一、区别
HiKariCP
1、字节码精简
减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一
2、优化代理和拦截器
3、定义集合类型
ConcurrentBag :提高并发读写的效率
Druid
1、Druid提供性能卓越的连接池功能外,还集成了SQL监控,黑名单拦截等功能,
2、强大的监控特性,通过Druid提供的监控功能,可以清楚知道连接池和SQL的工作情况。
3、监控SQL的执行时间、ResultSet持有时间、返回行数、更新行数、错误次数、错误堆栈信息;
4、Druid集合了开源和商业数据库连接池的优秀特性,并结合阿里巴巴大规模苛刻生产环境的使用经验进行优化。
汇总
线程池dbcp、druid、c3p0、jdbc、HikariCP对比汇总
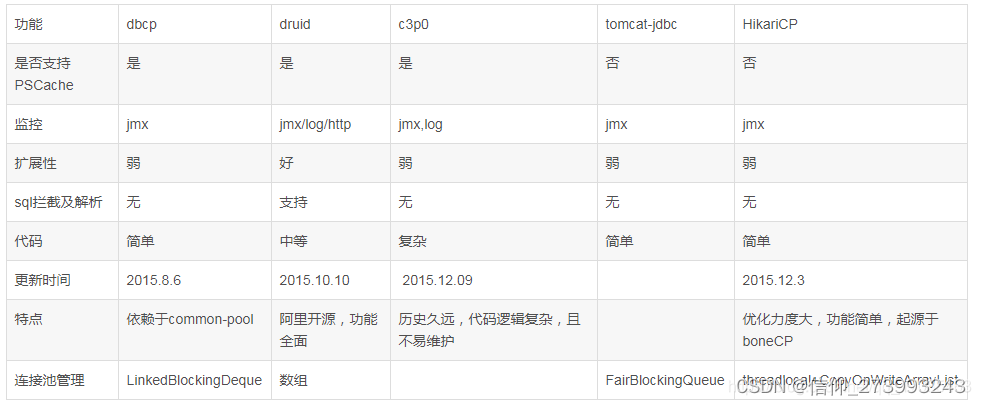
二、如何使用
SXDBC是众安自己封装的,但其实底层数据库连接池,也是用的HikariDataSource、DruidDataSource
下面介绍了,连接池的创建流程。先从加载DataSource开始
在关联Mybatis的时候,需要注册DataSource对象
@Bean
public DataSource dataSource() {
try {
return SxdbcDataSourceFactory.createDataSource(
this.dbName,
this.configCenterAddr,
this.configCenterType);
} catch (Exception e) {
throw new RuntimeException(e.getMessage());
}
}
构建SXDBCDataSource对象
public static DataSource createDataSource(final String logicDataSourceName, String configCenterAddr, String configCenterType) throws Exception {
//创建一个ConfigCenterClient对象,里面包含获取配置的Client,下面会介绍ConfigCenterClient对象
final ConfigCenterClient configCenterClient = ConfigCenterClient.init(configCenterAddr, configCenterType);
//通过上面得到的zk对象,获取指定路径下的内容转成ShardingConfig对象
ShardingConfig shardingConfig = getShardingConfig(configCenterClient, logicDataSourceName);
//通过ShardingConfig里面的DataSourceConfig属性值,来得到SXDBCDataSource,SXDBCDataSource继承了DataSource,
//如果我们不使用SXDBC使用mybatis原生的得到的也是DataSource对象,只不过SXDBC封装了一下DataSource
final SXDBCDataSource sxdbcDataSource = new SXDBCDataSource(logicDataSourceName, shardingConfig);
configCenterClient.registerMonitor(logicDataSourceName, new ConfigCenterListener() {
public void action() throws Exception {
ShardingConfig newShardingConfig = SxdbcDataSourceFactory.getShardingConfig(configCenterClient, logicDataSourceName);
sxdbcDataSource.updateDataSource(newShardingConfig);
}
});
//返回上面创建的DataSource
return sxdbcDataSource;
}
构建ZKClient对象
//ConfigCenterClient唯一实现类ZKClient对象
public class ZKClient extends ConfigCenterClient {
private static final String SXDBC_JDBC_PATH = "/sxdbc/jdbc";
private final CuratorFramework client;
public ZKClient(String connectString) {
this.client = CuratorFrameworkFactory.newClient(connectString, 60000, 15000, new RetryForever(10000));
this.client.start();
}
public String getDataSourceConfig(String logicDataSourceName) throws Exception {
String path = "/sxdbc/jdbc/" + logicDataSourceName;
return this.getData(path);
}
}
里面个很重要的属性
private final CuratorFramework client;
CuratorFramework是什么?
