以下为基于本地部署DeepSeek并实现API调用的完整操作方案,涵盖环境配置、服务部署及接口调用全流程:
一、环境准备与模型部署
-
工具选择与安装
- Ollama(推荐):轻量级本地模型管理工具,支持一键部署12
# 下载Ollama客户端(Windows示例) # 官网地址:https://ollama.com/ # 或通过网盘获取安装包:ml-citation{ref="2" data="citationList"}- LM Studio:可视化工具,适合非开发者用户3
# 下载地址:https://lmstudio.ai/ # 或直接获取Windows版本:ml-citation{ref="3" data="citationList"} -
模型下载与加载
- 通过Ollama命令行下载DeepSeek R1模型12
ollama run deepseek-r1:7b # 根据硬件选择1.5B/7B/20B版本:ml-citation{ref="2" data="citationList"}- 或通过LM Studio手动加载离线模型文件(需二级目录存储)3
二、API服务配置
-
启动本地API服务
- Ollama默认端口:11434
# 在LM Studio设置中启用服务,测试接口: curl http://localhost:8088/v1/models # 返回模型列表:ml-citation{ref="3" data="citationList"} - LM Studio自定义端口(如8088)
API地址:http://localhost:11434/v1 模型名称:deepseek-r1:7b:ml-citation{ref="2" data="citationList"}
- Ollama默认端口:11434
-
第三方客户端集成
- Cherry Studio:配置API端点快速调用12
API地址:http://localhost:11434/v1 模型名称:deepseek-r1:7b:ml-citation{ref="2" data="citationList"} - Chatbox:支持自定义HTTP请求头与流式响应1
- Cherry Studio:配置API端点快速调用12
三、API调用示例(Python)
import requests
# 请求参数配置
url = "http://localhost:11434/api/generate"
headers = {"Content-Type": "application/json"}
data = {
"model": "deepseek-r1:7b",
"prompt": "如何优化服务器性能?",
"stream": False # 设置为True启用流式响应
}
# 发送请求并解析结果
response = requests.post(url, json=data, headers=headers)
if response.status_code == 200:
print(response.json()["response"])
else:
print(f"请求失败,状态码:{response.status_code}")
注:需安装
requests库,支持文本补全、对话生成等任务23
四、注意事项
- 数据安全
- 本地部署确保数据不外传,适用于医疗、政务等敏感场景45
- 硬件需求
- GPU显存建议≥16GB(7B模型),CPU模式性能较低34
- 模型选择
- 根据场景选择1.5B(轻量级)或7B/20B(高精度)版本12
- 更新维护
- 定期通过
ollama pull deepseek-r1:7b更新模型2
- 定期通过
流程图解
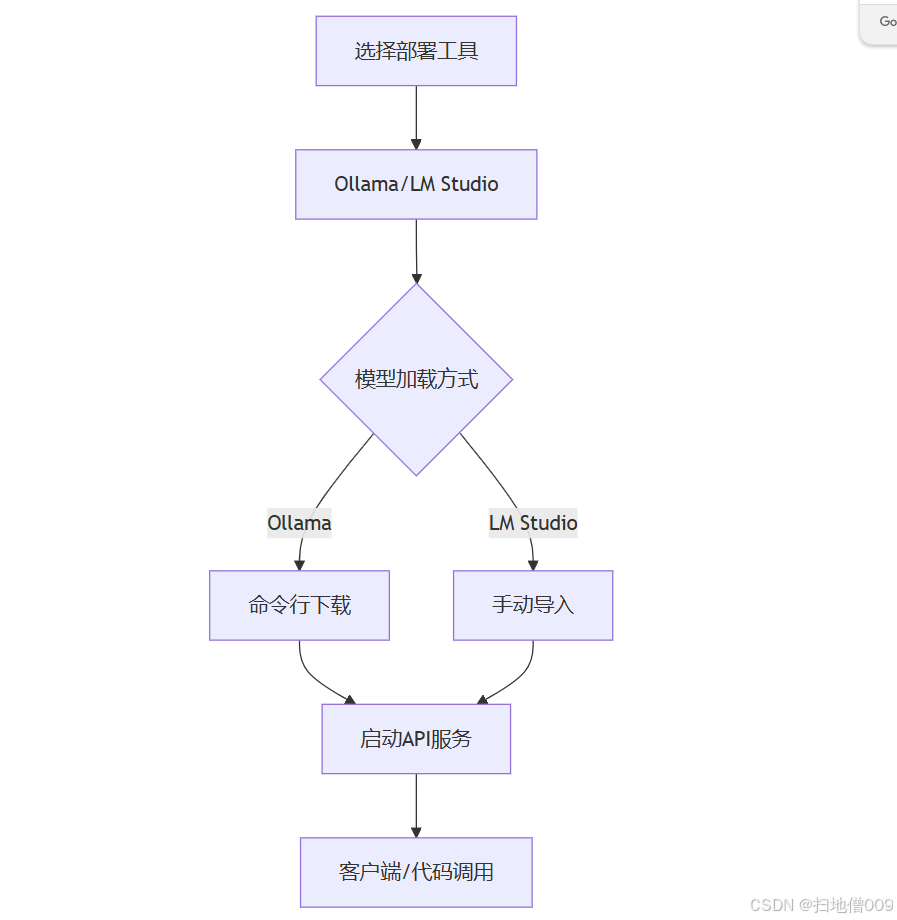
通过以上流程,可在10分钟内完成本地部署并实现API调用,满足私有化场景的智能化需求12。