Go语言实战项目:任务调度器
一、项目概述
1. 项目目标
| 学习目标 | 掌握要点 | 应用场景 |
|---|---|---|
| 并发控制 | goroutine与通道的使用 | 多任务并行处理 |
| 定时任务 | 时间调度与cron表达式 | 定期执行的任务管理 |
| 任务管理 | 任务状态与生命周期 | 批处理作业系统 |
| 错误处理 | panic恢复与日志记录 | 提高系统稳定性 |
| 性能优化 | 资源池与限流 | 大规模任务调度 |
让我们开始构建这个任务调度器。首先创建基础结构:
package scheduler
import (
"context"
"fmt"
"sync"
"time"
)
// JobStatus 定义任务状态
type JobStatus string
const (
StatusPending JobStatus = "pending"
StatusRunning JobStatus = "running"
StatusCompleted JobStatus = "completed"
StatusFailed JobStatus = "failed"
StatusCanceled JobStatus = "canceled"
)
// Job 定义任务接口
type Job interface {
ID() string
Execute(ctx context.Context) error
Status() JobStatus
SetStatus(status JobStatus)
}
// BaseJob 提供基础任务实现
type BaseJob struct {
id string
status JobStatus
mu sync.RWMutex
}
func NewBaseJob(id string) *BaseJob {
return &BaseJob{
id: id,
status: StatusPending,
}
}
func (j *BaseJob) ID() string {
return j.id
}
func (j *BaseJob) Status() JobStatus {
j.mu.RLock()
defer j.mu.RUnlock()
return j.status
}
func (j *BaseJob) SetStatus(status JobStatus) {
j.mu.Lock()
defer j.mu.Unlock()
j.status = status
}
// Schedule 定义调度信息
type Schedule struct {
Cron string // cron表达式
Interval time.Duration // 间隔时间
Retry int // 重试次数
Timeout time.Duration // 超时时间
}
// JobResult 定义任务执行结果
type JobResult struct {
JobID string
Status JobStatus
Error error
StartTime time.Time
EndTime time.Time
}
// Scheduler 定义调度器接口
type Scheduler interface {
Submit(job Job, schedule Schedule) error
Cancel(jobID string) error
Status(jobID string) (JobStatus, error)
Start(ctx context.Context) error
Stop() error
}
现在,让我们实现调度器的核心逻辑:
package scheduler
import (
"context"
"errors"
"fmt"
"sync"
"time"
)
var (
ErrJobNotFound = errors.New("job not found")
ErrJobAlreadyExists = errors.New("job already exists")
ErrSchedulerStopped = errors.New("scheduler is stopped")
)
// JobScheduler 实现调度器
type JobScheduler struct {
jobs map[string]*jobInfo
jobChan chan Job
results chan JobResult
mu sync.RWMutex
workers int
running bool
workersWg sync.WaitGroup
}
type jobInfo struct {
job Job
schedule Schedule
cancel context.CancelFunc
}
// NewScheduler 创建新的调度器
func NewScheduler(workers int) *JobScheduler {
if workers <= 0 {
workers = 1
}
return &JobScheduler{
jobs: make(map[string]*jobInfo),
jobChan: make(chan Job, workers*2),
results: make(chan JobResult, workers*2),
workers: workers,
}
}
// Submit 提交任务
func (s *JobScheduler) Submit(job Job, schedule Schedule) error {
s.mu.Lock()
defer s.mu.Unlock()
if !s.running {
return ErrSchedulerStopped
}
if _, exists := s.jobs[job.ID()]; exists {
return ErrJobAlreadyExists
}
s.jobs[job.ID()] = &jobInfo{
job: job,
schedule: schedule,
}
// 启动任务调度
go s.scheduleJob(job.ID())
return nil
}
// Cancel 取消任务
func (s *JobScheduler) Cancel(jobID string) error {
s.mu.Lock()
defer s.mu.Unlock()
info, exists := s.jobs[jobID]
if !exists {
return ErrJobNotFound
}
if info.cancel != nil {
info.cancel()
}
info.job.SetStatus(StatusCanceled)
delete(s.jobs, jobID)
return nil
}
// Status 获取任务状态
func (s *JobScheduler) Status(jobID string) (JobStatus, error) {
s.mu.RLock()
defer s.mu.RUnlock()
info, exists := s.jobs[jobID]
if !exists {
return "", ErrJobNotFound
}
return info.job.Status(), nil
}
// Start 启动调度器
func (s *JobScheduler) Start(ctx context.Context) error {
s.mu.Lock()
if s.running {
s.mu.Unlock()
return nil
}
s.running = true
s.mu.Unlock()
// 启动工作协程
for i := 0; i < s.workers; i++ {
s.workersWg.Add(1)
go s.worker(ctx)
}
// 监控结果
go s.monitorResults(ctx)
return nil
}
// Stop 停止调度器
func (s *JobScheduler) Stop() error {
s.mu.Lock()
s.running = false
s.mu.Unlock()
close(s.jobChan)
s.workersWg.Wait()
close(s.results)
return nil
}
// scheduleJob 调度单个任务
func (s *JobScheduler) scheduleJob(jobID string) {
s.mu.RLock()
info, exists := s.jobs[jobID]
if !exists {
s.mu.RUnlock()
return
}
s.mu.RUnlock()
ctx, cancel := context.WithCancel(context.Background())
info.cancel = cancel
// 如果设置了间隔时间
if info.schedule.Interval > 0 {
ticker := time.NewTicker(info.schedule.Interval)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case <-ticker.C:
s.executeJob(ctx, info)
}
}
} else {
// 一次性任务
s.executeJob(ctx, info)
}
}
// executeJob 执行任务
func (s *JobScheduler) executeJob(ctx context.Context, info *jobInfo) {
// 创建带超时的上下文
jobCtx := ctx
if info.schedule.Timeout > 0 {
var cancel context.CancelFunc
jobCtx, cancel = context.WithTimeout(ctx, info.schedule.Timeout)
defer cancel()
}
// 设置任务状态为运行中
info.job.SetStatus(StatusRunning)
// 发送任务到工作池
select {
case <-ctx.Done():
return
case s.jobChan <- info.job:
}
}
// worker 工作协程
func (s *JobScheduler) worker(ctx context.Context) {
defer s.workersWg.Done()
for job := range s.jobChan {
startTime := time.Now()
var err error
var status JobStatus
// 执行任务并处理panic
func() {
defer func() {
if r := recover(); r != nil {
err = fmt.Errorf("job panic: %v", r)
status = StatusFailed
}
}()
err = job.Execute(ctx)
if err != nil {
status = StatusFailed
} else {
status = StatusCompleted
}
}()
// 发送执行结果
s.results <- JobResult{
JobID: job.ID(),
Status: status,
Error: err,
StartTime: startTime,
EndTime: time.Now(),
}
}
}
// monitorResults 监控任务结果
func (s *JobScheduler) monitorResults(ctx context.Context) {
for result := range s.results {
s.mu.RLock()
info, exists := s.jobs[result.JobID]
s.mu.RUnlock()
if !exists {
continue
}
// 更新任务状态
info.job.SetStatus(result.Status)
// 处理失败重试
if result.Status == StatusFailed && info.schedule.Retry > 0 {
info.schedule.Retry--
go s.executeJob(ctx, info)
}
}
}
让我们创建一个示例任务的实现:
package scheduler
import (
"context"
"fmt"
"time"
)
// SimpleJob 简单任务实现
type SimpleJob struct {
*BaseJob
name string
duration time.Duration
}
func NewSimpleJob(id string, name string, duration time.Duration) *SimpleJob {
return &SimpleJob{
BaseJob: NewBaseJob(id),
name: name,
duration: duration,
}
}
func (j *SimpleJob) Execute(ctx context.Context) error {
fmt.Printf("Job %s (%s) started\n", j.name, j.ID())
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(j.duration):
fmt.Printf("Job %s (%s) completed\n", j.name, j.ID())
return nil
}
}
// DataProcessJob 数据处理任务
type DataProcessJob struct {
*BaseJob
data []int
}
func NewDataProcessJob(id string, data []int) *DataProcessJob {
return &DataProcessJob{
