
本篇文章中,笔者把之前自己码代码的过程中出现的一些已解决的常见bug和解决方法进行了整理,还在不断更新中~~~
主要内容有:
一、与读取CSV文件有关的报错
- 1.1 'utf-8' codec can't decode
- 1.2 pandas.read_csv() 报错OSError: Initializing from file failed
二、与数据处理有关包使用的报错
- 2.1 h5py_init_.py:26:FutureWarning:
- 2.2 ValueError: x and y must have same first dimension
- 2.3 VError: Found input variables with inconsistent numbers of samples: [73, 1]
- 2.4 ValueError: The truth value of an array with more than one ele
- 2.5 异类数据操作错误:TypeError: unsupported operand type(s) for -: 'str' and 'int'
三、基本语法错误
- 3.1 复制代码缩进问题:TabError: inconsistent use of tabs and spaces in indentation
- 3.2列表索引问题:TypeError: list indices must be integers or slices, not str
一、与读取CSV文件有关的报错
1.1 'utf-8' codec can't decode
从GitHub上下载的csv文件很多是raw中显示网页text格式的数据,然后右键另存为的数据,这些CSV文件看起来是逗号分隔的文件,但是内部数据的编码格式其实是带有BOM的utf-8的数据;
使用以下读取方式的时候,
# -*- coding: utf-8 -*-
。。。。。。
pre_train_sale = pd.read_csv('pre_train_sales_data.csv',encoding='utf-8')
会出现:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc9 in position 0: invalid - 需要对原来的数据进行以下的操作:(第二种方法可行)
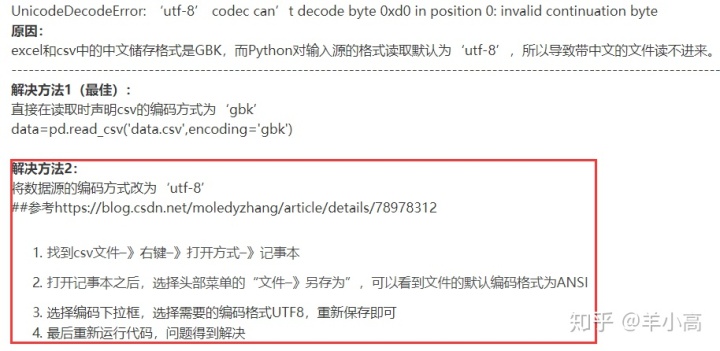
1.2 pandas.read_csv() 报错OSError: Initializing from file failed
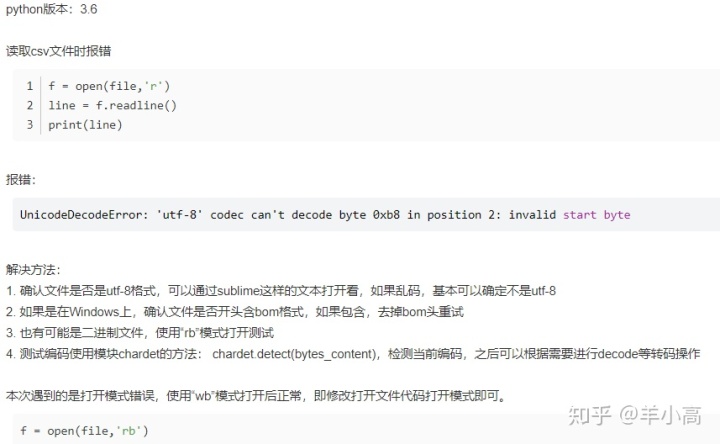
Python版本:Python 3.6
pandas.read_csv() 报错 OSError: Initializing from file failed,一般由两种情况引起:一种是函数参数为路径而非文件名称,另一种是函数参数带有中文。
# -*- coding: utf-8 -*-
"""
Created on Mon Jun 4 09:44:36 2018
@author: wfxu
"""
import pandas as pd
da1=pd.read_csv('F:数据源')
da2=pd.read_csv('F:2.0 数据源工程清单.csv')
这两种情况报错信息都是一样:
Traceback (most recent call last):
(报错细节不展示)
File "pandas/_libs/parsers.pyx", line 720, in pandas._libs.parsers.TextReader._setup_parser_source
OSError: Initializing from file failed
- 对于第一种情况很简单,原因就是没有把文件名称放到路径的后面,把文件名称添加到路径后面就可以了。还可以在代码中把文件夹切换到目标文件所在文件夹,但过程太繁杂,
- 第二种情况,即使路径、文件名都完整,还是报错的原因是这个参数中有中文,但是Python3不是已经支持中文了吗?参考了错误原因和pandas的源码,发现调用pandas的read_csv()方法时,默认使用C engine作为parser engine,而当文件名中含有中文的时候,用C engine在部分情况下就会出错。所以在调用read_csv()方法时指定engine为Python就可以解决问题了。
da4=pd.read_csv('F:数据源工程清单.csv',engine='python')- 对于第二种情况还有另外一种解决方法,使用open函数打开文件,再取访问里面数据:
da3=pd.read_csv(open('F:4.0 居配工程监测2.0 数据源02.东京新居配工程清单.csv'))二、与数据处理有关包使用的报错
2.1 h5py_init_.py:26:FutureWarning:
h5py_init_.py:26:FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
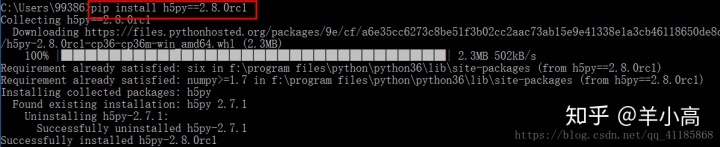
- 解决思路: 出错位置h5py_init_.py:26; 包内出错,是h5py包;
- 解决办法:对h5py进行更新升级, pip install h5py==2.8.0rc1;
2.2 ValueError: x and y must have same first dimension
- 使用matplotlib进行图形绘制,在执行plt.plot(x,y)的时候,遇见:
ValueError: x and y must have same first dimension, but have shapes (19,) and (20,) - 解决办法:
错误提示是x,y两个的维度不一致,一个是19, 另一个是20,因此,将x,y的变量值改为相同的个数即可。
2.3 VError: Found input variables with inconsistent numbers of samples: [73, 1]

2.4 报错信息ax = axes if axes else plt.gca() ValueError: The truth value of an array with more than one ele

2.5 异类数据操作错误:TypeError: unsupported operand type(s) for -: 'str' and 'int'
- 错误类型:TypeError: unsupported operand type(s) for +: ‘int’ and ‘str’
- 错误代码:page= input(‘请输入想要的第几页数据:’)
#代码如下
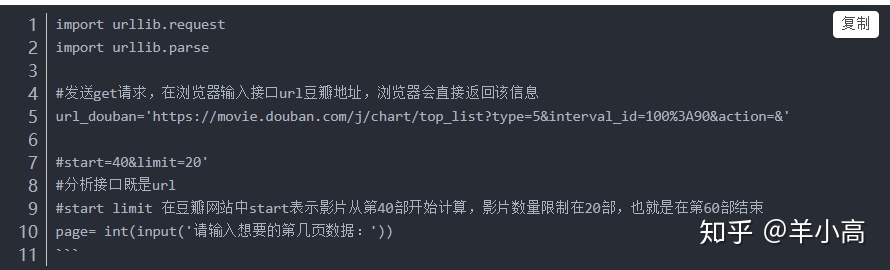
import urllib.request
import urllib.parse
#发送get请求,在浏览器输入接口url豆瓣地址,浏览器会直接返回该信息
url_douban='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
#start=40&limit=20'
#分析接口既是url
#start limit 在豆瓣网站中start表示影片从第40部开始计算,影片数量限制在20部,也就是在第60部结束
page= int(input('请输入想要的第几页数据:'))
- 运行后报错
# 请输入想要的第几页数据:0
Traceback (most recent call last):
File “1-post2.py”, line 16, in
‘start’:(page-1)*number,
TypeError: unsupported operand type(s) for -: ‘str’ and ‘int’
- 错误原因:“类型错误:不支持操作类型为整数和字符串”,这里需要解释的最关键的东西是“-” 正确操作:page= int(input(‘请输入想要的第几页数据:’))
三、基本语法错误
3.1 复制代码缩进问题:TabError: inconsistent use of tabs and spaces in indentation
- django测试时,遇见报错:
TabError: inconsistent use of tabs and spaces in indentation- 报错定位处的代码是拷贝的,存在缩进问题。
- 检查换行缩进,重新调整后,再执行就正常。
3.2 列表索引问题:TypeError: list indices must be integers or slices, not str
- 列表list的索引必须是整数或者切片,而不能是字符串类型。
- 在做python基础课程最后的课程练习“名片管理系统”时候,在编写代码时候遇到错误:
TypeError: list indices must be integers or slices, not str

- 错误代码部分如下:

- 错误提示的意思是: 列表list的索引必须是整数或者切片,而不能是字符串类型。
- 代码中,利用for in循环将card_info中数据进行遍历,并将每一次取出的结果放于info中。
- card_info定义为列表,其中存放着每一个名片信息组成的字典类型,我的本意是对字典类型中键"name"为name的值进行操作,却由于粗心对列表进行了操作。 将判断部分代码改成如下问题得到解决。修改后:if info["name"] == name: