直到碰到父元素或者另一个浮动元素。
浮动怎样产生的呢?
一般浮动是什么情况呢?一般是一个盒子里使用了CSS float浮动属性,导致父级对象盒子不能被撑开,这样CSS float浮动就产生了。
浮动产生负作用
1、背景不能显示
由于浮动产生,如果对父级设置了(CSS background背景)CSS背景颜色或CSS背景图片,而父级不能被撑开,所以导致CSS背景不能显示。
2、边框不能撑开
如果父级设置了CSS边框属性(css border),由于子级里使用了float属性,产生浮动,父级不能被撑开,导致边框不能随内容而被撑开。
3、margin padding设置了值但无效,不能正确显示
Javascript
1.javascript的typeof返回哪些数据类型
Object number function boolean underfind string
2.例举3种强制类型转换和2种隐式类型转换?
强制(parseInt,parseFloat,number)
隐式(== - ===)
3.split() join() 的区别
前者是切割成数组的形式,后者是将数组转换成字符串
4.数组方法pop() push() unshift() shift()
Push()尾部添加 pop()尾部删除
Unshift()头部添加 shift()头部删除
5.事件绑定和普通事件有什么区别
普通添加事件的方法:
var btn = document.getElementById("hello");
btn.onclick = function(){
alert(1);
}
btn.onclick = function(){
alert(2);
}
执行上面的代码只会alert 2
事件绑定方式添加事件:
var btn = document.getElementById("hello");
btn.addEventListener("click",function(){
alert(1);
},false);
btn.addEventListener("click",function(){
alert(2);
},false);
执行上面的代码会先alert 1 再 alert 2
普通添加事件的方法不支持添加多个事件,最下面的事件会覆盖上面的,而事件绑定(addEventListener)方式添加事件可以添加多个。
6.IE和DOM事件流的区别
1.执行顺序不一样、
2.参数不一样
3.事件加不加on
4.this指向问题
7.IE和标准下有哪些兼容性的写法
Var ev = ev || window.event
document.documentElement.clientWidth || document.body.clientWidth
Var target = ev.srcElement||ev.target
列举IE 与其他浏览器不一样的特性?
-
IE支持
currentStyle,FIrefox使用getComputStyle -
IE 使用
innerText,Firefox使用textContent -
滤镜方面:IE:
filter:alpha(opacity= num);Firefox:-moz-opacity:num -
事件方面:IE:
attachEvent:火狐是addEventListener -
鼠标位置:IE是
event.clientX;火狐是event.pageX -
IE使用
event.srcElement;Firefox使用event.target -
IE中消除list的原点仅需margin:0即可达到最终效果;FIrefox需要设置
margin:0;padding:0以及list-style:none -
CSS圆角:ie7以下不支持圆角
8.ajax请求的时候get 和post方式的区别
一个在url后面 一个放在虚拟载体里面
有大小限制
安全问题
应用不同 一个是论坛等只需要请求的,一个是类似修改密码的
9.call和apply的区别
Object.call(this,obj1,obj2,obj3)
Object.apply(this,arguments)
两者在作用上是相同的,但在参数上有区别的。
对于第一个参数意义都一样,但对第二个参数:
apply传入的是一个参数数组,也就是将多个参数组合成为一个数组传入,而call则作为call的参数传入(从第二个参数开始)。
如 func.call(func1,var1,var2,var3)对应的apply写法为:func.apply(func1,[var1,var2,var3])
同时使用apply的好处是可以直接将当前函数的arguments对象作为apply的第二个参数传入
10.ajax请求时,如何解析json数据
使用eval、JSON.parse 鉴于安全性考虑 使用parse更靠谱
13.事件委托是什么
让利用事件冒泡的原理,让自己的所触发的事件,让他的父元素代替执行!
//利用冒泡的原理,把事件加到父级上,触发执行效果。
//1.可以大量节省内存占用,减少事件注册。
//2.可以方便地动态添加和修改元素,不需要因为元素的改动而修改事件绑定。
var ul = document.querySelector('ul');
var list = document.querySelectorAll('ul li');
ul.addEventListener('click', function(ev){
var ev = ev || window.event;
var target = ev.target || ev.srcElemnt;
for(var i = 0, len = list.length; i < len; i++){
if(list[i] == target){
alert(i + "----" + target.innerHTML);
}
}
});
14.闭包是什么,有什么特性,对页面有什么影响,应用场景
闭包是指有权访问另一个函数作用域中的变量的函数. 创建闭包常见方式,就是在一个函数内部创建另一个函数.
应用场景 设置私有变量和方法
不适合场景:返回闭包的函数是个非常大的函数
闭包的缺点就是常驻内存,会增大内存使用量,使用不当很容易造成内存泄露。
受JavaScript链式作用域结构的影响,父级变量中无法访问到子级的变量值,为了解决这个问题,才使用闭包这个概念
15.如何阻止事件冒泡和默认事件
canceBubble、return false
16.添加 删除 替换 插入到某个接点的方法
obj.appendChidl()
obj.innersetBefore
obj.replaceChild
obj.removeChild
17.解释jsonp的原理,以及为什么不是真正的ajax
动态创建script标签,回调函数
Ajax是页面无刷新请求数据操作
18.javascript的本地对象,内置对象和宿主对象
本地对象为array obj regexp等可以new实例化
内置对象为gload Math 等不可以实例化的
宿主为浏览器自带的document,window 等
19.document load 和document ready的区别
Document.onload 是在结构和样式加载完才执行js
Document.ready原生种没有这个方法,jquery中有 $().ready(function)
20.”==”和“===”的不同
前者会自动转换类型
后者不会
21.javascript的同源策略
一段脚本只能读取来自于同一来源的窗口和文档的属性,这里的同一来源指的是主机名、协议和端口号的组合
::before 和:before有什么区别?
相同点
都可以用来表示伪类对象,用来设置对象前的内容
:befor和::before写法是等效的
不同点
:befor是Css2的写法,::before是Css3的写法
:before的兼容性要比::before好 ,不过在H5开发中建议使用::before比较好
加分项
伪类对象要配合content属性一起使用
伪类对象不会出现在DOM中,所以不能通过js来操作,仅仅是在 CSS 渲染层加入
伪类对象的特效通常要使用:hover伪类样式来激活
.test:hover::before { /* 这时animation和transition才生效 */ }
(内容3)——————
http://bbs.blueidea.com/thread-3107428-1-1.html以下都是网上整理出来的JS面试题,答案仅供参考。
4,IE与FF脚本兼容性问题
obj.addEventListener(sEv, fn, false);
obj.attachEvent('on'+sEv,fn);
detachevet
removeEventListener
DOMContentLoaded
onreadystatechange complete
DOMMouseScroll FF
onmousewheel 非FF
event.wheelDelta 上滚120 下-120
event.detail 上滚-3 下3
obj.getCurrentStyle[attr]
getComputedStyle(obj,false)[attr]
XMLHttpRequest
ActiveXObject('Mircorsoft.XMLHttp')
FF本地能设置读取cookie 其他不行
event ev
事件源
srcElement||target
toElement||relatedTarget
obj.setCapture();只有ie认
obj.releaseCapture();
5,规避javascript多人开发函数重名问题
命名空间
封闭空间
js模块化mvc(数据层、表现层、控制层)
seajs
变量转换成对象的属性
对象化
6,javascript面向对象中继承实现
function Person(name){
this.name = name;
}
Person.prototype.showName = function(){
alert(this.name);
}
function Worker(name, job){
Person.apply(this,arguments)
this.job = job;
}
for(var i in Person.prototype){
Worker.prototype = Person.prototype;
}
new Worker('sl', 'coders').showName();
js继承方式及其优缺点
原型链继承的缺点
一是字面量重写原型会中断关系,使用引用类型的原型,并且子类型还无法给超类型传递参数。
借用构造函数(类式继承)
借用构造函数虽然解决了刚才两种问题,但没有原型,则复用无从谈起。所以我们需要原型链+借用构造函数的模式,这种模式称为组合继承
组合式继承
组合式继承是比较常用的一种继承方法,其背后的思路是 使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又保证每个实例都有它自己的属性。
7,FF下面实现outerHTML
var oDiv = document.createElement('div');
var oDiv1 = document.getElementById('div1');
var oWarp = document.getElementById('warp');
oWarp.insertBefore(oDiv, oDiv1);
oDiv.appendChild(oDiv1);
var sOut = oDiv.innerHTML;
oWarp.insertBefore(oDiv1, oDiv);
oWarp.removeChild(oDiv);
alert(sOut);
8,编写一个方法 求一个字符串的字节长度
假设一个中文占两个字节
var str = '22两是';
alert(getStrlen(str))
function getStrlen(str){
var json = {len:0};
var re = /[\u4e00-\u9fa5]/;
for (var i = 0; i < str.length; i++) {
if(re.test(str.charAt(i))){
json['len']++;
}
};
return json['len']+str.length;
}
10,写出3个使用this的典型应用
事件: 如onclick this->发生事件的对象
构造函数 this->new 出来的object
call/apply 改变this
12,JavaScript中如何检测一个变量是一个String类型?请写出函数实现
typeof(obj) == 'string'
obj.constructor == String;
网站设计八步骤 https://zhidao.baidu.com/question/12980607.html
一、确定网站主题
二、搜集材料
三、规划网站
四、选择合适的制作工具
五、制作网页
六、上传测试
七、推广宣传
八、维护更新
内容分析:分清展现在网络中内容的层次和逻辑关系
结构设计:写出合理的html结构代码
布局设计:使用html+css进行布局
样式设计:首先要使用reset.css
交互设计:鼠标特效
行为设计:js代码,ajax页面行为和从服务器获取数据
最后:测试兼容性,优化性能;
2.1你能描述一下你制作网站 制作网站的基本流程吗?
步骤http://jingyan.baidu.com/article/c275f6bac69f28e33d7567ef.html
a.网站内容的设计;
b.域名的申请注册;
c.网站空间地址;
d.网站的运营维护;
e.网站的推广;
3.你能描述一下渐进增强和优雅降级之间的不同吗?
什么是渐进增强(progressive enhancement)、优雅降级(graceful degradation)呢?
渐进增强 progressive enhancement:针对低版本浏览器进行构建页面,保证最基本的功能,然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验。
优雅降级 graceful degradation:一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
区别:优雅降级是从复杂的现状开始,并试图减少用户体验的供给,而渐进增强则是从一个非常基础的,能够起作用的版本开始,并不断扩充,以适应未来环境的需要。降级(功能衰减)意味着往回看;而渐进增强则意味着朝前看,同时保证其根基处于安全地带。
“优雅降级”观点
“优雅降级”观点认为应该针对那些最高级、最完善的浏览器来设计网站。而将那些被认为“过时”或有功能缺失的浏览器下的测试工作安排在开发周期的最后阶段,并把测试对象限定为主流浏览器(如 IE、Mozilla 等)的前一个版本。
在这种设计范例下,旧版的浏览器被认为仅能提供“简陋却无妨 (poor, but passable)” 的浏览体验。你可以做一些小的调整来适应某个特定的浏览器。但由于它们并非我们所关注的焦点,因此除了修复较大的错误之外,其它的差异将被直接忽略。
“渐进增强”观点
“渐进增强”观点则认为应关注于内容本身。
内容是我们建立网站的诱因。有的网站展示它,有的则收集它,有的寻求,有的操作,还有的网站甚至会包含以上的种种,但相同点是它们全都涉及到内容。这使得“渐进增强”成为一种更为合理的设计范例。这也是它立即被 Yahoo! 所采纳并用以构建其“分级式浏览器支持 (Graded Browser Support)”策略的原因所在。
4. 请解释一下什么是语义化的HTML。
内容使用特定标签,通过标签就能大概了解整体页面的布局分布
6. 你如何对网站的文件和资源进行优化?
这道题考察 雅虎军规 1.尽可能减少http请求次数,将css, js, 图片各自合并 2.使用CDN,降低通信距离 3.添加Expire/Cache-Control头 4.启用Gzip压缩文件 5.将css放在页面最上面 6.将script放在页面最下面 7.避免在css中使用表达式 8.将css, js都放在外部文件中 9.减少DNS查询 10.最小化css, js,减小文件体积 11.避免重定向 12.移除重复脚本 13.配置实体标签ETag 14.使用AJAX缓存,让网站内容分批加载,局部更新
什么是Etag?
当发送一个服务器请求时,浏览器首先会进行缓存过期判断。浏览器根据缓存过期时间判断缓存文件是否过期。
情景一:若没有过期,则不向服务器发送请求,直接使用缓存中的结果,此时我们在浏览器控制台中可以看到 200 OK(from cache) ,此时的情况就是完全使用缓存,浏览器和服务器没有任何交互的。
情景二:若已过期,则向服务器发送请求,此时请求中会带上①中设置的文件修改时间,和Etag
然后,进行资源更新判断。服务器根据浏览器传过来的文件修改时间,判断自浏览器上一次请求之后,文件是不是没有被修改过;根据Etag,判断文件内容自上一次请求之后,有没有发生变化
情形一:若两种判断的结论都是文件没有被修改过,则服务器就不给浏览器发index.html的内容了,直接告诉它,文件没有被修改过,你用你那边的缓存吧—— 304 Not Modified,此时浏览器就会从本地缓存中获取index.html的内容。此时的情况叫协议缓存,浏览器和服务器之间有一次请求交互。
情形二:若修改时间和文件内容判断有任意一个没有通过,则服务器会受理此次请求,之后的操作同①
① 只有get请求会被缓存,post请求不会
Expires和Cache-Control
Expires要求客户端和服务端的时钟严格同步。HTTP1.1引入Cache-Control来克服Expires头的限制。如果max-age和Expires同时出现,则max-age有更高的优先级。
Cache-Control: no-cache, private, max-age=0
ETag: abcde
Expires: Thu, 15 Apr 2014 20:00:00 GMT
Pragma: private
Last-Modified: $now // RFC1123 format
ETag应用:
Etag由服务器端生成,客户端通过If-Match或者说If-None-Match这个条件判断请求来验证资源是否修改。常见的是使用If-None-Match。请求一个文件的流程可能如下:
====第一次请求===
1.客户端发起 HTTP GET 请求一个文件;
2.服务器处理请求,返回文件内容和一堆Header,当然包括Etag(例如"2e681a-6-5d044840")(假设服务器支持Etag生成和已经开启了Etag).状态码200
====第二次请求===
客户端发起 HTTP GET 请求一个文件,注意这个时候客户端同时发送一个If-None-Match头,这个头的内容就是第一次请求时服务器返回的Etag:2e681a-6-5d0448402.服务器判断发送过来的Etag和计算出来的Etag匹配,因此If-None-Match为False,不返回200,返回304,客户端继续使用本地缓存;流程很简单,问题是,如果服务器又设置了Cache-Control:max-age和Expires呢,怎么办
答案是同时使用,也就是说在完全匹配If-Modified-Since和If-None-Match即检查完修改时间和Etag之后,
服务器才能返回304.(不要陷入到底使用谁的问题怪圈)
为什么使用Etag请求头?
Etag 主要为了解决 Last-Modified 无法解决的一些问题。
栈和队列的区别?
栈的插入和删除操作都是在一端进行的,而队列的操作却是在两端进行的。
队列先进先出,栈先进后出。
栈只允许在表尾一端进行插入和删除,而队列只允许在表尾一端进行插入,在表头一端进行删除
栈和堆的区别?
栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。
堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收。
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构。
7. 为什么利用多个域名来存储网站资源会更有效?
确保用户在不同地区能用最快的速度打开网站,其中某个域名崩溃用户也能通过其他域名访问网站
8.请说出三种减低页面加载时间的方法
a、压缩css、js文件
b、合并js、css文件,减少http请求
c、外部js、css文件放在最底下
d、减少dom操作,尽可能用变量替代不必要的dom操作
e、css sprite也算一种,多域名也算一种吧。
9.什么是FOUC?你如何来避免FOUC?
由于css引入使用了@import 或者存在多个style标签以及css文件在页面底部引入使得css文件加载在html之后导致页面闪烁、花屏
用link加载css文件,放在head标签里面
10.文档类型的作用是什么?你知道多少种文档类型?
影响浏览器对html代码的编译渲染
html2.0、xHtml、html5
11.浏览器标准模式和怪异模式之间的区别是什么?
盒模型解释不同
1.你使用过那些Javascript库?
jquery seajs yui
2.哈希表
具有散列(映射)特性的数据模型
3.闭包
子函数能被外部调用到,则该作用连上的所有变量都会被保存下来。
4.请解释什么是Javascript的模块模式,并举出实用实例。
js模块化mvc(数据层、表现层、控制层)
seajs
命名空间
5.你如何组织自己的代码?是使用模块模式,还是使用经典继承的方法?
对内:模块模式
对外:继承
用过哪些设计模式?
工厂模式:
主要好处就是可以消除对象间的耦合,通过使用工程方法而不是new关键字。将所有实例化的代码集中在一个位置防止代码重复。
工厂模式解决了重复实例化的问题 ,但还有一个问题,那就是识别问题,因为根本无法 搞清楚他们到底是哪个对象的实例。
function createObject(name,age,profession){
//集中实例化的函数
var obj = new Object();
obj.name = name;
obj.age = age;
obj.profession = profession;
obj.move = function () {
return this.name + ' at ' + this.age + ' engaged in ' + this.profession;
};
return obj;
}
var test1 = createObject('trigkit4',22,'programmer');//第一个实例
var test2 = createObject('mike',25,'engineer');//第二个实例构造函数模式
使用构造函数的方法 ,即解决了重复实例化的问题 ,又解决了对象识别的问题,该模式与工厂模式的不同之处在于:
1.构造函数方法没有显示的创建对象 (new Object());
2.直接将属性和方法赋值给 this 对象;
3.没有 renturn 语句。
9.你如何优化自己的代码?
代码重用
避免全局变量(命名空间,封闭空间,模块化mvc..)
拆分函数避免函数过于臃肿
注释
10.你能解释一下JavaScript中的继承是如何工作的吗?
子构造函数中执行父构造函数,并用call\apply改变this
克隆父构造函数原型上的方法
11.useragent是什么
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
一些网站常常通过判断 UA 来给不同的操作系统、不同的浏览器发送不同的页面,因此可能造成某些页面无法在某个浏览器中正常显示,但通过伪装 UA 可以绕过检测。
浏览器的 UA 字串标准格式为: 浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息
12.请尽可能详尽的解释AJAX的工作原理。
(1)创建XMLHttpRequest对象,也就是创建一个异步调用对象.
(2)创建一个新的HTTP请求,并指定该HTTP请求的方法、URL及验证信息.
(3)设置响应HTTP请求状态变化的函数.
(4)发送HTTP请求.
(5)获取异步调用返回的数据.
(6)使用JavaScript和DOM实现局部刷新.
var xmlHttp = new XMLHttpRequest();
xmlHttp.open('GET','demo.php','true');
xmlHttp.send()
xmlHttp.onreadystatechange = function(){
if(xmlHttp.readyState === 4 & xmlHttp.status === 200){
}
}
//使用promise封装
function getJSON(url) {
return new Promise(function(resolve, reject) {
var XHR = new XMLHttpRequest();
XHR.open('GET', url, true);
XHR.send();
XHR.onreadystatechange = function() {
if (XHR.readyState == 4) {
if (XHR.status 200) {
try {
var response = JSON.parse(XHR.responseText);
resolve(response);
} catch (e) {
reject(e);
}
} else {
reject(new Error(XHR.statusText));
}
}
}
})
}
getJSON(url).then(res => console.log(res));
当前状态readystate
0 代表未初始化。 还没有调用 open 方法
1 代表正在加载。 open 方法已被调用,但 send 方法还没有被调用
2 代表已加载完毕。send 已被调用。请求已经开始
3 代表交互中。服务器正在发送响应
4 代表完成。响应发送完毕
常用状态码status
404 没找到页面(not found)
403 禁止访问(forbidden)
500 内部服务器出错(internal service error)
200 一切正常(ok)
304 没有被修改(not modified)(服务器返回304状态,表示源文件没有被修改)
ajax的缺点
1、ajax不支持浏览器back按钮。
2、安全问题 AJAX暴露了与服务器交互的细节。
3、对搜索引擎的支持比较弱。
4、破坏了程序的异常机制。
5、不容易调试。
在IE浏览器下,如果请求的方法是GET,并且请求的URL不变,那么这个请求的结果就会被缓存。解决这个问题的办法可以通过在URL末尾添加上随机的时间戳参数('t'= + new Date().getTime())
讲讲304缓存的原理
服务器首先产生ETag,服务器可在稍后使用它来判断页面是否已经被修改。本质上,客户端通过将该记号传回服务器要求服务器验证其(客户端)缓存。
304是HTTP状态码,服务器用来标识这个文件没修改,不返回内容,浏览器在接收到个状态码后,会使用浏览器已缓存的文件
客户端请求一个页面(A)。 服务器返回页面A,并在给A加上一个ETag。 客户端展现该页面,并将页面连同ETag一起缓存。 客户再次请求页面A,并将上次请求时服务器返回的ETag一起传递给服务器。 服务器检查该ETag,并判断出该页面自上次客户端请求之后还未被修改,直接返回响应304(未修改——Not Modified)和一个空的响应体。
19: 说说你还知道的其他状态码,状态码的存在解决了什么问题
302/307 临时重定向
301 永久重定向
借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了什么错误
38: 简单介绍一下promise,他解决了什么问题
Promise,就是一个对象,用来传递异步操作的消息。有三种状态:Pending(进行中)、Resolved(已完成,又称 Fulfilled)和 Rejected(已失败)。
有了 Promise 对象,就可以将异步操作以同步操作的流程表达出来,避免了层层嵌套的回调函数。
45: XSS和CSRF攻击
xss:比如在一个论坛发帖中发布一段恶意的JavaScript代码就是脚本注入,如果这个代码内容有请求外部服务器,那么就叫做XSS
写一个脚本将cookie发送到外部服务器这就是xss攻击但是没有发生csrf
防范:对输入内容做格式检查 输出的内容进行过滤或者转译
CSRF:又称XSRF,冒充用户发起请求(在用户不知情的情况下),完成一些违背用户意愿的请求 如恶意发帖,删帖
比如在论坛发了一个删帖的api链接 用户点击链接后把自己文章给删了 这里就是csrf攻击没有发生xss
防范:验证码 token 来源检测
web开发中会话跟踪的方法有哪些
- cookie
- session
- url重写
- 隐藏input
- ip地址
21: 说说content-box和border-box,为什么看起来content-box更合理,但是还是经常使用border-box
content-box 是W3C的标准盒模型 元素宽度=内容宽度+padding+border
border-box 是ie的怪异盒模型 他的元素宽度等于内容宽度 内容宽度包含了padding和border
比如有时候在元素基础上添加内距padding或border会将布局撑破 但是使用border-box就可以轻松完成
常见web安全及防护原理
sql注入原理
就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
总的来说有以下几点:
1.永远不要信任用户的输入,要对用户的输入进行校验,可以通过正则表达式,或限制长度,对单引号和双"-"进行转换等。
2.永远不要使用动态拼装SQL,可以使用参数化的SQL或者直接使用存储过程进行数据查询存取。
3.永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
4.不要把机密信息明文存放,请加密或者hash掉密码和敏感的信息。
XSS原理及防范
Xss(cross-site scripting)攻击指的是攻击者往Web页面里插入恶意 html标签或者javascript代码。比如:攻击者在论坛中放一个
看似安全的链接,骗取用户点击后,窃取cookie中的用户私密信息;或者攻击者在论坛中加一个恶意表单,
当用户提交表单的时候,却把信息传送到攻击者的服务器中,而不是用户原本以为的信任站点。
XSS防范方法
首先代码里对用户输入的地方和变量都需要仔细检查长度和对”<”,”>”,”;”,”’”等字符做过滤;其次任何内容写到页面之前都必须加以encode,避免不小心把html tag 弄出来。这一个层面做好,至少可以堵住超过一半的XSS 攻击。
首先,避免直接在cookie 中泄露用户隐私,例如email、密码等等。
其次,通过使cookie 和系统ip 绑定来降低cookie 泄露后的危险。这样攻击者得到的cookie 没有实际价值,不可能拿来重放。
如果网站不需要再浏览器端对cookie 进行操作,可以在Set-Cookie 末尾加上HttpOnly 来防止javascript 代码直接获取cookie 。
尽量采用POST 而非GET 提交表单
XSS与CSRF有什么区别吗?
XSS是获取信息,不需要提前知道其他用户页面的代码和数据包。CSRF是代替用户完成指定的动作,需要知道其他用户页面的代码和数据包。
要完成一次CSRF攻击,受害者必须依次完成两个步骤:
1.登录受信任网站A,并在本地生成Cookie。
2.在不登出A的情况下,访问危险网站B。
CSRF的防御
▪ 服务端的CSRF方式方法很多样,但总的思想都是一致的,就是在客户端页面增加伪随机数。
▪ 通过验证码的方法
HTTP和HTTPS
HTTP协议通常承载于TCP协议之上,在HTTP和TCP之间添加一个安全协议层(SSL或TSL),这个时候,就成了我们常说的HTTPS。
默认HTTP的端口号为80,HTTPS的端口号为443。
为什么HTTPS安全
因为网络请求需要中间有很多的服务器路由器的转发。中间的节点都可能篡改信息,而如果使用HTTPS,密钥在你和终点站才有。https之所以比http安全,是因为他利用ssl/tls协议传输。它包含证书,卸载,流量转发,负载均衡,页面适配,浏览器适配,refer传递等。保障了传输过程的安全性
(内容4)——————
各个浏览器中css表现的差异性(浏览器兼容问题):
(http://www.douban.com/group/topic/4629864/)
(http://blog.csdn.net/chuyuqing/article/details/37561313)
(http://www.iefans.net/ie-9-css-bug/)
1,各浏览器下,margin与padding显示差异
解决办法:CSS reset
2,block+float+水平margin,IE6里的间距比超过设置的间距(横向布局)
解决办法:diaplay:inline
(不用担心内联元素无宽高,因为float会让inline元素haslayout,让inline元素表现的和inline-block元素一样有宽高和垂直内外边距)
[我们最常用的就是div+CSS布局了,而div就是一个典型的块属性标签,横向布局的时候我们通常都是用div float实现的,横向的间距设置如果用margin实现,这就是一个必然会碰到的兼容性问题]
3,inline+(display:block)+float+水平margin,IE6里的间距比超过设置的间距
说明:该情况与上面的差不多,只是此处的元素一开始是内联元素,加了display:block的CSS属性.因为它本身就是行内属性标签,所以我们再加上display:inline的话,它的高宽就不可设了。这时候我们还需要在display:inline后面加入display:talbe
解决办法:display:inline;display:table;
4,IE6对margin:0 auto;不会正确的进行解析
解决办法:
在父元素中使用text-align:center,在元件中使用text-align:left
5,无法设置微高(一般小于10px):
说明:当设置元素高度小于10px时,IE6和IE7不受控制,超出设置的高度
产生原因:IE不允许原件的高度小于字体的高度
解决办法1:设置字体大小:font-size:0;
解决办法2:给超出高度的标签设置overflow:hidden
解决办法3:设置行高line-height小于你设置的高度
6,子元件撑破父元件
原因:父元件设置了overflow:auto属性,子元件会从父元件中撑破出来
解决办法:父元件中设置position:relative;
7,IE无法解析min-height和min-width
解决办法1:
selector{
min-height:150px;
height:auto !important;
height:150px;
}
解决办法2:
selector{
min-height:150px;
height:150px;
}
heml>body selector{
height:auto;
}
8,使用ul li时,li与li之间会空行
解决办法1:设置li selector{height:**px;}
解决办法2:li selector{float:left;clear:left;}
解决办法3:li{display:inline}
css sprite是什么,有什么优缺点
概念:将多个小图片拼接到一个图片中。通过background-position和元素尺寸调节需要显示的背景图案。
优点:
- 减少HTTP请求数,极大地提高页面加载速度
- 增加图片信息重复度,提高压缩比,减少图片大小
- 更换风格方便,只需在一张或几张图片上修改颜色或样式即可实现
缺点:
- 图片合并麻烦
- 维护麻烦,修改一个图片可能需要从新布局整个图片,样式
css hack原理及常用hack
原理:利用不同浏览器对CSS的支持和解析结果不一样编写针对特定浏览器样式。常见的hack有1)属性hack。2)选择器hack。3)IE条件注释
CSS hack:
+:IE6,IE7
_:IE6
\9:IE6,IE7,IE8
\0:IE8,IE9
\9\0:IE9
!important:All(IE6是有条件的支持)
常用的CSS reset:
(http://blog.bingo929.com/css-reset-collection.html)
margin:0;
padding:0;
border:0;
...
实现三个DIV等分排布在一行(考察border-box)
1.设置border-box width33.3%
2.flexbox flex:1
设置width的flex元素,flex属性值是多少
flex属性是flex-grow, flex-shrink 和 flex-basis的简写
flex-grow属性定义项目的放大比例,默认为0
flex-shrink属性定义了项目的缩小比例,默认为1
flex-basis属性定义了项目的固定空间
怎么实现从一个DIV左上角到右下角的移动,有哪些方法,都怎么实现
改变left值为window宽度-div宽度 top值为window高度-div高度
jquery的animate方法
css3的transition
盒子模型
1)盒子模型有两种,W3C和IE盒子模型
(1)W3C定义的盒子模型包括margin、border、padding、content ,元素的width=content的宽度
(2)IE盒子模型与W3C的盒子模型唯一区别就是元素的宽度,元素的width=content+padding+border
2)个人理解和心得,要记住在面试时,我们和面试官是平等的,而且面试官也非常欣赏喜欢交谈的人,在面试的时候能够去表达自己的想法,往往会给面试官留下非常好的印象。例如上面的盒子模型,示范如下:
我个人认为W3C定义盒子模型与IE定义的盒子模型,IE定义的比较合理,元素的宽度应该包含border(边框)和padding(填充),这个和我们现实生活的盒子是一样的,W3C也认识到自己的问题了,所以在CSS3中新增了一个样式box-sizing,包含两个属性content-box 和 border-box。
(1) content-box 元素的width=content+padding+border
.test1{ box-sizing:content-box; width:200px; padding:10px; border:15px solid #eee; }
(2) border-box 元素的width=width(用样式指定的宽度)
.test1{ box-sizing:border-box; width:200px; padding:10px; border:15px solid #eee; }
加分项回答(自己比较独到理解)
1.对于行级元素,margin-top和margin-bottom对于上下元素无效,margin-left和margin-right有效
2.对于相邻的块级元素margin-bottom和margin-top 取值方式
1) 都是正数: 取最大值
距离=Math.max(margin-bottom,margin-top)
2) 都是负数: 取最小值
距离=Math.min(margin-bottom,margin-top)
3)上面是正数,下面是负数或者 上面是负数,下面是正数: 正负相加
距离=margin-bottom+margin-top
对于盒子的选择:
需要依靠最上面的Doctype来看,如果没有声明Doctype,则按照浏览器会根据自己的行为去理解网页;声明后各浏览器会按照W3C标准去解释你的盒子,网页就能在各个浏览器中显示一致了
JS的数据类型(http://blog.sina.com.cn/s/blog_6fd4b3c10101d0va.html)
基本数据类型(5):string,number,null,undefined,boolean
引用类型:object,array,function;
数据类型 typeof
string string
number number
boolean boolean
undefined undefined
null object
object object
array object
function function
(NaN) (number)
(Error) (Function)
区分基本数据类型:typeof;
区分引用数据类型:instanceof(instanceof还可以检测到具体的是什么实例,可以检测是否是正则表达式)
eg:[1,2,3,4] instanceof Array; //true
\d{3} instanceof RegExp; //true
区分各数据类型:
Object.prototype.toString.call(val).slice(8,-1);
eg:Object.prototype.toString.call([1,2,3]).slice(8,-1); //Array
obj instanceof typeName;
eg:[1,2,3] instanceof Array; //true
obj.constructor.toString().indexof(typeName);
eg:[1,2,3].constructor.toString().indexof("Array");
//9(只要值不为-1,即为typeName类型)
会不会SEO(搜索引擎优化)
1,站内优化
使得网站在搜索引擎上的友好度和站内用户的良好体验度上升
让网站在搜索引擎的排名靠前并且得到很好的客户转换率
2,站外优化
通过SEO手段帮助网站和网站所属企业进行品牌推广
前端需要注意哪些SEO
- 合理的title、description、keywords:搜索对着三项的权重逐个减小,title值强调重点即可,重要关键词出现不要超过2次,而且要靠前,不同页面title要有所不同;description把页面内容高度概括,长度合适,不可过分堆砌关键词,不同页面description有所不同;keywords列举出重要关键词即可
- 语义化的HTML代码,符合W3C规范:语义化代码让搜索引擎容易理解网页
- 重要内容HTML代码放在最前:搜索引擎抓取HTML顺序是从上到下,有的搜索引擎对抓取长度有限制,保证重要内容一定会被抓取
- 重要内容不要用js输出:爬虫不会执行js获取内容
- 少用iframe:搜索引擎不会抓取iframe中的内容
- 非装饰性图片必须加alt
- 提高网站速度:网站速度是搜索引擎排序的一个重要指标
html5新特性?
1,webStorage(sessionStorage,localStorage);
2,onmessage,postmessage解决跨域问题;
3,新的文档类型 (New Doctype):
之前的声明文档类型:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">在H5中失效,H5只需要用
<!DOCTYPE html>即可完成文档声明
4,新增一系列语义化标签:header,footer,figure+figcaption,article,nav等
5,新增属性 :
占位符 (placeholder:
在HTML4或XHTML中,你需要用JavaScript来给文本框添加占位符。
比如,你可以提前设置好一些信息,当用户开始输入时,文本框中的文字就消失。而在HTML5中,新的“placeholder”就简化了这个问题;
input新增属性:required(必填项);pattern(正则限定输入);
6,audio(音频)与video(视频);
7,<script async="async">
事件模型
DOM事件模型是如何的,编写一个EventUtil工具类实现事件管理兼容
- DOM事件包含捕获(capture)和冒泡(bubble)两个阶段:捕获阶段事件从window开始触发事件然后通过祖先节点一次传递到触发事件的DOM元素上;冒泡阶段事件从初始元素依次向祖先节点传递直到window
- 标准事件监听elem.addEventListener(type, handler, capture)/elem.removeEventListener(type, handler, capture):handler接收保存事件信息的event对象作为参数,event.target为触发事件的对象,handler调用上下文this为绑定监听器的对象,event.preventDefault()取消事件默认行为,event.stopPropagation()/event.stopImmediatePropagation()取消事件传递
- 老版本IE事件监听elem.attachEvent('on'+type, handler)/elem.detachEvent('on'+type, handler):handler不接收event作为参数,事件信息保存在window.event中,触发事件的对象为event.srcElement,handler执行上下文this为window使用闭包中调用handler.call(elem, event)可模仿标准模型,然后返回闭包,保证了监听器的移除。event.returnValue为false时取消事件默认行为,event.cancleBubble为true时取消时间传播
- 通常利用事件冒泡机制托管事件处理程序提高程序性能。
事件绑定
(http://www.cnblogs.com/iloveyoucc/archive/2012/08/15/2639874.html)
1,绑定元素属性:事件属性名称由事件类型外加一个on前缀构成
eg:<input type="button" name="myButton" onClick="myFunc()">
可以支持开发者把参数传递给事件处理器函数
2,绑定对象属性:
eg:document.forms[0].myButton.onclick = myFunc
没有办法向事件函数传递参数
3,绑定IE4+支持<script for="id" event="eventName">标识
for属性的值必须是元素的id;必须把事件的名称(onmouseover,onclick等等)分配给 event属性
eg:<input type="button" name="myButton" id="button1">
<script for="button1" event="onclick">
// script statements here
</script>
标识中的语句可以调用页面上其它地方定义的任何函数(或者从.js文件中导入的函数)
这种绑定方式意味着您必须为每一个元素和每一个事件创建一个<script for event>标识
4,IE5+支持:elemObject.attachEvent("eventName", functionReference);
eg:document.getElementById("").attachEvent("onclick",function(){...});
注意:不能在元素被载入浏览器之前执行这个语句;
该对象的引用在相应的 HTML 按键元素被浏览器创建之前,都是无效的;
要让这样的绑定语句或者在页面的底部运行,或者在body元素的onLoad
事件处理器调用的函数中运行
5,W3C DOM的addEventListener()方法
eg:docuemnt.getElementById("").addEventListener("click",function(){...},false);
第三个参数表示是否在捕获阶段进行处理
【注意方法4和方法5中,事件的名字:IE中要加前缀"on",W3C不用加前缀】
jsonp&&跨域问题
外边距折叠(collapsing margins)
什么情况下外边距会合并
外边距合并指的是,当两个垂直外边距相遇时,它们将形成一个外边距。
合并后的外边距的高度等于两个发生合并的外边距的高度中的较大者。
正则式(http://deerchao.net/tutorials/regex/regex.htm)
毗邻的两个或多个margin会合并成一个margin,叫做外边距折叠。规则如下:
- 两个或多个毗邻的普通流中的块元素垂直方向上的margin会折叠
- 浮动元素/inline-block元素/绝对定位元素的margin不会和垂直方向上的其他元素的margin折叠
- 创建了块级格式化上下文的元素,不会和它的子元素发生margin折叠
- 元素自身的margin-bottom和margin-top相邻时也会折叠
stacking context,布局规则
z轴上的默认层叠顺序如下(从下到上):
- 根元素的边界和背景
- 常规流中的元素按照html中顺序
- 浮动块
- positioned元素按照html中出现顺序
如何创建stacking context:
- 根元素
- z-index不为auto的定位元素
- a flex item with a z-index value other than 'auto'
- opacity小于1的元素
- 在移动端webkit和chrome22+,z-index为auto,position: fixed也将创建新的stacking context
如何创建块级格式化上下文(block formatting context),BFC有什么用
如何理解bfc(http://www.cnblogs.com/lhb25/p/inside-block-formatting-ontext.html)
BFC:块级格式化上下文【在css3中叫Flow Root】是一个独立布局环境,相邻盒子margin垂直方向会重叠。
如何触发生成一个BFC:
- 根元素
- 浮动元素(
float不是none) - 绝对定位元素(
position取值为absolute或fixed) 块容器【block containers】display取值为inline-block,table-cell,table-caption,flex,inline-flex之一的元素块盒子【blok boxes】overflow不是visible的元素
作用:
- 可以包含浮动元素
- 不被浮动元素覆盖
- 阻止父子元素的margin折叠
HTTP的工作原理
客户机与服务器建立连接后,发送一个请求给服务器,请求格式为:统一资源标识符、协议版本号。服务器收到请求的信息(包括请求行,请求头,请求体)。服务器接收到请求后,给予相应的响应信息,格式为一个状态行(包括响应行,响应头,响应体)。
在internet上,http通讯通常发生在TCP/IP连接之上。缺省端口是TCP的80端口。
基于HTTP协议的客户/服务器模式的信息交换过程,分为四个过程:建立连接、发送请求信息、发送响应信息、关闭连接。
服务器可能同时接受多个请求,这时就会产生多个sessoin,每个session分别处理各自的请求。
一个HTTP请求的工作过程
一次HTTP操作称为一个事务,其工作整个过程如下:
1)、地址解析
如用客户端浏览器请求这个页面:http://localhost.com:8080/index.htm
从中分解出协议名、主机名、端口、对象路径等部分,对于我们的这个地址,解析得到的结果如下:
协议名:http
主机名:localhost.com
端口:8080
对象路径:/index.html
在这一步,需要域名系统DNS解析域名localhost.com,得主机的IP地址。
2)、封装HTTP请求数据包
把以上部分结合本机自己的信息,封装成一个HTTP请求数据包
3)封装成TCP包,建立TCP连接(TCP的三次握手)
在HTTP工作开始之前,客户机(Web浏览器)首先要通过网络与服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。这里是8080端口
4)客户机发送请求命令
建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可内容。
5)服务器响应
服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
实体消息是服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
6)服务器关闭TCP连接
一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码
Connection:keep-alive
TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
服务器将响应信息传给客户端,响应体中的内容可能是一个html页面,也可能是一张图片,通过输入流将其读出,并写回到显示器上。
一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?
