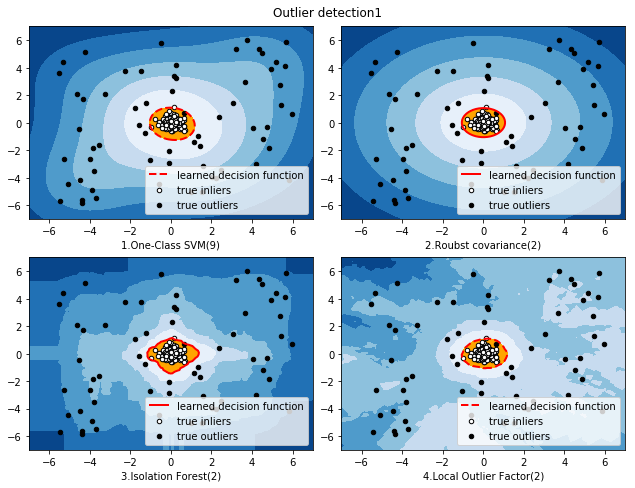
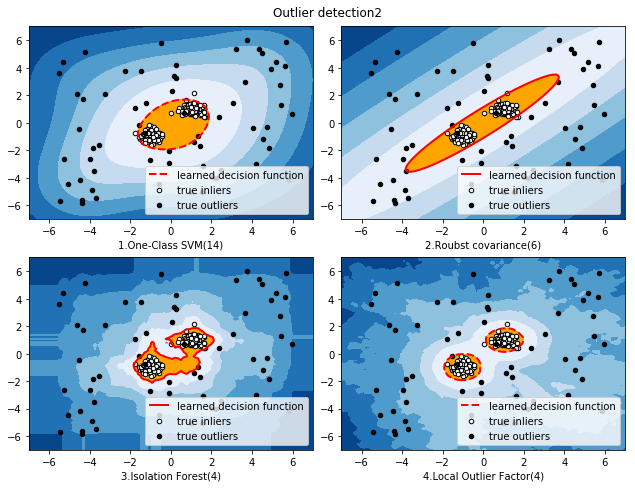
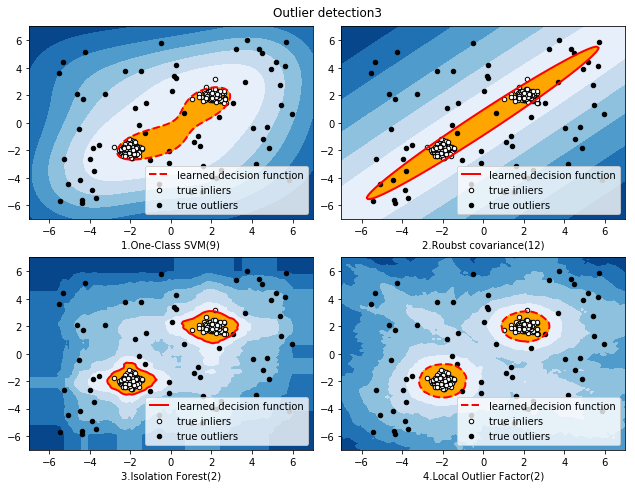
本文主要介绍4种异常点检测方法,One-Class SVM(一分类向量机,非高斯分布)、EllipticEnvelope(基于高斯概率密度的异常点检测)、Isolation Forest(基于集成学习方法异常点检测)、LocalOutlierFactor(基于密度的局部异常因子),并基于同一数据集,对比不同检测方法的效果。
实现代码如下所示:
'''
目标:比较One-Class SVM、EllipticEnvelope、Isolation Forest、
LocalOutlierFactor这4种异常检测算法在相同数据集下的异常检测效果。
'''
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn import svm
from sklearn.covariance import EllipticEnvelope
from sklearn.ensemble import IsolationForest
from sklearn.neighbors import LocalOutlierFactor
rng = np.random.RandomState(42)
#设置样本数量、异常样本比例,不同类样本分离度
n_samples = 256
outliers_fraction = 0.25
clusters_separation = [0,1,2]
#定义各种异常检测方法
classifiers = {
"One-Class SVM":svm.OneClassSVM(nu=0.95 * outliers_fraction + 0.05,kernel='rbf',gamma=0.1),
"Roubst covariance":EllipticEnvelope(contamination=outliers_fraction),
"Isolation Forest":IsolationForest(max_samples=n_samples,
contamination=outliers_fraction,
random_state=rng),
"Local Outlier Factor":LocalOutlierFactor(n_neighbors=35,
contamination=outliers_fraction)}
#样本集各变量赋初值
xx,yy = np.meshgrid(np.linspace(-7,7,100),np.linspace(-7,7,100))
n_inliers = int((1 - outliers_fraction) * n_samples)
n_outliers = int(outliers_fraction * n_samples)
ground_truth = np.ones(n_samples,dtype=int)
ground_truth[-n_outliers:] = -1
#在不同的样本分离度下测试异常检测效果
for i,offset in enumerate(clusters_separation):
np.random.seed(42)
#生成数据
X1 = 0.3 * np.random.randn(n_inliers // 2,2) - offset
X2 = 0.3 * np.random.randn(n_inliers // 2,2) + offset
X = np.r_[X1,X2]
X = np.r_[X,np.random.uniform(low=-6,high=6,size=(n_outliers,2))]
#模型匹配
plt.figure(figsize=(9,7))
for j,(clf_name,clf) in enumerate(classifiers.items()):
#数据匹配
if clf_name == "Local Outlier Factor":
y_pred = clf.fit_predict(X)
scores_pred = clf.negative_outlier_factor_
else:
clf.fit(X)
scores_pred = clf.decision_function(X)
y_pred = clf.predict(X)
threshold = stats.scoreatpercentile(scores_pred,100 * outliers_fraction)
n_errors = (y_pred != ground_truth).sum()
#画图
if clf_name == "Local Outlier Factor":
Z = clf._decision_function(np.c_[xx.ravel(),yy.ravel()])
else:
Z = clf.decision_function(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
subplot = plt.subplot(2,2,j+1)
subplot.contourf(xx,yy,Z,levels=np.linspace(Z.min(),threshold,7),
cmap=plt.cm.Blues_r)
a = subplot.contour(xx,yy,Z,levels=[threshold],linewidths=2,colors='red')
subplot.contourf(xx,yy,Z,levels=[threshold,Z.max()],colors='orange')
#正常样本
b = subplot.scatter(X[:-n_outliers,0],X[:-n_outliers,1],c='white',s=20,edgecolor='k')
#异常样本
c = subplot.scatter(X[-n_outliers:,0],X[-n_outliers:,1],c='black',s=20,edgecolor='k')
subplot.axis('tight')
subplot.legend(
[a.collections[0],b,c],
['learned decision function','true inliers','true outliers'],
prop=matplotlib.font_manager.FontProperties(size=10),
loc='lower right')
subplot.set_xlabel("{}.{}({})".format(j+1,clf_name,n_errors))
subplot.set_xlim((-7,7))
subplot.set_ylim((-7,7))
plt.subplots_adjust(0.04,0.1,0.96,0.94,0.1,0.20)
plt.suptitle("Outlier detection{}".format(i+1))
plt.show()
对比结果如下图所示: