代码阅读:一口一口吃mooncake这块月饼
原创 于游 于游的碎碎念 2024年11月29日 19:47 北京 标题已修改
由于工作的关系,最近频繁接触章老师的研究成果,很荣幸第一时间知道了mooncake开源的消息。这个开源的实现是目前kvcache 优化过程中,非常落地的一个项目。
如果还不知道mooncake是什么,建议去看论文:
《Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving》
论文地址:https://arxiv.org/abs/2407.00079
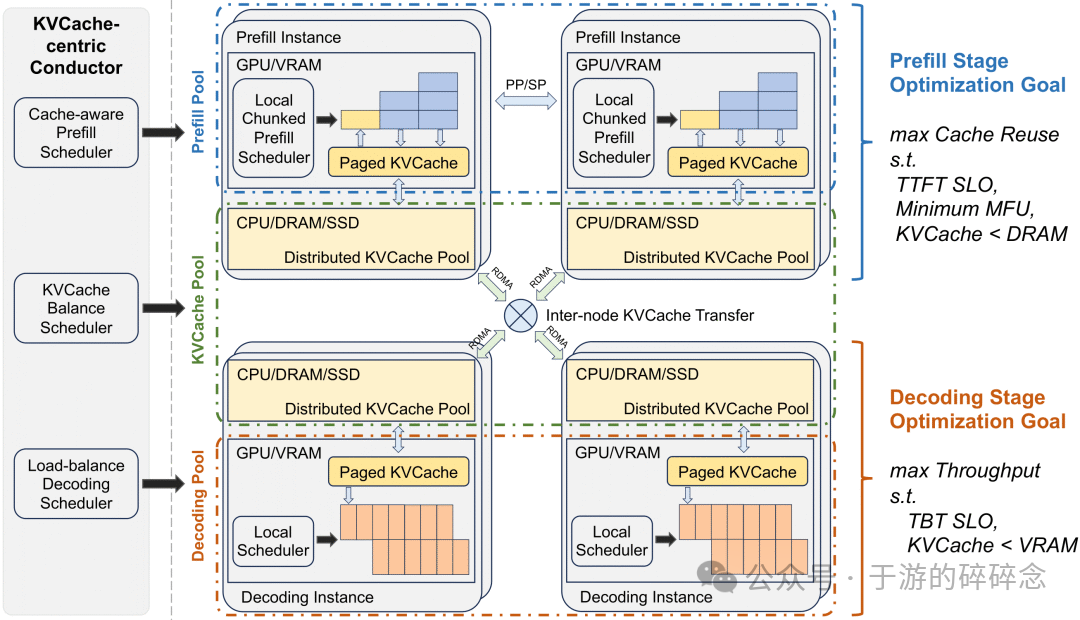
由于论文发表的时候,还没有开源,我当时还尝试着各种方法做一些python伪代码的复现。
现在终于可以大方的看一下,原主的工程实践了。
开源地址:https://github.com/kvcache-ai/Mooncake
非常完整的开源,我今天去看的时候已经收了1.7K的star,给mingxing zhang老师点赞。
其实开源的md已经写得非常清楚了,而且网上已经铺天盖地的各种解读的文章了,本来我这个公众号从来不追热点,不过看完代码之后,还是简单的写点自己的理解。
首先是有一个相对的共识 就是 KVcache这玩意会一直在一个高水位。“每个请求的私有内存”是推理系统优化的主要瓶颈;若不解决,像 Groq 这样的架构将占据优势。尽管有努力减小 KVCache 的大小,但增加其容量的动力更强。
通过系统分离,可以独立发展“算力每美元”和“带宽每美元”,有利于硬件优化。由于自回归(AR)模型的惯性,解码成本始终与带宽成本强烈正相关。即将出现的硬件解决方案将大幅提升“带宽每美元”。
由于尚未有芯片在“算力每美元”和“带宽每美元”上同时最优,集群架构必然需要拆分为两个异构部分,以分别优化计算和带宽效率。
这
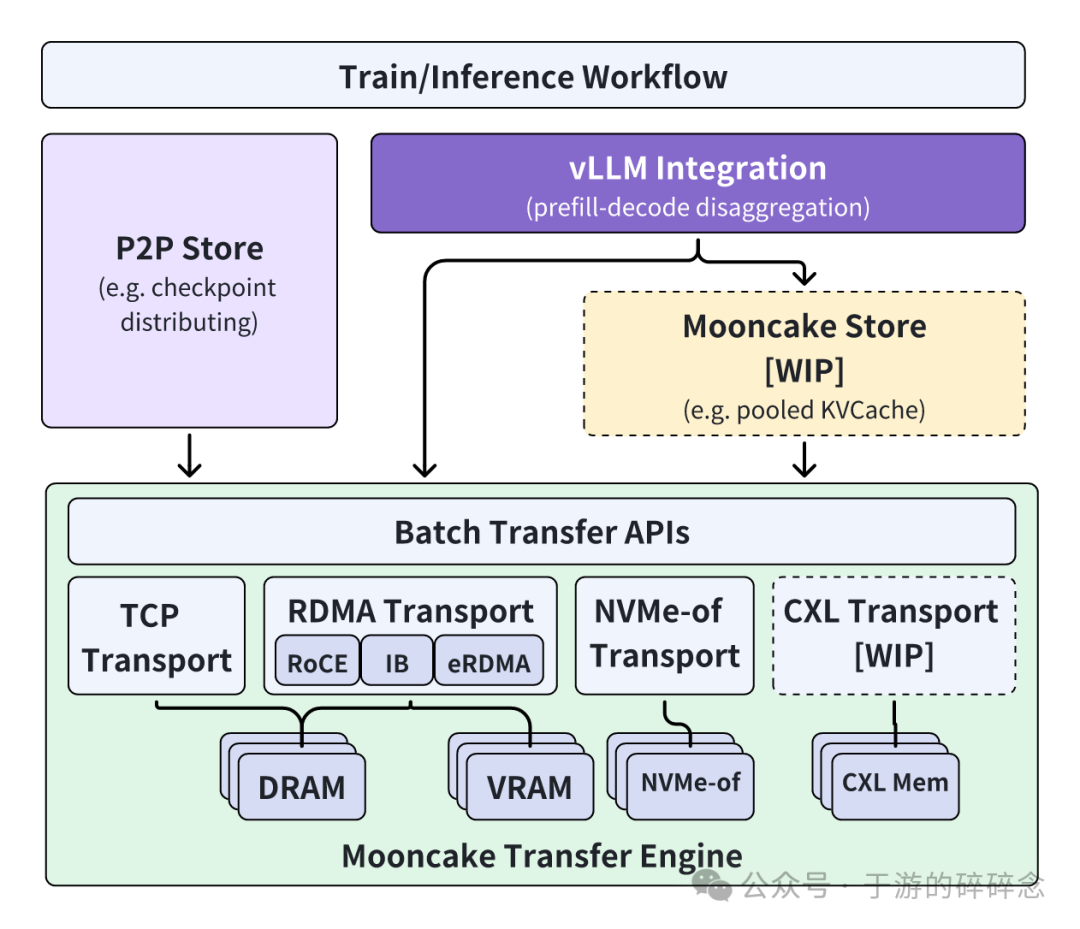
这个图我就不多做解释了,这次开源store部分还没到。因为阅读的时间短我也是简单看看我的理解是否对,另外根据理解,我整理md里面搭建流程,那个流程相对复杂,我试了一下,整理了一下文档,可以简化一下。
顶层目录结构:
mooncake-p2p-store/: P2P存储相关的实现mooncake-transfer-engine/: 传输引擎的实现mooncake-integration/: 集成测试doc/: 项目文档dependencies.sh: 依赖安装脚本CMakeLists.txt: 项目构建配置文件README.md: 项目说明文档
这里面赞一下项目文档,不愧是学术+工程开源,文档写得相当的OK。
这里我主要分析一下主开源文件夹 mooncake-transfer-engine/
include/: 头文件目录src/: 主要源代码目录example/: 示例代码tests/: 测试代码rust/: Rust语言实现的部分scripts/: 辅助脚本
这是一个包含C++和Rust混合编程的项目,主要实现了P2P存储和传输引擎的功能。采用CMake作为构建系统,并且完整提供了测试,示例、文档。
基础设施层
include/├── common.h # 通用定义和工具├── config.h # 配置管理└── error.h # 错误处理
-
common.h: 提供基础数据结构和工具函数
-
config.h: 管理系统配置参数
-
error.h: 统一的错误处理机制
传输引擎核心:
include/├── transfer_engine.h # 传输引擎接口├── transfer_engine_c.h # C语言接口封装└── transfer_metadata.h # 元数据管理src/├── transfer_engine.cpp # 传输引擎实现├── transfer_engine_c.cpp # C接口实现└── transfer_metadata.cpp # 元数据管理实现
-
传输引擎:提供高层数据传输接口
-
元数据管理:处理传输相关的元数据
-
C语言接口:支持跨语言调用
传输协议实现:
include/transport/├── transport.h # 传输协议基类├── rdma_transport/ # RDMA传输实现├── tcp_transport/ # TCP传输实现├── nvmeof_transport/ # NVMe-oF传输实现└── cxl_transport/ # CXL传输实现src/transport/├── transport.cpp # 基类实现├── rdma_transport/ # RDMA具体实现├── tcp_transport/ # TCP具体实现├── nvmeof_transport/ # NVMe-oF具体实现└── cxl_transport/ # CXL具体实现
核心类的逻辑关系:
// 类关系图TransferEngine├── TransferMetadata // 元数据管理└── Transport // 传输协议抽象基类├── RDMATransport // RDMA实现├── TCPTransport // TCP实现├── NVMeOFTransport // NVMe-oF实现└── CXLTransport // CXL实现
我也整理了这个开源的功能图

关键接口和调用流程:
// 1. 初始化传输引擎TransferEngine::init()├── loadConfig() // 加载配置└── initTransports() // 初始化传输协议// 2. 数据传输流程TransferEngine::transfer()├── prepareMetadata() // 准备元数据├── selectTransport() // 选择传输协议├── splitData() // 数据分片└── executeTransfer() // 执行传输// 3. 异步操作支持TransferEngine::asyncTransfer()├── createTransferTask() // 创建传输任务├── scheduleTask() // 调度任务└── notifyCompletion() // 完成通知
当然这个完整的开源也包含了扩展性设计:
-
插件式传输协议:通过Transport基类支持新协议扩展
-
配置化管理:支持通过配置文件调整系统行为
-
跨语言支持:提供C接口便于语言绑定
-
异步操作:支持高并发场景
具体的可以去看代码了~~~~开源的搭建的环境写的非常清楚,不过散落在各个文件中,我大体实验的过程中,简单的记录了下流程,给大家做参考
1、环境准备:
# 系统要求- OS: Ubuntu 22.04 LTS+- cmake: 3.22.x- gcc: 10.2.1+- Python: 3.10+- Go: 1.19+# 安装基础依赖sudo apt-get install -y build-essential \cmake \libibverbs-dev \libgoogle-glog-dev \libgtest-dev \libjsoncpp-dev \libnuma-dev \libpython3-dev \libboost-all-dev \libssl-dev \libgrpc-dev \libgrpc++-dev \libprotobuf-dev \protobuf-compiler-grpc \pybind11-dev
2、编译步骤:
# 1. 克隆代码git clone https://github.com/kvcache-ai/Mooncake.gitcd Mooncake# 2. 安装依赖bash dependencies.sh# 3. 编译Mooncakemkdir buildcd buildcmake .. # 可选参数:-DUSE_CUDA=ON 启用GPU支持make -j$(nproc)# 4. 安装vLLMgit clone [email protected]:kvcache-ai/vllm.gitcd vllmgit checkout mooncake-integrationpip3 uninstall vllm -ypip3 install vllm==0.6.2pip3 uninstall torchvision -ypython3 python_only_dev.py
3、配置文件准备:创建 mooncake.json:
{"prefill_url": "192.168.0.137:13003","decode_url": "192.168.0.139:13003","metadata_server": "192.168.0.139:2379","protocol": "rdma", # 或 "tcp""device_name": "erdma_0" # RDMA设备名,使用tcp时置空}
4、测试步骤:
# 1. 启动etcd服务etcd --listen-client-urls http://0.0.0.0:2379 --advertise-client-urls http://localhost:2379# 2. 启动预填充节点(生产者)export VLLM_HOST_IP="192.168.0.137"export VLLM_PORT="51000"export MASTER_ADDR="192.168.0.137"export MASTER_PORT="54324"export MOONCAKE_CONFIG_PATH=./mooncake.jsonexport VLLM_DISTRIBUTED_KV_ROLE=producerexport VLLM_USE_MODELSCOPE=Truepython3 -m vllm.entrypoints.openai.api_server \--model Qwen/Qwen2.5-7B-Instruct-GPTQ-Int4 \--port 8100 \--max-model-len 10000 \--gpu-memory-utilization 0.95# 3. 启动解码节点(消费者)export VLLM_HOST_IP="192.168.0.137"export VLLM_PORT="51000"export MASTER_ADDR="192.168.0.137"export MASTER_PORT="54324"export MOONCAKE_CONFIG_PATH=./mooncake.jsonexport VLLM_DISTRIBUTED_KV_ROLE=consumerexport VLLM_USE_MODELSCOPE=Truepython3 -m vllm.entrypoints.openai.api_server \--model Qwen/Qwen2.5-7B-Instruct-GPTQ-Int4 \--port 8200 \--max-model-len 10000 \--gpu-memory-utilization 0.95
5、预期测试结果:
RDMA传输性能:输出Token吞吐量: XXX tok/s总Token吞吐量: XXX tok/s平均TTFT: XXXXms中位数TTFT: XXX msP99 TTFT: XXXX msTCP传输性能:输出Token吞吐量: XXX tok/s总Token吞吐量: XXX tok/s平均TTFT: XXXXX ms中位数TTFT: XXXX msP99 TTFT: XXXX ms
6、性能验证方式
# 使用OpenAI API格式测试import openaiopenai.api_base = "http://localhost:8100/v1" # 预填充节点# 或 "http://localhost:8200/v1" # 解码节点response = openai.ChatCompletion.create(model="Qwen2.5-7B-Instruct-GPTQ-Int4",messages=[{"role": "user", "content": "测试消息"}],stream=True)
这个代码严重依赖RDMA设备,并且预填充和解码节点的MASTER_ADDR和MASTER_PORT必须相同。
整体来说,这个开源还是非常完整的,不过实验环境估计只有从业者能有机会去测试,在现在KVCache极度膨胀,并且成本极高的今天,这个项目其实对长上下文有着非常强的意义。由于只是读书笔记,代码本身有很多值得学习的地方。感兴趣的同学一定去看原始的开源。
再次给项目组点赞~~ 向章老师致敬,相当落地的研究方向。
既然来了,没关注的同学关注一下再走呗

于游的碎碎念
技术分享,生活分享,基本上想发啥就发啥
78篇原创内容
公众号
老于的技术文章推荐阅读: