
我们在上一篇《向Hadoop Say Hello——初识Hadoop》中已经对HDFS进行了简单介绍,还不清楚HDFS是什么的朋友可以点击上面链接先看上一篇,在这一篇中我们聚焦HDFS,从HDFS的设计架构和重要概念开始学习,然后会学习HDFS的命令行操作以及Java Api操作。
特别提示:本文所进行的演示都是在hadoop-2.6.0-cdh5.15.1的版本进行的
一、HDFS概述
HDFS 是 Hadoop Distribute File System,Hadoop分布式文件系统的简称。这个文件系统是一个适用于大的数据集的支持高吞吐和高容错的运行在通用(廉价)机上的分布式文件系统。
设计目标
- 故障的快速检测和自动恢复(容错)
分布式的文件系统将由成百上千台的机器共同组成集群,在集群中每一台机器都可能出现故障,当出现部分机器出现故障时,保证服务的正常提供是一个重要的工作,因此故障的快递检测和自动快速恢复是 HDFS 的核心设计目标
- 流式数据访问(高吞吐)
HDFS 的设计是为了存储大文件,它更注重数据访问的吞吐量,对访问的延时性要求较低,它不适用于低延时的场景,为了保证大吞吐量的数据访问,HDFS 被设计成了更适合批量处理,且以流式读取数据的方式
- 存储大的数据集
通常情况下在HDFS上运行的应用都具有大的数据集,一个典型的 HDFS 文件大小是 GB 到 TB 的级别,在实际中超大型集群的HDFS中文件的大小也可能达到PB级别
- 简化数据一致性模型
大部分运行在 HDFS 上的应用对文件都是"一次写入,多次读出"访问模型。所以HDFS就作出了一个文件一旦创建、写入成功后就不需要再修改了的假设,这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能(后文会分析HDFS的数据一致性问题)
- 移动计算的位置比移动数据的位置更划算
由于网络带宽是一个有限资源,一个计算任务的运行,当计算数据离计算逻辑所在节点越近这个计算任务执行的就越高效,数据量越大这种特点就越明显。所以在 HDFS 中设计了提供给应用将计算逻辑移动到数据附近这样的接口
- 可移植性
为了方便HDFS作为大规模数据应用平台得到广泛应用,HDFS被设计成了一个易于从一个平台移植到另一个平台的数据应用系统
二、HDFS中一些概念
Block(块)
HDFS和一般的磁盘文件系统一样,也有Block的概念,和一般文件相同的是,用户存储的文件都会被按照Block Size被拆分存储,但与一般磁盘文件系统不同的是,当一个文件的实际大小比Block Size小的时候,它不会占用Block Size大小的物理空间。这句话如何理解呢?
咱们举个栗子,HDFS的默认块大小是128M,假设现在有一个200M的文件那么存储在HDFS上时就会被拆分成两个Block存储,分别是一个128M的块和一个72M的块,且他们占用的物理空间也是200M。而在一般的磁盘文件系统中块的大小是4K,不同点就是如果一个文件大小是5K那么它存储在磁盘文件系统中所占用的物理空间大小是8k,在一般磁盘文件系统中文件大小没有超过一个块大小时,是按照一个块的大小占用空间。
文件系统命名空间
HDFS和传统的文件系统一样支持分层的文件组织结构。支持常用的文件创建,删除、移动,重命名等操作,并且也支持用户配额和访问权限控制。现有的HDFS实现不支持硬链接或软链接。
副本机制
为了容错,每个文件被拆分后的 Block 都是以副本的方式存储,每个文件的块大小和以及复制的副本系数都是可以配置,HDFS 默认是3副本配置。
在集群中副本的放置位置对HDFS的可靠性和性能都有很大的影响,所以优化副本摆放策略在一个大型集群中显得尤为重要。在HDFS中是使用一种机架感知的副本放置策略,这种策略是基于提高数据可靠性、可用性和网络带宽利用率而设计的一种策略
在机架感知副本策略下,当副本系数是3时,HDFS的文件副本放置方式如下:如果写入程序位于数据节点上,则将一个副本放在本地计算机上,否则放在与写入程序位于同一机架中的随机数据节点上,另一个副本放在不同(远程)机架中的节点上,最后一个放在同一远程机架中的不同节点上。
二、HDFS的架构
HDFS 是一个主从架构的服务。一个 HDFS 集群包括一个 NameNode 节点、一个 SecondaryNameNode 节点(非必须)和多个 DataNode 节点。
NameNode
NameNode是一个主节点,是所有 HDFS 元数据的决策器和存储库,它管理文件系统名称空间、确定块到数据节点的映射,并且控制客户端对文件的访问。但是 NameNode 从不与用户数据直接交互,与用户数据交互的工作都由DataNode 来做。
DataNode
DataNode是管理它们运行的节点的数据存储,通常一个集群中每个节点一个都有一个 DataNode。DataNode 负责为来自客户端的读写请求提供服务,同时它还会根据 NameNode 的指令执行块创建、删除和复制。
SecondaryNameNode
SecondaryNameNode是NameNode的一个冷备份,可以看做是一个CheckPoint,它主要负责合并 fsimage 和 fsedits,并推送给 NameNode。它也会维护一个合并后的 Namespace Image 副本, 可用于在 NameNode 故障后恢复数据
架构图
接下来咱们可以看下面这张图(图片来自Hadoop官网),这就是HDFS的一个架构图
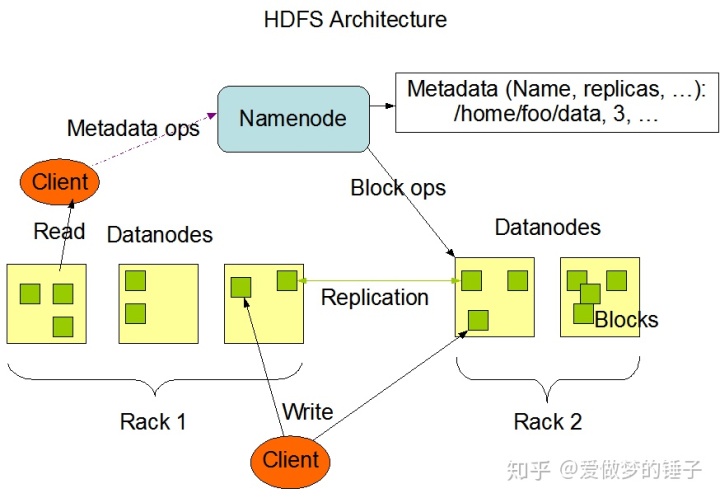
图中的几个要点:
- NameNode管理着Metadata(元数据)
- 客户端client对元数据的操作是指向NameNode,对用户数据的读写是通过DataNode
- NameNode向DataNode发送Block的操作命令
- 一块的副本被存储在不同的机架中
HDFS Federation
通过了解架构大家是否发现了一个问题?在 HDFS 的主从架构中 NameNode 成了集群扩大的瓶颈,随着集群增大和文件数据量增多,单个 NameNode 性能就无法满足需求,这也就意味着,HDFS 集群的大小是受 NameNode 节点约束的。
HDFS Federation( HDFS 联邦)就是为了解决这种问题,它提供了一种横向扩展 NameNode 的方式。在 Federation 模式中,每个 NameNode 管理命名空间的一部分,同时也各自维护一个 Block Pool,保存 Block 的节点映射信息。各 NameNode 节点之间是独立的,一个节点的失败不会导致其他节点管理的文件不可用,同时失败的节点所管理的文件数据也就不可访问,所以 HDFS Federation 只是解决 HDFS 的拓展问题,并不是解决单点故障问题的。
四、HDFS的安装和使用
在刚开始学习的过程中建议先使用单机版,避免因为集群的问题提高了学习门槛,打击自己学习信心,在熟练其使用和原理后在使用集群也不迟。
HDFS的安装可以参照《教你安装单机版Hadoop》,这篇文章里面有讲述HFDS的安装。
HDFS安装成功后如下操作
- 第一次启动前需要对文件系统进行格式化:
${HADOOP_HOME}/bin/hdfs name -format - 启动HDFS:
${HADOOP_HOME}/sbin/start-dfs.sh
在HDFS启动后,我们就可以访问 HDFS 的 Web 页面,查看HDFS的信息,HDFS web 访问默认端口是50070,浏览器打开效果如下:
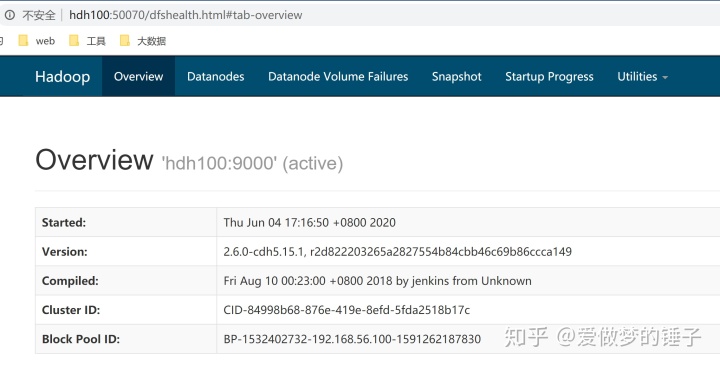
首页是一个Overview概览信息,里面包括了集群基本信息(Hadoop版本、集群ID、Block Pool ID等)、存储摘要以及NameNode的运行状态等。
在顶部第二个主菜单下是DataNode的信息,页面效果如下:
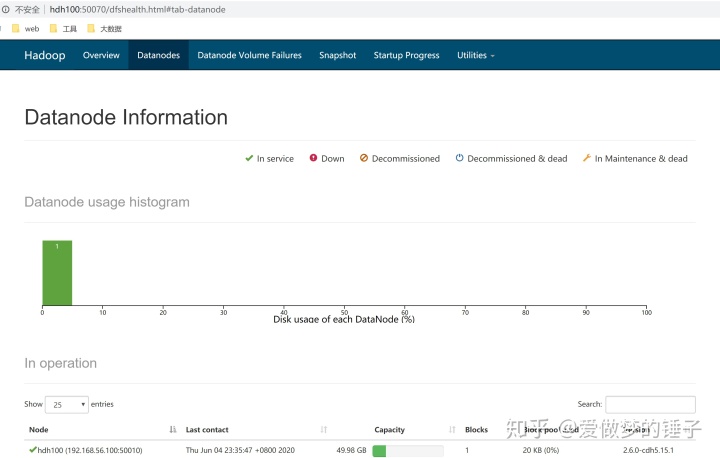
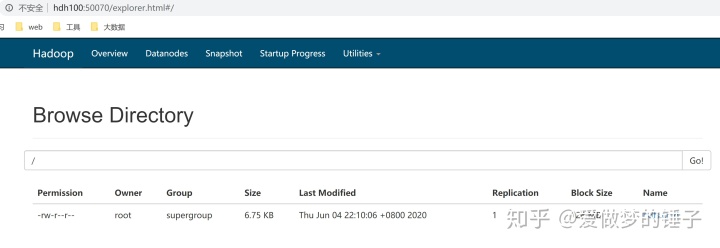
在主菜单的最后一项Utilities下面有一个Browse the file system,这个页面就是HDFS的一个文件浏览器,可以查看在HDFS上存储的文件,效果如下:
四、HDFS基本操作(命令和Java Api)
HDFS 包含的常用操作如下
命令操作
HDFS的命令有两种使用方式
- 通过hadoop命令:
hadoop fs [options],eg:./hadoop fs -ls / - 通过hdfs命令:
hdfs dfs [options],eg:./hdfs dfs -ls /
其实两种方法调用的是相同的脚本代码。
常用命令中有一部分是类似于Linux的文件管理命令,对于这一部分命令可以类比Linux中的使用,我们就不讲解了,我们只把HDFS中一些特别的命令学习一下。
类似Linux系统的文件管理命令有:ls, cat, chgrp, chmod, chown, cp, df, du, find, mkdir, mv, rm, rmdir, tail, test
我们学习一下这些命令:
- appendToFile:将一个或者多个文件添加到HDFS系统中
- copyFromLocal:将本地文件拷贝到HDFS
- count:统计hdfs对应路径下的目录个数,文件个数,文件总计大小
- expunge:从垃圾箱目录永久删除超过保留阈值的检查点中的文件,并创建新检查点
- get:从HDFS上传输文件到本地
- getmerge:把hdfs指定目录下的所有文件内容合并到本地linux的文件中
- moveFromLocal:把本地文件移动到HDFS上,本地文件会被删除
- moveToLocal:把HDFS文件移动到本地,HDFS文件会被删除
- put:将文件上传到HDFS上
- setrep:修改文件或目录副本数
- stat:输出指定目录的信息,可设置格式化输出(%b: 文件大小,%n: 文件名,%o: 块大小,%r: 副本个数,%y, %Y: 修改日期)
- text:格式化输出文件的内容,允许的格式化包括zip,和 TextRecordInputStream
- touchz:在指定目录创建一个新文件,如果文件存在,则创建失败
Hadoop的文件系统
在使用Java的Api前我们现先了解一下Hadoop的抽象文件系统
org.apache.hadoop.fs.FileSystem 是Hadoop中抽象的一个文件系统,我们今天所使用的HDFS只是这个抽象的文件系统的实现之一,HDFS提供了几个主要的实现包括:LocalFileSystem、 DistributeFileSystem、 WebHdfsFileSystem、 HarFileSystem、 ViewFileSystem、 FtpFileSystem、 S3AFileSystem
- LocalFileSystem:对本地文件系统的一个实现
- DistributeFileSystem:HDFS的实现
- WebHdfsFileSystem:通过Http请求提供对HDFS的认证和读写操作的实现,还有一个SWebHdfsFileSystem是基于Https的实现
- HarFileSystem:这是Hadoop存档文件系统的实现,归档后的多个文件可以进行压缩成一个文件
- ViewFileSystem:视图文件系统,只是逻辑上唯一的一个视图文件系统,主要是来做HDFS Federation的时候,将不同集群中的文件系统进行映射,在逻辑上形成一个文件系统,在客户端屏蔽底层细节
- FtpFileSystem:基于ftp协议的一个文件系统实现
- S3AFileSystem: 基于S3A协议的一个文件系统实现,S3是Amazon的对象存储服务
Java Api
- pom中加入hadoop-client依赖
<repositories>
<!--使用的Hadoop是CDH版本的需要引用一下cloudera的仓库库-->
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!--Hadoop客户端-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.15.1</version>
</dependency>
</dependencies>- 一个简单的演示代码
package site.teamo.learning.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.Closeable;
import java.io.IOException;
public class HdfsApp {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
FileSystem fs = null;
try {
//创建配置,设置Hdfs的地址信息
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://hdh100:8020");
//在系统环境变量设置使用的用户名
System.setProperty("HADOOP_USER_NAME", "root");
//打开一个文件系统
fs = FileSystem.get(configuration);
//创建一个目录
fs.mkdirs(new Path("/dream-hammer"));
//判断是否是目录
fs.isDirectory(new Path("/dream-hammer"));
//创建一个文件dream1.txt,返回值boolean类型,true:创建成功;false:创建失败
fs.createNewFile(new Path("/dream-hammer/dream1.txt"));
//判断文件是否存在,返回值是boolean类型,true:存在;false:不存在
fs.exists(new Path("/dream-hammer/dream1.txt"));
//向文件追加内容
FSDataOutputStream out = null;
try {
out = fs.append(new Path("/dream-hammer/dream1.txt"));
out.writeUTF("dream-hammer");
out.flush();
out.close();
} finally {
close(out);
}
//打开dream1的输入流
FSDataInputStream in = null;
try {
in = fs.open(new Path("/dream-hammer/dream1.txt"));
System.out.println(in.readUTF());
in.close();
} finally {
close(in);
}
//删除目录和文件
fs.delete(new Path("/dream-hammer"), true);
} finally {
close(fs);
}
}
/**
* 关闭流,释放资源
* @param closeable
*/
public static void close(Closeable closeable) {
if (closeable != null) {
try {
closeable.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}总结:这篇文章主要是对HDFS的基础理论知识进行了介绍和说明,同时也介绍了HDFS的基本使用,比较基础易懂,也适合刚接触HDFS的朋友阅读学习,锤子会在下一篇文章里面介绍 HDFS读写数据流程,这个属于更深层次的东西了,关注【爱做梦的锤子】,一起学习进步
> 文章欢迎转载,转载请注明出处,个人公众号【**爱做梦的锤子**】,全网同id,个站 [Hope for a Miracle](Hope for a Miracle),欢迎关注,里面会分享更多有用知识,还有我的私密照片