CuratorFramework是Netflix公司开发一款连接zookeeper服务的框架,提供了比较全面的功能,除了基础的节点的操作,节点的监听,还有集群的连接以及重试。
其实就是创建一个zk的对象,通过zk我们可以拿到这个zk下面有多少个路劲,并且拿到每个路径下面的数据
下面展示一下/sxdbc/jdbc/wx_lighthouse_00路径下的内容,里面包含mysql的连接地址,账号密码,连接池类型HikariCP,超时时间,最大最小连接数量。
{
"needDirectConnect": "Y",
"shardingRule": {
},
"dataSourcesConfig": {
"wx_lighthouse_00": {
"url": "jdbc:mysql://rxxxxm:3306/wx_lighthouse_00?autoReconnect=true&failOverReadOnly=false&characterEncoding=UTF-8",
"username": "root",
"password": "root",
"pool": "HikariCP",
"connectionTimeoutMilliseconds": 30000,
"idleTimeoutMilliseconds": 600000,
"maxLifetimeMilliseconds": 1800000,
"minPoolSize": 1,
"maxPoolSize": 50
}
}
}
回到上面的
ConfigCenterClient.init(configCenterAddr, configCenterType);
public static ConfigCenterClient init(String configCenterAddr, String configCenterType) {
return new ZKClient(configCenterAddr);//创建了一个ZKClient对象
}
//创建Zk连接对象
public ZKClient(String connectString) {
this.client = CuratorFrameworkFactory.newClient(connectString, 60000, 15000, new RetryForever(10000));
this.client.start();
}
上面得到zkClient连接对象,就可以从zk里面读出配置的内容,下面可以读取内容
回到getShardingConfig,下面通过configCenterClient对象从zk里面读取内容
getShardingConfig(configCenterClient, logicDataSourceName);
private static ShardingConfig getShardingConfig(ConfigCenterClient configCenterClient, String logicDataSourceName) throws Exception {
String shardingConfigStr = configCenterClient.getDataSourceConfig(logicDataSourceName);
return (ShardingConfig)JsonUtil.parseJsonToObject(shardingConfigStr, (new TypeToken<ShardingConfig>() {
}).getType());
}
public String getDataSourceConfig(String logicDataSourceName) throws Exception {
String path = "/sxdbc/jdbc/" + logicDataSourceName;
return this.getData(path);
}
代码中从节点logicDataSourceName得到数据,节点数据shardingConfigStr内容如下
"wx_lighthouse_00": {
"url": "jdbc:mysql://xxxxcs.com:3306/wx_lighthouse_00?autoReconnect=true&failOverReadOnly=false&characterEncoding=UTF-8",
"username": "root",
"password": "root",
"pool": "HikariCP",
"connectionTimeoutMilliseconds": 30000,
"idleTimeoutMilliseconds": 600000,
"maxLifetimeMilliseconds": 1800000,
"minPoolSize": 1,
"maxPoolSize": 50
}
上面配置就包含我们需要链接的数据,账号密码,以及连接池配置参数
再回到创建SXDBCDataSource对象
SXDBCDataSource sxdbcDataSource = new SXDBCDataSource(logicDataSourceName, shardingConfig);
看下SXDBCDataSource的构造方法
public class SXDBCDataSource implements DataSource {
public SXDBCDataSource(String logicDataSourceName, ShardingConfig shardingConfig) throws SQLException {
this.logicDataSourceName = logicDataSourceName;
this.loadConfig(shardingConfig);
this.initDataSource();
//这里很重要初始化DataSource的操作,我们使用原的mybatis创建DataSource的是怎么做的
}
}
使用原生的DataSource,我们大部分是这样做的,创建一个DruidDataSource对象,然后Spring会把这个Bean注入到容器中
@Bean(name = "dataSource")
public DruidDataSource dataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(dataSourceProperties.getUrl());//设置Url
dataSource.setDriverClassName(dataSourceProperties.getDriverClassName());//设置DriverName
dataSource.setUsername(dataSourceProperties.getUsername());//设置账号密码
dataSource.setPassword(dataSourceProperties.getPassword());
//没设置的属性,都是用的默认
return dataSource;
}
上面也是往DruidDataSource里面设置各种链接配置,所以我们也可以通过SXDBCDataSource猜到一个大概,里面也是创建一个DataSource对象,然后往里面设置数据库链接配置,只不过SXDBCDataSource继承了DataSource简单封装了一下而已,下面看下SXDBCDataSource怎么做的
回到SXDBCDataSource的构造方法,会有一个初始化DataSource方法
this.initDataSource();
initDataSource会执行的ConnectionPool.create方法
private void initDataSource() throws SQLException {
if (this.activeDataSource != null) {
this.expiredDataSources.put(this.activeDataSource, this.dataSourceToConnectionPool);
}
this.dataSourceToConnectionPool = (Map)this.shardingConfig.getDataSourcesConfig().entrySet().stream().collect(Collectors.toMap(Entry::getKey, (entry) -> {
return ConnectionPool.create((DataSourceConfig)entry.getValue());
}));
this.updateShardingDataSource();
}
看下create方法做了什么封装
public static ConnectionPool create(DataSourceConfig dataSourceConfig) {
switch(dataSourceConfig.getPool()) {
case HikariCP:
return new HikariConnectionPool(dataSourceConfig);
case DruidCP:
return new DruidConnectionPool(dataSourceConfig);//创建Druid类型的连接池,连接池就是用来存链接数据库的连接。
default:
throw new RuntimeException(String.format("DataSource Type [%s] is not supported!", dataSourceConfig.getPool()));
}
}
三、Druid
上面代码,假设类型是DruidCP类型,看下DruidConnectionPool,这是连接池对象
new DruidConnectionPool(dataSourceConfig);
//下面是ConnectionPool构造方法,最终会执行最下面的构造方法
public DruidConnectionPool(DataSourceConfig dataSourceConfig) {
super(dataSourceConfig);
}
//里面会执行createConnectionPool方法
public ConnectionPool(DataSourceConfig dataSourceConfig) {
this.dataSourceConfig = dataSourceConfig;
this.dataSource = this.createConnectionPool();
}
createConnectionPool会创建DruidDataSource对象,然后设置各种属性
public DataSource createConnectionPool() {
DataSourceConfig config = this.getDataSourceConfig();
//创建DruidDataSource对象,下面开始设置DruidDataSource的各个属性值
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setDriverClassName("com.mysql.jdbc.Driver");
druidDataSource.setUrl(config.getUrl());
druidDataSource.setUsername(config.getUsername());
druidDataSource.setPassword(config.getPassword());
druidDataSource.setMaxWait(config.getConnectionTimeoutMilliseconds());
druidDataSource.setMinEvictableIdleTimeMillis(config.getIdleTimeoutMilliseconds());
druidDataSource.setMaxEvictableIdleTimeMillis(config.getMaxLifetimeMilliseconds());
druidDataSource.setMaxActive(config.getMaxPoolSize());
druidDataSource.setMinIdle(config.getMinPoolSize());
return druidDataSource;
}
其实createConnectionPool这个代码和上面的使用原生的DruidDataSource来创建DataSource一样的,只是众安对其进行了一次封装
四、HikariConnectionPool
再看HikariConnectionPool创建的线程池之前,先看下在用Hikari线程池的时候,我们需要怎么去配置它的一些参数
1、配置
#DataSource类型,有Hikari和Druid两种,选用不同的创建的线程池也不一样
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
#最小空闲连接,默认值10,小于0或大于maximum-pool-size,都会重置为maximum-pool-size
spring.datasource.hikari.minimum-idle=5
#最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值
spring.datasource.hikari.maximum-pool-size=15
#自动提交从池中返回的连接,默认值为true
spring.datasource.hikari.auto-commit=true
#空闲连接超时时间,默认值600000(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;不等于0且小于10秒,会被重置为10秒。
#只有空闲连接数大于最大连接数且空闲时间超过该值,才会被释放
spring.datasource.hikari.idle-timeout=30000
