一、知网介绍
提起中国知网,如果你曾经写过论文,那么基本上都会与中国知网打交道,因为写一篇论文必然面临着各种查重,当然翟博士除外。但是,本次重点不在于写论文跟查重上,而在于我们要爬取知网上一些论文的数据,什么样的数据呢?我们举一个例子来说,在知网上,搜索论文的方式有很多种,但是对于专业人士来说,一般都会使用高级检索,因为直接去查找作者的话,容易查找到很多重名作者,所以我们本次的爬虫也是使用了高级检索(泛称)的爬虫,再具体就是专业检索,有助于我们唯一定位到作者。
二、常规步骤—页面分析
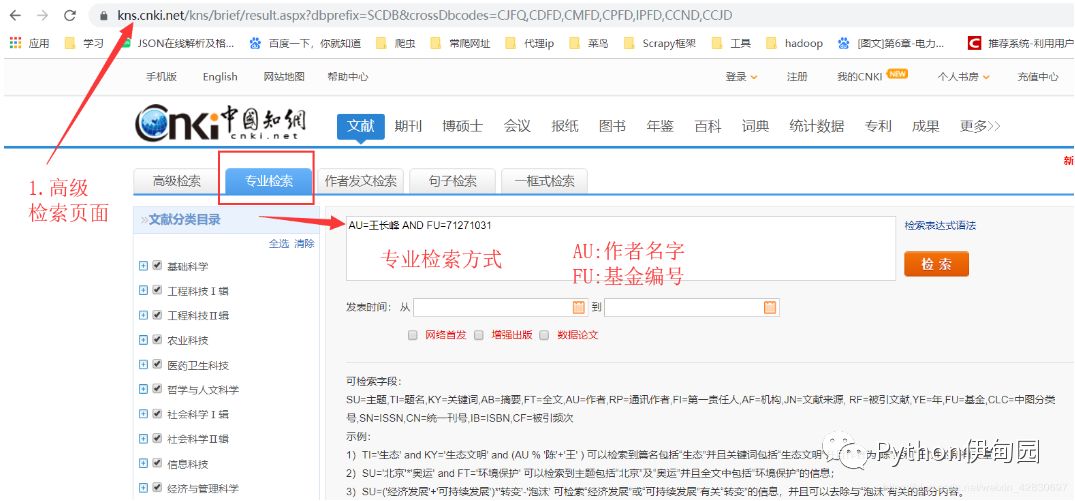
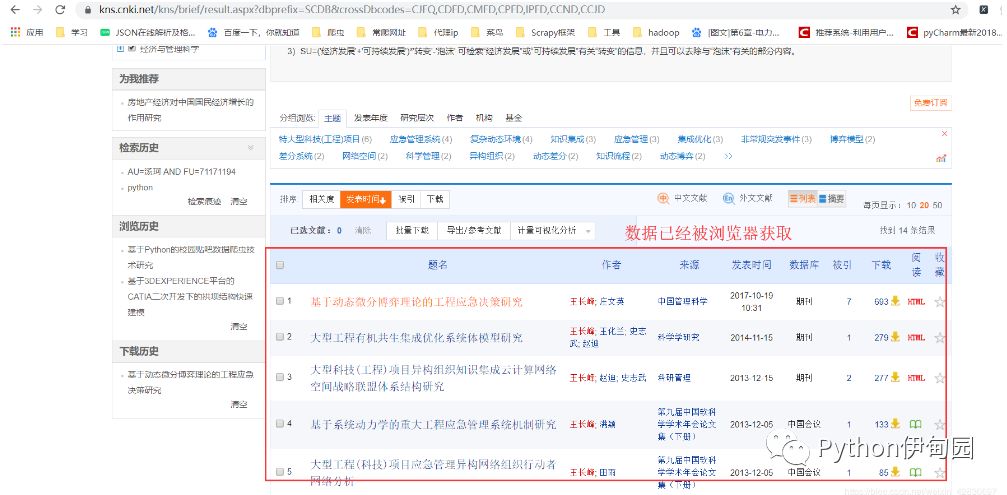
1.来到高级检索页面,以【AU=王长峰 AND FU=71271031】为例检索,结果如下:
2.利用Xpath语法尝试获取这些数据,却发现一无所获。
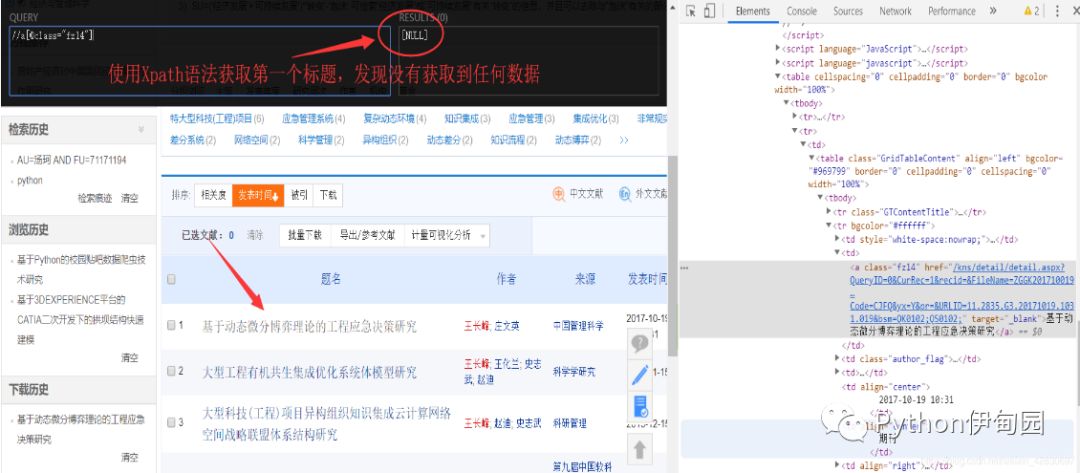
3.按照常理来说,即使是动态网页也可以利用Xpath语法提取到数据,只是在Python里面获取不到而已&#x