1、45分钟,首先问项目,介绍你熟悉的,我说聊天室,简单介绍了一下,他说你项目多少个高并发这种你测试过吗,我说没有,他没有深究我,想问我性能,问我部署在云端了吗我说没有,这个他表示可以理解;
2、因为上面提到多线程,他说线程池创建方式,我回了excutor excutorservice什么的,threadpollexcutor,我说这个里面会定义很多线程信息,最大线程数啥的,我准备说里面参数,他说你不用说参数英文,我就说了最大线程数,指定线程数,存活时间,任务队列,拒绝策略,他说那你说下拒绝策略,我说了直接抛出异常,还有运行一个当前被丢弃的任务,造成任务提交线程性能下降,还有一个策略丢弃最老的一个请求,还有一个丢弃掉没有办法的任务
Java 中的线程池是通过 Executor 框架实现的,该框架中用到了 Executor,Executors,
ExecutorService,ThreadPoolExecutor ,Callable 和 Future、FutureTask 这几个类。
ThreadPoolExecutor的构造方法如下:public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize, long keepAliveTime,TimeUnit unit, BlockingQueue workQueue) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,Executors.defaultThreadFactory(), defaultHandler); }
- corePoolSize:指定了线程池中的线程数量。
- maximumPoolSize:指定了线程池中的最大线程数量。
- keepAliveTime:当前线程池数量超过 corePoolSize 时,多余的空闲线程的存活时间,即多少时间内会被销毁。
- unit:keepAliveTime 的单位。
- workQueue:任务队列,被提交但尚未被执行的任务。
- threadFactory:线程工厂,用于创建线程,一般用默认的即可。
- handler:拒绝策略,当任务太多来不及处理,如何拒绝任务。
拒绝策略
线程池中的线程已经用完了,无法继续为新任务服务,同时,等待队列也已经排满了,再也塞不下新任务了。这时候我们就需要拒绝策略机制合理的处理这个问题。
JDK 内置的拒绝策略如下:
- AbortPolicy : 直接抛出异常,阻止系统正常运行。
- CallerRunsPolicy : 只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。显然这样做不会真的丢弃任务,但是,任务提交线程的性能极有可能会急剧下降。
- DiscardOldestPolicy : 丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务。
- DiscardPolicy : 该策略默默地丢弃无法处理的任务,不予任何处理。如果允许任务丢失,这是最好的一种方案。
以上内置拒绝策略均实现了 RejectedExecutionHandler 接口,若以上策略仍无法满足实际需要,完全可以自己扩展 RejectedExecutionHandler 接口。
3、他让我描述核心线程数、最大线程数,队列,这里他还给场景多少个咋咋,具体到数字,这个其实问线程执行流程,然后我答了,就也过了这个问题
- 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
- 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
a) 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务
b) 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列
c) 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
d) 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常 RejectExecutionException。- 当一个线程完成任务时,它会从队列中取下一个任务来执行。
- 当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池所有任务完成后,它最终会收缩到 corePoolSize 的大小。
4、String、StringBuffer、StringBuilder问我,我答了一下,这个过了
可变性
String类中使用字符数组保存字符串,private final char value[],所以string对象是不可变的;
因为字符串是不可变的,所以在它创建的时候HashCode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,char[] value,这两种对象都是可变的。
StringBuffer是线程安全的可变字符序列,在大量拼接字符串时,就可以使用长度可变的字符容器,构造一个其中不带字符的字符串缓冲区,初始容量为 16 个字符;
线程安全性
String中的对象是不可变的,也就可以理解为常量,线程安全。
AbstractStringBuilder是StringBuilder与StringBuffer的公共父类,定义了一些字符串的基本操作,如expandCapacity、append、insert、indexOf等公共方法。
StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对String 类型进行改变的时候,都会生成一个新的String对象,然后将指针指向新的String 对象;
StringBuffer每次都会对对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用StringBuilder 相比使用StringBuffer 仅能获得10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结
如果要操作少量的数据用 = String
单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
5、JVM组成,我说老师你意思JVM内存吗(他说这个下个再问,他可能觉得我故意的,所以下个没问我这个)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aAASzVS7-1639378899419)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\1617029127058.png)]
5、他说你说到GC那你说下里面算法,我说了垃圾回收好处,然后对象什么时候需要被回收,引用计数器和可达行分析算法,然后开始说算法有哪些,标记清除算法,我说基于这个算法有问题,所以有了复制算法,介绍了一下,标记整理算法,分代收集算法,我说了新生代老年代
GC是什么,为什么要gc
GC是垃圾回收的意思,内存处理是编程人员最容易出现问题的地方,忘记或者错误的内存;
回收会导致程序或系统的不稳定甚至崩溃,Java提供的GC功能可以自动监测对象是否超过作用域从而达到自动回收的目的,Java语言没有提供释放已分配内存的显示操作方法;
如何判断对象死亡
堆中存放着所有的对象实例,对堆垃圾回收前的第一步就是要判断哪些对象已经死亡(即不可能再被任何途径使用的对象)
引用计数法
给对象中添加一个引用计数器,每当有一个地方引用它,计数器+1,引用失效,计数器-1;任何时候计数器为0的对象就是不可能再被使用的;
带来的弊端:
循环引用、计数器会带来一定的开销;
可达性分析算法
这个算法的基本思想就是通过一系列的称为"GC Roots"的对象作为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连的话,则证明此对象是不可用的;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aKLA6hag-1639378899422)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\1615469606661.png)]
垃圾回收器算法
标记——清除算法
首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。这个算法是最基础的算法,后续的算法都是在它的基础上改进,这个算法的缺点在:
1、效率问题
2、空间问题(标记清除后会产生大量不连续的碎片)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UdVnIBh3-1639378899423)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\1615516145423.png)]
复制算法
为了解决效率问题,“复制”收集算法出现了,它可以将内存分为大小相同的两块,每次使用其中的一块,当这一块的内存使用完成之后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉,这样就使每次的内存回收都是对内存区间的一半进行回收;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dv5eVaqr-1639378899424)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\1615516396250.png)]
标记——整理算法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8IoC5vY4-1639378899425)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\1615516427006.png)]
根据老年代的特点出的一种标记算法,标记过程仍然与“标记——请除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存;
分代收集算法
当前虚拟机的垃圾回收器都使用这个分代收集算法,它根绝对象存货周期的不同将内存分为几块;一般将Java堆分为新生代和老年代,这样就可以根据各个年代的特点选择合适的垃圾收集算法;
比如在新生代中,每次收集都会有大量的对象死去,所以可以选择复制算法,只需要付出少量对象复制的成本就可以完成每次垃圾回收。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记——清除”或“标记——整理”算法进行垃圾回收;
HotSpot为什么要分为新生代和老年代
主要是为了提升GC效率;
6、他说那你说新生代、老年代的占比,我说了1/3 2/3
新生代from to这两个区域,他说那你知道标记多少次对象才会被放到老年代,我说from to之间移动对象,15岁;
简述分代垃圾回收器是怎么工作的
分代回收器有2个分区:老年代和新生代,新生代默认的空间占比总空间的1/3,老年代是2/3;
新生代使用的是复制算法,新生代里面有3个区:Eden、ToSurvivor、FromSurvivor,它们默认占比是8:1:1,执行流程如下:
- 把Eden+FromSurvivor存活的对象放入ToSurvivor区; - 清空Eden和FromSurvivor分区; - FromSurvivor和ToSurvivor分区交换,FromSurvivor变成了ToSurvivor,ToSurvivor变成了ToSurvivor;每次在FromSurvivor到ToSurvivor移动时都存活的对象,年龄就+1,当年龄到达15时(默认配置是15),升级为老年代。大对象也会直接进入老年代;
老年代当空间占用达到某个值之后,就会触发全局垃圾回收,一般使用标记整理算法【首先扫描一次所有老年代,标记出存活的对象,然后回收没有标记的对象。MajorGC 的耗时比较长,因为要扫描再回收。MajorGC 会产生内存碎片,为了减少内存损耗,我们一般需要进行合并或者标记出来方便下次直接分配。当老年代也满了装不下的时候,就会抛出 OOM(Out of Memory)异常。】,以上这些循环往复就构成了整个分代垃圾回收的整体执行流程;
7、问我集合,我说collection list set queue map他问我list set区别,我说了:一个是有序且重复,一个是无序不重复;
8、线程状态,我说了新生态,就绪态,运行态,阻塞态,死亡态,介绍了一下:
新生态:New
一个线程被实例化完成,但是还没有做任何操作;就绪态:Ready
一个线程已经被开启,已经开始去争抢CPU时间片;Java虚拟机会为这个线程创建方法调用栈、程序计数器,等待调度运行;运行态:Run
一个线程抢到了CPU时间片,开始运行这个线程run()的逻辑;阻塞态:Interrupt
一个线程在运行的过程中,受到某些操作的影响,放弃了已经获取到的CPU时间片,并且不再去参与CPU时间片的争抢,此时线程处于挂起状态(暂停);死亡态:Dead
一个线程对象需要被销毁;一个线程会以以下3种方式结束,结束后就是死亡状态;
9、他说你线程阻塞的时候wait和sleep区别,这个没有回答好 他不是很满意,我只说了sleep能醒来,别的不知道,他说没关系:
1、对于 sleep()方法,我们首先要知道该方法是属于 Thread 类中的,而 wait()方法,则是属于Object 类中的。
2、sleep()方法导致了程序暂停执行指定的时间,让出 CPU 给其他线程,但是他的监控状态依然保持着,当指定的时间到了又会自动恢复运行状态。在调用 sleep()方法的过程中,线程不会释放对象锁。
3、而当调用 wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用 notify()方法后本线程才进入对象锁定池准备获取对象锁进入运行状态。
10、他说线程死锁,我说了死锁原因,然后他问我死锁产生条件,我说了4个,互斥条件,产生阻塞不放资源,死循环,sleep抓着资源不放;
指的是两个或两个以上的线程,因为同时抢占CPU资源而出现的相互等待现象;
1、互斥条件:该资源任一时刻只由一个线程占用;
2、请求与保持条件:一个进程因为请求资源而阻塞时,对已获得的资源保持不放;
3、不剥夺条件:线程已获得的资源在未使用完成之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源;sleep()
4、循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系;
11、java里面常见异常类,我说了运行期异常,以及常见异常类,编译期异常我说几个,他说我这个没说对,这个大意了,好险
运行期异常:
1、交给JVM处理,打印异常的堆栈信息,退出JVM;
2、try catch捕获异常;
RuntimeException及其子类都被称为运行时异常。
特点:Java编译器不会检查它,也就是说,当程序中可能出现这类异常时,倘若既"没有通过throws声明抛出它",也"没有用try-catch语句捕获它",还是会编译通过。例如,除数为零时产生的
ArithmeticException异常,数组越界时产生的IndexOutOfBoundsException异常,fail-fast机制产生的ConcurrentModicationException异常(java.util包下面的所有的集合类都是快速失败的,“快速失败”也就是fail-fast,它是Java集合的一种错误检测机制。)当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast机制。记住是有可能,而不是一定;常见的五种运行时异常:
ClassCastException(类转换异常)
IndexOutOfBoundsException(数组越界)
NullPointerException(空指针异常)
ArrayStoreException(数据存储异常,操作数组是类型不一致)
Bu?erOver?owException
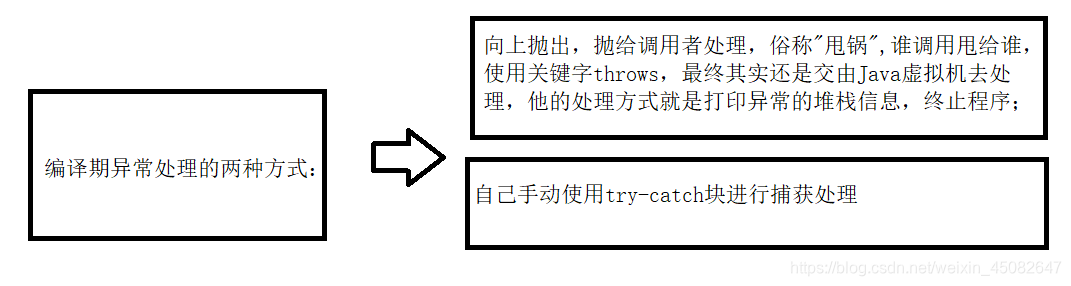
编译期异常
是指非RuntimeException及其子类,编译期异常必须处理,否则程序无法运行;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wiH8VjvY-1639378899427)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\1614857224098.png)]
Java编译器会检查它。此类异常,要么通过throws进行声明抛出,要么通过try-catch进行捕获处理,否则不能通过编译。例如,CloneNotSupportedException就属于被检查异常。当通过clone()接口去克隆一个对象,而该对象对应的类没有实现Cloneable接口,就会抛出CloneNotSupportedException异常。被检查异常通常都是可以恢复的;
如:
IOException
FileNotFoundException
SQLException 被检查的异常适用于那些不是因程序引起的错误情况,比如:读取文件时文件不存在引发的FileNotFoundException 。然而,不被检查的异常通常都是由于糟糕的编程引起的,比如:在对象引用时没有确保对象非空而引起的 NullPointerException;
错误
定义 : Error类及其子类;
特点 : 和运行时异常一样,编译器也不会对错误进行检查。当资源不足、约束失败、或是其它程序无法继续运行的条件发生时,就产生错误。程序本身无法修复这些错误的。例如,VirtualMachineError就属于错误。出现这种错误会导致程序终止运行。OutOfMemoryError、
ThreadDeath。Java虚拟机规范规定JVM的内存分为了好几块,比如堆,栈,程序计数器,方法区等
12、oom他问我了解不,他问构建过吗,我说没有特别了解过,我说递归算吗,他说对可以,他说他想了解怎么构建这个异常,定位这个经验,我说没有
13、Linux他问我这个了解不,我说没有,这个很尴尬了,我表示下去一定会学习的,他说这个了解肯定好,不了解没关系
14、他又问我jvm调优,我说没有调优过,但是知道一些参数,这里很尴尬,他说你看的书还行,比较多,但是很多东西没有上手,很尴尬
他给我一个场景,我意识到这个JVM参数是一个调整新生代老年代这个比例,他说是这个,但是我说我记不清楚这个参数,他说么关系这个还是比较细,记不清楚没关系;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g4KPSPfU-1639378899428)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\1617029770087.png)]
15、他说来个算法,看你当时笔试,是因为出题太难了吗,我说不是找个当时状态不太好,好险
然后快排,我写了一堆,后来他说你这个自己找下哪错了,我没找出来,我说老师你提示下,他说他那边显示多少行有错误,我看了下就是返回值有问题,后来运行失败,然后他正准备问我为啥啥的,我突然发现没调用函数,我就赶紧调用,发现运行出来了,好险,要是没有运行出来我就惨了,他让我讲了下思路,我就很难过的顺了一下算法,没再问我,继续开始提问,我就哎,我同学面美团面了快一个小时,难道我也这么受到折磨;
import java.util.Arrays;
public class QuickSortDemo {
public static void main(String[] args) {
int[] arr = {19, 97, 9, 17, 20, 8};
QuickSort(arr, 0, arr.length - 1);
System.out.println(Arrays.toString(arr));
}
public static void QuickSort(int[] arr, int left, int right){
//首先要进行一个数据的校验
if(left > right){
return;
}
//设立左边标记,右边标记,基准
int l = left;
int r = right;
int pivot = arr[left];
//定义中间变量,用于交换
int temp =0;
while(l < r) {
//从右往左开始找,直到找到一个小于基准的数字停下来
//跳出循环
while (l < r && arr[r] >= pivot) {
r--;
}
//从左往右开始找,直到找到一个大于基准的数字停下来
//跳出循环
while (l < r && arr[l] <= pivot) {
l++;
}
//找到之后,交换两边数字
temp = arr[l];
arr[l] = arr[r];
arr[r] = temp;
}
//跳出循环
//此时说明l=r;
//将基准数字与l=r位置上的数字进行交换
arr[left] = arr[l];
arr[l] = pivot;
//此时,大于基准的数字都在基准的右边
//小于基准的数字都在基准的左边
//左半边递归
QuickSort(arr,left, l-1);
//右半边递归
QuickSort(arr, r+1, right);
}
}
16、他问我redis,我说有用过jedis,但是不太熟悉,他就没问,问我集群啥我说没有了解过,是单机;
这里其实可以说本地配置过一主二从这样;
@Test void contextLoads() { //创建Jedis对象 Jedis jedis = new Jedis("127.0.0.1", 6379); String response = jedis.ping(); System.out.println(response); //PONG }
- 常用的API
string、list、set、hash、zset,所有的api命令就是之前学习的指令,一个都没有变化;
@Test void testKey() throws JSONException { Jedis jedis = new Jedis("127.0.0.1", 6379); //清空数据库 jedis.flushDB(); //将对象存入redis System.out.println(jedis.set("name", "zhangsan"));//ok System.out.println(jedis.set("age", "20"));//ok System.out.println(jedis.set("hobby", "sing"));//ok //判断是否存在key System.out.println(jedis.exists("name"));//true //输出系统所有的键: System.out.println(jedis.keys("*"));//[name, age, hobby] //删除键 System.out.println(jedis.del("name"));//1 //查看键所存储的值的数据类型 System.out.println(jedis.type("age"));//string //随机返回Key空间中的一个 System.out.println(jedis.randomKey());//hobby //重命名key System.out.println(jedis.rename("age", "myage"));//ok //取出修改后的key System.out.println(jedis.get("myage"));//20 //按照索引查询 System.out.println(jedis.select(0));//ok //返回当前数据库中所有key的数目 System.out.println(jedis.dbSize());//2 //删除当前数据库中所有的Key System.out.println(jedis.flushAll());//ok }@Test void testString() { Jedis jedis = new Jedis("127.0.0.1", 6379); jedis.flushDB(); System.out.println("===========增加数据==========="); System.out.println(jedis.set("key1", "value1"));//ok System.out.println(jedis.set("key2", "value2"));//ok System.out.println(jedis.set("key3", "value3"));//ok System.out.println("删除键key2:" + jedis.del("key2")); System.out.println("获取键key2:" + jedis.get("key2")); System.out.println("修改key1:" + jedis.set("key1", "value1Changed")); System.out.println("获取key1的值:" + jedis.get("key1")); System.out.println("在key3后面加入值:" + jedis.append("key3", "End")); System.out.println("key3的值:" + jedis.get("key3")); System.out.println("增加多个键值对:" + jedis.mset("key01", "value01", "key02", "value02", "key03", "value03")); System.out.println("获取多个键值对:" + jedis.mget("key01", "key02", "key03")); System.out.println("获取多个键值对:" + jedis.mget("key01", "key02", "key03", "key04")); System.out.println("删除多个键值对:" + jedis.del("key01", "key02")); System.out.println("获取多个键值对:" + jedis.mget("key01", "key02", "key03")); jedis.flushDB(); System.out.println("===========新增键值对防止覆盖原先值=============="); System.out.println(jedis.setnx("key1", "value1")); System.out.println(jedis.setnx("key2", "value2")); System.out.println(jedis.setnx("key2", "value2-new")); System.out.println(jedis.get("key1")); System.out.println(jedis.get("key2")); System.out.println("===========新增键值对并设置有效时间============="); System.out.println(jedis.setex("key3", 2, "value3")); System.out.println(jedis.get("key3")); try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(jedis.get("key3")); System.out.println("===========获取原值,更新为新值=========="); System.out.println(jedis.getSet("key2", "key2GetSet")); System.out.println(jedis.get("key2")); System.out.println("获得key2的值的字串:" + jedis.getrange("key2", 2, 4)); }@Test void testList() { Jedis jedis = new Jedis("127.0.0.1", 6379); jedis.flushDB(); System.out.println("===========添加一个list==========="); jedis.lpush("collections", "ArrayList", "Vector", "Stack", "HashMap", "WeakHashMap", "LinkedHashMap"); jedis.lpush("collections", "HashSet"); jedis.lpush("collections", "TreeSet"); jedis.lpush("collections", "TreeMap"); System.out.println("collections的内容:" + jedis.lrange("collections", 0, -1));//-1代表倒数第一个元素,-2代表倒数第二个元素,end为-1表示查询全部 System.out.println("collections区间0-3的元素:" + jedis.lrange("collections", 0, 3)); System.out.println("==============================="); // 删除列表指定的值 ,第二个参数为删除的个数(有重复时),后add进去的值先被删,类似于出栈 System.out.println("删除指定元素个数:" + jedis.lrem("collections", 2, "HashMap")); System.out.println("collections的内容:" + jedis.lrange("collections", 0, -1)); System.out.println("删除下表0-3区间之外的元素:" + jedis.ltrim("collections", 0, 3)); System.out.println("collections的内容:" + jedis.lrange("collections", 0, -1)); System.out.println("collections列表出栈(左端):" + jedis.lpop("collections")); System.out.println("collections的内容:" + jedis.lrange("collections", 0, -1)); System.out.println("collections添加元素,从列表右端,与lpush相对应:" + jedis.rpush("collections", "EnumMap")); System.out.println("collections的内容:" + jedis.lrange("collections", 0, -1)); System.out.println("collections列表出栈(右端):" + jedis.rpop("collections")); System.out.println("collections的内容:" + jedis.lrange("collections", 0, -1)); System.out.println("修改collections指定下标1的内容:" + jedis.lset("collections", 1, "LinkedArrayList")); System.out.println("collections的内容:" + jedis.lrange("collections", 0, -1)); System.out.println("==============================="); System.out.println("collections的长度:" + jedis.llen("collections")); System.out.println("获取collections下标为2的元素:" + jedis.lindex("collections", 2)); System.out.println("==============================="); jedis.lpush("sortedList", "3", "6", "2", "0", "7", "4"); System.out.println("sortedList排序前:" + jedis.lrange("sortedList", 0, -1)); System.out.println(jedis.sort("sortedList")); System.out.println("sortedList排序后:" + jedis.lrange("sortedList", 0, -1)); }@Test void testSet() { Jedis jedis = new Jedis("127.0.0.1", 6379); jedis.flushDB(); System.out.println("============向集合中添加元素(不重复)============"); System.out.println(jedis.sadd("eleSet", "e1", "e2", "e4", "e3", "e0", "e8", "e7", "e5")); System.out.println(jedis.sadd("eleSet", "e6")); System.out.println(jedis.sadd("eleSet", "e6")); System.out.println("eleSet的所有元素为:" + jedis.smembers("eleSet")); System.out.println("删除一个元素e0:" + jedis.srem("eleSet", "e0")); System.out.println("eleSet的所有元素为:" + jedis.smembers("eleSet")); System.out.println("删除两个元素e7和e6:" + jedis.srem("eleSet", "e7", "e6")); System.out.println("eleSet的所有元素为:" + jedis.smembers("eleSet")); System.out.println("随机的移除集合中的一个元素:" + jedis.spop("eleSet")); System.out.println("随机的移除集合中的一个元素:" + jedis.spop("eleSet")); System.out.println("eleSet的所有元素为:" + jedis.smembers("eleSet")); System.out.println("eleSet中包含元素的个数:" + jedis.scard("eleSet")); System.out.println("e3是否在eleSet中:" + jedis.sismember("eleSet", "e3")); System.out.println("e1是否在eleSet中:" + jedis.sismember("eleSet", "e1")); System.out.println("e1是否在eleSet中:" + jedis.sismember("eleSet", "e5")); System.out.println("================================="); System.out.println(jedis.sadd("eleSet1", "e1", "e2", "e4", "e3", "e0", "e8", "e7", "e5")); System.out.println(jedis.sadd("eleSet2", "e1", "e2", "e4", "e3", "e0", "e8")); System.out.println("将eleSet1中删除e1并存入eleSet3中:" + jedis.smove("eleSet1", "eleSet3", "e1"));//移到集合元素 System.out.println("将eleSet1中删除e2并存入eleSet3中:" + jedis.smove("eleSet1", "eleSet3", "e2")); System.out.println("eleSet1中的元素:" + jedis.smembers("eleSet1")); System.out.println("eleSet3中的元素:" + jedis.smembers("eleSet3")); System.out.println("============集合运算================="); System.out.println("eleSet1中的元素:" + jedis.smembers("eleSet1")); System.out.println("eleSet2中的元素:" + jedis.smembers("eleSet2")); System.out.println("eleSet1和eleSet2的交集:" + jedis.sinter("eleSet1", "eleSet2")); System.out.println("eleSet1和eleSet2的并集:" + jedis.sunion("eleSet1", "eleSet2")); System.out.println("eleSet1和eleSet2的差集:" + jedis.sdiff("eleSet1", "eleSet2"));//eleSet1中有,eleSet2中没有 jedis.sinterstore("eleSet4", "eleSet1", "eleSet2");//求交集并将交集保存到dstkey的集合 System.out.println("eleSet4中的元素:" + jedis.smembers("eleSet4")); }@Test void testHash() { Jedis jedis = new Jedis("127.0.0.1", 6379); jedis.flushDB(); Map<String, String> map = new HashMap<String, String>(); map.put("key1", "value1"); map.put("key2", "value2"); map.put("key3", "value3"); map.put("key4", "value4"); //添加名称为hash(key)的hash元素 jedis.hmset("hash", map); //向名称为hash的hash中添加key为key5,value为value5元素 jedis.hset("hash", "key5", "value5"); System.out.println("散列hash的所有键值对为:" + jedis.hgetAll("hash"));//return Map<String,String> System.out.println("散列hash的所有键为:" + jedis.hkeys("hash"));//return Set<String> System.out.println("散列hash的所有值为:" + jedis.hvals("hash"));//return List<String> System.out.println("将key6保存的值加上一个整数,如果key6不存在则添加key6:" + jedis.hincrBy("hash", "key6", 6)); System.out.println("散列hash的所有键值对为:" + jedis.hgetAll("hash")); System.out.println("将key6保存的值加上一个整数,如果key6不存在则添加key6:" + jedis.hincrBy("hash", "key6", 3)); System.out.println("散列hash的所有键值对为:" + jedis.hgetAll("hash")); System.out.println("删除一个或者多个键值对:" + jedis.hdel("hash", "key2")); System.out.println("散列hash的所有键值对为:" + jedis.hgetAll("hash")); System.out.println("散列hash中键值对的个数:" + jedis.hlen("hash")); System.out.println("判断hash中是否存在key2:" + jedis.hexists("hash", "key2")); System.out.println("判断hash中是否存在key3:" + jedis.hexists("hash", "key3")); System.out.println("获取hash中的值:" + jedis.hmget("hash", "key3")); System.out.println("获取hash中的值:" + jedis.hmget("hash", "key3", "key4")); }
- 使用jedis操作事务:
@Test void testTx() throws JSONException { Jedis jedis = new Jedis("127.0.0.1", 6379); jedis.flushDB(); //定义一个对象字符串 JSONObject jsonObject = new JSONObject(); jsonObject.put("username", "zhangsan"); jsonObject.put("age", 20); String str = jsonObject.toJSONString(); //开启事务 Transaction multi = jedis.multi();//返回事务对象 try { multi.set("user1", str); multi.set("user2", str); //模拟异常,代码抛出异常事务执行失败 System.out.println(1 / 0); //提交异常,捕获运行时异常,输出空对象 multi.exec(); } catch (Exception e) { //放弃事务 multi.discard(); e.printStackTrace(); } finally { System.out.println(jedis.get("user1")); System.out.println(jedis.get("user2")); //{"age":20,"username":"zhangsan"} //{"age":20,"username":"zhangsan"} //关闭连接 jedis.close(); } }
主从复制
概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower),数据的复制是单向的,只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点;
作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
- 故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式;
- 负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
- 高可用(集群)基石:主从复制还是哨兵和集群能够实施的基础。
为什么使用集群
一般来说,要将Redis运用于工程项目中,只使用一台Redis是万万不能的(宕机),原因如下:
1、从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大;
2、从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有内存用作Redis存储内存,一般来说,单台Redis最大使用内存不应该超过20G。
【问】:电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点也就是"多读少写"。对于这种场景,我们可以使如下这种架构:
主从复制,读写分离,可以减缓服务器的压力,架构中经常使用;只要在公司中,主从复制就是必须要使用的,因为在真实的项目中不可能单机使用Redis;
【总结】
单台服务器难以负载大量的请求; 单台服务器故障率高,系统崩坏概率大; 单台服务器内存容量有限;
环境配置
只配置从库,不用配置主库;
127.0.0.1:6379> info replication #查看当前库的基本信息 # Replication role:master # 角色 master connected_slaves:0 # 没有从机 master_replid:81eb381b213743d11e794ccec513dd5bfc507afb master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 (1.56s)复制3个配置文件,然后修改对应的信息:
端口 pid名字 log文件名 dump.rdb名字启动单机多服务集群:
一主二从配置
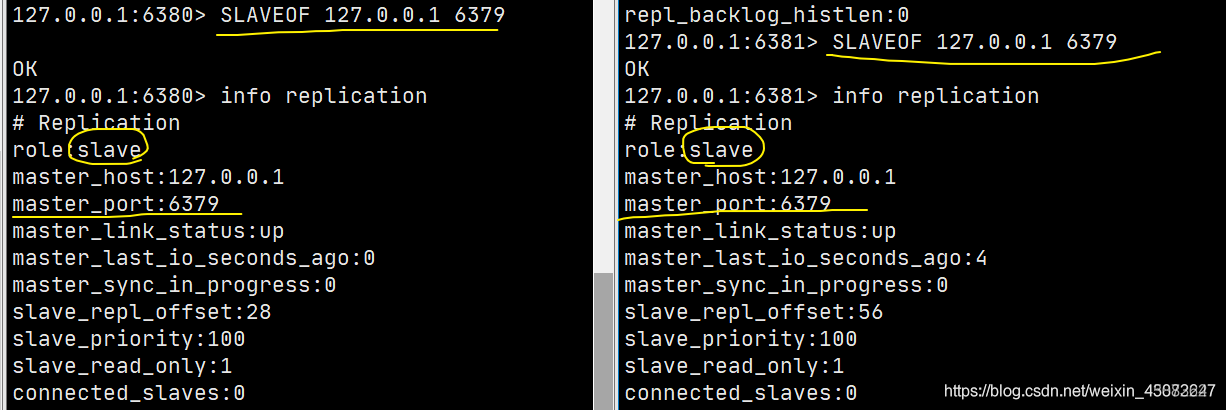
默认情况下,每台Redis服务器都是主节点,一般情况下只用配置从机就好了; 一主(79)二从(80,81),使用
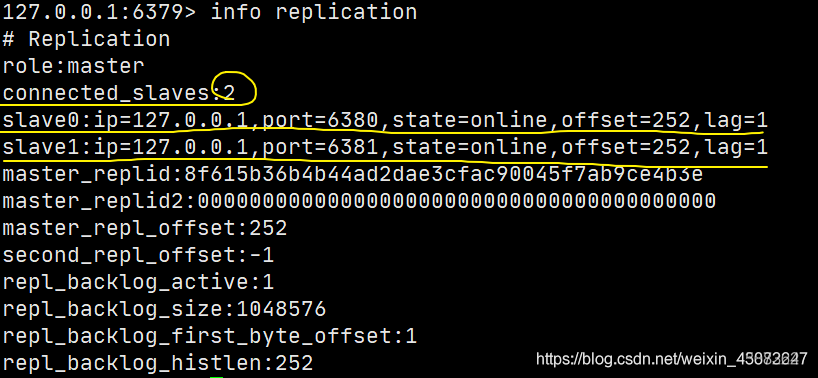
SLAVEOF host port就可以为从机配置主机了。SLAVEOF host 6379 #找谁当自己的老大; role:slave # 当前角色是从机; master_host:127.0.0.1 #可以看到主机的信息然后主机上也能看到从机的状态:
connected_slaves:1 # 多了从机的配置 slave0:ip=127.0.0.1,port=6380,state=online,offset=42,lag=1 # 多了从机的配置真实的从主配置应该在配置文件中配置,这样的话是永久的,这里使用的是命令,暂时的;
使用规则
从机只能读,不能写,主机可读可写但是多用于写;
127.0.0.1:6381> set name sakura # 从机6381写入失败 (error) READONLY You can't write against a read only replica. 127.0.0.1:6380> set name sakura # 从机6380写入失败 (error) READONLY You can't write against a read only replica. 127.0.0.1:6379> set name sakura OK 127.0.0.1:6379> get name "sakura"【重点】
当主机断电宕机后,默认情况下从机的角色不会发生变化 ,集群中只是失去了写操作,当主机恢复以后,又会连接上从机恢复原状。
当从机断电宕机后,若不是使用配置文件配置的从机,再次启动后就会变回主机,它是无法获取之前主机的数据的,若此时重新配置称为从机,又可以获取到主机的所有数据。这里就要提到一个复制原理。
复制原理
Slave 启动成功连接到 master 后会发送一个sync同步命令,Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步。
- 因此只要是重新连接master,一次完全同步(全量复制)将被自动执行,数据一定可以在从机中看到;
层层链路
如果主机断电宕机之后,集群中没有主机了,我们可以在最开始设置集群的时候,设置一个主机存在,然后设置它的一个从机,将这个从机作为另一个从机的主机,但是此时这个从机还是只能进行读操作,不能是写的操作;这种情况下也可以完成主从复制;
- 以上两种情况在实际中都不会使用;
第二条中提到,默认情况下,主机故障后,不会出现新的主机,实际中有两种方式可以产生新的主机:
1、从机手动执行命令
slaveof no one,这样执行以后从机会独立出来成为一个主机; 缺点在于一切操作都是手动的; 2、使用哨兵模式(自动选举老大的模式);

【最后】
然后他就说他那边差不多了,提示我没带耳机那边有点吵,其实是他自己,哎,然后他说他一面就问下基础,好心告诉我hr会打电话找我二面,然后介绍了一堆他部门,呼叫中心,哎,也可以理解,毕竟美团还是不错,所以可想我简历进去,也不会直接到了很牛的部门
反问,我说老师你觉得我需要在哪提升,他说你扩展不行,你看你redis啥的虽然也用,但是不是很深入,好吧_,Linux他说你知道可以更好,他说还有动手,oom这个还没有试过,然后他说整体还行,我说老师您说的也有感受到,我实战确实少点,Linux也确实在学习范围内
件数据后,将其存盘并加载到内存中。
- 增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步。
- 因此只要是重新连接master,一次完全同步(全量复制)将被自动执行,数据一定可以在从机中看到;
层层链路
如果主机断电宕机之后,集群中没有主机了,我们可以在最开始设置集群的时候,设置一个主机存在,然后设置它的一个从机,将这个从机作为另一个从机的主机,但是此时这个从机还是只能进行读操作,不能是写的操作;这种情况下也可以完成主从复制;
- 以上两种情况在实际中都不会使用;
第二条中提到,默认情况下,主机故障后,不会出现新的主机,实际中有两种方式可以产生新的主机:
1、从机手动执行命令
slaveof no one,这样执行以后从机会独立出来成为一个主机; 缺点在于一切操作都是手动的; 2、使用哨兵模式(自动选举老大的模式);
【最后】
然后他就说他那边差不多了,提示我没带耳机那边有点吵,其实是他自己,哎,然后他说他一面就问下基础,好心告诉我hr会打电话找我二面,然后介绍了一堆他部门,呼叫中心,哎,也可以理解,毕竟美团还是不错,所以可想我简历进去,也不会直接到了很牛的部门
反问,我说老师你觉得我需要在哪提升,他说你扩展不行,你看你redis啥的虽然也用,但是不是很深入,好吧_,Linux他说你知道可以更好,他说还有动手,oom这个还没有试过,然后他说整体还行,我说老师您说的也有感受到,我实战确实少点,Linux也确实在学习范围内
然后他说部门在北京,我说为什么上海给我打电话,他说这个是人家私人电话,我说哦,这样,然后结束了;