目录
三. 没覆盖索引时,is not null、not like导致索引失效
九、sql 中 where 条件中 in 的参数过多导致数据库放弃走索引
一. 联合索引导致索引失败情况
- 最左前缀法则:就是在联合主键中第一个索引会被使用,如果没有用到最左一个索引则其他索引会失效,例如:组合索引(id,name,sex) 使用的时候,可以id 或者id,name . 禁止直接name,或者sex.会导致联合索引失败 。
- 注意: id, name,sex 这三个字段填写顺序不会有影响, mysql会自动优化成最左匹配的顺序2. 下面两条查询会索引失效
代码示例
<!-- 这三条会命中索引 -->
explain select SQL_NO_CACHE * from `user_test` where uid=10 ;
explain select SQL_NO_CACHE * from `user_test` where uid=10 and name='张三';
explain select SQL_NO_CACHE * from `user_test` where uid=10 and name='张三' and phone='13527748096';
----------------------------------------------------------------------------------
<!-- 这两条不会走索引(因为没有遵循最左前缀原则) -->
explain select SQL_NO_CACHE * from `user_test` where name='张三' and phone='13527748096';
explain select SQL_NO_CACHE * from `user_test` where name='张三';
----------------------------------------------------------------------------------
<!-- 这一条sql由于有最左前缀索引id 所以索引部分成功,部分失效,id字段索引使用成功 -->
explain select SQL_NO_CACHE * from `user_test` where uid=10 and phone='13527748096';二. like 查询导致索引失效情况
不考虑索引覆盖问题
like模糊查询导致索引失效的情况,根据 % 号使用位置导致索引失效情况
<!-- like 匹配字段前加 % 索引失效 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM t2 where uuid LIKE "%u"
<!-- like 匹配字段前后都加 % 索引失效 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM t2 where uuid LIKE "%u%"
<!-- like 匹配字段后加 % 走索引 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM t2 where uuid LIKE "u%"三. 没覆盖索引时,is not null、not like导致索引失效
因为is not null、not like不能精准匹配,全表扫描二级索引树再回表效率不如直接全表扫描聚簇索引树。但使用覆盖索引时,联合索引数据量小,加载到内存所需空间比聚簇索引树小,且不需要回表,索引效率优于全表扫描聚簇索引树。覆盖索引:一个索引包含了满足查询结果的数据就叫做覆盖索引,不需要回表等操作。
is null 可以使用索引
is not null 无法使用索引
原因:
在进行索引扫描时,MySQL 会优先利用索引中已经存在的值进行查询,在查询时直接跳过为 NULL 的那些行。但是,如果使用了 IS NOT NULL 条件,那么 MySQL 无法在索引中找到 NULL 值,也就是说,MySQL 无法像前面那样跳过那些为 NULL 的行,只能扫描整张表来找到符合条件的行,因此无法使用索引。
解决方案:
设计数据库的时候就将字段设置为 NOT NULL 约束
将 INT 类型的字段,默认值设置为0。
将字符类型的默认值设置为空字符串('')。
索引失效
<!-- IS NOT NULL: 无法触发索引 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM t2 where uuid IS NOT NULL命中索引
<!-- IS NULL 会命中索引 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM t2 where uuid IS NULL四. 计算、函数导致索引失效
- 代码示例
<!-- 函数导致索引失效,不走索引 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test tt WHERE LEFT(tt.name,3) = 'l';
<!-- 索引优化成like,走索引 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test tt WHERE tt.name LIKE 'n%';
<!-- 计算函数导致索引失效 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test tt WHERE tt.id+1 = 9;五. 类型转换导致索引失效
<!-- 手动类型转换,通过调用函数,导致索引失效 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test WHERE name = CAST(22 as CHAR);
<!-- 自动类型转换导致索引失效。name字段类型是varchar,你赋值成数字它会默认转成字符串导致索引失败 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test WHERE name = 123;
<!-- 索引优化成目标字符串,走索引 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test WHERE name = '123';六. 范围条件右边的列索引失效
场景:(a,b,c)联合索引,查询条件a,b,c,如果b使用了范围查询,那么b右边的c索引失效
解决办法:新建联合索引(a,c,b)或(c,a,b),把需要范围查询的字段放在最后
- 范围包括:(<) (<=) (>) (>=) 和 between
代码示例
<!-- 创建联合索引 -->