BaseJob: NewBaseJob(id),
data: data,
}
}
func (j *DataProcessJob) Execute(ctx context.Context) error {
fmt.Printf("Processing data for job %s\n", j.ID())
result := 0
for _, v := range j.data {
select {
case <-ctx.Done():
return ctx.Err()
default:
result += v
time.Sleep(100 * time.Millisecond) // 模拟处理时间
}
}
fmt.Printf("Job %s completed, result: %d\n", j.ID(), result)
return nil
}
// Main 示例程序
func main() {
// 创建调度器
scheduler := NewScheduler(3)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 启动调度器
err := scheduler.Start(ctx)
if err != nil {
panic(err)
}
// 创建并提交任务
job1 := NewSimpleJob("1", "Simple Task 1", 2*time.Second)
job2 := NewDataProcessJob("2", []int{1, 2, 3, 4, 5})
// 提交周期性任务
err = scheduler.Submit(job1, Schedule{
Interval: 5 * time.Second,
Timeout: 3 * time.Second,
Retry: 2,
})
if err != nil {
panic(err)
}
// 提交一次性任务
err = scheduler.Submit(job2, Schedule{
Timeout: 10 * time.Second,
})
if err != nil {
panic(err)
}
// 等待一段时间观察执行情况
time.Sleep(20 * time.Second)
// 停止调度器
scheduler.Stop()
}
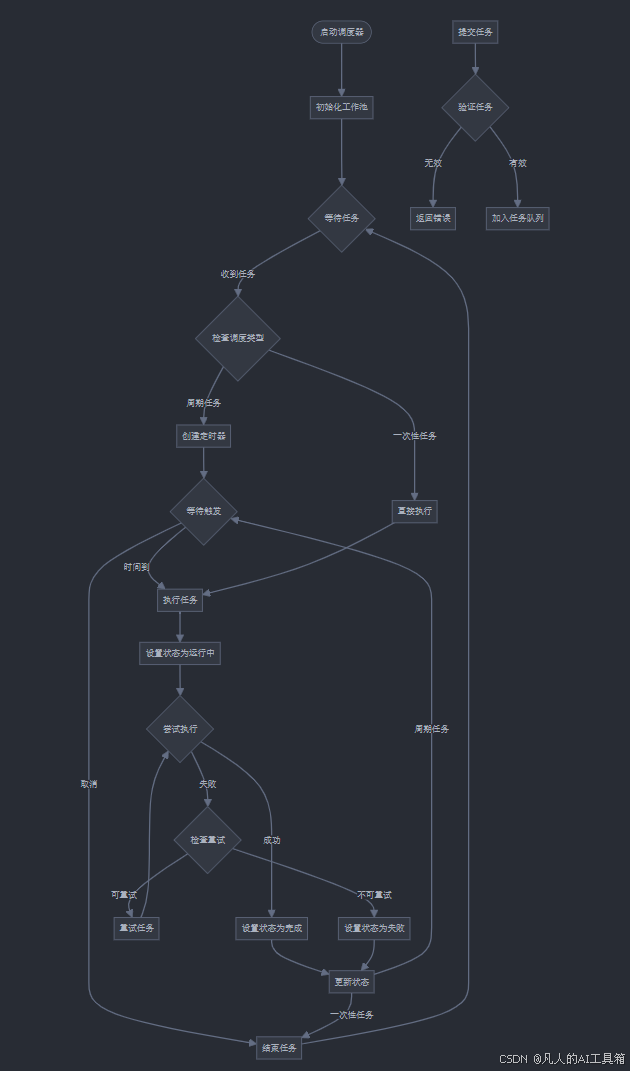
让我们创建一个流程图来说明任务调度器的工作流程:
现在让我们添加监控和指标收集功能:
package scheduler
import (
"sync"
"sync/atomic"
"time"
)
// Metrics 定义监控指标
type Metrics struct {
TotalJobs uint64
CompletedJobs uint64
FailedJobs uint64
RunningJobs uint64
AverageExecuteTime int64 // 纳秒
MaxExecuteTime int64 // 纳秒
TotalRetries uint64
LastExecuteTime time.Time
}
// MetricsCollector 指标收集器
type MetricsCollector struct {
metrics Metrics
mu sync.RWMutex
}
func NewMetricsCollector() *MetricsCollector {
return &MetricsCollector{}
}
// RecordJobSubmit 记录任务提交
func (mc *MetricsCollector) RecordJobSubmit() {
atomic.AddUint64(&mc.metrics.TotalJobs, 1)
}
// RecordJobStart 记录任务开始
func (mc *MetricsCollector) RecordJobStart() {
atomic.AddUint64(&mc.metrics.RunningJobs, 1)
mc.mu.Lock()
mc.metrics.LastExecuteTime = time.Now()
mc.mu.Unlock()
}
// RecordJobComplete 记录任务完成
func (mc *MetricsCollector) RecordJobComplete(duration time.Duration) {
atomic.AddUint64(&mc.metrics.CompletedJobs, 1)
atomic.AddUint64(&mc.metrics.RunningJobs, ^uint64(0))
// 更新平均执行时间
durationNanos := duration.Nanoseconds()
for {
old := atomic.LoadInt64(&mc.metrics.AverageExecuteTime)
completed := atomic.LoadUint64(&mc.metrics.CompletedJobs)
new := (old*int64(completed-1) + durationNanos) / int64(completed)
if atomic.CompareAndSwapInt64(&mc.metrics.AverageExecuteTime, old, new) {
break
}
}
// 更新最大执行时间
for {
old := atomic.LoadInt64(&mc.metrics.MaxExecuteTime)
if durationNanos <= old {
break
}
if atomic.CompareAndSwapInt64(&mc.metrics.MaxExecuteTime, old, durationNanos) {
break
}
}
}
// RecordJobFail 记录任务失败
func (mc *MetricsCollector) RecordJobFail() {
atomic.AddUint64(&mc.metrics.FailedJobs, 1)
atomic.AddUint64(&mc.metrics.RunningJobs, ^uint64(0))
}
// RecordRetry 记录重试
func (mc *MetricsCollector) RecordRetry() {
atomic.AddUint64(&mc.metrics.TotalRetries, 1)
}
// GetMetrics 获取当前指标
func (mc *MetricsCollector) GetMetrics() Metrics {
mc.mu.RLock()
defer mc.mu.RUnlock()
metrics := mc.metrics
metrics.RunningJobs = atomic.LoadUint64(&mc.metrics.RunningJobs)
