深度学习已经成为图像识别领域的核心技术,特别是在目标检测、图像分割等任务中,深度神经网络的应用取得了显著进展。在这些任务的网络架构中,通常可以分为三个主要部分:Backbone、Neck 和 Head。这些部分在整个网络中扮演着至关重要的角色,它们各自处理不同的任务,从特征提取到最终的预测输出,形成了一个完整的图像处理流程。
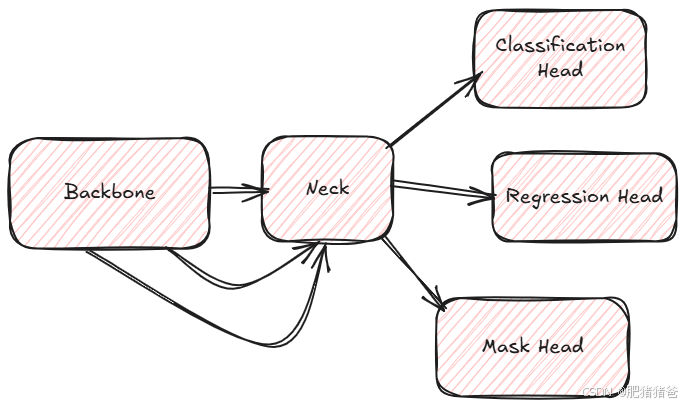
本文将详细介绍这三部分的作用以及它们在目标检测和图像分割中的应用,帮助大家更好地理解深度学习图像算法的网络架构。
1. Backbone:特征提取的基础
1.1 Backbone 的作用
Backbone 是深度学习模型中用于提取图像特征的部分。其主要作用是从输入的图像中提取出不同层次、不同尺度的特征,这些特征将被传递到后续的网络部分进行进一步的处理。在目标检测和图像分割等任务中,Backbone 通常由一些经典的卷积神经网络(CNN)架构组成,比如 ResNet、VGG、EfficientNet 等。
1.2 常见的 Backbone 网络
- ResNet(Residual Networks):ResNet 是一种采用了残差连接的深度神经网络,能够有效解决深度网络中的梯度消失问题。它通过引入残差模块,使得网络能够更深层次地训练,从而提取更加丰富的特征。
- VGG(Visual Geometry Group):VGG 是一种经典的卷积神经网络架构,虽然它较为简单,但在许多计算机视觉任务中仍然表现良好。它通常由多个卷积层和池化层堆叠而成,结构比较深,能够提取多层次的图像特征。
- EfficientNet:EfficientNet 采用了复合缩放的策略,通过在宽度、深度和分辨率三个维度上进行有效的扩展,获得了较为高效的计算性能。它在保证精度的同时大大减少了计算量和参数量,适用于需要高效计算的场景。
1.3 Backbone 的作用在目标检测中的体现
Backbone 主要用于提取图像中的 低级特征(如边缘、纹理)和 高级特征(如物体的形状、类别)。在目标检测任务中,Backbone 会生成 特征图(Feature Map),这些特征图用于后续目标定位、分类和其他任务。
2. Neck:多尺度特征融合
2.1 Neck 的作用
Neck 部分负责在 Backbone 提取的基础特征上进行进一步处理。它的主要任务是 多尺度特征融合。由于图像中物体的尺寸可能非常不同,目标检测和图像分割模型需要同时处理大物体和小物体。Neck 通过在多个尺度上提取特征,确保模型能够处理各种尺寸的目标。
2.2 常见的 Neck 架构
- FPN(Feature Pyramid Networks):FPN 是一种典型的多尺度特征融合方法,特别适合处理目标检测中的多尺度问题。它通过自上而下的路径对不同层次的特征进行融合,使得高层特征能够与低层特征结合,从而提高检测精度。
- PANet(Path Aggregation Network):PANet 是另一种改进的多尺度特征融合方法,它通过引入路径聚合机制进一步优化了特征的融合效果,增强了不同尺度之间的信息流动。
- BiFPN(Bidirectional Feature Pyramid Networks):BiFPN 是 FPN 的一种扩展,通过双向信息流动的设计,使得不同尺度的特征能够更加充分地融合,提高了模型在多尺度物体检测中的能力。
2.3 Neck 的作用在目标检测中的体现
在目标检测任务中,Neck 主要用于处理 Backbone 提取的多层次特征,将其融合成更加丰富的特征图,提升对不同尺寸目标的检测能力。例如,FPN 在目标检测中的应用,可以帮助模型在同一张图像中同时识别大物体和小物体。