CREATE INDEX table_test_index ON table_test(age,height,name);
<!-- 都不使用范围查询,使用所有索引 key_len为205 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test tt WHERE tt.age = 34 AND tt.height = 178 AND tt.name = 'ning';
<!-- 联合索引第一个参数age使用范围查询,全部索引失效。ken_len为0,全表扫描 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test tt WHERE tt.age > 20 AND tt.height = 4 AND tt.name = 'liu';
<!-- 联合索引第二个参数height使用范围查询,name索引失效。key_len为10,即只用age和height -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test tt WHERE tt.age = 30 AND tt.height > 3 AND tt.name = 'liu';
<!-- 联合索引第三个参数name使用范围查询,索引都生效。key_len为205 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test tt WHERE tt.age = 30 AND tt.height = 4 AND tt.name > 'liu';
七. 没覆盖索引时,“不等于”导致索引失效
因为“不等于”不能精准匹配,全表扫描二级索引树再回表效率不如直接全表扫描聚簇索引树。但使用覆盖索引时,联合索引数据量小,加载到内存所需空间比聚簇索引树小,且不需要回表,索引效率优于全表扫描聚簇索引树。
没覆盖索引的情况下,使用“不等于”导致索引失效。因为如果使用索引,则需要依次遍历非聚簇索引B+树里所有叶节点,时间复杂度O(n),找到记录后还要回表,加在一起效率不如全表扫描,所以查询优化器就选择全表扫描了。
覆盖索引:一个索引包含了满足查询结果的数据就叫做覆盖索引,不需要回表等操作。
不等于符号:!= 或者<>,这两个符号意义相同。
代码示例
<!-- 查所有字段,并且使用“不等于”,索引失效 -->
EXPLAIN select SQL_NO_CACHE * FROM table_test WHERE age <> 20;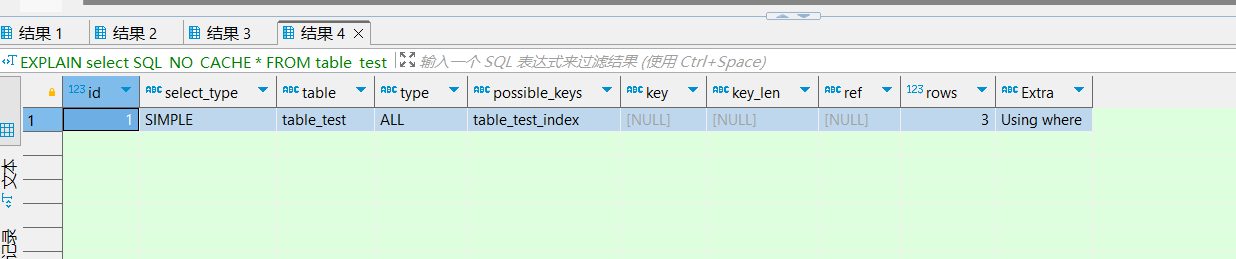
八. “OR”前后存在非索引列,导致索引失效
在MySQL中,使用OR条件不一定会导致索引失效,但在某些情况下可能会影响索引的使用,从而影响查询性能。以下是一些可能导致索引失效的情况:
-
索引选择性:如果
OR条件连接的两个或多个列中,只有一个或没有列被索引,MySQL优化器可能无法有效使用索引。 -
查询优化器决策:MySQL查询优化器会根据查询条件和索引的情况来选择最优的查询计划。如果优化器认为全表扫描比使用索引更快,尤其是在数据分布不均匀或存在大量重复值的情况下,可能会选择不使用索引。
-
索引类型不匹配:即使列已被索引,但由于索引类型与查询条件不匹配,也可能导致索引失效。
-
复合索引使用:对于复合索引,如果
OR条件跨越了复合索引的多个列,且没有遵循最左前缀原则,可能导致索引失效。 -
范围查询和
OR结合:如果OR条件中包含范围查询,且这些范围查询不是独立的,可能会影响索引的使用。
解决方法:
-
创建复合索引:针对经常使用
OR条件的列,可以创建一个复合索引来提高查询性能。 -
重写查询:有时将复杂的
OR条件重写为UNION操作可以更好地利用索引。 -
使用
EXPLAIN分析:使用EXPLAIN命令来分析查询的执行计划,查看是否使用了索引以及如何优化查询。 -
数据规范化:在数据库设计阶段,通过数据规范化来减少冗余数据和重复值,可以提高索引的选择性。
-
监控和调优:定期监控数据库的性能指标,通过监控工具发现性能瓶颈并进行相应的调优。
九、sql 中 where 条件中 in 的参数过多导致数据库放弃走索引
- in 中参数过多导致全表检索
<!-- in中参数过多导致全表检索 -->
EXPLAIN SELECT SQL_NO_CACHE * FROM table_test WHERE ark in ('');十. 不同字符集导致索引失败,建议utf8mb4
不同的字符集进行比较前需要进行转换会造成索引失效。
数据库和表的字符集统一使用utf8mb4。统一使用utf8mb4( 5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。
十一. 总结
- 尽量全值匹配:查询age and classId and name时,(age,classId,name)索引比(age,classId)快。
- 考虑最左前缀:联合索引把频繁查询的列放左。索引(a,b,c),只能查(a,b,c),(a,b),(a)。
- 主键尽量自增:如果主键不自增,需要查找目标位置再插入,并且如果目标位置所在数据页满了就必须得分页,造成性能损耗。
- 计算、函数导致索引失效:计算例如where num+1=2,函数例如abs(num)取绝对值
- 类型转换导致索引失效:例如name=123,而不是name='123'。又例如使用了不同字符集。
- 范围条件右边的列索引失效:例如(a,b,c)联合索引,查询条件a,b,c,如果b使用了范围查询,那么b右边的c索引失效。建议把需要范围查询的字段放在最后。范围包括:(<) (<=) (>) (>=) 和 between。
- 没覆盖索引时,“不等于”导致索引失效:因为“不等于”不能精准匹配,全表扫描二级索引树再回表效率不如直接全表扫描聚簇索引树。但使用覆盖索引时,联合索引数据量小,加载到内存所需空间比聚簇索引树小,且不需要回表,索引效率优于全表扫描聚簇索引树。覆盖索引:一个索引包含了满足查询结果的数据就叫做覆盖索引,不需要回表等操作。
- 没覆盖索引时,左模糊查询导致索引失效:例如LIKE '%abc'。因为字符串开头都不能精准匹配。跟上面一个道理。
- 没覆盖索引时,is not null、not like无法使用索引:因为不能精准匹配。跟上面一个道理。
- “OR”前后存在非索引列,导致索引失效:MySQL里,即使or左边条件满足,右边条件依然要进行判断。
- 不同字符集导致索引失败:建议utf8mb4,不同的字符集进行比较前需要进行 转换 会造成索引失效。
原文链接:https://blog.csdn.net/qq_40991313/article/details/130779528