分为4个步骤:
(1),当发送一个URL请求时,不管这个URL是Web页面的URL还是Web页面上每个资源的URL,浏览器都会开启一个线程来处理这个请求,同时在远程DNS服务器上启动一个DNS查询。这能使浏览器获得请求对应的IP地址。
(2), 浏览器与远程`Web`服务器通过`TCP`三次握手协商来建立一个`TCP/IP`连接。该握手包括一个同步报文,一个同步-应答报文和一个应答报文,这三个报文在 浏览器和服务器之间传递。该握手首先由客户端尝试建立起通信,而后服务器应答并接受客户端的请求,最后由客户端发出该请求已经被接受的报文。
(3),一旦`TCP/IP`连接建立,浏览器会通过该连接向远程服务器发送`HTTP`的`GET`请求。远程服务器找到资源并使用HTTP响应返回该资源,值为200的HTTP响应状态表示一个正确的响应。
(4),此时,`Web`服务器提供资源服务,客户端开始下载资源。
请求返回后,浏览器会解析`HTML`生成`DOM Tree`,其次会根据CSS生成CSS Rule Tree,而`javascript`又可以根据`DOM API`操作`DOM`说说TCP传输的三次握手四次挥手策略
为了准确无误地把数据送达目标处,TCP协议采用了三次握手策略。用TCP协议把数据包送出去后,TCP不会对传送 后的情况置之不理,它一定会向对方确认是否成功送达。握手过程中使用了TCP的标志:SYN和ACK。
发送端首先发送一个带SYN标志的数据包给对方。接收端收到后,回传一个带有SYN/ACK标志的数据包以示传达确认信息。
最后,发送端再回传一个带ACK标志的数据包,代表“握手”结束。
若在握手过程中某个阶段莫名中断,TCP协议会再次以相同的顺序发送相同的数据包。
断开一个TCP连接则需要“四次握手”:
▪ 第一次挥手:主动关闭方发送一个FIN,用来关闭主动方到被动关闭方的数据传送,也就是主动关闭方告诉被动关闭方:我已经不 会再给你发数据了(当然,在fin包之前发送出去的数据,如果没有收到对应的ack确认报文,主动关闭方依然会重发这些数据),但是,此时主动关闭方还可 以接受数据。
▪ 第二次挥手:被动关闭方收到FIN包后,发送一个ACK给对方,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号)。
▪ 第三次挥手:被动关闭方发送一个FIN,用来关闭被动关闭方到主动关闭方的数据传送,也就是告诉主动关闭方,我的数据也发送完了,不会再给你发数据了。
▪ 第四次挥手:主动关闭方收到FIN后,发送一个ACK给被动关闭方,确认序号为收到序号+1,至此,完成四次挥手。
TCP和UDP的区别
TCP(Transmission Control Protocol,传输控制协议)是基于连接的协议,也就是说,在正式收发数据前,必须和对方建立可靠的连接。一个TCP连接必须要经过三次“对话”才能建立起来
UDP(User Data Protocol,用户数据报协议)是与TCP相对应的协议。它是面向非连接的协议,它不与对方建立连接,而是直接就把数据包发送过去!
UDP适用于一次只传送少量数据、对可靠性要求不高的应用环境。
关于Http 2.0 你知道多少?
HTTP/2引入了“服务端推(server push)”的概念,它允许服务端在客户端需要数据之前就主动地将数据发送到客户端缓存中,从而提高性能。
HTTP/2提供更多的加密支持
HTTP/2使用多路技术,允许多个消息在一个连接上同时交差。
它增加了头压缩(header compression),因此即使非常小的请求,其请求和响应的header都只会占用很小比例的带宽。
瀑布流布局(基于多栏列表流体布局实现)如何高性能的实现最优排序后的多栏列表布局?
什么是瀑布流?
瀑布流布局由pinterest.com网站首创,它的原理是:先通过计算出一排能够容纳几列元素,然后寻找各列之中所有元素高度之和的最小者,并将新的元素添加到该列上,然后继续寻找所有列的各元素之和的最小者,继续添加至该列上,如此循环下去,直至所有元素均能够按要求排列为止;
瀑布流视图与UITableView类似,但是相对复杂一点.UITableView只有一列,可以有多个小节(section),每一个小节(section)可以有多行(row).
瀑布流呢,可以有多列,每一个item(单元格)的高度可以不相同,但是宽度必须一样.排列的方式是,从左往右排列,哪一列现在的总高度最小,就优先排序把item(单元格)放在这一列.这样排完所有的单元格后,可以保证每一列的总高度都相差不大,不至于,有的列很矮,有的列很高.这样就很难看了.
绝对定位(css)+javascript+ajax+json。简单一点如果不做滚动加载的话就是绝对定位(css)+javascript了,ajax和json是滚动加载更多内容的时候用到的。
实现思路:
1、计算页面的宽度,计算出页面可放数据块的列数(如上图所示就有6列)。
2、将各个数据块的高度尺寸记入数组中(需要等所有图片加载完成,否则无法知道图片的高度)。
3、用绝对定位先将页面第一行填满,因为第一行的top位置都是一样的,然后用数组记录每一列的总高度。
4、继续用绝对定位将其他数据块定位在最短的一列的位置之后然后更新该列的高度。
5、当浏览器窗口大小改变时,重新执行一次上面1-4步以重新排放(列数随页面宽度而改变,因而需要重新排放)。
6、滚动条滚动到底部时加载新的数据进来后也是定位在最短的一列的位置之后然后更新该列的高度。
今天四处闲逛,看到迅雷UEDxwei兄写了篇名为“浅谈个人在瀑布流网页的实现中遇到的问题和解决方法”的文章,我两只沉沉的萝卜眼顿时放出无数闪亮的小星星。
原文重点如下:
瀑布流的排序算法,参考demo1,思路非常简单,我们把瀑布流拆成三个部分来看:容器、列、格子
1.先计算当前屏幕最多能容纳几列瀑布,其值为 "向下取整(屏幕可见区域宽度/(格子宽度+间距))";
2.为了保证容器的居中,将容器的宽度设置为 列数* (格子宽度+间距) – 间距,这里需要注意的是 当容器的宽度计算出来之后再显示,否则会造成页面宽度的抖动,影响体验。;
3.排序开始,先把前N(N为列数)个格子分别放到每一列中,然后每次寻找高度最小的一列,把格子放进去(left值为列序号*(格子宽度+间距),top值为 列高+间距),并刷新列的高度,遍历所有格子直到所有的格子都被排序。
最后将事件句柄绑定到window.onload和window.onresize上,一个瀑布流布局的页面就出来了。
这样的排序算法看起来很美好,可真正结合异步加载数据应用到页面里还要解决以下几个问题
1.当缩放浏览器窗口时会不断地触发事件,如果每次都响应的话会狂耗性能,需要在缩放动作结束后再执行重排方法。
第一个问题我是用setTimeout和clearTimeout来解决的,思路是窗口变化之后开始计时,如果窗口还在变换则从新开始计时,窗口不再变化则延时(很短的时间)触发重排事件。暂时只想到这个,这里应该还有更好的方法。
代码如下
var re;window.onresize = function() {clearTimeout(re);re = setTimeout(resize,100);};
2.页面滚动到底部请求数据成功之后只对新增的节点重排。
第二个问题在于如果每次有新的数据加载,都要对整个容器内的节点进行重排,非常消耗性能。解决思路:
a.将列保存在全局数组中,每次重排或者新增格子之后更新数组的数据,这样下次执行排序算法的时候可以直接调用。
b.将新增格子保存在数组中作为参数传递给排序算法,仅对新格子进行遍历和操作。
3.如果服务器无法给出图片高度,需要在图片加载完毕之后再进行重排。
第三个问题是如果服务器无法给出图片尺寸,那么必须在图片完全加载完毕之后才可进行排序(因为高度是实时获取的,图片不全高度有误差),这里没有什么好办法,只能遍历图片,每张图片加载成功后执行一个回调函数,将加载成功的图片数量+1,当加载成功的图片数量等于图片总数的时候执行排序方法。缺点是有一张图片加载不成功就无法看到所有的,真正项目中还是需要在异步加载数据的时候获取图片尺寸。
好了,以上就是在这次瀑布流实现过程中遇到的问题和解决方法,由一开始加载3-4屏就卡死到现在可以无限加载(ff,chrome),深感优化js的必要性和无限性。
pinterest以及上面迅雷UED xwei的瀑布流demo(至少在FireFox下还是有致命的显示bug的)都是采用的绝对定位实现的,有相对复杂的位置计算。
我一向不喜欢吃别人嚼过的米饭,于是尝试使用另外的原理实现。我是个流体布局控,对绝对定位啊、浮动啊什么的一向没什么好感,于是,这里要介绍的就是基于多栏列表流体布局实现的瀑布流布局效果。
大致结构、布局见下面的手绘图:

没有复杂的位置计算,不需要知道里面元素的高度以及宽度,且易理解,关键是具体实现~~
四、原理
第一次进入的时候,根据浏览器宽度以及每列宽度计算出列表个数,然后不管三七二十一,每列先加载个5张图片再说。
当滚动的时候,对每一列的底部位置做检测,如果在屏幕中或屏幕上方,则立即append一个新图片(注意:为了简化代码,提高性能,同时便于演示等,这里只append了一个)。因为,滚动时连续的,因此,我们实际看到的效果是图片不断load出来。
当浏览器宽度改变的时候,页面上有个id为waterFallDetect空span标签,这个标签作用有两个:一是实现两端对齐效果,二是用来检测瀑布流布局是否需要刷新。
检测原理如下:
该span标签宽度与一个列表宽度一致,当浏览器宽度变小的时候,如果小到一定程度,显然,浏览器最右边的列表就会跑到下一行,把空span挤到后面去,空span发生较大的水平位移,显然,可以通知脚本,布局需要刷新;当浏览器宽度变大的时候,如果变大的尺寸超过一列的宽度,显然,这个空span灰跑到第一行去,同样是发生较大的水平位移,因此,又可以通知脚本刷新瀑布流布局了。
这个方法的好处是几乎没有计算就可以一点不差地知道何时瀑布流布局需要刷新。这显然要比设置resize定时器+位置尺寸计算要简单高性能地多。
滚动时的页面刷新是基于HTML字符串的处理,而不是更改每个DOM元素的位置(这是绝对定位实现的处理),因此,这里的效率显然更高。
五、总结:基于多栏列表流体布局瀑布流效果优点
- 简单:最大限度利用了浏览器的流体特性进行布局,省去了很多计算的麻烦;新人更易懂和上手
- 更好的性能:这个体现在多处,如浏览器宽度改变,瀑布流刷新时候的效率等
- 无需知晓尺寸:如果是要绝对定位实现瀑布流,必须知道每个小模块的高度以及宽度(否则无法定位),而基于列表的布局则无需知道高宽
您可以狠狠地点击这里:基于多栏列表瀑布流布局demo
欢迎各种滚动,缩放等测试。低版本IE浏览器也是兼容滴。问题嘛也是有滴,就是滚动到一定位置再F5刷新的时候,部分加载的内容有丢失,需要重新滚动加载。这个嘛,我个人觉得小小demo,没必要折腾啦(实际上要实现也比较容易,改动如下:每次滚动不是append一个节点,而是连续回调直到加载到屏幕下方。不懂什么意思?花点功夫看看JS实现原理就会明白了)~~
瀑布流布局延伸:动态规划算法
出处:经典算法(2)——0/1背包问题(动态规划法)
0-1背包问题:有一个贼在偷窃一家商店时,发现有n件物品,第i件物品价值vi 元,重wi 磅,此处vi 与wi 都是整数。他希望带走的东西越值钱越好,但他的背包中至多只能装下W磅的东西,W为一整数。应该带走哪几样东西?这个问题之所以称为0-1背包,是因为每件物品或被带走;或被留下;小偷不能只带走某个物品的一部分或带走同一物品两次。
在分数(部分)背包问题(fractional knapsack problem) 中,场景与上面问题一样,但是窃贼可以带走物品的一部分,而不必做出0-1的二分选择。可以把0-1背包问题的一件物品想象成一个金锭,而部分问题中的一件物品则更像金沙。
两种背包问题都具有最优子结构性质。对0-1背包问题,考虑重量不超过W而价值最高的装包方案。如果我们将商品j从此方案中删除,则剩余商品必须是重量不超过W-wj的价值最高的方案(小偷只能从不包括商品j的n-1个商品中选择拿走哪些)。
虽然两个问题相似,但我们用贪心策略可以求解背包问题,而不能求解0-1背包问题,为了求解部分数背包问题,我们首先计算每个商品的每磅价值vi /wi。遵循贪心策略,小偷首先尽量多地拿走每磅价值最高的商品,如果该商品已全部拿走而背包未装满,他继续尽量多地拿走每磅价值第二高的商品,依次类推,直到达到重量上限W。因此,通过将商品按每磅价值排序,贪心算法的时间运行时间是O(nlgn)。
为了说明贪心这一贪心策略对0-1背包问题无效,考虑下图所示的问题实例。此例包含3个商品和一个能容纳50磅重量的背包。商品1重10磅,价值60美元。商品2重20磅,价值100美元。商品3重30磅,价值120美元。因此,商品1的每磅价值为6美元,高于商品2的每磅价值5美元和商品3的每磅价值4美元。因此,上述贪心策略会首先拿走商品1。但是,最优解应该是商品2和商品3,而留下商品1。拿走商品1的两种方案都是次优的。
但是,对于分数背包问题,上述贪心策略首先拿走商品1,是可以生成最优解的。拿走商品1的策略对0-1背包问题无效是因为小偷无法装满背包,空闲空间降低了方案的有效每磅价值。在0-1背包问题中,当我们考虑是否将一个商品装入背包时,必须比较包含此商品的子问题的解与不包含它的子问题的解,然后才能做出选择。这会导致大量的重叠子问题——动态规划的标识。

例子 :0-1背包问题。总共有三件物品,背包可容纳5磅的东西,物品1重1磅,价值60元。物品2重2磅,价值100元,物品3重3磅,价值120元。怎么才能最大化背包所装物品的价值。
解答 :我们可以得出物品一每磅价值60元,大于物品二的每磅50元和物品3的每磅40元。如果按照贪心算法的话就要取物品1。然而最优解应该取的是物品2和3,留下了1.
在0-1背包问题中不应取物品1的原因在于这样无法将背包填满,空余的空间就降低了货物的有效每磅价值。
我们可以利用动态规划来解0-1背包问题。
假设c[i]表示第i件物品的重量,w[i]表示第i件物品的价值,f[i][j]表示背包容量为j,可选物品为物品1~i时,背包能获得的最大价值。
用动态规划求解即先求出背包容量较小时能获得的最大价值,然后根据背包容量较小时的结果求出背包容量较大时的结果,也就是一个递推的填表过程。
当没有可选物品时,背包能获得的最大价值为0。即表格可初始化为

填表过程(即状态转移方程)是:

"j<c[i]"表示第i件物品的重量大于当前背包的容量j,此时显然不放第i件物品。下面解释上述方程在“其它“情况下的意义:”将前i件物品放入容量为j背包中“这个问题,如果只考虑第i件物品放或者不放,那么就可以转化为只涉及前i-1件物品的问题,即:
1. 如果不放第i件物品,则问题转化为只涉及”前i-1件物品放入容量为j的背包中“
2. 如果放第i件物品,则问题转化为”前i-1件物品放入剩下的容量为j-c[i]的背包中“,此时能获得的最大价值就是f[i-1][j-c[i]]再加上通过放入第i件物品获得的价值获得的价值w[i]。
则在”其他“情况下,f[i][j]就是1、2中最大的那个值。
显然,可以从左下角利用状态转移方程依次逐行填表,得到f[3][5](表示可选物品为1、2、3,且背包容量为5时,能获得的最大价值),可见动态规划的确即为一个递推的过程。填表后如下表所示:

代码如下:
int N = 3,V = 5;
//N是物品数量,V是背包容量
int c[4] = {
0,
1,
2,
3
};
int w[4] = {
0.60.100.120
};
for
(i = 0; i <= V; i++) {
//逐行填表,i表示当前可选物品数,j表示当前背包的容量
f[i][0] = 0;
for
(j = 1; j <= V; j++) {
if
(j < c[i]) {
f[i][j] = f[i - 1][j];
}
else
{
f[i][j] = max(f[i - 1][j], f[i - 1][j - c[i]] + w[i]);
}
}
}
|
背包问题初始化
求最优解的背包问题中,事实上有两种不太相同的问法。有的题目要求”恰好装满背包“时的最优解,有的题目则没有要求必须把背包装满。这两种问法的区别是求解时的初始化不同。
如果是第一种问法,要求恰好装满背包,那么在初始化时除了f[0][0]为0,其他f[0][1~V]均设为-∞ ,这样就可以包装最终得到的解释一种恰好装满背包的最优解。
如果并没有要求必须是把背包装满,而是只希望价格尽量大,初始化时应该将f[0][1~V]全部设为0.
这是为什么呢?可以这样理解:初始化的f数组事实上就是在没有任何物品可以放入背包时的合法状态。如果要求背包恰好装满,那么此时只有容量为0的背包可以在什么也不装且价值为0的情况下被”恰好装满“,其他容量的背包均没有合法的解,属于未定义的状态,应该被赋值为-∞。如果背包并非被必须装满,那么任何容量的背包都有一个合法解”什么都不装“,这个解的价值为0,所以初始状态的值也就全部为0了。
如何水平居中一个元素
如果需要居中的元素为常规流中inline元素,为父元素设置text-align: center;即可实现
如果需要居中的元素为常规流中block元素,1)为元素设置宽度,2)设置左右margin为auto。3)IE6下需在父元素上设置text-align: center;,再给子元素恢复需要的值
<body>
<div class="content">
aaaaaa aaaaaa a a a a a a a a
</div>
</body>
<style>
body {
background: #DDD;
text-align: center; /* 3 */
}
.content {
width: 500px; /* 1 */
text-align: left; /* 3 */
margin: 0 auto; /* 2 */
background: purple;
}
</style>
如果需要居中的元素为浮动元素,1)为元素设置宽度,2)position: relative;,3)浮动方向偏移量(left或者right)设置为50%,4)浮动方向上的margin设置为元素宽度一半乘以-1
<body>
<div class="content">
aaaaaa aaaaaa a a a a a a a a
</div>
</body>
<style>
body {
background: #DDD;
}
.content {
width: 500px; /* 1 */
float: left;
position: relative; /* 2 */
left: 50%; /* 3 */
margin-left: -250px; /* 4 */
background-color: purple;
}
</style>
如果需要居中的元素为绝对定位元素,1)为元素设置宽度,2)偏移量设置为50%,3)偏移方向外边距设置为元素宽度一半乘以-1
<body>
<div class="content">
aaaaaa aaaaaa a a a a a a a a
</div>
</body>
<style>
body {
background: #DDD;
position: relative;
}
.content {
width: 800px;
position: absolute;
left: 50%;
margin-left: -400px;
background-color: purple;
}
</style>
如果需要居中的元素为绝对定位元素,1)为元素设置宽度,2)设置左右偏移量都为0,3)设置左右外边距都为auto
<body>
<div class="content">
aaaaaa aaaaaa a a a a a a a a
</div>
</body>
<style>
body {
background: #DDD;
position: relative;
}
.content {
width: 800px;
position: absolute;
margin: 0 auto;
left: 0;
right: 0;
background-color: purple;
}
</style>
如何竖直居中一个元素
参考资料:6 Methods For Vertical Centering With CSS。 盘点8种CSS实现垂直居中
需要居中元素为单行文本,为包含文本的元素设置大于font-size的line-height:
<p class="text">center text</p>
<style> .text { line-height: 200px; } </style>
尽可能的提出实现水平居中和垂直居中的解决方案?
来源:用CSS/CSS3 实现 水平居中和垂直居中的完整攻略
水平居中:行内元素解决方案
只需要把行内元素包裹在一个属性display为block的父层元素中,并且把父层元素添加如下属性即可:
.parent {
text-align:center;
}
水平居中:块状元素解决方案
.item {
/* 这里可以设置顶端外边距 */
margin: 10px auto;
}
水平居中:多个块状元素解决方案
将元素的display属性设置为inline-block,并且把父元素的text-align属性设置为center即可:
.parent {
text-align:center;
}
水平居中:多个块状元素解决方案 (使用flexbox布局实现)
使用flexbox布局,只需要把待处理的块状元素的父元素添加属性display:flex及justify-content:center即可:
.parent {
display:flex;
justify-content:center;
}
垂直居中:单行的行内元素解决方案
.parent {
background: #222;
height: 200px;
}
/* 以下代码中,将a元素的height和line-height设置的和父元素一样高度即可实现垂直居中 */
a {
height: 200px;
line-height:200px;
color: #FFF;
}
垂直居中:多行的行内元素解决方案
组合使用display:table-cell和vertical-align:middle属性来定义需要居中的元素的父容器元素生成效果,如下:
.parent {
background: #222;
width: 300px;
height: 300px;
/* 以下属性垂直居中 */
display: table-cell;
vertical-align:middle;
}
垂直居中:已知高度的块状元素解决方案
.item{
top: 50%;
margin-top: -50px; /* margin-top值为自身高度的一半 */
position: absolute;
padding:0;
}
水平垂直居中:已知高度和宽度的元素解决方案1
这是一种不常见的居中方法,可自适应,比方案2更智能,如下:
.item{
position: absolute;
margin:auto;
left:0;
top:0;
right:0;
bottom:0;
}
水平垂直居中:已知高度和宽度的元素解决方案2
.item{
position: absolute;
top: 50%;
left: 50%;
margin-top: -75px; /* 设置margin-left / margin-top 为自身高度的一半 */
margin-left: -75px;
}
水平垂直居中:未知高度和宽度元素解决方案3
.item{
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%); /* 使用css3的transform来实现 */
}
水平垂直居中:使用flex布局实现4
.parent{
display: flex;
justify-content:center;
align-items: center;
/* 注意这里需要设置高度来查看垂直居中效果 */
background: #AAA;
height: 300px;
}
写写自己常用的CSS3特性:
1.选择器
属性选择器(只有IE6不支持)
[att^="value"]
匹配包含以特定的值开头的属性的元素
eg:div[class^="item"]{background:yellow;}
[class以item开头的元素的background属性为yellow]
[att$="value"]
匹配包含以特定的值结尾的属性的元素
[att*="value"]
匹配包含含有特定的值的属性的元素
2.连字符(所有浏览器都支持)
CSS3中唯一新引入的连字符是通用的兄弟选择器(同级)。它针对一个元素的有同一个父级节点的所有兄弟级别元素。
比如,给某个特定的div的同级的图片添加一个灰色的边框(div和图片应该有同一个父级节点),在样式表中定义下面的样式就足够了:
div~img {
border: 1px solid #ccc;
}
3.伪类
:nth-child(n)
让你基于元素在父节点的子元素的列表位置来指定元素。你可以是用数字、数字表达式或odd 和even 关键词(对斑马样式的列表很完美)。所以如果你想匹配在第四个元素之后的一个3个元素的分组,你可以简单的这样使用:
:nth-child(3n+4) { }/*匹配第4,7,10,13,16,19...个元素*/
:nth-last-child(n)
与上个选择器的思想同样,但是从后面匹配元素(倒序),比如,为了指定一个div里面的最后两个段落,我们可以使用下面的选择器:
div p:nth-last-child(-n+2)
:last-child
匹配一个父节点下的最后一个子元素,等同于:nth-last-child(1)
:checked
匹配选择的元素,比如复选框
:empty
匹配空元素(没有子元素)。
:not(s)
匹配所有不符合指定声明(s)的元素。比如,如果你想让所有的没有使用”lead”类的段落的显示为黑色,可以这样写:
p:not([class*="lead"]) { color: black; }
多栏布局(火狐浏览器、谷歌浏览器,IE10+等支持)
使用多栏布局时只能为所有栏指定一个统一的高度,栏与栏之间的宽度不可能是不一样的,另外也不可能具体指定什么栏中显示什么内容,因此比较适合使用在显示文章内容的时候,不适合用于安排整个网页中由各元素组成的网页结构时。
1.多栏布局第一个属性:column-count
column-count属性为一个数字表示列数,不带单位,含义是将一个元素中的内容分为多栏进行显示
.box {
width: 600px;
backgrond-color: #ddd;
column-count: 2;
}
2.多栏布局的第二个属性:column-gap
使用column-gap属性来设定多栏之间的间隔距离。
.box {
width: 600px;
backgrond-color: #ddd;
column-count: 2;
column-gap: 60px;
}
3.多栏布局第3个属性:column-rule
column-rule属性在栏与栏之间增加一条间隔线,并且设定该间隔线的宽度、样式、颜色,该属性的指定方法与css中的border属性指定方法相同
.box {
width: 600px;
backgrond-color: #ddd;
column-count: 2;
column-gap: 60px;
column-rule: 5px dashed #000;
}
4.多栏布局最后一个属性:column-width
column-width可以设置每一栏的宽度,但是在实际测试中发现并不像描述的那么简单,遂列举出以下几个问题:
在设定column-width的同时必须设置盒子的width,否则盒子宽度默认为100%,每栏宽度按照栏数平均分。
盒子每栏宽度必须大于等于column-width设定的值,否则就会减少栏数来增加每栏宽度,例如盒子宽度400px,一共2栏,那么每栏宽度就是200px,如果设置column-width: 210px的话盒子就会变成1栏以保证每栏宽度大于等于column-width:210px;,但是如果每栏宽度大于column-width的值时每栏宽度也不会强制等于column-width,这么看column-width的个性有点像min-width。
【CSS3规范里描述的是,各列的高度是均衡的,浏览器会自动调整每列里填充多少文本、均分文本,来使各列的高度保持均衡一致】
CSS3属性Word Wrap
(http://www.w3chtml.com/css3/properties/text/word-wrap.html)
对于文字过长会导致文字撑破容器出来:
word-wrap:break-word;内容将在边界内换行,如果需要,单词内部允许断行.
word-wrap:normal;内容将会撑破容器盒子
弹性盒子模型:box-flex
CSS3中新的盒子模型——弹性盒子模型(Flexible Box Model):
1.box-flex属性(很适用于流体布局),用来按比例分配父标签的宽度或高度空间
eg: #one{box-flex:2;}
#two{box-flex:1;}
#three{box-flex:1;}
表示id分别为one,two,three的元素把父标签按照2:1:1的比例分割;
2.父标签需要声明为
father{display:box;}
father{display:inline-box;}
【注意:目前而言,仅Firefox/Chrome/Safari浏览器支持弹性盒子模型(IE9不详,Opera尚未),且使用的时候,需要附带私有前缀。就是诸如-moz-, -webkit-前缀】
3.当子元素中有宽度值的时候,此元素就定宽处理,剩下的空间再按比例分配
eg:#one{box-flex:2;}
#two{box-flex:1;}
#three{width:200px;}
three宽度为200像素,one和two把剩下的空间按2:1分
4.弹性盒子模型下的爸爸(父标签)其实是很有货的。爸爸肚子中的货有:box-orient, box-direction, box-align, box-pack, box-lines. 现在依次讲讲这里box打头的属性都是干嘛用的。
5.box-orient用来确定子元素的方向。是横着排还是竖着走:
inline-axis是默认值。且horizontal与inline-axis的表现似乎一致的,让子元素横排;而vertical与block-axis的表现也是一致的,让元素纵列
6.子元素除了box-flex属性,还有两个属性,box-flex-group和box-ordinal-group,其中box-flex-group的作用不详,貌似目前浏览器也不支持;box-ordinal-group的作用是拉帮结派。数值越小,位置就越靠前,这不难理解,第一组在最前嘛,随后第二组,第三组…
例如:box-ordinal-group:1的组就会在box-ordinal-group:2的组前面显示。于是,我们可以利用这个属性改变子元素的顺序。
常见浏览器CSS前缀:
Webkit核心浏览器的(比如, Safari), 它们以-webkit-开始,以及Gecko核心的浏览器(比如, Firefox),以-moz-开始,还有Konqueror (-khtml-)、Opera (-o-) 以及Internet Explorer (-ms-)都有它们自己的属性扩展(目前只有IE8支持-ms-前缀)
css选择器权重:
style:1000;
ID:100;
class:10;
tagName:1;
子选择器(>)全部选择(*):0;
[后面的这些权值只是定的一个相对参考,并不是具体的值]
link和@import的区别:
页面中使用CSS的方式主要有3种:
1,行内添加定义style属性值
2,页面头部内嵌调用
3,外面链接调用其中外面引用有两种:link和@import
区别:
1:link是XHTML标签,除了加载CSS外,还可以定义RSS等其他事务;
@import属于CSS范畴,只能加载CSS。
2:link引用CSS时,在页面载入时同时加载;
@import需要页面网页完全载入以后加载。
3:link是XHTML标签,无兼容问题;
@import是在CSS2.1提出的,低版本的浏览器不支持。
4:ink支持使用Javascript控制DOM去改变样式;
而@import不支持。
继承的几种方式:
1,构造函数
2,原型链
数据传递的几种方式:
get,post,本地存储(localStorage)
[面试官问我,除了get和post方法还有什么别的方法?我想了半天,面试官说,本地存储啊~~(就是localStorage),其实我想说PUT,HEAD来着@_@]
worker主线程:
Web Workers 是 HTML5 提供的一个javascript多线程解决方案,我们可以将一些大计算量的代码交由web Worker运行而不冻结用户界面。
1.通过 worker = new Worker( url ) 加载一个JS文件来创建一个worker,同时返回一个worker实例。
2.通过worker.postMessage( data ) 方法来向worker发送数据。
3.绑定worker.onmessage方法来接收worker发送过来的数据。
4.可以使用 worker.terminate() 来终止一个worker的执行。webSocket:
[http://www.cnblogs.com/wei2yi/archive/2011/03/23/1992830.html]
是下一代客户端-服务器的异步通信方法,该通信取代了单个的TCP套接字,使用ws或wss协议,可用于任意的客户端和服务器程序;而且有一个优秀的第三方API,名为Socket.IO
服务器和客户端可以在给定的时间范围内的任意时刻,相互推送信息;
与ajax的区别:
WebSocket并不限于以Ajax(或XHR)方式通信,因为Ajax技术需要客户端发起请求,而WebSocket服务器和客户端可以彼此相互推送信息;XHR受到域的限制,而WebSocket允许跨域通信
// 创建一个Socket实例
var socket = new WebSocket('ws://localhost:8080'); //ws表示socket协议
// 打开Socket
socket.onopen = function(event) {
// 发送一个初始化消息
socket.send('I am the client and I\'m listening!');
// 监听消息
socket.onmessage = function(event) {
console.log('Client received a message',event);
};
// 监听Socket的关闭
socket.onclose = function(event) {
console.log('Client notified socket has closed',event);
};
// 关闭Socket....
socket.close()
};
不用angularJS,如何实现双向数据绑定
56:http请求头
get post delete put head options trace connect
OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法
57:nginx的好处?和node的比较
高并发 响应快
1.相似点:
1.1异步非阻塞I/O, 事件驱动;
2.不同点:
2.1Nginx 采用C编写,更性能更高,但是它仅适合于做web服务器,用于反向代理或者负载均衡等服务;Nginx背后的业务层编程思路很还是同步编程方式,例如PHP.
2.2NodeJs高性能平台,web服务只是其中一块,NodeJs在处理业务层用的是JS编写,采用的是异步编程方式和思维方式。
Flash、Ajax各自的优缺点,在使用中如何取舍?
Flash适合处理多媒体、矢量图形、访问机器;对CSS、处理文本上不足,不容易被搜索。
-Ajax对CSS、文本支持很好,支持搜索;多媒体、矢量图形、机器访问不足。
- 共同点:与服务器的无刷新传递消息、用户离线和在线状态、操作DOM
如何获取浏览器信息:
Navigator 对象包含有关浏览器的信息。
Navigator 对象属性:
属性 描述 IE F O
appCodeName 返回浏览器的代码名。 4 1 9
appMinorVersion 返回浏览器的次级版本。 4 No No
appName 返回浏览器的名称。 4 1 9
appVersion 返回浏览器的平台和版本信息。 4 1 9
browserLanguage 返回当前浏览器的语言。 4 No 9
cookieEnabled 返回指明浏览器中是否启用
cookie 的布尔值。 4 1 9
cpuClass 返回浏览器系统的 CPU 等级。 4 No No
onLine 返回指明系统是否处于脱机模式的布尔值。
4 No No
platform 返回运行浏览器的操作系统平台。4 1 9
systemLanguage 返回 OS 使用的默认语言。 4 No No
userAgent 返回由客户机发送服务器的
user-agent 头部的值。 4 1 9
userLanguage 返回 OS 的自然语言设置。 4 No 9
数组操作:
toString(param):
null和undefined没有toString()方法
把null或undefined变成字符串的方法:null+''或者String(null);
直接用(null).toString()会报错。
param
是可选的,当需要把数值型数据转换成相应的进制数时,param可以进行设置;eg:把十进制8转换成二进制:(8).toString(2);//"1000";
此处注意:必须是是number类型,若是("8").toString(2);//"8";
对于浮点数
如果小数点后面都是0,调用toString方法会把后面的0去掉
(10.00).toString();//"10";(10.01).toString();//"10.01";
对于object的toString()
返回"[object ObjectName]",其中ObjectName是对象类型的名称。
对于Date对象:
var date = new Date();
date.toString();//当前时间信息:"Mon Oct 19 2015 19:55:55 GMT+0800 (中国标准时间)"
【思考点:如何将小数点后面都为0的浮点数转化为字符串?
10.00+"";//"10"(如何得到"10.00");
10.00+10.00;//20(为什么不是20.00);
10.01+10.00;//20.009999999999998(为什么不是20.01)
】
String()与toString()的区别:
(1)null和undefined有String()转换成字符串,而toString()不能;
(2)toString()能设定数值数据转换的进制数,而String()不能;
(3)其他情况下:toString(val) === String(val)
join(seperator):数组以分隔符seperator转换成字符串
DOM操作——怎样添加、移除、移动、复制、创建和查找节点。
1)创建新节点
createDocumentFragment() //创建一个DOM片段
createElement() //创建一个具体的元素
createTextNode() //创建一个文本节点
2)添加、移除、替换、插入
appendChild()
removeChild()
replaceChild()
insertBefore() //并没有insertAfter()
3)查找
getElementsByTagName() //通过标签名称
getElementsByName() //通过元素的Name属性的值(IE容错能力较强,
会得到一个数组,其中包括id等于name值的)
getElementById() //通过元素Id,唯一性
selector:querySelector() | querySelectorAll()
(原生写法,比jquery速度快,缺点是IE6、7不支持。):
//接收的参数和CSS选择器接收的参数一样
baseElement.querySelector(selector);
baseElement.querySelectorAll(selector);
baseElement可以是document,也可以是DOM
eg:document.querySelectorAll("input[type='checkbox']");
document.querySelector === document.querySelectorAll[0];
注意:querySelector与querySelectorAll的区别:
(1)querySelector 用来获取一个元素;
querySelectorAll 可以获取多个元素。
(2)querySelector将返回匹配到的第一个元素,如果没有
匹配的元素则返回 NullquerySelectorAll 返回一个包
含匹配到的元素的数组,如果没有匹配的元素则返回的数组为空
document对象与querySelector的区别:
(1)getElement方法只能用于document,不能用于DOM,而querySelector可以
(2)getElment只能根据name,id,tagName获取DOM,而querySelector不受限制
关于querySelector的一些bug:
<div class= "test" id= "testId" >
<p><span>Test</span></p>
</div>
<script type= "text/javascript" >
var testElement= document.getElementById( 'testId' );
var element = testElement.querySelector( '.test span' );
var elementList = document.querySelectorAll( '.test span' );
console.log(element); // <span>Test</span>
console.log(elementList); // 1
</script>
按照W3C的来理解,这个例子应该返回:element:null;elementList:[];因为作为baseElement的 testElement里面根本没有符合selectors的匹配子节点;但浏览器却好像无视了baseElement,只在乎selectors,也就是说此时baseElement近乎document;这和我们的预期结果不合.
解决办法:看网址里面的内容吧,有点看不懂的感觉
document.ready与window.onload:
(http://blog.sina.com.cn/s/blog_49fa034d01011lpc.html)Jquery中$(document).ready()的作用类似于传统JavaScript中的window.onload方法,不过与window.onload方法还是有区别的。
1.执行时间
window.onload必须等到页面内包括图片的所有元素加载完毕后才能执行。$(document).ready()是DOM结构绘制完毕后就执行,不必等到加载完毕。
2.编写个数不同window.onload不能同时编写多个,如果有多个window.onload方法,只会执行一个。$(document).ready()可以同时编写多个,并且都可以得到执行
3.简化写法window.onload没有简化写法。$(document).ready(function(){})可以简写成$(function(){});
即:document.ready在window.onload前面执行
document对象:
每个载入浏览器的HTML文档都会成为Document对象。
Document 对象使我们可以从脚本中对 HTML 页面中的所有元素进行访问。
提示:Document 对象是 Window 对象的一部分,可通过 window.document 属性对其进行访问[window.document可以得到文档的内容(源码)]
document对象的属性:
document.URL:当前页面的url;
document.referrer:返回载入当前文档的文档的 URL;
(如果当前文档不是通过超级链接访问的,则为null,该属性允许客户端JS
访问HTTP引用头部。)
document.title:当前页面的title;
document.cookie:当前页面所有的cookie;
document.lastModified:当前页面最后的修改时间;
document.domain:当前页面的域名;
使用iframe的优缺点
优点:
1.程序调入静态页面比较方便;
2.页面和程序分离;
缺点:
1.iframe有不好之处:样式/脚本需要额外链入,会增加请求。
另外用js防盗链只防得了小偷,防不了大盗。
2.iframe好在能够把原先的网页全部原封不动显示下来,但是如果用在首页,是搜索引擎最讨厌的.那么你
的网站即使做的在好,也排不到好的名次!
如果是动态网页,用include还好点!
但是必须要去除他的<html><head><title><body>标签!
3.框架结构有时会让人感到迷惑,特别是在多个框架中都出现上下、左右滚动条的时候。这些滚动条除了
会挤占已经特别有限的页面空间外,还会分散访问者的留心力。访问者遇到这种站点往往会立刻转身离开
。他们会想,既然你的主页如此混乱,那么站点的其他部分也许更不值得阅读。
4.链接导航疑问。运用框架结构时,你必须保证正确配置所有的导航链接,如不然,会给访问者带来很大
的麻烦。比如被链接的页面出现在导航框架内,这种情况下访问者便被陷住了,因为此时他没有其他地点
可去。
5.调用外部页面,需要额外调用css,给页面带来额外的请求次数;
为什么少用iframe
iframes 提供了一个简单的方式把一个网站的内容嵌入到另一个网站中。但我们需要慎重的使用iframe。iframe的创建比其它包括scripts和css的 DOM 元素的创建慢了 1-2 个数量级。
使用 iframe 的页面一般不会包含太多 iframe,所以创建 DOM 节点所花费的时间不会占很大的比重。但带来一些其它的问题:onload 事件以及连接池(connection pool)。
1.Iframes 阻塞页面加载
及时触发 window 的 onload 事件是非常重要的。onload 事件触发使浏览器的 “忙” 指示器停止,告诉用户当前网页已经加载完毕。当 onload 事件加载延迟后,它给用户的感觉就是这个网页非常慢。
window 的 onload 事件需要在所有 iframe 加载完毕后(包含里面的元素)才会触发。在 Safari 和 Chrome 里,通过 JavaScript 动态设置 iframe 的 SRC 可以避免这种阻塞情况。
2.唯一的连接池
浏览器只能开少量的连接到web服务器。比较老的浏览器,包含 Internet Explorer 6 & 7 和 Firefox 2,只能对一个域名(hostname)同时打开两个连接。这个数量的限制在新版本的浏览器中有所提高。Safari 3+ 和 Opera 9+ 可同时对一个域名打开 4 个连接,Chrome 1+, IE 8 以及 Firefox 3 可以同时打开 6 个。你可以通过这篇文章查看具体的数据表:Roundup on Parallel Connections.
有人可能希望 iframe 会有自己独立的连接池,但不是这样的。绝大部分浏览器,主页面和其中的 iframe 是共享这些连接的。这意味着 iframe 在加载资源时可能用光了所有的可用连接,从而阻塞了主页面资源的加载。如果 iframe 中的内容比主页面的内容更重要,这当然是很好的。但通常情况下,iframe 里的内容是没有主页面的内容重要的。这时 iframe 中用光了可用的连接就是不值得的了。一种解决办法是,在主页面上重要的元素加载完毕后,再动态设置 iframe 的 SRC。
美国前 10 大网站都使用了 iframe。大部分情况下,他们用它来加载广告。这是可以理解的,也是一种符合逻辑的解决方案,用一种简单的办法来加载广告服务。但请记住,iframe 会给你的页面性能带来冲击。只要可能,不要使用 iframe。当确实需要时,谨慎的使用他们。
iframe和frame的区别
1、frame不能脱离frameSet单独使用,iframe可以;
2、frame不能放在body中;
如下可以正常显示:
<!--<body>-->
<frameset rows="50%,*">
<frame name="frame1" src="http://gongxquan.blog.163.com/test1.htm"/>
<frame name="frame2" src="http://gongxquan.blog.163.com/test2.htm"/>
</frameset>
<!--<body>-->
如下不能正常显示:
<body>
<frameset rows="50%,*">
<frame name="frame1" src="http://gongxquan.blog.163.com/test1.htm"/>
<frame name="frame2" src="http://gongxquan.blog.163.com/test2.htm"/>
</frameset>
<body>
3、嵌套在frameSet中的iframe必需放在body中;
如下可以正常显示:
<body>
<frameset>
<iframe name="frame1" src="http://gongxquan.blog.163.com/test1.htm"/>
<iframe name="frame2" src="http://gongxquan.blog.163.com/test2.htm"/>
</frameset>
</body>
如下不能正常显示:
<!--<body>-->
<frameset>
<iframe name="frame1" src="http://gongxquan.blog.163.com/test1.htm"/>
<iframe name="frame2" src="http://gongxquan.blog.163.com/test2.htm"/>
</frameset>
<!--</body>-->
4、不嵌套在frameSet中的iframe可以随意使用;
如下均可以正常显示:
<body>
<iframe name="frame1" src="http://gongxquan.blog.163.com/test1.htm"/>
<iframe name="frame2" src="http://gongxquan.blog.163.com/test2.htm"/>
</body>
<!--<body>-->
<iframe name="frame1" src="http://gongxquan.blog.163.com/test1.htm"/>
<iframe name="frame2" src="http://gongxquan.blog.163.com/test2.htm"/>
<!--</body>-->
5、frame的高度只能通过frameSet控制;iframe可以自己控制,不能通过frameSet控制,如:
<!--<body>-->
<frameset rows="50%,*">
<frame name="frame1" src="http://gongxquan.blog.163.com/test1.htm"/>
<frame name="frame2" src="http://gongxquan.blog.163.com/test2.htm"/>
</frameset>
<!--</body>-->
<body>
<frameset>
<iframe height="30%" name="frame1" src="http://gongxquan.blog.163.com/test1.htm"/>
<iframe height="100" name="frame2" src="http://gongxquan.blog.163.com/test2.htm"/>
</frameset>
</body>
6、如果在同一个页面使用了两个以上的iframe,在IE中可以正常显示,在firefox中只能显示出第一个;使用两个以上的frame在IE和firefox中均可正常
- html文件的渲染过程(性能优化的依据):
- (http://blog.csdn.net/luckygll/article/details/7432713)
- (http://my.oschina.net/u/1414906/blog/357860)
- 客户端发出请求---服务器响应将html文件返回给请求的客户端浏览器中;
- 页面开始加载;
- 加载从html标签开始;
- 加载到head标签时,如果标签内有个外部样式文件(.css)要加载;
- 客户端向服务器发出一个请求加载CSS文件,服务器响应;
- CSS加载完成后,客户端浏览器继续加载html文件里的body标签(在CSS文件加载完毕后同时渲染页面);
- 客户端在body标签发现img标签并且引用了一张图片,客户端浏览器向服务器发出一次请求,浏览器不会等到图片下载完,而是继续渲染后面的代码;
- img标签中的图片加载完了,要显示出来,而图片又要占用一定的面积,又会影响到后面的布局,浏览器不得不回来重新渲染这一部分;
- body标签里的标签加载及渲染完成后,浏览器发现script标签中的代码,浏览器需要想服务器发出请求加载js文件,服务器响应;
- 浏览器解析执行js文件时发现里面有一些对body文档结构变化的操作(隐藏某段内容等),此时浏览器又需要重新去渲染这些内容;
- 知道浏览器发现 </html>标签;
- 等等,还没完。用户点击了一下界面中的换肤按钮,js让浏览器换了一下<link>的css标签;
- 浏览器召集了在座的各位<div><span><ul><li>们,“大伙儿收拾收拾行李,咱得重新来过……”,浏览器向服务器请求了新的CSS文件,重新渲染页面。
页面回流与重绘(Reflow & Repaint)
如果你的HTML变得很大很复杂,那么影响你JavaScript性能的可能并不是JavaScript代码的复杂度,而是页面的回流和重绘。
reflow(回流):当render tree中的一部分(或全部)因为元素的规模尺寸,布局,隐藏等改变而需要重新构建。这就称为回流(reflow)。每个页面至少需要一次回流,就是在页面第一次加载的时候。
回流如何出现:当该对象即将重绘时,浏览器会根据条件判断该对象的重绘结果是否会依赖该对象的祖先元素。如果有则将该对象祖先元素也加入本次重绘。并一直向上 寻找,直到条件不匹配。
回流:对某个区域、对象进行重绘,根据条件影响到它的祖先对象进入重绘(并可能无限递归直到顶级祖先对象)
(http://www.cnblogs.com/dujingjie/p/5784890.html)
导致浏览器reflow的一些因素:
1、添加或者删除可见的DOM元素;
2、元素位置改变;
3、元素尺寸改变——边距、填充、边框、宽度和高度
4、内容改变——比如文本改变或者图片大小改变而引起的计算值宽度和高度改变;
5、页面渲染初始化;
6、浏览器窗口尺寸改变——resize事件发生时;
repaint(重绘):当render tree中的一些元素需要更新属性,而这些属性只是影响元素的外观,风格,而不会影响布局的,比如background-color。则就叫称为重绘。
重绘:对某个区域、对象的重新渲染表现
重绘如何出现:改变对象的形状、坐标、表现以及内容都会引发该对象被重新渲染,这种现象即为重绘。
如何减少回流、重绘
1. 直接改变className,如果动态改变样式,则使用cssText(考虑没有优化的浏览器)
2. 让要操作的元素进行”离线处理”,处理完后一起更新
a) 使用DocumentFragment进行缓存操作,引发一次回流和重绘;
b) 使用display:none技术,只引发两次回流和重绘;
c) 使用cloneNode(true or false) 和 replaceChild 技术,引发一次回流和重绘;
3.不要经常访问会引起浏览器flush队列的属性,如果你确实要访问,利用缓存
4. 让元素脱离动画流,减少回流的Render Tree的规模
避免大量页面回流的手段也有很多,其本质都是尽量减少引起回流和重绘的DOM操作。
(http://itindex.net/detail/54285-回流-reflow-repaint)
最后总结:
1、重绘可能引发回流
2、回流必定引发重绘
页面渲染原理是什么?
渲染引擎是干什么的
渲染引擎可以显示html、xml文档及图片,它也可以借助插件(一种浏览器扩展)显示其他类型数据,例如使用PDF阅读器插件可以显示PDF格式。
渲染引擎
不同的浏览器有不同的渲染引擎,对于渲染引擎的使用总结如下:
Trident(MSHTML)内核:IE,MaxThon,TT,The World,360,搜狗浏览器等
Gecko内核:Netscape6及以上版本,FF,MozillaSuite/SeaMonkey等
Presto内核:Opera7及以上
Webkit内核:Safari,Chrome等
渲染主流程
渲染引擎首先通过网络获得所请求文档的内容,通常以8K分块的方式完成。下面是渲染引擎在取得内容之后的基本流程:
解析html以构建dom树 -> 构建render树 -> 布局render树 -> 绘制render树

步骤详细解释
第一步:渲染引擎开始解析html,根据标签构建DOM节点
第二步:根据css样式构建渲染树,包括元素的大小、颜色,隐藏的元素不会被构建到该树中。
第三步:根据css样式构建布局树,主要是确定元素要显示的位置。
第四步:根据前面的信息,绘制渲染树。
js的阻塞特性:(解决:使用异步加载的方式:在script标签中添加async属性)
其中js是阻塞式的加载,浏览器在加载js时,当浏览器在执行js代码时,不会做其他的事情,即<script>的每次出现都会让页面等待脚本的解析和执行,js代码执行后,才会继续渲染页面。新一代浏览器虽然支持并行下载。但是js下载仍会阻塞其他资源的下载(比如图片)。所以应该把js放到页面的底部。
js的优化:
1.要使用高效的选择器。
2.将选择器保存为局部变量
3.先操作再显示
47:offsetHeight, scrollHeight, clientHeight,scrollTop分别代表什么
clientHeight:内部可视区域大小。包括内容可见部分的高度,可见的padding;不包括border,水平方向的scrollbar,margin。
offsetHeight:整个可视区域大小。包括内容可见部分的高度,border,可见的padding,水平方向的scrollbar(如果存在);不包括margin。
scrollHeight:元素内容的高度。包括内容的高度(可见与不可见),padding(可见与不可见);不包括border,margin。
scrollTop:元素内容向上滚动了多少像素。
50:rem和em的区别
em相对于父元素,rem相对于根元素
51:严格模式的特性
严格模式对Javascript的语法和行为,都做了一些改变。
全局变量必须显式声明。
对象不能有重名的属性
函数必须声明在顶层
- 消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;
- 提高编译器效率,增加运行速度;
- 为未来新版本的Javascript做好铺垫。
66.zepto和jquery区别
zepto比jquery体积小很多,移动端的兼容性不需要要考虑很多,jquery中的很多功能都没有。
width()和height()不一样 解决用.css('width')
你觉得jQuery或zepto源码有哪些写的好的地方
(答案仅供参考)
jQuery源码封装在一个匿名函数的自执行环境中,有助于防止变量的全局污染,然后通过传入window对象参数,可以使window对象作为局部变量使用,好处是当jquery中访问window对象的时候,就不用将作用域链退回到顶层作用域了,从而可以更快的访问window对象。同样,传入undefined参数,可以缩短查找undefined时的作用域链。
(function( window, undefined ) {
//用一个函数域包起来,就是所谓的沙箱
//在这里边var定义的变量,属于这个函数域内的局部变量,避免污染全局
//把当前沙箱需要的外部变量通过函数参数引入进来
//只要保证参数对内提供的接口的一致性,你还可以随意替换传进来的这个参数
window.jQuery = window.$ = jQuery;
})( window );jquery将一些原型属性和方法封装在了jquery.prototype中,为了缩短名称,又赋值给了jquery.fn,这是很形象的写法。
有一些数组或对象的方法经常能使用到,jQuery将其保存为局部变量以提高访问速度。
jquery实现的链式调用可以节约代码,所返回的都是同一个对象,可以提高代码效率。
67.css3动画和jquery动画的差别
1.css3中的过渡和animation动画都是基于css实现机制的,属于css范畴之内,并没有涉及到任何语言操作。效率略高与jQuery中的animate()函数,但兼容性很差。
2.jQuery中的animate()函数可以简单的理解为css样式的“逐帧动画”,是css样式不同状态的快速切换的结果。效率略低于css3动画执行效率,但是兼容性好。
68.如何解决ajax无法后退的问题
HTML5里引入了新的API,即:history.pushState, history.replaceState
可以通过pushState和replaceState接口操作浏览器历史,并且改变当前页面的URL。
onpopstate监听后退
70.分域名请求图片的原因和好处
浏览器的并发请求数目限制是针对同一域名的,超过限制数目的请求会被阻塞
浏览器并发请求有个数限制,分域名可以同时并发请求大量图片
71.页面的加载顺序
html顺序加载,其中js会阻塞后续dom和资源的加载,css不会阻塞dom和资源的加载但是会阻塞js的加载。
浏览器会使用prefetch对引用的资源提前下载
1.没有 defer 或 async,浏览器会立即加载并执行指定的脚本
2.有 async,加载和渲染后续文档元素的过程将和 script.js 的加载与执行并行进行(下载异步,执行同步,加载完就执行)。
3.有 defer,加载后续文档元素的过程将和 script.js 的加载并行进行(异步),但是 script.js 的执行要在所有元素解析完成之后,DOMContentLoaded 事件触发之前完成。
73.计算机网络的分层概述
tcp/ip模型:从下往上分别是链路层,网络层,传输层,应用层
osi模型:从下往上分别是物理层,链路层,网络层,传输层,会话层,表示层,应用层。
73.浏览器js、css缓存问题
浏览器缓存的意义在于提高了执行效率,但是也随之而来带来了一些问题,导致修改了js、css,客户端不能更新
都加上了一个时间戳作为版本号
<script type=”text/javascript” src=”{JS文件连接地址}?version=XXXXXXXX”></script>
74.setTimeout,setInterval,requestAnimationFrame之间的区别
setInterval如果函数执行的时间很长的话,第二次的函数会放到队列中,等函数执行完再执行第二次,导致时间间隔发生错误。
而settimeout一定是在这个时间定时结束之后,它才会执行
requestAnimationFrame是为了做动画专用的一个方法,这种方法对于dom节点的操作会比较频繁。
75.webpack常用到哪些功能
设置入口 设置输出目 设置loader extract-text-webpack-plugin将css从js代码中抽出并合并 处理图片文字等功能 解析jsx解析bable
76.介绍sass
&定义变量 css嵌套 允许在代码中使用算式 支持if判断for循环
77.websocket和ajax轮询
Websocket是HTML5中提出的新的协议,注意,这里是协议,可以实现客户端与服务器端的通信,实现服务器的推送功能。
其优点就是,只要建立一次连接,就可以连续不断的得到服务器推送的消息,节省带宽和服务器端的压力。
ajax轮询模拟长连接就是每个一段时间(0.5s)就向服务器发起ajax请求,查询服务器端是否有数据更新
其缺点显而易见,每次都要建立HTTP连接,即使需要传输的数据非常少,所以这样很浪费带宽
78.tansition和margin的百分比根据什么计算
transition是相对于自身,margin相对于参照物
84.移动端兼容问题
IOS移动端click事件300ms的延迟响应
一些情况下对非可点击元素如(label,span)监听click事件,ios下不会触发,css增加cursor:pointer就搞定了
85.bootstrap的栅格系统如何实现的
box-sizing: border-box;
container row column设置百分比
XML和JSON的区别?
(1).数据体积方面。
JSON相对于XML来讲,数据的体积小,传递的速度更快些。
(2).数据交互方面。
JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互。
(3).数据描述方面。
JSON对数据的描述性比XML较差。
(4).传输速度方面。
JSON的速度要远远快于XML。请你谈谈Cookie的弊端
cookie虽然在持久保存客户端数据提供了方便,分担了服务器存储的负担,但还是有很多局限性的。
第一:每个特定的域名下最多生成20个cookie
1.IE6或更低版本最多20个cookie
2.IE7和之后的版本最后可以有50个cookie。
3.Firefox最多50个cookie
4.chrome和Safari没有做硬性限制
IE和Opera 会清理近期最少使用的cookie,Firefox会随机清理cookie。
cookie的最大大约为4096字节,为了兼容性,一般不能超过4095字节。
IE 提供了一种存储可以持久化用户数据,叫做userdata,从IE5.0就开始支持。每个数据最多128K,每个域名下最多1M。这个持久化数据放在缓存中,如果缓存没有清理,那么会一直存在。
优点:极高的扩展性和可用性
1.通过良好的编程,控制保存在cookie中的session对象的大小。
2.通过加密和安全传输技术(SSL),减少cookie被破解的可能性。
3.只在cookie中存放不敏感数据,即使被盗也不会有重大损失。
4.控制cookie的生命期,使之不会永远有效。偷盗者很可能拿到一个过期的cookie。
缺点:
1.`Cookie`数量和长度的限制。每个domain最多只能有20条cookie,每个cookie长度不能超过4KB,否则会被截掉.
2.安全性问题。如果cookie被人拦截了,那人就可以取得所有的session信息。即使加密也与事无补,因为拦截者并不需要知道cookie的意义,他只要原样转发cookie就可以达到目的了。
3.有些状态不可能保存在客户端。例如,为了防止重复提交表单,我们需要在服务器端保存一个计数器。如果我们把这个计数器保存在客户端,那么它起不到任何作用。
跨域:
协议,域名,端口号有一个不同就被称为跨域
prototype与__proto__
(http://www.cnblogs.com/snandy/archive/2012/09/01/2664134.html)
prototype:每一个函数对象都有一个显示的prototype属性,它代表了对象的原型
__proto__:内部原型(IE6/7/8/9不支持),每个对象都有一个名为__proto__的内部隐藏属性,指向于它所对应的原型对象,
IE9中可以使用Object.getPrototypeOf(obj)获取对象的内部原型;
[原型链是基于__proto__才得以形成]
所有对象__proto__都指向其构造器的prototype,包括自定义的构造器
[注意:构造器可以直接用构造器的名字,也可以用实例对象的constructor属性获得]
作用域与作用域链
作用域:变量的作用域有全局作用域和局部作用域两种http://www.cnblogs.com/lhb25/archive/2011/09/06/javascript-scope-chain.html
作用域链:函数也是对象,实际上,JavaScript里一切都是对象。函数对象和其它对象一样,拥有可以通过代码访问的属性和一系列仅供JavaScript引擎访问的内部属性。其中一个内部属性是[[Scope]],由ECMA-262标准第三版定义,该内部属性包含了函数被创建的作用域中对象的集合,这个集合被称为函数的作用域链,它决定了哪些数据能被函数访问。改变作用域链
函数每次执行时对应的运行期上下文都是独一无二的,所以多次调用同一个函数就会导致创建多个运行期上下文,当函数执行完毕,执行上下文会被销毁。每一个运行期上下文都和一个作用域链关联。一般情况下,在运行期上下文运行的过程中,其作用域链只会被 with 语句和 catch 语句影响。
介绍一下你所了解的作用域链,作用域链的尽头是什么,为什么
每一个函数作用域链的作用是保证执行环境里有权访问的变量和函数是有序的,作用域链的变量只能向上访问,变量访问到window对象即被终止,作用域链向下访问变量是不被允许的。
javascript模块化是什么及其优缺点介绍
如今backbone、emberjs、spinejs、batmanjs
等MVC框架侵袭而来。CommonJS、AMD、NodeJS、RequireJS、SeaJS、curljs等模块化的JavaScript扑面而来。web前端已经演变成大前端,web前端的发展速度之快。
1)我们来看看什么是模块化?
模块化是一种将系统分离成独立功能部分的方法,可将系统分割成独立的功能部分,严格定义模块接口、模块间具有透明性。javascript中的模块在一些C、PHP、java中比较常见:
c中使用include 包含.h文件;php中使用require_once包含.php文件
java使用import导入包
此中都有模块化的思想。
2)模块化的优缺点:
a>优点:
可维护性
1.灵活架构,焦点分离
2.方便模块间组合、分解
3.方便单个模块功能调试、升级
4.多人协作互不干扰
可测试性
1.可分单元测试
b>缺点:
性能损耗
1.系统分层,调用链会很长
2.模块间通信,模块间发送消息会很耗性能
3)最近的项目中也有用到模块化,
使用的是seajs,但是当引用到jquery,jquery easyui/或者jquery
UI组件时,有可能会用到很多jquery插件,那这样要是实现一个很复杂的交互时,模块间的依赖会很多,使用define()方法引入模块会很多,不知
有么有什么好的方法?
4)附:
内聚度
内聚度指模块内部实现,它是信息隐藏和局部化概念的自然扩展,它标志着一个模块内部各成分彼此结合的紧密程度。好处也很明显,当把相关的任务分组后去阅读就容易多了。 设计时应该尽可能的提高模块内聚度,从而获得较高的模块独立性。
耦合度
耦合度则是指模块之间的关联程度的度量。耦合度取决于模块之间接口的复杂性,进入或调用模块的位置等。与内聚度相反,在设计时应尽量追求松散耦合的系统。
跳出循环体
break:跳出最内层循环或者退出一个switch语句
continue:跳出当前循环继续下一个循环
return:跳出循环,即使函数主体中还有其他语句,函数执行也会停止
(内容5)——————
1、新的 HTML5 文档类型和字符集是?
HTML5 文档类型很简单:<!doctype html>
HTML5 使用 UTF-8 编码示例:
2、HTML5 中如何嵌入音频?
HTML5 支持 MP3、Wav 和 Ogg 格式的音频,下面是在网页中嵌入音频的简单示例:
<audio controls>
<source src=”jamshed.mp3″ type=”audio/mpeg”>
Your browser does’nt support audio embedding feature.
</audio>3、HTML5 中如何嵌入视频?
和音频类似,HTML5 支持 MP4、WebM 和 Ogg 格式的视频,下面是简单示例:
|
1
2
3
4
|
<video width=”450″ height=”340″ controls>
<source src=”jamshed.mp4″ type=”video/mp4″>
Your browser does’nt support video embedding feature.
</video>
|
4、除了 audio 和 video,HTML5 还有哪些媒体标签?
HTML5 对于多媒体提供了强有力的支持,除了 audio 和 video 标签外,还支持以下标签:
<embed> 标签定义嵌入的内容,比如插件。
|
1
|
<embed type=”video/quicktime” src=”Fishing.mov”>
|
<source> 对于定义多个数据源很有用。
|
1
2
3
4
|
<video width=”450″ height=”340″ controls>
<source src=”jamshed.mp4″ type=”video/mp4″>
<source src=”jamshed.ogg” type=”video/ogg”>
</video>
|
<track> 标签为诸如 video 元素之类的媒介规定外部文本轨道。 用于规定字幕文件或其他包含文本的文件,当媒介播放时,这些文件是可见的。
|
1
2
3
4
5
6
|
<video width=”450″ height=”340″ controls>
<source src=”jamshed.mp4″ type=”video/mp4″>
<source src=”jamshed.ogg” type=”video/ogg”>
<track kind=”subtitles” label=”English” src=”jamshed_en.vtt” srclang=”en”
default
></track>
<track kind=”subtitles” label=”Arabic” src=”jamshed_ar.vtt” srclang=”ar”></track>
</video>
|
5、HTML5 Canvas 元素有什么用?
Canvas 元素用于在网页上绘制图形,该元素标签强大之处在于可以直接在 HTML 上进行图形操作,
|
1
2
|
<canvas id=”canvas1″ width=”300″ height=”100″>
</canvas>
|
6、HTML5 存储类型有什么区别?
HTML5 能够本地存储数据,在之前都是使用 cookies 使用的。HTML5 提供了下面两种本地存储方案:
- localStorage 用于持久化的本地存储,数据永远不会过期,关闭浏览器也不会丢失。
- sessionStorage 同一个会话中的页面才能访问并且当会话结束后数据也随之销毁。因此sessionStorage不是一种持久化的本地存储,仅仅是会话级别的存储
7、HTML5 有哪些新增的表单元素?
HTML5 新增了很多表单元素让开发者构建更优秀的 Web 应用程序。
- datalist
- datetime
- output
- keygen
- date
- month
- week
- time
- color
- number
- range
- url
8、HTML5 废弃了哪些 HTML4 标签?
HTML5 废弃了一些过时的,不合理的 HTML 标签:
- frame
- frameset
- noframe
- applet
- big
- center
- basefront
9、HTML5 标准提供了哪些新的 API?
HTML5 提供的应用程序 API 主要有:
- Media API
- Text Track API
- Application Cache API
- User Interaction
- Data Transfer API
- Command API
- Constraint Validation API
- History API
10、HTML5 应用程序缓存和浏览器缓存有什么区别?
应用程序缓存是 HTML5 的重要特性之一,提供了离线使用的功能,让应用程序可以获取本地的网站内容,例如 HTML、CSS、图片以及 JavaScript。这个特性可以提高网站性能,它的实现借助于 manifest 文件,如下:
<!doctype html>
<html manifest=”example.appcache”>
…..
</html>
(内容6)——————
前端开发面试题
https://github.com/markyun/My-blog/tree/master/Front-end-Developer-Questions
更新时间: 2015-10-9
HTML
Doctype作用?标准模式与兼容模式各有什么区别?
(1)、<!DOCTYPE>声明位于位于HTML文档中的第一行,处于 <html> 标签之前。告知浏览器的解析器用什么文档标准解析这个文档。DOCTYPE不存在或格式不正确会导致文档以兼容模式呈现。
(2)、标准模式的排版 和JS运作模式都是以该浏览器支持的最高标准运行。在兼容模式中,页面以宽松的向后兼容的方式显示,模拟老式浏览器的行为以防止站点无法工作。
HTML5 为什么只需要写 <!DOCTYPE HTML>?
HTML5 不基于 SGML,因此不需要对DTD进行引用,但是需要doctype来规范浏览器的行为(让浏览器按照它们应该的方式来运行);
而HTML4.01基于SGML,所以需要对DTD进行引用,才能告知浏览器文档所使用的文档类型。
行内元素有哪些?块级元素有哪些? 空(void)元素有那些?
首先:CSS规范规定,每个元素都有display属性,确定该元素的类型,每个元素都有默认的display值,如div的display默认值为“block”,则为“块级”元素;span默认display属性值为“inline”,是“行内”元素。
(1)行内元素有:a b span img input select strong(强调的语气)
(2)块级元素有:div ul ol li dl dt dd h1 h2 h3 h4…p
(3)常见的空元素:
<br> <hr> <img> <input> <link> <meta>
鲜为人知的是:
<area> <base> <col> <command> <embed> <keygen> <param> <source> <track> <wbr>
页面导入样式时,使用link和@import有什么区别?
(1)link属于XHTML标签,除了加载CSS外,还能用于定义RSS, 定义rel连接属性等作用;而@import是CSS提供的,只能用于加载CSS;
(2)页面被加载的时,link会同时被加载,而@import引用的CSS会等到页面被加载完再加载;
(3)import是CSS2.1 提出的,只在IE5以上才能被识别,而link是XHTML标签,无兼容问题;
介绍一下你对浏览器内核的理解?
主要分成两部分:渲染引擎(layout engineer或Rendering Engine)和JS引擎。
渲染引擎:负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要内核。
JS引擎则:解析和执行javascript来实现网页的动态效果。
最开始渲染引擎和JS引擎并没有区分的很明确,后来JS引擎越来越独立,内核就倾向于只指渲染引擎。
常见的浏览器内核有哪些?
Trident内核:IE,MaxThon,TT,The World,360,搜狗浏览器等。[又称MSHTML]
Gecko内核:Netscape6及以上版本,FF,MozillaSuite/SeaMonkey等
Presto内核:Opera7及以上。 [Opera内核原为:Presto,现为:Blink;]
Webkit内核:Safari,Chrome等。 [ Chrome的:Blink(WebKit的分支)]
详细文章:浏览器内核的解析和对比 - 依水间
html5有哪些新特性、移除了那些元素?如何处理HTML5新标签的浏览器兼容问题?如何区分 HTML 和 HTML5?
* HTML5 现在已经不是 SGML 的子集,主要是关于图像,位置,存储,多任务等功能的增加。
绘画 canvas;
用于媒介回放的 video 和 audio 元素;
本地离线存储 localStorage 长期存储数据,浏览器关闭后数据不丢失;
sessionStorage 的数据在浏览器关闭后自动删除;
语意化更好的内容元素,比如 article、footer、header、nav、section;
表单控件,calendar、date、time、email、url、search;
新的技术webworker, websockt, Geolocation;
移除的元素:
纯表现的元素:basefont,big,center,font, s,strike,tt,u;
对可用性产生负面影响的元素:frame,frameset,noframes;
* 支持HTML5新标签:
IE8/IE7/IE6支持通过document.createElement方法产生的标签,
可以利用这一特性让这些浏览器支持HTML5新标签,
浏览器支持新标签后,还需要添加标签默认的样式。
当然最好的方式是直接使用成熟的框架、使用最多的是html5shim框架
<!--[if lt IE 9]>
<script> src="http://html5shim.googlecode.com/svn/trunk/html5.js"</script>
<![endif]-->
* 如何区分: DOCTYPE声明\新增的结构元素\功能元素
什么是web语义化,有什么好处
web语义化是指通过HTML标记表示页面包含的信息,包含了HTML标签的语义化和css命名的语义化。 HTML标签的语义化是指:通过使用包含语义的标签(如h1-h6)恰当地表示文档结构 css命名的语义化是指:为html标签添加有意义的class,id补充未表达的语义,如Microformat通过添加符合规则的class描述信息 为什么需要语义化:
- 去掉样式后页面呈现清晰的结构
- 盲人使用读屏器更好地阅读
- 搜索引擎更好地理解页面,有利于收录
- 便团队项目的可持续运作及维护
HTML5的离线储存怎么使用,工作原理能不能解释一下?
在用户没有与因特网连接时,可以正常访问站点或应用,在用户与因特网连接时,更新用户机器上的缓存文件。
原理:HTML5的离线存储是基于一个新建的.appcache文件的缓存机制(不是存储技术),通过这个文件上的解析清单离线存储资源,这些资源就会像cookie一样被存储了下来。之后当网络在处于离线状态下时,浏览器会通过被离线存储的数据进行页面展示。
如何使用:
1、页面头部像下面一样加入一个manifest的属性;
2、在cache.manifest文件的编写离线存储的资源;
CACHE MANIFEST
#v0.11
CACHE:
js/app.js
css/style.css
NETWORK:
resourse/logo.png
FALLBACK:
/ /offline.html
3、在离线状态时,操作window.applicationCache进行需求实现。
详细的使用请参考:有趣的HTML5:离线存储
浏览器是怎么对HTML5的离线储存资源进行管理和加载的呢?
在线的情况下,浏览器发现html头部有manifest属性,它会请求manifest文件,如果是第一次访问app,那么浏览器就会根据manifest文件的内容下载相应的资源并且进行离线存储。如果已经访问过app并且资源已经离线存储了,那么浏览器就会使用离线的资源加载页面,然后浏览器会对比新的manifest文件与旧的manifest文件,如果文件没有发生改变,就不做任何操作,如果文件改变了,那么就会重新下载文件中的资源并进行离线存储。
离线的情况下,浏览器就直接使用离线存储的资源。
详细的使用请参考:有趣的HTML5:离线存储
请描述一下 cookies,sessionStorage 和 localStorage 的区别?
cookie是网站为了标示用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。
cookie数据始终在同源的http请求中携带(即使不需要),记会在浏览器和服务器间来回传递。
sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存。
存储大小:
cookie数据大小不能超过4k。
sessionStorage和localStorage 虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大。
有期时间:
localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据;
sessionStorage 数据在当前浏览器窗口关闭后自动删除。
cookie 设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭
iframe有那些缺点?
*iframe会阻塞主页面的Onload事件;
*搜索引擎的检索程序无法解读这种页面,不利于SEO;
*iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载。
使用iframe之前需要考虑这两个缺点。如果需要使用iframe,最好是通过javascript
动态给iframe添加src属性值,这样可以可以绕开以上两个问题。
Label的作用是什么?是怎么用的?
label标签来定义表单控制间的关系,当用户选择该标签时,浏览器会自动将焦点转到和标签相关的表单控件上。
<label for="Name">Number:</label> <input type=“text“name="Name" id="Name"/>
<label>Date:<input type="text" name="B" /></label>
HTML5的form如何关闭自动完成功能?
给不想要提示的 form 或下某个input 设置为 autocomplete=off。
请描述一下 cookies,sessionStorage 和 localStorage 的区别?
cookie在浏览器和服务器间来回传递。 sessionStorage和localStorage不会
sessionStorage和localStorage的存储空间更大;
sessionStorage和localStorage有更多丰富易用的接口;
sessionStorage和localStorage各自独立的存储空间;
如何实现浏览器内多个标签页之间的通信? (阿里)
调用localstorge、cookies等本地存储方式
webSocket如何兼容低浏览器?(阿里)
Adobe Flash Socket 、 ActiveX HTMLFile (IE) 、 基于 multipart 编码发送 XHR 、 基于长轮询的 XHR
CSS
介绍一下CSS的盒子模型?
(1)有两种, IE 盒子模型、标准 W3C 盒子模型;IE的content部分包含了 border 和 pading;
(2)盒模型: 内容(content)、填充(padding)、边界(margin)、 边框(border).
CSS 选择符有哪些?哪些属性可以继承?优先级算法如何计算? CSS3新增伪类有那些?
* 1.id选择器( # myid)
2.类选择器(.myclassname)
3.标签选择器(div, h1, p)
4.相邻选择器(h1 + p)
5.子选择器(ul > li)
6.后代选择器(li a)
7.通配符选择器( * )
8.属性选择器(a[rel = "external"])
9.伪类选择器(a: hover, li: nth - child)
* 可继承的样式: font-size font-family color, UL LI DL DD DT;
* 不可继承的样式:border padding margin width height ;
* 优先级就近原则,同权重情况下样式定义最近者为准;
* 载入样式以最后载入的定位为准;
优先级为:
!important > id > class > tag
important 比 内联优先级高
CSS3新增伪类举例:
p:first-of-type 选择属于其父元素的首个 <p> 元素的每个 <p> 元素。
p:last-of-type 选择属于其父元素的最后 <p> 元素的每个 <p> 元素。
p:only-of-type 选择属于其父元素唯一的 <p> 元素的每个 <p> 元素。
p:only-child 选择属于其父元素的唯一子元素的每个 <p> 元素。
p:nth-child(2) 选择属于其父元素的第二个子元素的每个 <p> 元素。
:enabled :disabled 控制表单控件的禁用状态。
:checked 单选框或复选框被选中。
如何居中div?如何居中一个浮动元素?
