对机器学习的项目理解,学习分析业务如何解决?

数据分析概述

机器学习,数据分析,数据挖掘的区别和联系

数据分析的应用场景

预测模型和建模及分析,也可以做股票建模… 个性化推荐
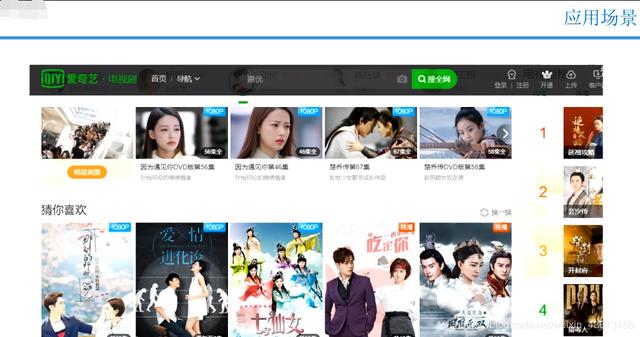

又例如,线下店的选取如何去敲定位置 ,要考虑因素的是什么,例如买家的位置信息,可以用聚类算法K-means,真实业务对接算法。
机器学习的开发流程
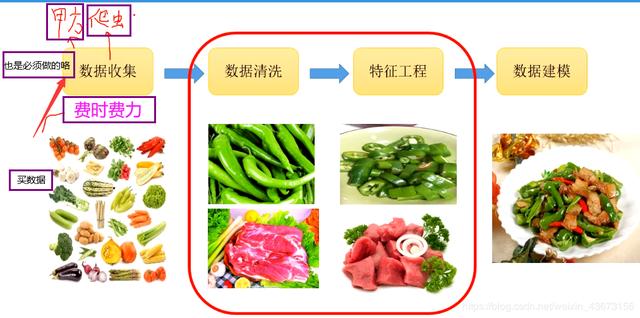
重点
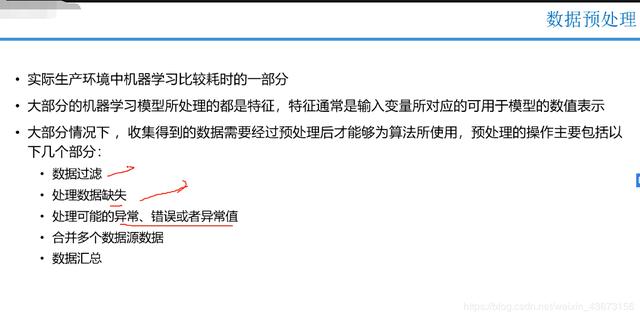
数据清洗:关键的是选取那些是重要的特征,缺失值(NAN),重复值(过拟合问题),去除噪音… 特征工程:独热编码,特征缩放…
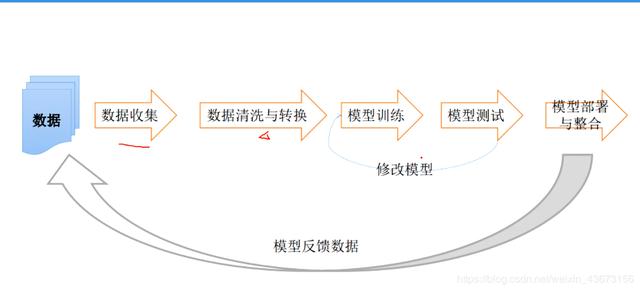
这个流程可能是大半年的上线部署过程!!!

Flume:流的形式;Kafka:消息队列;
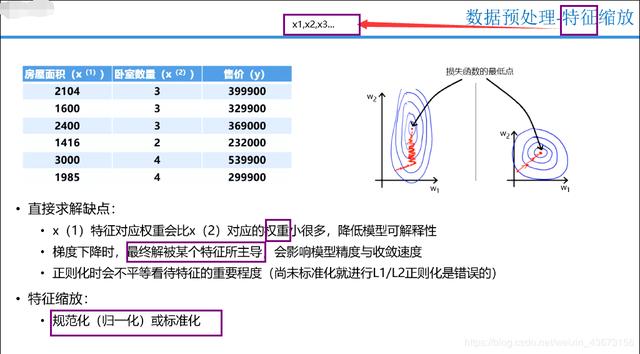
对于房屋面积,数值明显很大,如何x1w1+x2w2+b,明显x1不做处理x1=2104和x2=3,这x2就没意义了(太小)啦兄弟。就要做特征缩放咯啦!! 还得说说啥玩意是正则化: 正则化的概念及原因 简单来说,正则化是一种为了减小测试误差的行为(有时候会增加训练误差)。我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当你用比较复杂的模型比如神经网络,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。
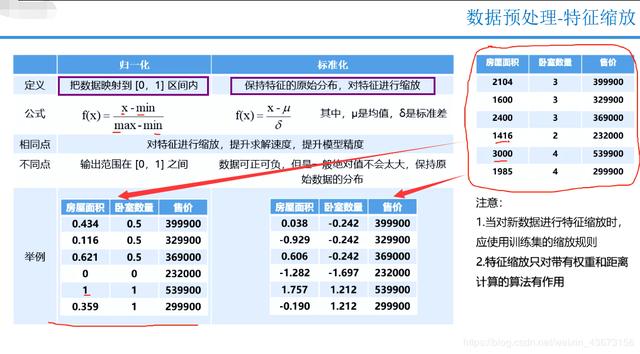
标准化后是类似标准正态分布的咯!标准化比归一化更加常用,可能因为归一化后数据会为0(0*权重就不太好了).

方法四的性别问题就是升维的过程!

带权学习比较好,但是不是每一个算法都支持这个带权学习! 看看朴素贝叶斯的算法中 有这东西的讲解,可以去我博客中找找哦!祝你好运!
