DataFrame是由多种类型的列构成的二维标签数据结构.[1]
往往包含index(行标签)和columns(列标签), 彼此独立, 互不影响
直观理解:DataFrame 是带标签的二维数组
1.由(元组),[列表]或一维数组 构成的(元组)或[列表]创建
(元组)和[列表]在这里用法几乎相同, 下面用[列表]代表
1.1[[列表]列表]或[(元组)列表]或([列表]元组)或((元组)元组)
import 
1.2[一维数组列表]或(一维数组元组)
import 2.由二维数组创建
import 3.由(元组),[列表]或一维数组 构成的字典创建
3.1{(元组)字典} 或 {[列表]字典}
import 
3.2{一维数组字典}
import 4.由{字典} 构成的[列表]创建
import 
5.由{字典} 构成的{字典}创建
import 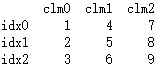
6.由Series创建
Series的name变成了DataFrame的index.
Series的index变成了DataFrame的column.
import 
7.由标量创建
import 
必须用index和columns关键字指定行列标签.
详解
本文函数为 pd.DataFrame(data=None, index=None, columns=None)
data, 位置参数, 按顺序传入时, 不用写data=传入数据
import 生成DataFrame时, 长度尽量保持一致, 省的出错
import 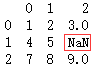
import 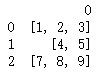
以[列表]作为键值构成的字典, 键值长度必须一致
import 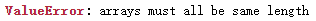
index, 指定行标签, columns, 指定列标签
没有标签, 指定时, [标签列表]中元素个数要与其行或列数对应相同.
import 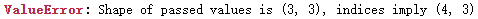
已有标签, 再指定, 则进行索引筛选, 没有的引入NaN值, 举个栗子
import 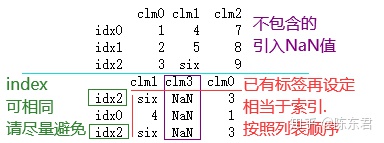
还有如下可选关键字
dtype, 给DataFrame里的成员指定数据类型, 默认dtype=None
import 
参考
- ^https://www.pypandas.cn/docs/getting_started/dsintro.html#dataframe