文章目录
前言
前面已经构建了大语言模型代码,本篇文章在此基础上探索不同模块功能,包含数据划分加工处理、评估方法、resume训练、torchrun训练、wandb使用方法以及deepspeed训练方法。
一、基于代码解读数据划分与模型变换
假如我们想划分验证集,huggingface已有方式可以调用。我将直接给出代码,至于详细可参考我的huggingface教程专栏。
1、参数添加
我们使用test_size参数划分我们读取数据比列,如下:
@dataclass
class DataTrainingArguments:
test_size: Optional[Union[float,str]] = field( default=None, metadata={"help": "split dataset to use eval."} )
2、验证集划分方法
直接使用train_test_split函数即可实现划分,其代码如下:
# 构造测试数据集
train_dataset ,test_dataset = None, None
if data_args.test_size and training_args.do_eval:
split_dataset = processed_dataset['train'].train_test_split(test_size=data_args.test_size)
train_dataset ,test_dataset = split_dataset['train'],split_dataset['test']
else:
train_dataset = processed_dataset['train']
3、Trainer初始化参数改动
很简单,就是给一个eval_dataset = test_dataset if training_args.do_eval else None,参数添加是否有验证集,无为None,否则就是上面给的验证集。
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset ,
eval_dataset = test_dataset if training_args.do_eval else None, # 如果允许才会进行评估
tokenizer=tokenizer,
data_collator=data_collator,
)
二、基于代码添加评估方法模块
1、训练评估与保存
train_result = trainer.train() # 模型训练
# 添加训练评估
metrics = train_result.metrics
metrics["train_samples"] = len(train_dataset)
trainer.log_metrics("train", metrics) # 保存
trainer.save_metrics("train", metrics)
trainer.save_state() # 保存转态
2、验证评估与保存
判断如果具备验证集,那么就添加此模块,和train很像。
# Evaluation
if training_args.do_eval and data_args.test_size:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
metrics["eval_samples"] =len(test_dataset)
try:
perplexity = math.exp(metrics["eval_loss"])
except OverflowError:
perplexity = float("inf")
metrics["perplexity"] = perplexity
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
三、基于代码添加resume方法
很简单,直接resume_from_checkpoint=True即可实现,但必须有保存权重等内容才可以,否则会报错的。
# train_result = trainer.train()
train_result = trainer.train(resume_from_checkpoint=True)
四、基于代码使用torchrun模式训练
只需更改原来launch json模块内容,如下:
{
"name": "train",
"type": "python",
"request": "launch",
"program": "/home/miniconda3/envs/llama3/bin/torchrun",
"console": "integratedTerminal",
"justMyCode": false,
"args": [
"/language_model/Chinese-LLaMA-Alpaca-3-main/llama3_model/main.py",
...
],
"env": {
"CUDA_VISIBLE_DEVICES": "0"
},
}
因其比较简单,我不在解读了,我已试过,可以实现训练。而gpu设定使用CUDA_VISIBLE_DEVICES此方法。
五、基于代码使用wandb训练
huggingface已经集成了wandb方法,可在huggingface初始化Trainer的trainging_args中添加,举例如下:
from transformers import TrainingArguments
training_args = TrainingArgs(
output_dir='./results', # 输出目录
num_train_epochs=3, # 训练轮数
per_device_train_batch_size=16, # 每个GPU/CPU的训练批次大小
per_device_eval_batch_size=64, # 每个GPU/CPU的评估批次大小
warmup_steps=500, # 预热步数
weight_decay=0.01, # 权重衰减
logging_dir='./logs', # 日志目录
logging_steps=10, # 日志记录频率
load_best_model_at_end=True, # 是否在结束时加载最佳模型
metric_for_best_model='accuracy', # 用于选择最佳模型的指标
evaluation_strategy='epoch', # 评估策略
report_to='wandb', # 报告到 W&B
run_name='your_run_name' # W&B 运行名称
)
如果使用sh或launch.json给参数,可直接给--report_to设置为wandb,举例如果是launch.json设置如下:
"args": [
"/language_model/Chinese-LLaMA-Alpaca-3-main/llama3_model/main.py",
"--report_to","wandb",
...
]
如此设置是因模型一般都继承TrainingArgs类,该类有此参数。
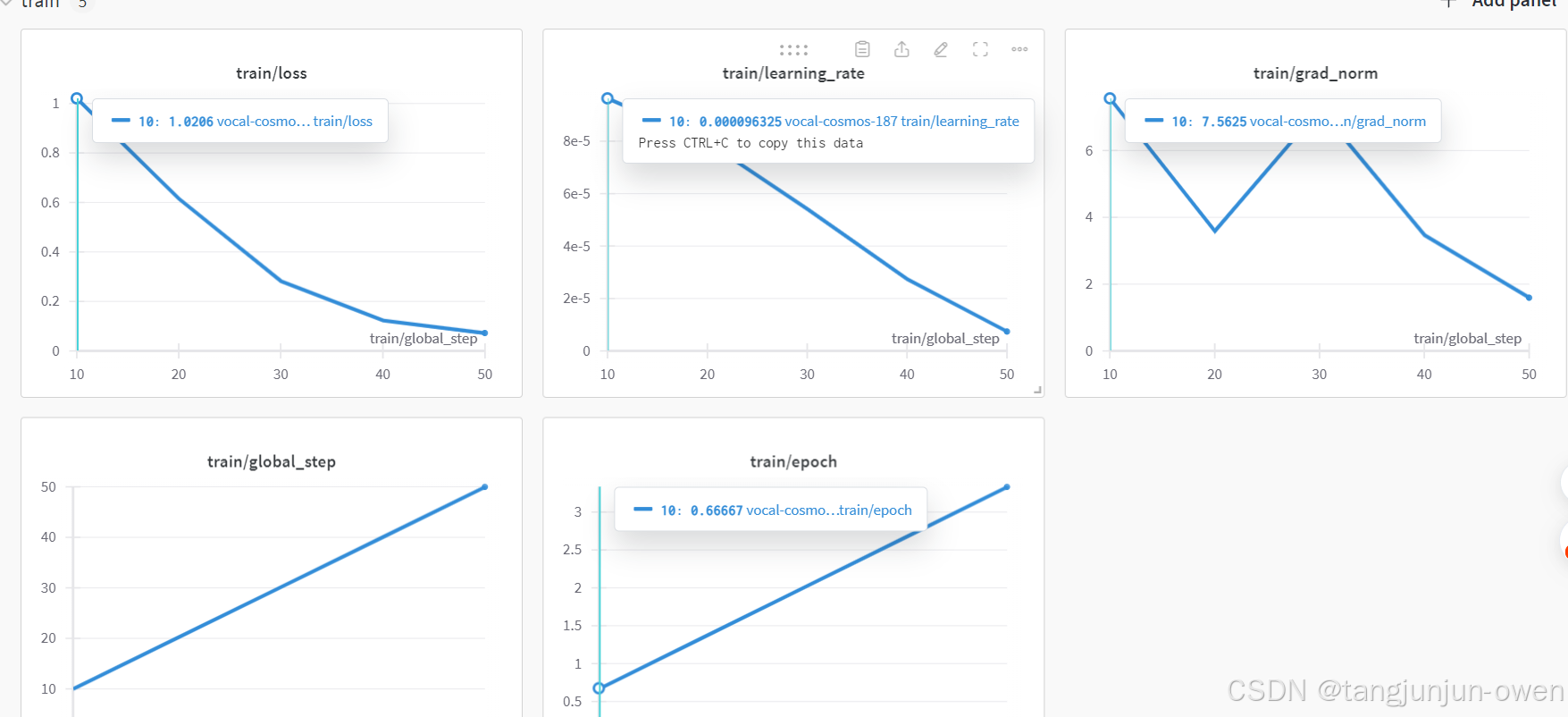
最终,运行结果如下图显示:
六、基于代码使用deepspeed训练
参考deepspeed官网链接:点击这里
1、deepspeed理解
首先要明白训练模型时显存主要用在如下四个地方:1、模型参数 2、梯度 3、优化器 4、激活值
Zero-0:不使用所有类型的分片,仅使用DeepSpeed作为DDP,速度最快(显存够时使用)
Zero-1:切分优化器状态,分片到每个数据并行的工作进程(每个GPU)下;有微小的速度提升。
Zero-2:切分优化器状态 + 梯度,分片到每个数据并行的工作进程(每个GPU)下
Zero-3:切分优化器状态 + 梯度 + 模型参数,分片到每个数据并行的工作进程(每个GPU)下
2、zero配置文件
我们主要讨论zero2与zero3的使用方法。因此,我们后续解读介绍zero2与zeor3相关内容。
1、zero2配置文件与解读
直接给出zero2配置文件内容,其对应参数zero2的文件解释如下:
{
"zero_optimization": {
"stage": 2, // 指定了优化级别。在这里,`stage 2` 表示优化器状态会在不同的节点之间进行分区,从而减少内存占用。
"offload_optimizer": { // 这一部分配置了当优化器状态不需要驻留在 GPU 上时应该存储的位置
"device": "cpu", // 存储优化器状态的设备。这里设置为 "cpu",意味着优化器状态将被存储在 CPU 内存中。
"pin_memory": true // 如果设置为 true,则优化器状态将在 CPU 内存中固定,可以加快 CPU 和 GPU 之间的数据传输速度。
},
"allgather_partitions": true, // 设置为 true 时,确保在更新步骤之前收集所有优化器状态的分区。
"allgather_bucket_size": 5e8, // 执行 all-gather 操作时使用的数据块大小。这里的值 5e8 表示数据将以每块 5 千万元素的方式进行聚集。
"overlap_comm": true, //如果设置为 true,则允许通信和计算重叠,以提高效率。
"reduce_scatter": true, // 当设置为 true 时,启用 reduce-scatter 操作来跨节点分配梯度。
"reduce_bucket_size": 5e8, // 执行 reduce 操作时使用的数据块大小。这里的值 5e8 表示梯度将以每块 5 千万元素的方式进行聚合。
"contiguous_gradients": true, //当设置为 true 时,确保梯度在内存中是连续的,这可以提高性能。
"round_robin_gradients": true //如果设置为 true,则梯度将在各节点间以轮询方式分布。
},
"bf16": { //这一部分配置了使用 bfloat16(BF16)浮点格式,这是一种半精度浮点格式,通常用于训练神经网络,因为它在精度和内存效率之间取得了良好的平衡。
"enabled": "auto" //设置为 "auto",这意味着系统会根据硬件能力和所训练模型自动决定是否使用 BF16 格式。
},
"optimizer": { // 优化器
"type": "AdamW", //指定了优化器类型。这里选择了 "AdamW",这是一种 Adam 的变体,它可以将权重衰减与学习率分开处理。
"params": {
"lr": "auto", // 学习率。设置为 "auto" 意味着学习率将根据情况自动确定,可能是通过学习率调度器或预定义的值。
"betas": "auto", //指数衰减率用于估计动量。设置为 "auto" 意味着这些值将自动设定。
"eps": "auto", //为了防止除零而添加到分母的一个小常数。设置为 "auto" 意味着这个值将自动设定。
"weight_decay": "auto" // 权重衰减系数。设置为 "auto" 意味着这个值将自动设定。
}
},
"scheduler": { // 这一部分配置了学习率调度器。
"type": "WarmupLR", //指定了调度器类型。这里选择了 "WarmupLR",这种调度器通常在训练开始时逐渐增加学习率。
"params": {
"warmup_min_lr": "auto", // 温暖期期间的最小学习率。设置为 "auto" 意味着这个值将自动设定。
"warmup_max_lr": "auto", // 温暖期期间的最大学习率。设置为 "auto" 意味着这个值将自动设定。
"warmup_num_steps": "auto" // 学习率逐渐增加的时间步数。设置为 "auto" 意味着这个值将自动设定。
}
},
"gradient_accumulation_steps": "auto", // 在执行一次优化器更新前累积梯度的步数。设置为 "auto" 意味着这个值将自动设定。
"gradient_clipping": "auto", //梯度的最大范数。设置为 "auto" 意味着这个值将自动设定。
"steps_per_print": 20, // 训练进度的打印频率。这里设置为每 20 步输出一次训练进度。
"train_batch_size": "auto", // 训练时使用的总批次大小。设置为 "auto" 意味着这个值将自动设定。
"train_micro_batch_size_per_gpu": "auto", // 每个 GPU 上的微批次大小。设置为 "auto" 意味着这个值将自动设定。
"wall_clock_breakdown": false // 当设置为 false 时,不会记录训练过程中各个组件的时间详细信息。
}
2、zero3配置文件与解读
直接给出zero3配置文件内容,其对应参数zero3的文件解释如下:
{
# 配置bfloat16(bf16)精度
"bf16": {
"enabled": "auto" # 自动判断是否启用bf16精度,基于硬件情况。bf16是一种半精度浮点格式,可以显著减少内存使用和加速训练过程。
},
# 优化器配置
"optimizer": {
"type": "AdamW", # 优化器类型:AdamW,这是Adam的一种变体,它将权重衰减正则化分离,有助于避免过拟合。
"params": {
"lr": "auto", # 学习率,自动确定。学习率是训练过程中模型权重更新的速度。
"betas": "auto", # 指数衰减率用于估计第一和第二矩,自动确定。第一矩是梯度的平均值,第二矩是梯度平方的平均值。
"eps": "auto", # 分母中添加的小数值以提高数值稳定性,自动确定。在Adam算法中,这个小数值用来防止除以零的情况。
"weight_decay": "auto" # 权重衰减系数,自动确定。权重衰减用于正则化模型,防止过拟合。
}
},
# 学习率调度器配置
"scheduler": {
"type": "WarmupLR", # 调度器类型:WarmupLR,这是一种逐渐从较小值增加学习率的方式,通常用于初始阶段。
"params": {
"warmup_min_lr": "auto", # 温暖期(warmup)期间的最小学习率,自动确定。通常开始的学习率会很小。
"warmup_max_lr": "auto", # 温暖期期间的最大学习率,自动确定。这是温暖期结束时的学习率。
"warmup_num_steps": "auto" # 温暖期的步数,自动确定。这是温暖期持续的时间长度。
}
},
# Zero Redundancy Optimizer (ZeRO) 阶段3配置
"zero_optimization": {
"stage": 3, # ZeRO优化阶段(1、2或3)。阶段越高,对内存使用的优化越强,但可能会影响性能。
"offload_optimizer": { # 将优化器状态卸载到CPU或磁盘的配置
"device": "cpu", # 卸载优化器状态的目标设备(CPU或磁盘)。对于阶段3,优化器状态必须卸载到非GPU设备上。
"pin_memory": True # 如果为True,则使用固定内存以便更快地传输数据到GPU。固定内存有助于加速数据传输。
},
"offload_param": { # 将参数卸载到CPU或磁盘的配置
"device": "cpu", # 卸载参数的目标设备(CPU或磁盘)。对于阶段3,参数必须卸载到非GPU设备上。
"pin_memory": True # 如果为True,则使用固定内存以便更快地传输数据到GPU。固定内存有助于加速数据传输。
},
"overlap_comm": True, # 如果为True,则使通信与计算重叠,这样可以在等待通信的同时进行计算,提高并行性。
"contiguous_gradients": True, # 如果为True,则梯度在内存中连续存储以提高缓存效率。连续存储有助于提高缓存命中率。
"sub_group_size": 1e9, # 梯度通信的子组大小,设置为非常大的值以有效地禁用子分组。子分组可以进一步减少通信开销。
"reduce_bucket_size": "auto", # 所有reduce操作的桶大小,自动确定。桶大小控制了所有reduce操作的粒度。
"stage3_prefetch_bucket_size": "auto", # 阶段3中的预取桶大小,自动确定。预取可以减少等待时间,提高性能。
"stage3_param_persistence_threshold": "auto", # 阶段3中持久化参数存储的阈值,自动确定。该阈值控制哪些参数需要持久化存储。
"stage3_max_live_parameters": 1e9, # 最大活动参数数量,设置为非常大的值以有效地禁用限制。活动参数是指在GPU内存中的参数。
"stage3_max_reuse_distance": 1e9, # 最大参数重用距离,设置为非常大的值以有效地禁用限制。参数重用可以帮助减少内存消耗。
"stage3_gather_16bit_weights_on_model_save": True # 如果为True,在保存模型时将以16位格式聚集权重。这对于存储和恢复模型时节省空间很有帮助。
},
# 梯度累积步数
"gradient_accumulation_steps": "auto", # 积累梯度的步数,在执行更新之前,自动确定。梯度累积可以减少通信次数。
# 梯度裁剪
"gradient_clipping": "auto", # 梯度裁剪阈值,自动确定。梯度裁剪有助于防止梯度爆炸问题。
# 打印训练状态的步数
"steps_per_print": 20, # 每N步打印一次训练状态。这有助于监控训练过程。
# 训练批次大小
"train_batch_size": "auto", # 所有GPU上的总训练批次大小,自动确定。批次大小对训练速度和模型性能有很大影响。
# 每个GPU的训练微批次大小
"train_micro_batch_size_per_gpu": "auto", # 每个GPU上的微批次大小,自动确定。微批次大小是每个GPU上处理的数据量。
# 墙钟时间细分
"wall_clock_breakdown": False # 如果为True,则打印详细的定时信息。这有助于调试和性能分析。
}
当然,猛然发现有一个配置是fp16,fp16`配置段落是与混合精度训练相关的设置。混合精度训练是一种技术,它使用半精度浮点数(通常是FP16)来加速计算并减少内存使用,同时在关键操作中使用单精度(通常是FP32)以保持数值稳定性。
"fp16": {
"enabled": "auto", //设置为"auto"意味着DeepSpeed将根据环境自动决定是否启用FP16训练。如果设置为true,则强制启用FP16,如果是false,则禁用FP16。
"loss_scale": 0, //这个值用于缩放梯度以避免梯度下溢(underflow)或上溢(overflow)。0表示动态损失缩放。
"loss_scale_window": 1000, //这是用于计算动态损失缩放值的样本窗口大小。在此窗口内,系统会根据梯度的行为调整损失缩放因子。
"initial_scale_power": 16, //动态损失缩放的初始值是2的此幂次方。例如,如果设置为16,则初始损失缩放值为2^16。
"hysteresis": 2, //当系统检测到梯度上溢后,它会降低损失缩放值,并且在接下来的几次迭代中即使没有检测到梯度上溢也不会再增加损失缩放值。这个数字定义了这种延迟的长度。
"min_loss_scale": 1 //这是指定的最小损失缩放值。即使系统继续降低损失缩放值,它也不会低于这个阈值。
},
这些参数对于控制在使用FP16训练期间的数值稳定性和性能非常重要。Zero3(ZeRO-Offload stage 3)是一个更高级的功能,它提供了模型并行性以及数据并行性下的内存优化,但它不是直接通过上述fp16参数来配置的。ZeRO-Offload的配置通常会在DeepSpeed的其他部分指定,如zero_optimization部分。如果您想了解有关Zero3的具体配置,请提供相关部分的配置信息,以便我能给出更准确的解释。
3、zero2与zero3的区别
这两个配置文件描述了使用 ZeRO (Zero Redundancy Optimizer) 技术的不同阶段(Stage 2 和 Stage 3)来进行分布式深度学习训练时的设置。ZeRO 是一种旨在减少内存使用并提高大规模模型训练效率的技术。
1. zero2与zero3差异
共同点:zero2与zero3均有特征
①、优化器状态在不同的节点之间进行分区。
②、优化器状态存储在 CPU 内存中,并且固定在内存中以加快 CPU 和 GPU 之间的数据传输速度。
③、执行 all-gather 操作来收集所有优化器状态的分区。
④、使用 reduce-scatter 操作来跨节点分配梯度。
差异点:zero3新增特征内容
①、增加了参数的卸载,即模型参数本身也会被卸载到非 GPU 设备上。
②、参数和优化器状态都卸载到 CPU 或磁盘上。
③、提供了更高级别的配置选项,例如 sub_group_size 和 stage3_max_live_parameters,这些选项可以进一步优化内存使用和通信开销。
2. zero中的auto配置配置说明
两个配置文件中的许多参数都被设置为 “auto”,这意味着它们将根据运行时环境自动调整。但是,Stage 3 文件中出现了一些额外的自动配置参数,如 stage3_prefetch_bucket_size 和 stage3_param_persistence_threshold,这些在 Stage 2 中是没有的。
3. zero3特有配置参数
offload_param: 专门用于控制模型参数的卸载。
sub_group_size: 控制梯度通信的子组大小。
stage3_prefetch_bucket_size: 控制阶段3中的预取桶大小。
stage3_param_persistence_threshold: 控制哪些参数需要持久化存储。
stage3_max_live_parameters: 最大活动参数数量。
stage3_max_reuse_distance: 最大参数重用距离。
stage3_gather_16bit_weights_on_model_save: 在保存模型时聚集权重。
4. zero2与zero3内存管理
zero2主要关注优化器状态的卸载,通过固定内存 (pin_memory) 加快 CPU 和 GPU 之间的数据传输。而zero3不仅卸载优化器状态,而且还卸载模型参数。
5、小结
zero2 主要关注于通过分区优化器状态来减少内存使用,并且将这些状态卸载到 CPU 内存中,而zero3 在zero2的基础上进一步扩展,通过卸载模型参数到 CPU 或磁盘来进一步减少 GPU 内存占用,并提供了更多的配置选项来优化内存使用和通信效率。
总的来说,随着zero 阶段的提高,对内存使用的优化更加深入,但也可能会引入更多的复杂性和潜在的性能影响。选择适当的阶段取决于具体的应用场景、硬件配置以及对内存和性能的要求。
3、deepspeed使用细节
1、单机单卡与单机多卡
单节点情况下,即单机单卡或者单机多卡,CUDA_VISIBLE_DEVICES 不能与DeepSpeed一起使用来控制应该使用哪些设备。正确的方式如下,在localhost后选择用来训练的GPU:
deepspeed --include localhost:1
2、deepspeed与huggingface使用zero参数优先级
默认优先级:huggingface—>deepspeed。
说白了,deepspeed已被集成huggingface中,自然huggingface的Trainer的TrainingArguments参数也可以被deepspeed获得。如果deepspeed和Trainer两边都配置了,会默认优先使用deepspeed的参数。简单讲就是模型训练时会首先看ds config中有没有相关配置,有的话就直接使用,没有的话就使用HF(Trainer)中的配置。 所以如果两边都配置了的话HF中的相关参数就失效了。
4、deepspeed训练命令
huggingface已经集成了deepspeed方法,可在huggingface初始化Trainer的trainging_args中添加,我们只需给出zero文件即可实现。
1、deepspeed的sh脚本训练
1、deepspeed的sh脚本训练
deepspeed --include localhost:0,1 train.py\
--deepspeed "./zero2.json" \
....
我也给出也给一个github上的列子,参考内容:https://github.com/mst272/LLM-Dojo/blob/main/run_example.sh
2、完整大模型deepspeed的sh脚本训练
DATA_PATH=''
OUTPUT_PATH=""
MODEL_PATH=""
# deepspeed 启动
deepspeed --include localhost:0,1 main_train.py\
--train_args_path "sft_args" \
--train_data_path "$DATA_PATH" \
--model_name_or_path "$MODEL_PATH" \
--max_len 1024 \
--num_train_epochs 1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--task_type "sft" \
--train_mode "qlora" \
--output_dir "$OUTPUT_PATH" \
--save_strategy "steps" \
--save_steps 500 \
--save_total_limit 5 \
--learning_rate 2e-4 \
--warmup_steps 10 \
--logging_steps 1 \
--lr_scheduler_type "cosine_with_min_lr" \
--gradient_checkpointing True \
--report_to "wandb" \
--deepspeed './train_args/deepspeed_config/ds_config_zero2.json' \
--bf16 True
# task_type:[pretrain, sft, dpo_multi, dpo_single]
# train_mode:[qlora, lora, full]
# train_args_path: [sft_args,dpo_args]
# python main_train.py --train_data_path 数据集路径 --model_name_or_path 模型路径 ......同上述传入参数
2、deepspeed的vscode框架训练方法
这里,我给出了deepspeed的zero2使用方法,而zero2配置文件在上面也给出。
{
"name": "main",
"type": "python",
"request": "launch",
"program": "/home/miniconda3/envs/llama3/bin/deepspeed",
"console": "integratedTerminal",
"justMyCode": false,
"args": [
"--include", "localhost:0",
"llama3_model/train.py",
"--deepspeed","/language_model/Chinese-LLaMA-Alpaca-3-main/llama3_model/deepspeed_config/ds_config_zero2.json",
...
]
}
3、zero3训练探索
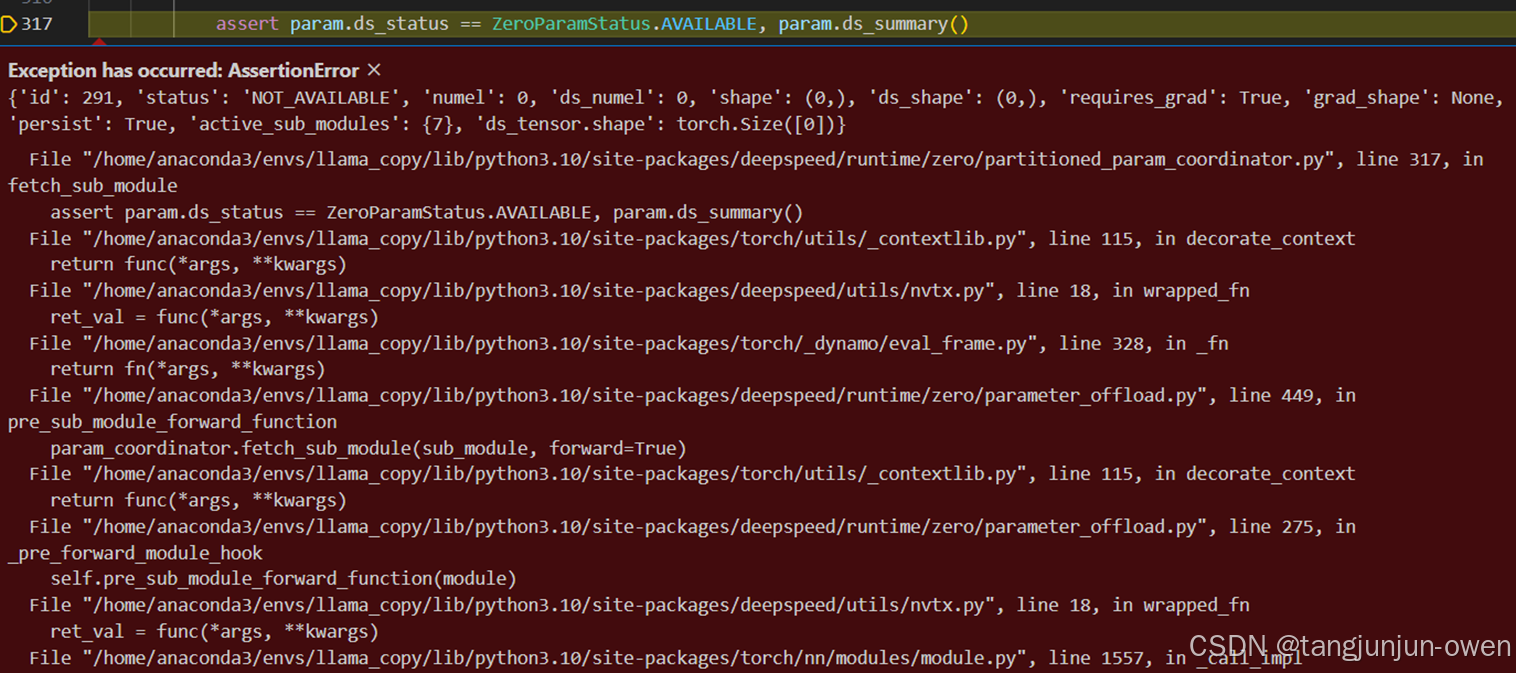
紧接着,十分愉悦进入zero3方式训练大模型,但我始终如何配置环境都出现以下报错,
也看到一些博主说,zero3训练很慢,一个6h跑完代码使用zero3跑了2天2夜也未跑完,于是我也暂时放弃这个方法。但我个人觉得zero3配置是没啥问题的,具体应该是版本匹配问题。
强化学习解读:https://www.zhihu.com/question/603107633/answer/3562965032
dpo训练
原始数据:
{"chosen":
[{"content":"嗨,我想学玩掷马蹄铁游戏。你能教我吗?","role":"user"},{"content":"我可以教你,但也许我应该先告诉你,一局典型的掷马蹄铁游戏通常由2名玩家参与,并使用6到8个马蹄铁.","role":"assistant"},{"content":"好的。还需要什么来玩这个游戏,规则是什么?","role":"user"},{"content":"一个马蹄铁通常是金属制成的,长度大约在3到3.5英寸之间,厚度约为1英寸。马蹄铁底部还应该有一个2英寸乘3英寸的平面,这是橡胶与金属接触的地方。我们还需要两根桩子和六个马蹄铁.","role":"assistant"}],
"rejected":[{"content":"嗨,我想学玩掷马蹄铁游戏。你能教我吗?","role":"user"},{"content":"我可以教你,但也许我应该先告诉你,一局典型的掷马蹄铁游戏通常由2名玩家参与,并使用6到8个马蹄铁.","role":"assistant"},{"content":"好的。还需要什么来玩这个游戏,规则是什么?","role":"user"},{"content":"马蹄铁是金属或塑料制成的圆盘。马蹄铁有不同的重量,较轻的更容易投掷,因此它们通常是初学者的标准选择.","role":"assistant"}],
"prompt":"嗨,我想学玩掷马蹄铁游戏。你能教我吗?"}
数据解释:
在大语言模型的DPO(Direct Preference Optimization)训练中,chosen、rejected 和 prompt 是用来构建偏好学习任务的基本元素。下面以您提供的示例为基础来进行解释:
Prompt (提示)
定义: Prompt 是用户给定的一段文本或者对话历史,用于引导模型生成相应的回复。
示例: "嗨,我想学玩掷马蹄铁游戏。你能教我吗?"
作用: Prompt 在这里的作用是提供了一个对话场景,告诉模型接下来需要讨论的内容。
Chosen (被选中的回复)
定义: Chosen 是一组回复中被认为更优的那个选项。在训练过程中,模型会学习这些更优的回复模式。
示例:
"我可以教你,但也许我应该先告诉你,一局典型的掷马蹄铁游戏通常由2名玩家参与,并使用6到8个马蹄铁。"
"一个马蹄铁通常是金属制成的,长度大约在3到3.5英寸之间,厚度约为1英寸。马蹄铁底部还应该有一个2英寸乘3英寸的平面,这是橡胶与金属接触的地方。我们还需要两根桩子和六个马蹄铁。"
作用: 这些被选中的回复提供了正确的信息和指导,帮助模型学习如何更好地回答类似的问题。
Rejected (被拒绝的回复)
定义: Rejected 是一组回复中被认为不太理想的选项。模型通过学习这些不太理想的回复,从而避免在未来的生成中出现类似的错误。
示例:
"Horseshoes are either metal or plastic discs. The horseshoes come in different weights, and the lighter ones are easier to throw, so they are often the standard for beginning players."
"马蹄铁是金属或塑料制成的圆盘。马蹄铁有不同的重量,较轻的更容易投掷,因此它们通常是初学者的标准选择。"
作用: 这些被拒绝的回复可能包含了一些不准确的信息(例如,提到马蹄铁可能是塑料制成的,而实际上比赛用的马蹄铁通常是金属制成的),或者是不太相关的描述。通过学习这些被拒绝的回复,模型可以学会避免提供此类答案。
综上所述,在DPO训练中,模型通过对比chosen和rejected的差异来学习如何生成更高质量的回复。通过这种方式,模型能够逐渐改进其生成能力,以提供更加准确和有用的输出。
提问内容:
chat = [ {"role": "user", "content": "以下是一道小学数学题:小明星期一到星期五每天都要骑自行车上学,每天骑的距离不一样,如下图所示。如果小明星期一到星期五骑自行车去学校一共骑了70公里,那么他这五天分别骑了多少公里?\n星期一: 12公里\n星期二: 8公里\n星期三: 10公里\n星期四: 15公里\n星期五: ?"},]
推理输入转为input_ids的token内容:
'<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n以下是一道小学数学题:小明星期一到星期五每天都要骑自行车上学,每天骑的距离不一样,如下图所示。如果小明星期一到星期五骑自行车去学校一共骑了70公里,那么他这五天分别骑了多少公里?\n星期一: 12公里\n星期二: 8公里\n星期三: 10公里\n星期四: 15公里\n星期五:?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n'