#连接池名称,默认HikariPool-1
spring.datasource.hikari.pool-name=Hikari
#连接最大存活时间.不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短;单位ms
spring.datasource.hikari.max-lifetime=55000
#连接超时时间:毫秒,小于250毫秒,会被重置为默认值30秒
spring.datasource.hikari.connection-timeout=30000
#连接测试查询
spring.datasource.hikari.connection-test-query=SELECT 1
2、下面是代码介绍
new HikariConnectionPool(dataSourceConfig)
创建HikariPool对象,里面涉及到的内容比较多,主要由4个对象
1、connectionBag:线程池容器
2、addConnectionQueue:连接队列
3、addConnectionExecutor:新建db连接的线程池
4、closeConnectionExecutor:关闭db连接的线程池
5、houseKeeperTask:维持连接池中连接数量为固定的minimumIdle大小
疑问:上面5个对象之间的关系是什么,带着疑问先看下HikariPool的构造方法
HikariPool构造函数
public HikariPool(final HikariConfig config){
super(config);
//1.构建线程池容器ConcurrentBag
this.connectionBag = new ConcurrentBag<>(this);
//2、设置锁SuspendResumeLock底层就是独占锁
this.suspendResumeLock = config.isAllowPoolSuspension() ? new SuspendResumeLock() : SuspendResumeLock.FAUX_LOCK;
this.houseKeepingExecutorService = initializeHouseKeepingExecutorService();
// 3、创建连接,校验有效性 快速失败
checkFailFast();
if (config.getMetricsTrackerFactory() != null) {
setMetricsTrackerFactory(config.getMetricsTrackerFactory());
}
else {
setMetricRegistry(config.getMetricRegistry());
}
setHealthCheckRegistry(config.getHealthCheckRegistry());
handleMBeans(this, true);
ThreadFactory threadFactory = config.getThreadFactory();
final int maxPoolSize = config.getMaximumPoolSize();
//创建连接队列blockQueue,上限为maxPoolSize
LinkedBlockingQueue<Runnable> addConnectionQueue = new LinkedBlockingQueue<>(maxPoolSize);
//该对象,可以获取当前有几个db连接等待创建,避免提交过多新建任务导致超过max
this.addConnectionQueueReadOnlyView = unmodifiableCollection(addConnectionQueue);
//创建线程池,该线程池里面的线程负责新建db连接,1个核心线程,队列上面创建线程队列addConnectionQueue,createThreadPoolExecutor下面有代码说明
this.addConnectionExecutor =
createThreadPoolExecutor(addConnectionQueue, "线程名", threadFactory, new ThreadPoolExecutor.DiscardOldestPolicy());
//创建线程池,里面的线程负责关闭db连接,1个核心线程、队列上限maxPoolSize,拒绝策略设置:由调用线程处理该任务
this.closeConnectionExecutor = createThreadPoolExecutor(maxPoolSize, "线程名", threadFactory, new ThreadPoolExecutor.CallerRunsPolicy());
//连接泄露检测(leakDetectionThreshold默认为0,不开启),db连接从连接池中取出后开始计时,如果超过一定的时长还未归还则认为可能发现连接泄露或者慢查询了
this.leakTaskFactory = new ProxyLeakTaskFactory(config.getLeakDetectionThreshold(), houseKeepingExecutorService);
//定时任务,主要定时检查连接池内连接数,维持到minimumIdle的数量,主要由HouseKeeper完成这个任务,下面有介绍HouseKeeper代码
this.houseKeeperTask = houseKeepingExecutorService.scheduleWithFixedDelay(new HouseKeeper(), 100L, housekeepingPeriodMs, MILLISECONDS);
//com.zaxxer.hikari.blockUntilFilled表示:启动时等待创建完成设置的最小连接数,getInitializationFailTimeout表示:初始化失败超时时间
if (Boolean.getBoolean("com.zaxxer.hikari.blockUntilFilled") && config.getInitializationFailTimeout() > 1) {
//addConnectionExecutor是负责新建db连接的线程池,修改核心线程数值是随机的
addConnectionExecutor.setCorePoolSize(Math.min(16, Runtime.getRuntime().availableProcessors()));
//addConnectionExecutor负责新建db连接的线程池,修改最大线程数值是随机的
addConnectionExecutor.setMaximumPoolSize(Math.min(16, Runtime.getRuntime().availableProcessors()));
//上面2行代码,就是为了在初始化的时候,多创建一些线程,后面会被核心线程数和最大线程池改为正常值
........
addConnectionExecutor.setCorePoolSize(1);
addConnectionExecutor.setMaximumPoolSize(1);
}
}
注意:houseKeepingExecutorService也是一个线程池,他的scheduleWithFixedDelay方法是指定间隔多长时间执行一次任务。默认时30秒
看下上面createThreadPoolExecutor这个方法
public static ThreadPoolExecutor createThreadPoolExecutor(
final BlockingQueue<Runnable> queue,
final String threadName,
ThreadFactory threadFactory,
final RejectedExecutionHandler policy){
if (threadFactory == null) {
threadFactory = new DefaultThreadFactory(threadName, true);
}
//里面会创建JDK的线程池ThreadPoolExecutor
ThreadPoolExecutor executor = new ThreadPoolExecutor(1 /*core*/, 1 /*max*/, 5 /*keepalive*/, SECONDS, queue, threadFactory, policy);
executor.allowCoreThreadTimeOut(true);//当超过keepalive时间后,核心线程也会被回收
return executor;
}
关于ThreadPoolExecutor介绍请看我的另一篇文章跳转
houseKeeperTask
再看下houseKeeperTask是怎么得到的
this.houseKeeperTask =
houseKeepingExecutorService.scheduleWithFixedDelay(new HouseKeeper(), 100L, housekeepingPeriodMs, MILLISECONDS);
里面会创建HouseKeeper对象,而HouseKeeper#run()的目的就是维持连接池的连接数量稳定在minimumIdle个,超过minimumIdle就收回,不够就补充线程
@Override
public void run(){
.....
// 第一块
if (idleTimeout > 0L && config.getMinimumIdle() < config.getMaximumPoolSize()) {//最大线程和最小线程不相等
final List<PoolEntry> notInUse = connectionBag.values(STATE_NOT_IN_USE);//找出空闲的连接集合
int toRemove = notInUse.size() - config.getMinimumIdle();//需要清理的数量
//通过自旋的方式,移除超出的线程,这个自选好像会有线程安全问题
for (PoolEntry entry : notInUse) {
if (toRemove > 0 && elapsedMillis(entry.lastAccessed, now) > idleTimeout && connectionBag.reserve(entry)) {//判断空闲时间是否超过idleTimeout
closeConnection(entry, "(connection has passed idleTimeout)");
toRemove--;
}
}
}
.......
// 第二块
fillPool();
}
上面代码分为2块
第一块:池内空闲的连接, 超过 minimumIdle 的那部分,如果空闲超过 idleTimeout 则清除掉。
第二块:调用fillPool() 空闲db连接数补足到 minimumIdle 个
//从sharedList里面找出状态是0的对象,0表示连接是空闲状态。然后翻转集合
private final CopyOnWriteArrayList<T> sharedList;
public List<T> values(final int state){
final List<T> list = sharedList.stream().filter(e -> e.getState() == state).collect(Collectors.toList());
Collections.reverse(list);
return list;
}
//fillPool方法主要是当数量不够idleTimeout,则创建新的连接放入线程池
private synchronized void fillPool(){
final int connectionsToAdd =
Math.min(config.getMaximumPoolSize() - getTotalConnections(), config.getMinimumIdle() - getIdleConnections())- addConnectionQueueReadOnlyView.size();
for (int i = 0; i < connectionsToAdd; i++) {
//提交给连接创建的线程池addConnectionExecutor新建连接
addConnectionExecutor.submit((i < connectionsToAdd - 1) ? poolEntryCreator : postFillPoolEntryCreator);
}
}