给div设置一个宽度,然后添加margin:0 auto属性
div{
width:200px;
margin:0 auto;
}
居中一个浮动元素
确定容器的宽高 宽500 高 300 的层
设置层的外边距
.div {
Width:500px ; height:300px;//高度可以不设
Margin: -150px 0 0 -250px;
position:relative;相对定位
background-color:pink;//方便看效果
left:50%;
top:50%;
}
列出display的值,说明他们的作用。position的值, relative和absolute定位原点是?
1.
block 象块类型元素一样显示。
none 缺省值。象行内元素类型一样显示。
inline-block 象行内元素一样显示,但其内容象块类型元素一样显示。
list-item 象块类型元素一样显示,并添加样式列表标记。
2.
*absolute
生成绝对定位的元素,相对于 static 定位以外的第一个父元素进行定位。
*fixed (老IE不支持)
生成绝对定位的元素,相对于浏览器窗口进行定位。
*relative
生成相对定位的元素,相对于其正常位置进行定位。
* static 默认值。没有定位,元素出现在正常的流中
*(忽略 top, bottom, left, right z-index 声明)。
* inherit 规定从父元素继承 position 属性的值。
CSS3有哪些新特性?
CSS3实现圆角(border-radius:8px),阴影(box-shadow:10px),
对文字加特效(text-shadow、),线性渐变(gradient),旋转(transform)
transform:rotate(9deg) scale(0.85,0.90) translate(0px,-30px) skew(-9deg,0deg);//旋转,缩放,定位,倾斜
增加了更多的CSS选择器 多背景 rgba
一个满屏 品 字布局 如何设计?
display: block;和display: inline;的区别
block元素特点:
1.处于常规流中时,如果width没有设置,会自动填充满父容器
2.可以应用margin/padding
3.在没有设置高度的情况下会扩展高度以包含常规流中的子元素
4.处于常规流中时布局时在前后元素位置之间(独占一个水平空间)
5.忽略vertical-align
inline元素特点
1.水平方向上根据direction依次布局
2.不会在元素前后进行换行
3.受white-space控制
4.margin/padding在竖直方向上无效,水平方向上有效
5.width/height属性对非替换行内元素无效,宽度由元素内容决定
6.非替换行内元素的行框高由line-height确定,替换行内元素的行框高由height,margin,padding,border决定
6.浮动或绝对定位时会转换为block
7.vertical-align属性生效
display:none和visibility:hidden的区别?
display:none 隐藏对应的元素,在文档布局中不再给它分配空间,它各边的元素会合拢,就当他从来不存在。
visibility:hidden 隐藏对应的元素,但是在文档布局中仍保留原来的空间。
position:absolute和float属性的异同
共同点:对内联元素设置float和absolute属性,可以让元素脱离文档流,并且可以设置其宽高。
不同点:float仍会占据位置,absolute会覆盖文档流中的其他元素。
介绍一下box-sizing属性?
box-sizing属性主要用来控制元素的盒模型的解析模式。默认值是content-box。
content-box:让元素维持W3C的标准盒模型。元素的宽度/高度由border + padding + content的宽度/高度决定,设置width/height属性指的是content部分的宽/高
border-box:让元素维持IE传统盒模型(IE6以下版本和IE6~7的怪异模式)。设置width/height属性指的是border + padding + content
标准浏览器下,按照W3C规范对盒模型解析,一旦修改了元素的边框或内距,就会影响元素的盒子尺寸,就不得不重新计算元素的盒子尺寸,从而影响整个页面的布局。
常见兼容性问题?
* png24位的图片在iE6浏览器上出现背景,解决方案是做成PNG8.
* 浏览器默认的margin和padding不同。解决方案是加一个全局的*{margin:0;padding:0;}来统一。
* IE6双边距bug:块属性标签float后,又有横行的margin情况下,在ie6显示margin比设置的大。
浮动ie产生的双倍距离 #box{ float:left; width:10px; margin:0 0 0 100px;}
这种情况之下IE会产生20px的距离,解决方案是在float的标签样式控制中加入 ——_display:inline;将其转化为行内属性。(_这个符号只有ie6会识别)
渐进识别的方式,从总体中逐渐排除局部。
首先,巧妙的使用“\9”这一标记,将IE游览器从所有情况中分离出来。
接着,再次使用“+”将IE8和IE7、IE6分离开来,这样IE8已经独立识别。
css
.bb{
background-color:#f1ee18;/*所有识别*/
.background-color:#00deff\9; /*IE6、7、8识别*/
+background-color:#a200ff;/*IE6、7识别*/
_background-color:#1e0bd1;/*IE6识别*/
}
* IE下,可以使用获取常规属性的方法来获取自定义属性,
也可以使用getAttribute()获取自定义属性;
Firefox下,只能使用getAttribute()获取自定义属性.
解决方法:统一通过getAttribute()获取自定义属性.
* IE下,even对象有x,y属性,但是没有pageX,pageY属性;
Firefox下,event对象有pageX,pageY属性,但是没有x,y属性.
* 解决方法:(条件注释)缺点是在IE浏览器下可能会增加额外的HTTP请求数。
* Chrome 中文界面下默认会将小于 12px 的文本强制按照 12px 显示,
可通过加入 CSS 属性 -webkit-text-size-adjust: none; 解决.
超链接访问过后hover样式就不出现了 被点击访问过的超链接样式不在具有hover和active了解决方法是改变CSS属性的排列顺序:
L-V-H-A : a:link {} a:visited {} a:hover {} a:active {}
为什么要初始化CSS样式。
- 因为浏览器的兼容问题,不同浏览器对有些标签的默认值是不同的,如果没对CSS初始化往往会出现浏览器之间的页面显示差异。
- 当然,初始化样式会对SEO有一定的影响,但鱼和熊掌不可兼得,但力求影响最小的情况下初始化。
*最简单的初始化方法就是: * {padding: 0; margin: 0;} (不建议)
淘宝的样式初始化:
body, h1, h2, h3, h4, h5, h6, hr, p, blockquote, dl, dt, dd, ul, ol, li, pre, form, fieldset, legend, button, input, textarea, th, td { margin:0; padding:0; }
body, button, input, select, textarea { font:12px/1.5tahoma, arial, \5b8b\4f53; }
h1, h2, h3, h4, h5, h6{ font-size:100%; }
address, cite, dfn, em, var { font-style:normal; }
code, kbd, pre, samp { font-family:couriernew, courier, monospace; }
small{ font-size:12px; }
ul, ol { list-style:none; }
a { text-decoration:none; }
a:hover { text-decoration:underline; }
sup { vertical-align:text-top; }
sub{ vertical-align:text-bottom; }
legend { color:#000; }
fieldset, img { border:0; }
button, input, select, textarea { font-size:100%; }
table { border-collapse:collapse; border-spacing:0; }
absolute的containing block计算方式跟正常流有什么不同?
position跟display、margin collapse、overflow、float这些特性相互叠加后会怎么样?
对BFC规范的理解?
(W3C CSS 2.1 规范中的一个概念,它决定了元素如何对其内容进行定位,以及与其他元素的关 系和相互作用。)
css定义的权重
以下是权重的规则:标签的权重为1,class的权重为10,id的权重为100,以下例子是演示各种定义的权重值:
/*权重为1*/
div{
}
/*权重为10*/
.class1{
}
/*权重为100*/
#id1{
}
/*权重为100+1=101*/
#id1 div{
}
/*权重为10+1=11*/
.class1 div{
}
/*权重为10+10+1=21*/
.class1 .class2 div{
}
如果权重相同,则最后定义的样式会起作用,但是应该避免这种情况出现
用过媒体查询,针对移动端的布局吗?
使用 CSS 预处理器吗?喜欢那个?
SASS
如果需要手动写动画,你认为最小时间间隔是多久,为什么?(阿里)
多数显示器默认频率是60Hz,即1秒刷新60次,所以理论上最小间隔为1/60*1000ms = 16.7ms
display:inline-block 什么时候会显示间隙?(携程)
移除空格、使用margin负值、使用font-size:0、letter-spacing、word-spacing
JavaScript
函数防抖和函数节流
函数防抖是指频繁触发的情况下,只有足够的空闲时间,才执行代码一次
函数防抖的要点,也是需要一个setTimeout来辅助实现。延迟执行需要跑的代码。
如果方法多次触发,则把上次记录的延迟执行代码用clearTimeout清掉,重新开始。
如果计时完毕,没有方法进来访问触发,则执行代码。
//函数防抖
var timer = false
document.getElementById("debounce").onScroll = function() {
clearTimeout(timer)
timer = setTimeout(function(){
console.log(‘函数防抖’)
}, 300)
}函数节流是指一定时间内js方法只跑一次
函数节流的要点是,声明一个变量当标志位,记录当前代码是否在执行。
如果空闲,则可以正常触发方法执行。
如果代码正在执行,则取消这次方法执行,直接return。
//函数节流
var canScroll = true;
document.getElementById('throttle').onScroll = function() {
if (!canScroll) {
return;
}
canScroll = false;
setTimeout(function(){
console.log('函数节流');
canScroll = true;
},300)
}说几条写JavaScript的基本规范?
1.不要在同一行声明多个变量。
2.请使用 ===/!==来比较true/false或者数值
3.使用对象字面量替代new Array这种形式
4.不要使用全局函数。
5.Switch语句必须带有default分支
6.函数不应该有时候有返回值,有时候没有返回值。
7.For循环必须使用大括号
8.If语句必须使用大括号
9.for-in循环中的变量 应该使用var关键字明确限定作用域,从而避免作用域污染。
eval是做什么的?
它的功能是把对应的字符串解析成JS代码并运行;
应该避免使用eval,不安全,非常耗性能(2次,一次解析成js语句,一次执行)。
null,undefined 的区别?
null是一个表示”无”的对象,转为数值时为0;undefined是一个表示”无”的原始值,转为数值时为NaN。
当声明的变量还未被初始化时,变量的默认值为undefined。
undefined表示”缺少值”,就是此处应该有一个值,但是还没有定义。典型用法是:
(1)变量被声明了,但没有赋值时,就等于undefined。
(2) 调用函数时,应该提供的参数没有提供,该参数等于undefined。
(3)对象没有赋值的属性,该属性的值为undefined。
(4)函数没有返回值时,默认返回undefined。
null表示”没有对象”,即该处不应该有值。典型用法是:
(1) 作为函数的参数,表示该函数的参数不是对象。
(2) 作为对象原型链的终点。
http响应中content-type包含哪些内容
请求中的消息主体是用何种方式编码
application/x-www-form-urlencoded
这是最常见的 POST 提交数据的方式 按照 key1=val1&key2=val2 的方式进行编码
application/json
告诉服务端消息主体是序列化后的 JSON 字符串
浏览器缓存有哪些,通常缓存有哪几种方式
强缓存 强缓存如果命中,浏览器直接从自己的缓存中读取资源,不会发请求到服务器。
协商缓存 当强缓存没有命中的时候,浏览器一定会发送一个请求到服务器,通过服务器端依据资源的另外一些http header验证这个资源是否命中协商缓存,如果协商缓存命中,服务器会将这个请求返回(304),若未命中请求,则将资源返回客户端,并更新本地缓存数据(200)。
HTTP头信息控制缓存
Expires(强缓存)+过期时间 Expires是HTTP1.0提出的一个表示资源过期时间的header,它描述的是一个绝对时间
Cache-control(强缓存) 描述的是一个相对时间,在进行缓存命中的时候,都是利用客户端时间进行判断 管理更有效,安全一些 Cache-Control: max-age=3600
Last-Modified/If-Modified-Since(协商缓存) 标示这个响应资源的最后修改时间。Last-Modified是服务器相应给客户端的,If-Modified-Sinces是客户端发给服务器,服务器判断这个缓存时间是否是最新的,是的话拿缓存。
Etag/If-None-Match(协商缓存) etag和last-modified类似,他是发送一个字符串来标识版本。
Node.js的适用场景?
高并发、聊天、实时消息推送new Vue({...})实例化过程中发生了什么?
每个 Vue 应用都是通过 Vue 函数创建一个新的 Vue 实例开始的
参考:
https://cn.vuejs.org/v2/guide/instance.html
Vue生命周期总结
简单总结为三个步骤:初始化创建vue实例->编译模版挂载到dom->销毁vue实例
每个 Vue 实例呢,在被创建之前都要经过一系列的初始化过程。
过程如下:
首先根据传入的选项对象创建Vue实例
data 对象中能找到的所有的属性。当这些属性的值发生改变时,视图将会产生“响应”,即匹配更新为新的值,双向绑定概念。
生命周期图示:
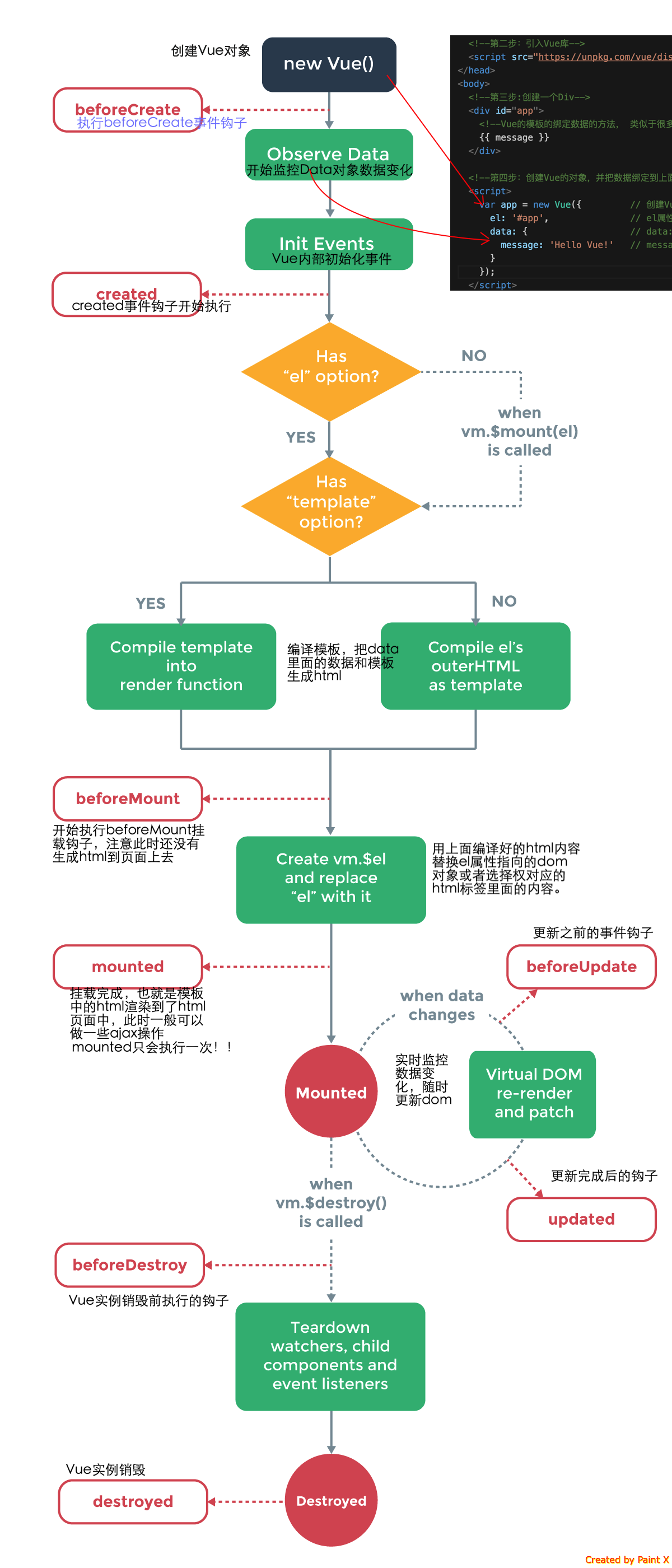
Vue双向绑定概念
双向绑定是指:HTML标签与数据对象互绑。许多遵循MVVM模型的框架如Vue、angular都有此功能。好处是简写了代码提升了开发效率,变革了之前Dom的开发方式,主导开发方式变成了前端由数据驱动的开发时代。
vue.js 则是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者(文本节点则是作为订阅者),在收到消息后执行相应的更新操作。
compile主要做的事情是解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
MVVM作为数据绑定的入口,整合Observer、Compile和Watcher三者,通过Observer来监听自己的model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer和Compile之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
AngularJS 采用“脏值检测”的方式,数据发生变更后,对于所有的数据和视图的绑定关系进行一次检测,识别是否有数据发生了改变。

生命周期有哪些, 怎么用?
beforecreated:el 和 data 并未初始化
created:完成了 data 数据的初始化,el没有
beforeMount:完成了 el 和 data 初始化
mounted :完成挂载 updated;destroyed
react:初始化阶段、运行中阶段、销毁阶段
初始化getDefaultProps()和getInitialState()初始化
componentWillMount() 在组件即将被渲染到页面
render() 组件渲染
componentDidMount() 组件被渲染到页面上,
运行中shouldComponentUpdate() componentWillUpdate() render() componentDidUpdate()
销毁componentWillUnmount()
父子组件怎么通信的?
兄弟组件怎么通信的?
vuex 建立一个vue实例 emit触发事件 on监听事件
redux 子A -> 父 -> 子B
介绍一下你对webpack的理解,和gulp有什么不同
Webpack是模块打包工具,他会分析模块间的依赖关系,然后使用loaders处理它们,最后生成一个优化并且合并后的静态资源。
gulp是前端自动化工具 能够优化前端工作流程,比如文件合并压缩
webpack打包速度慢,你觉得可能的原因是什么,该如何解决
模块太多
Webpack 可以配置 externals 来将依赖的库指向全局变量,从而不再打包这个库
Node,Koa用的怎么样
koa是一个相对于express来说,更小,更健壮,更富表现力的Web框架,不用写回调
koa是从第一个中间件开始执行,遇到next进入下一个中间件,一直执行到最后一个中间件,在逆序
async await语法的支持
UMD规范和ES6模块化,Commonjs的对比
CommonJS是一个更偏向于服务器端的规范。用于NodeJS 是同步的
AMD是依赖前置的
CMD推崇依赖就近,延迟执行。可以把你的依赖写进代码的任意一行
AMD和CMD都是用difine和require,但是CMD标准倾向于在使用过程中提出依赖,就是不管代码写到哪突然发现需要依赖另一个模块,那就在当前代码用require引入就可以了,规范会帮你搞定预加载,你随便写就可以了。但是AMD标准让你必须提前在头部依赖参数部分写好(没有写好? 倒回去写好咯)。这就是最明显的区别。
UMD写一个文件需要兼容不同的加载规范
ES6通过import、export实现模块的输入输出。其中import命令用于输入其他模块提供的功能,export命令用于规定模块的对外接口。
commonjs 同步 顺序执行
AMD 提前加载,不管是否调用模块,先解析所有模块 requirejs 速度快 有可能浪费资源
CMD 提前加载,在真正需要使用(依赖)模块时才解析该模块 seajs 按需解析 性能比AMD差
如何评价AngularJS和BackboneJS
backbone具有依赖性,依赖underscore.js。Backbone + Underscore + jQuery(or Zepto) 就比一个AngularJS 多出了2 次HTTP请求.
Backbone的Model没有与UI视图数据绑定,而是需要在View中自行操作DOM来更新或读取UI数据。AngularJS与此相反,Model直接与UI视图绑定,Model与UI视图的关系,通过directive封装,AngularJS内置的通用directive,就能实现大部分操作了,也就是说,基本不必关心Model与UI视图的关系,直接操作Model就行了,UI视图自动更新。
AngularJS的directive,你输入特定数据,他就能输出相应UI视图。是一个比较完善的前端MVW框架,包含模板,数据双向绑定,路由,模块化,服务,依赖注入等所有功能,模板功能强大丰富,并且是声明式的,自带了丰富的 Angular 指令。
react和vue有哪些不同 说说你对这两个框架的看法
都用了virtual dom的方式, 性能都很好
ui上都是组件化的写法,开发效率很高
vue是双向数据绑定,react是单项数据绑定,当工程规模比较大时双向数据绑定会很难维护
vue适合不会持续的 小型的web应用,使用vue.js能带来短期内较高的开发效率. 否则采用react
介绍js的基本数据类型。
number,string,boolean,object,undefined
Javascript如何实现继承?
通过原型和构造器
["1", "2", "3"].map(parseInt) 答案是多少?
[1, NaN, NaN] 因为 parseInt 需要两个参数 (val, radix),其中 radix 表示解析时用的基数。map 传了 3 个 (element, index, array),对应的 radix 不合法导致解析失败。
如何创建一个对象? (画出此对象的内存图)
function Person(name, age) {
this.name = name;
this.age = age;
this.sing = function() { alert(this.name) }
}
谈谈This对象的理解。
this是js的一个关键字,随着函数使用场合不同,this的值会发生变化。
但是有一个总原则,那就是this指的是调用函数的那个对象。
this一般情况下:是全局对象Global。 作为方法调用,那么this就是指这个对象
事件是?IE与火狐的事件机制有什么区别? 如何阻止冒泡?
1. 我们在网页中的某个操作(有的操作对应多个事件)。例如:当我们点击一个按钮就会产生一个事件。是可以被 JavaScript 侦测到的行为。
2. 事件处理机制:IE是事件冒泡、火狐是 事件捕获;
3. ev.stopPropagation();
什么是闭包(closure),为什么要用它?
执行say667()后,say667()闭包内部变量会存在,而闭包内部函数的内部变量不会存在.使得Javascript的垃圾回收机制GC不会收回say667()所占用的资源,因为say667()的内部函数的执行需要依赖say667()中的变量。这是对闭包作用的非常直白的描述.
function say667() {
// Local variable that ends up within closure
var num = 666;
var sayAlert = function() { alert(num); }
num++;
return sayAlert;
}
var sayAlert = say667();
sayAlert()//执行结果应该弹出的667
"use strict";是什么意思 ? 使用它的好处和坏处分别是什么?
如何判断一个对象是否属于某个类?
使用instanceof (待完善)
if(a instanceof Person){
alert('yes');
}
new操作符具体干了什么呢?
new共经历了四个过程。
var fn = function () { };
var fnObj = new fn();
1、创建了一个空对象
var obj = new object();
2、设置原型链
obj._proto_ = fn.prototype;
3、让fn的this指向obj,并执行fn的函数体
var result = fn.call(obj);
4、判断fn的返回值类型,如果是值类型,返回obj。如果是引用类型,就返回这个引用类型的对象。
if (typeof(result) == "object"){
fnObj = result;
} else {
fnObj = obj;
}
Javascript中,有一个函数,执行时对象查找时,永远不会去查找原型,这个函数是?
hasOwnProperty
JSON 的了解?
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。
它是基于JavaScript的一个子集。数据格式简单, 易于读写, 占用带宽小
{"age":"12", "name":"back"}
js延迟加载的方式有哪些?
defer和async、动态创建DOM方式(用得最多)、按需异步载入js
ajax 是什么?
同步和异步的区别?
如何解决跨域问题?
跨域通信:js进行DOM操作、通信时如果目标与当前窗口不满足同源条件,浏览器为了安全会阻止跨域操作。跨域通信通常有以下方法
如果是log之类的简单单项通信,新建<img>,<script>,<link>,<iframe>元素,通过src,href属性设置为目标url。实现跨域请求
如果请求json数据,使用<script>进行jsonp请求 现代浏览器中多窗口通信使用HTML5规范的targetWindow.postMessage(data, origin);其中data是需要发送的对象,origin是目标窗口的origin。window.addEventListener('message', handler, false);handler的event.data是postMessage发送来的数据,event.origin是发送窗口的origin,event.source是发送消息的窗口引用
flash,内部服务器设置代理页面 通过修改document.domain来跨域。将子域和主域的document.domain设为同一个主域.前提条件:这两个域名必须属于同一个基础域名!而且所用的协议,端口都要一致,否则无法利用document.domain进行跨域
跨域请求数据,现代浏览器可使用HTML5规范的CORS功能,只要目标服务器返回HTTP头部**Access-Control-Allow-Origin: ***即可像普通ajax一样访问跨域资源
window.name(既不复杂,也能兼容到几乎所有浏览器)
模块化怎么做?
立即执行函数,不暴露私有成员
var module1 = (function(){
var _count = 0;
var m1 = function(){
//...
};
var m2 = function(){
//...
};
return {
m1 : m1,
m2 : m2
};
})();
AMD(Modules/Asynchronous-Definition)、CMD(Common Module Definition)规范区别?
异步加载的方式有哪些?
(1) defer,只支持IE
(2) async:
(3) 创建script,插入到DOM中,加载完毕后callBack
documen.write和 innerHTML的区别
document.write只能重绘整个页面
innerHTML可以重绘页面的一部分
.call() 和 .apply() 的区别?
例子中用 add 来替换 sub,add.call(sub,3,1) == add(3,1) ,所以运行结果为:alert(4);
注意:js 中的函数其实是对象,函数名是对 Function 对象的引用。
function add(a,b)
{
alert(a+b);
}
function sub(a,b)
{
alert(a-b);
}
add.call(sub,3,1);
Jquery与jQuery UI 有啥区别?
*jQuery是一个js库,主要提供的功能是选择器,属性修改和事件绑定等等。
*jQuery UI则是在jQuery的基础上,利用jQuery的扩展性,设计的插件。
提供了一些常用的界面元素,诸如对话框、拖动行为、改变大小行为等等JQuery的源码看过吗?能不能简单说一下它的实现原理?
JQuery的end()方法是什么功能?
大多数 jQuery 的选择器方法会返回一个当前选择器匹配到元素集对象。end()是返回前选择器匹配到后、剩下的元素集合。
jquery 中的deferred()方法是什么?
jq实现异步编程promise规范的API,用它能解决传统异步编程代码执行结构不清晰的问题。
传统的异步编程会带来的一些问题:
1.序列化异步操作导致的问题
1),延续传递风格Continuation Passing Style (CPS)
2),深度嵌套
3),回调地狱
2.并行异步操作的困难
jquery 中如何将数组转化为json字符串,然后再转化回来?
jQuery中没有提供这个功能,所以你需要先编写两个jQuery的扩展:
$.fn.stringifyArray = function(array) {
return JSON.stringify(array)
}
$.fn.parseArray = function(array) {
return JSON.parse(array)
}
然后调用:
$("").stringifyArray(array)
针对 jQuery 的优化方法?
*基于Class的选择性的性能相对于Id选择器开销很大,因为需遍历所有DOM元素。
*频繁操作的DOM,先缓存起来再操作。用Jquery的链式调用更好。
比如:var str=$("a").attr("href");
*for (var i = size; i < arr.length; i++) {}
for 循环每一次循环都查找了数组 (arr) 的.length 属性,在开始循环的时候设置一个变量来存储这个数字,可以让循环跑得更快:
for (var i = size, length = arr.length; i < length; i++) {}
JavaScript中的作用域与变量声明提升?
那些操作会造成内存泄漏?
内存泄漏指任何对象在您不再拥有或需要它之后仍然存在。
垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为 0(没有其他对象引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收。
setTimeout 的第一个参数使用字符串而非函数的话,会引发内存泄漏。
闭包、控制台日志、循环(在两个对象彼此引用且彼此保留时,就会产生一个循环)
Javascript垃圾回收方法
标记清除(mark and sweep)
这是JavaScript最常见的垃圾回收方式,当变量进入执行环境的时候,比如函数中声明一个变量,垃圾回收器将其标记为“进入环境”,当变量离开环境的时候(函数执行结束)将其标记为“离开环境”。
垃圾回收器会在运行的时候给存储在内存中的所有变量加上标记,然后去掉环境中的变量以及被环境中变量所引用的变量(闭包),在这些完成之后仍存在标记的就是要删除的变量了
引用计数(reference counting)
在低版本IE中经常会出现内存泄露,很多时候就是因为其采用引用计数方式进行垃圾回收。引用计数的策略是跟踪记录每个值被使用的次数,当声明了一个 变量并将一个引用类型赋值给该变量的时候这个值的引用次数就加1,如果该变量的值变成了另外一个,则这个值得引用次数减1,当这个值的引用次数变为0的时 候,说明没有变量在使用,这个值没法被访问了,因此可以将其占用的空间回收,这样垃圾回收器会在运行的时候清理掉引用次数为0的值占用的空间。
在IE中虽然JavaScript对象通过标记清除的方式进行垃圾回收,但BOM与DOM对象却是通过引用计数回收垃圾的,
也就是说只要涉及BOM及DOM就会出现循环引用问题。
JQuery一个对象可以同时绑定多个事件,这是如何实现的?
jQuery链式操作如何实现以及为什么要用链式操作?
链式写法原理通过调用对象上的方法最后 return this 把对象再返回回来,return、prototype是其原理实现的核心点。
jq是如何实现链式写法的呢?
//jquery源码 jQuery = function (selector, context) { return new jQuery.fn.init(selector, context, rootjQuery); }, jQuery.fn = jQuery.prototype = {} jQuery.fn.init.prototype = jQuery.fn;
这几行代码实现了JQ的链式写法定义一个函数,return 一个实例,实例对象的init函数里进行了处理初始化操作,比如选择器,拼接字符串等等,这里不一一介绍。 最后再将jq的prototype 赋值给init方法的prototype。这就是jq用起来简单方便的黑魔法原理所在
为什么要用链式操作呢?一般的解释是节省代码量,代码看起来更优雅,其实用链式操作的好处是解决了异步编程模型的执行流程不清晰的问题,提升了更好的异步编程体验。jQuery中$(document).ready就非常好的阐释了这一理念。
DOMCotentLoaded是一个事件,在DOM并未加载前,jQuery的大部分操作都不会奏效,但jQuery的设计者并没有把他当成事件一样来处理,而是转成一种“选其对象,对其操作”的思路。$选择了document对象,ready是其方法进行操作。这样子流程问题就非常清晰了,在链条越后位置的方法就越后执行。
CommonJS中的异步编程模型也延续了这一想法,每一个异步任务返回一个Promise对象,该对象有一个then方法,允许指定回调函数。 所以我们可以这样写: f1().then(f2).then(f3); 这种方法我们无需太过关注实现,也不太需要理解异步,只要懂得通过函数选对象,通过then进行操作,就能进行异步编程。
如何判断当前脚本运行在浏览器还是node环境中?(阿里)
通过判断Global对象是否为window,如果不为window,当前脚本没有运行在浏览器中其他问题
你遇到过比较难的技术问题是?你是如何解决的?
常使用的库有哪些?常用的前端开发工具?开发过什么应用或组件?
页面重构怎么操作?
列举IE 与其他浏览器不一样的特性?
99%的网站都需要被重构是那本书上写的?
什么叫优雅降级和渐进增强?
WEB应用从服务器主动推送Data到客户端有那些方式?
对Node的优点和缺点提出了自己的看法?
*(优点)因为Node是基于事件驱动和无阻塞的,所以非常适合处理并发请求,
因此构建在Node上的代理服务器相比其他技术实现(如Ruby)的服务器表现要好得多。
此外,与Node代理服务器交互的客户端代码是由javascript语言编写的,
因此客户端和服务器端都用同一种语言编写,这是非常美妙的事情。
*(缺点)Node是一个相对新的开源项目,所以不太稳定,它总是一直在变,
而且缺少足够多的第三方库支持。看起来,就像是Ruby/Rails当年的样子。
如何进行网站性能优化,雅虎军规24条!
雅虎Best Practices for Speeding Up Your Web Site:
content方面
- 减少HTTP请求:合并文件、CSS精灵、inline Image 减少DNS查询:DNS查询完成之前浏览器不能从这个主机下载任何任何文件。方法:DNS缓存、将资源分布到恰当数量的主机名,平衡并行下载和DNS查询 避免重定向:多余的中间访问 使Ajax可缓存 非必须组件延迟加载 未来所需组件预加载 减少DOM元素数量 将资源放到不同的域下:浏览器同时从一个域下载资源的数目有限,增加域可以提高并行下载量 减少iframe数量 不要404
Server方面
- 使用CDN 添加Expires或者Cache-Control响应头 对组件使用Gzip压缩 配置ETag Flush Buffer Early Ajax使用GET进行请求 避免空src的img标签
Cookie方面
- 减小cookie大小 引入资源的域名不要包含cookie
css方面
- 将样式表放到页面顶部 不使用CSS表达式 使用不使用@import 不使用IE的Filter
Javascript方面
- 将脚本放到页面底部 将javascript和css从外部引入 压缩javascript和css 删除不需要的脚本 减少DOM访问 合理设计事件监听器
图片方面
- 优化图片:根据实际颜色需要选择色深、压缩 优化css精灵 不要在HTML中拉伸图片 保证favicon.ico小并且可缓存
移动方面
- 保证组件小于25k Pack Components into a Multipart Document
对普通的网站有一个统一的思路,就是尽量向前端优化、减少数据库操作、减少磁盘IO。向前端优化指的是,在不影响功能和体验的情况下,能在浏览器执行的不要在服务端执行,能在缓存服务器上直接返回的不要到应用服务器,程序能直接取得的结果不要到外部取得,本机内能取得的数据不要到远程取,内存能取到的不要到磁盘取,缓存中有的不要去数据库查询。减少数据库操作指减少更新次数、缓存结果减少查询次数、将数据库执行的操作尽可能的让你的程序完成(例如join查询),减少磁盘IO指尽量不使用文件系统作为缓存、减少读写文件次数等。程序优化永远要优化慢的部分,换语言是无法“优化”的。
http状态码有那些?分别代表是什么意思?
100-199 用于指定客户端应相应的某些动作。
200-299 用于表示请求成功。
300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息。
400-499 用于指出客户端的错误。400 1、语义有误,当前请求无法被服务器理解。401 当前请求需要用户验证 403 服务器已经理解请求,但是拒绝执行它。
500-599 用于支持服务器错误。 503 – 服务不可用
一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?(流程说的越详细越好)
查找浏览器缓存
DNS解析、查找该域名对应的IP地址、重定向(301)、发出第二个GET请求
进行HTTP协议会话
客户端发送报头(请求报头)
服务器回馈报头(响应报头)
html文档开始下载
文档树建立,根据标记请求所需指定MIME类型的文件
文件显示
[
浏览器这边做的工作大致分为以下几步:
加载:根据请求的URL进行域名解析,向服务器发起请求,接收文件(HTML、JS、CSS、图象等)。
解析:对加载到的资源(HTML、JS、CSS等)进行语法解析,建议相应的内部数据结构(比如HTML的DOM树,JS的(对象)属性表,CSS的样式规则等等)
}
除了前端以外还了解什么其它技术么?你最最厉害的技能是什么?
你常用的开发工具是什么,为什么?
对前端界面工程师这个职位是怎么样理解的?它的前景会怎么样?
前端是最贴近用户的程序员,比后端、数据库、产品经理、运营、安全都近。
1、实现界面交互
2、提升用户体验
3、有了Node.js,前端可以实现服务端的一些事情
前端是最贴近用户的程序员,前端的能力就是能让产品从 90分进化到 100 分,甚至更好,
参与项目,快速高质量完成实现效果图,精确到1px;
与团队成员,UI设计,产品经理的沟通;
做好的页面结构,页面重构和用户体验;
处理hack,兼容、写出优美的代码格式;
针对服务器的优化、拥抱最新前端技术。
加班的看法?
加班就像借钱,原则应当是------救急不救穷
平时如何管理你的项目?
先期团队必须确定好全局样式(globe.css),编码模式(utf-8) 等;
编写习惯必须一致(例如都是采用继承式的写法,单样式都写成一行);
标注样式编写人,各模块都及时标注(标注关键样式调用的地方);
页面进行标注(例如 页面 模块 开始和结束);
CSS跟HTML 分文件夹并行存放,命名都得统一(例如style.css);
JS 分文件夹存放 命名以该JS功能为准的英文翻译。
图片采用整合的 images.png png8 格式文件使用 尽量整合在一起使用方便将来的管理
如何设计突发大规模并发架构?
说说最近最流行的一些东西吧?常去哪些网站?
Node.js、Mongodb、npm、MVVM、MEAN、three.js
移动端(Android IOS)怎么做好用户体验?
清晰的视觉纵线、信息的分组、极致的减法、
利用选择代替输入、标签及文字的排布方式、
依靠明文确认密码、合理的键盘利用、
你在现在的团队处于什么样的角色,起到了什么明显的作用?
你认为怎样才是全端工程师(Full Stack developer)?
介绍一个你最得意的作品吧?
你的优点是什么?缺点是什么?
如何管理前端团队?
最近在学什么?能谈谈你未来3,5年给自己的规划吗?
想问公司的问题?
问公司问题:
目前关注哪些最新的Web前端技术(未来的发展方向)?
前端团队如何工作的(实现一个产品的流程)?
公司的薪资结构是什么样子的?
前端学习网站推荐
1. 极客标签: http://www.gbtags.com/
2. 掘金: https://juejin.im/
3. 前端周刊: http://www.feweekly.com/issues
4. 慕课网: http://www.imooc.com/
5. Segmentfault:https://segmentfault.com/
6. Hacker News: https://news.ycombinator.com/news
7. InfoQ: http://www.infoq.com/
8. w3cplus: http://www.w3cplus.com/
9. Stack Overflow: http://stackoverflow.com/
10.w3school: http://www.w3school.com.cn/
11.mozilla: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript
文档推荐
(内容7)——————