上一篇博文我们介绍了ML.NET 的入门:
本文我们继续,研究分享一下聚类算法k-means.
一、k-means算法简介
k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。
1. k-means算法的原理是什么样的?参考:https://baijiahao.baidu.com/s?id=1622412414004300046&wfr=spider&for=pc
k-means算法中的k代表类簇个数,means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述),因此,k-means算法又称为k-均值算法。
k-means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。
数据对象间距离的计算有很多种,k-means算法通常采用欧氏距离来计算数据对象间的距离。算法详细的流程描述如下:

2. k-means算法的优缺点:
优点: 算法简单易实现;
缺点: 需要用户事先指定类簇个数; 聚类结果对初始类簇中心的选取较为敏感; 容易陷入局部最优; 只能发现球形类簇;
接下来我们说一下k-means算法的经典应用场景:鸢尾花
二、鸢尾花
首先,鸢尾花是一种植物,有四个典型的属性:
- 花瓣长度
- 花瓣宽度
- 花萼长度
- 花萼宽度

鸢尾花有三大品种setosa、versicolor 或 virginica ,每个品种对应的以上四个属性各不相同。
鸢尾花数据集中一共包含了150条记录,每个样本的包含它的萼片长度和宽度,花瓣的长度和宽度以及这个样本所属的具体品种。每个品种的样本量为50条。
鸢尾花样本数据格式:
5.2,3.4,1.4,0.2,Iris-setosa
4.7,3.2,1.6,0.2,Iris-setosa
4.8,3.1,1.6,0.2,Iris-setosa
6.0,2.2,4.0,1.0,Iris-versicolor
6.1,2.9,4.7,1.4,Iris-versicolor
5.6,2.9,3.6,1.3,Iris-versicolor
5.7,2.5,5.0,2.0,Iris-virginica
5.8,2.8,5.1,2.4,Iris-virginica
6.4,3.2,5.3,2.3,Iris-virginica
上述数据中,第一列是鸢尾花花萼长度,第二列是鸢尾花花萼宽度,第三列是鸢尾花花瓣长度,第四列是鸢尾花花瓣宽度。
基于上述数据做机器学习、训练,形成一个模型。
三、ML.NET k-means
基于上述的场景,我们先准备样本数据,https://github.com/dotnet/machinelearning/blob/master/test/data/iris.data
另存为iris.data文件,每个属性逗号间隔。
然后,大致梳理了一下实现步骤:
- 新建一个.Net Core Console Project
- 添加Microsoft.ML nuget 1.2.0版本
- 添加鸢尾花数据、预测类实体类IrisData、ClusterPrediction
- 构造MLContext、从iris.data构造IDataView,采用Trainers.KMeans进行模型训练,形成模型文件:IrisClusteringModel.zip
- 输入一个测试数据,进行预测。
好,让我们开始搞吧:
1. 新建一个.Net Core Console Project
先看下用的VS的版本:

新建一个.Net Core Console的Project KMeansDemo
2. 添加Microsoft.ML nuget 1.2.0版本
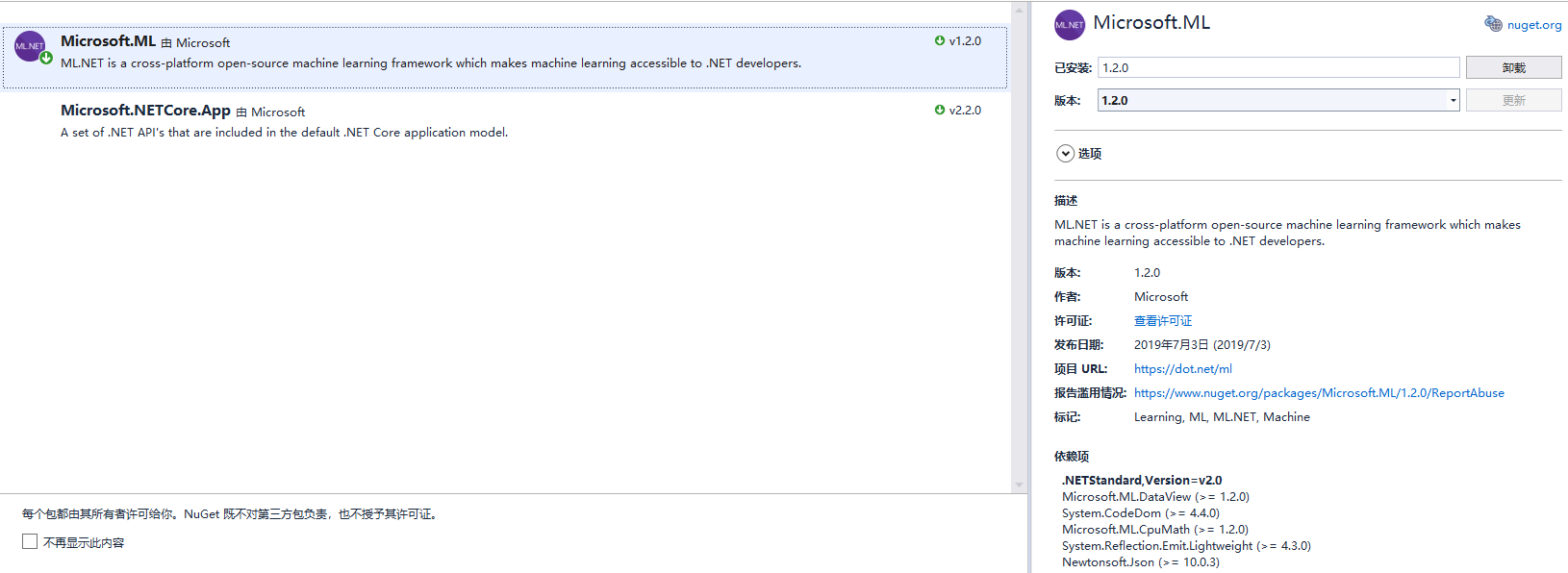
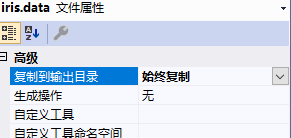
将iris.data文件放到Project下的Data目录中,同时右键iris.data,设置为:始终复制
3. 添加鸢尾花数据、预测类实体类IrisData、ClusterPrediction
using System;
using System.Collections.Generic;
using System.Text;
namespace KMeansDemo
{
using Microsoft.ML.Data;
/// <summary>
/// 鸢尾花数据
/// </summary>
class IrisData
{
/// <summary>
/// 鸢尾花花萼长度
/// </summary>
[LoadColumn(0)]
public float SepalLength;
/// <summary>
/// 鸢尾花花萼宽度
/// </summary>
[LoadColumn(1)]
public float SepalWidth;
/// <summary>
/// 鸢尾花花瓣长度
/// </summary>
[LoadColumn(2)]
public float PetalLength;
/// <summary>
/// 鸢尾花花瓣宽度
/// </summary>
[LoadColumn(3)]
public float PetalWidth;
}
}
using System;
using System.Collections.Generic;
using System.Text;
namespace KMeansDemo
{
using Microsoft.ML.Data;
public class ClusterPrediction
{
/// <summary>
/// 预测的族群
/// </summary>
[ColumnName("PredictedLabel")]
public uint PredictedClusterId;
[ColumnName("Score")]
public float[] Distances;
}
}4. 构造MLContext、从iris.data构造IDataView,采用Trainers.KMeans进行模型训练,形成模型文件:IrisClusteringModel.zip
在Main函数中,开始编码 ,首先添加引用
using Microsoft.ML;
声明样本数据文件和模型文件的文件路径
static readonly string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "iris.data");
static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "IrisClusteringModel.zip");
构造MLContext、IDataView,采用Trainer.KMeans进行模型训练,形成模型文件:IrisClusteringModel.zip
var mlContext = new MLContext(seed: 0);
IDataView dataView = mlContext.Data.LoadFromTextFile<IrisData>(_dataPath, hasHeader: false, separatorChar: ',');
string featuresColumnName = "Features";
var pipeline = mlContext.Transforms
.Concatenate(featuresColumnName, "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")
.Append(mlContext.Clustering.Trainers.KMeans(featuresColumnName, numberOfClusters: 3));
var model = pipeline.Fit(dataView);
using (var fileStream = new FileStream(_modelPath, FileMode.Create, FileAccess.Write, FileShare.Write))
{
mlContext.Model.Save(model, dataView.Schema, fileStream);
}
Console.WriteLine("完成模型训练!");
Console.WriteLine("模型文件:"+ _modelPath);
5. 输入一个测试数据,进行预测。
输入一个测试数据,使用生成的模型,进行预测:
var predictor = mlContext.Model.CreatePredictionEngine<IrisData, ClusterPrediction>(model);
var Setosa = new IrisData
{
SepalLength = 5.1f,
SepalWidth = 3.5f,
PetalLength = 1.4f,
PetalWidth = 0.2f
};
var prediction = predictor.Predict(Setosa);
Console.WriteLine($"Cluster: {prediction.PredictedClusterId}");
Console.WriteLine($"Distances: {string.Join(" ", prediction.Distances)}");
Console.WriteLine("Press any key!");全部的代码:
1 using Microsoft.ML; 2 using System; 3 using System.IO; 4 5 namespace KMeansDemo 6 { 7 class Program 8 { 9 static readonly string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "iris.data"); 10 static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "IrisClusteringModel.zip"); 11 12 static void Main(string[] args) 13 { 14 var mlContext = new MLContext(seed: 0); 15 IDataView dataView = mlContext.Data.LoadFromTextFile<IrisData>(_dataPath, hasHeader: false, separatorChar: ','); 16 string featuresColumnName = "Features"; 17 var pipeline = mlContext.Transforms 18 .Concatenate(featuresColumnName, "SepalLength", "SepalWidth", "PetalLength", "PetalWidth") 19 .Append(mlContext.Clustering.Trainers.KMeans(featuresColumnName, numberOfClusters: 3)); 20 var model = pipeline.Fit(dataView); 21 using (var fileStream = new FileStream(_modelPath, FileMode.Create, FileAccess.Write, FileShare.Write)) 22 { 23 mlContext.Model.Save(model, dataView.Schema, fileStream); 24 } 25 Console.WriteLine("完成模型训练!"); 26 Console.WriteLine("模型文件:"+ _modelPath); 27 28 //预测 29 var predictor = mlContext.Model.CreatePredictionEngine<IrisData, ClusterPrediction>(model); 30 31 var Setosa = new IrisData 32 { 33 SepalLength = 5.1f, 34 SepalWidth = 3.5f, 35 PetalLength = 1.4f, 36 PetalWidth = 0.2f 37 }; 38 39 var prediction = predictor.Predict(Setosa); 40 Console.WriteLine($"Cluster: {prediction.PredictedClusterId}"); 41 Console.WriteLine($"Distances: {string.Join(" ", prediction.Distances)}"); 42 Console.WriteLine("Press any key!"); 43 } 44 } 45 }
Run,看一下输出:

以上就是通过ML.NET 的KMeans算法,实现聚类。
上面的数据是一个监督学习的样本,同时是一个数值类型的数据,比较好奇的是,能不能对文本数据+值数据进行聚类,下一篇,我们将继续完成文本数据+值数据的聚类分析。
以上,分享给大家。
周国庆
2019/7/14