3. Head:最终预测输出
3.1 Head 的作用
Head 是网络的最后一部分,负责根据 Neck 融合后的特征图,进行 目标检测的分类和回归预测。通常情况下,Head 会输出目标类别的 概率分布 和 边界框(Bounding Box),或者输出像素级的 分割结果(在图像分割任务中)。
3.2 常见的 Head 架构
-
目标检测中的 Head:
- 分类头(Classification Head):输出每个候选区域属于不同类别的概率。
- 回归头(Regression Head):预测目标的位置,即边界框的坐标(如左上角和右下角的坐标)。
经典的目标检测框架,如 Faster R-CNN 和 YOLO 都包含分类头和回归头,用于预测目标类别和位置。
-
图像分割中的 Head:
- 像素级分类头(Pixel-wise Classification Head):在图像分割任务中,Head 负责为每个像素分配一个类别标签。常见的图像分割网络如 U-Net 就是通过这种方式进行像素级别的预测。
3.3 Head 的作用在目标检测中的体现
Head 部分最终决定了检测框的精度和准确性,它直接影响模型的 定位能力 和 分类精度。目标检测中,Head 会根据 Neck 提供的多尺度特征图,生成候选框并进行精确的分类和定位。而在图像分割中,Head 会为每个像素点分配一个标签,最终实现图像的精细分割。
4. 完整的目标检测架构
我们将通过一个简化的目标检测框架(例如 Faster R-CNN)来展示 Backbone、Neck 和 Head 的组合:
4.1 Faster R-CNN 结构示意图
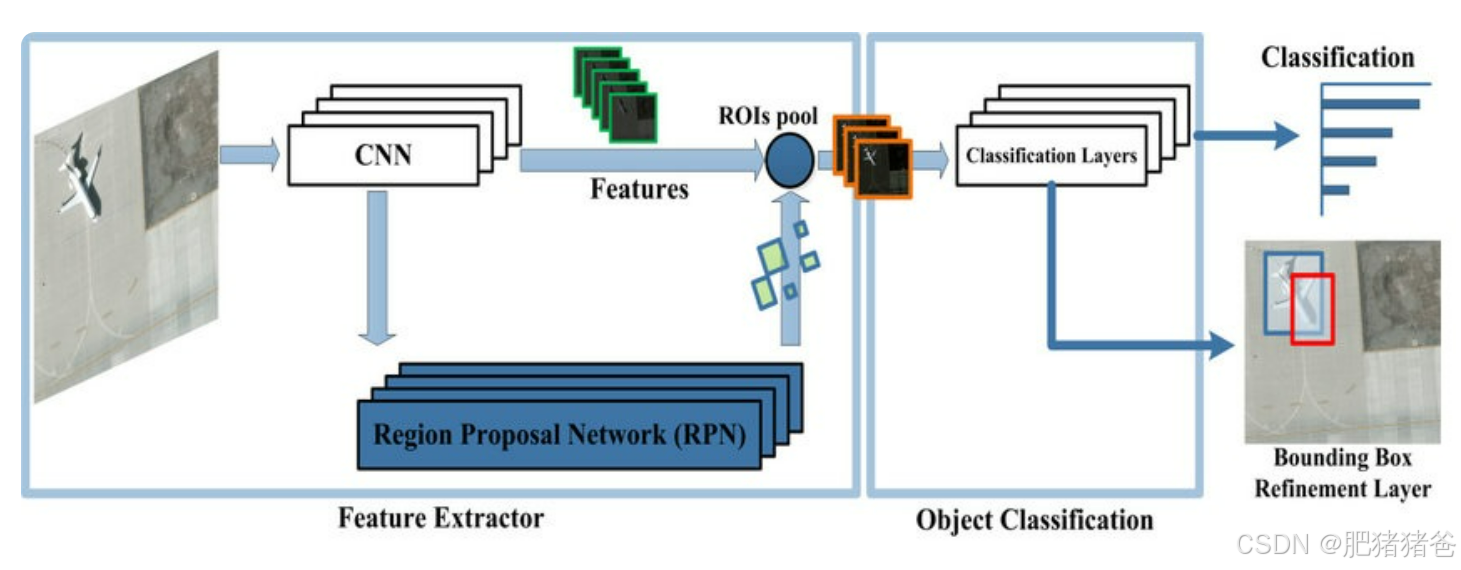
- Backbone:通常使用 ResNet 等卷积网络来提取图像特征。
- Neck:在 Faster R-CNN 中,可以使用 RPN(Region Proposal Network)来生成候选框并进行多尺度特征融合。
- Head:包括分类头(确定候选框属于哪个类别)和回归头(预测候选框的位置)。
5. 各组件常用算法总结
| 任务 | Backbone(主干网络) | Neck(脖部部分) | Head(头部部分) |
|---|---|---|---|
| 目标检测 | ResNet、VGG、Darknet 等 | FPN、RPN、PANet 等 | 分类头(预测类别)、回归头(预测边界框) |
| 语义分割 | VGG、ResNet、Xception 等 | ASPP、U-Net 中的跳跃连接等 | 1x1 卷积层(预测每个像素的类别) |
| 实例分割 | ResNet、VGG 等 | FPN | 检测头(分类、回归)、掩膜头(生成掩膜) |
这些算法的共同点是:Backbone 负责提取图像的特征,Neck 负责增强或融合特征(如通过多尺度处理),而 Head 则根据任务需求生成最终的输出结果(如类别、边界框或掩膜)。
6.总结
在目标检测和图像分割等任务中,网络的整体架构通常由 Backbone、Neck 和 Head 三个部分组成。这三个部分的分工明确,各自承担着不同的任务:
- Backbone 提供了从图像中提取特征的能力,主要负责图像的特征学习。
- Neck 对不同尺度的特征进行融合,以适应不同大小目标的检测或分割。
- Head 根据融合后的特征进行最终的预测输出,包括目标分类、边界框回归或像素级分类。
随着深度学习的不断发展,这些架构不断得到优化,新的方法如 FPN、PANet 和 BiFPN 等也不断涌现,使得目标检测和图像分割在精度和效率上都有了显著的提升。理解这些基本组成部分以及它们之间的关系,将帮助你更好地设计和优化深度学习图像处理模型。