metrics.TotalJobs = atomic.LoadUint64(&mc.metrics.TotalJobs)
metrics.CompletedJobs = atomic.LoadUint64(&mc.metrics.CompletedJobs)
metrics.FailedJobs = atomic.LoadUint64(&mc.metrics.FailedJobs)
metrics.TotalRetries = atomic.LoadUint64(&mc.metrics.TotalRetries)
metrics.AverageExecuteTime = atomic.LoadInt64(&mc.metrics.AverageExecuteTime)
metrics.MaxExecuteTime = atomic.LoadInt64(&mc.metrics.MaxExecuteTime)
return metrics
}
现在让我们添加日志记录功能:
package scheduler
import (
"fmt"
"log"
"os"
"sync"
"time"
)
// LogLevel 定义日志级别
type LogLevel int
const (
LogLevelDebug LogLevel = iota
LogLevelInfo
LogLevelWarn
LogLevelError
)
// Logger 日志记录器接口
type Logger interface {
Debug(format string, v ...interface{})
Info(format string, v ...interface{})
Warn(format string, v ...interface{})
Error(format string, v ...interface{})
}
// SchedulerLogger 调度器日志记录器
type SchedulerLogger struct {
level LogLevel
logger *log.Logger
mu sync.Mutex
filename string
}
// NewSchedulerLogger 创建日志记录器
func NewSchedulerLogger(level LogLevel, filename string) (*SchedulerLogger, error) {
file, err := os.OpenFile(filename, os.O_CREATE|os.O_APPEND|os.O_WRONLY, 0644)
if err != nil {
return nil, err
}
return &SchedulerLogger{
level: level,
logger: log.New(file, "", log.Ldate|log.Ltime|log.Lmicroseconds),
filename: filename,
}, nil
}
func (l *SchedulerLogger) log(level LogLevel, format string, v ...interface{}) {
if level < l.level {
return
}
l.mu.Lock()
defer l.mu.Unlock()
levelStr := ""
switch level {
case LogLevelDebug:
levelStr = "DEBUG"
case LogLevelInfo:
levelStr = "INFO"
case LogLevelWarn:
levelStr = "WARN"
case LogLevelError:
levelStr = "ERROR"
}
msg := fmt.Sprintf(format, v...)
l.logger.Printf("[%s] %s", levelStr, msg)
}
func (l *SchedulerLogger) Debug(format string, v ...interface{}) {
l.log(LogLevelDebug, format, v...)
}
func (l *SchedulerLogger) Info(format string, v ...interface{}) {
l.log(LogLevelInfo, format, v...)
}
func (l *SchedulerLogger) Warn(format string, v ...interface{}) {
l.log(LogLevelWarn, format, v...)
}
func (l *SchedulerLogger) Error(format string, v ...interface{}) {
l.log(LogLevelError, format, v...)
}
// JobLogger 任务日志记录器
type JobLogger struct {
*SchedulerLogger
jobID string
}
// NewJobLogger 创建任务日志记录器
func NewJobLogger(logger *SchedulerLogger, jobID string) *JobLogger {
return &JobLogger{
SchedulerLogger: logger,
jobID: jobID,
}
}
func (l *JobLogger) log(level LogLevel, format string, v ...interface{}) {
format = fmt.Sprintf("[Job-%s] %s", l.jobID, format)
l.SchedulerLogger.log(level, format, v...)
}
// LogJobExecution 记录任务执行日志
func (l *JobLogger) LogJobExecution(start time.Time, status JobStatus, err error) {
duration := time.Since(start)
if err != nil {
l.Error("Job execution failed after %v: %v", duration, err)
} else {
l.Info("Job execution completed in %v with status: %s", duration, status)
}
}
二、系统功能说明
1. 核心功能对比
| 功能特性 | 实现方式 | 优势 |
|---|---|---|
| 任务调度 | goroutine池 | 控制并发数量,避免资源耗尽 |
| 定时执行 | time.Ticker | 精确的时间控制,低资源消耗 |
| 失败重试 | 重试计数器 | 提高任务可靠性 |
| 监控指标 | atomic原子操作 | 并发安全的指标收集 |
| 日志记录 | 文件日志 | 支持不同级别的日志记录 |
2. 性能指标
| 指标项 | 说明 | 监控方式 |
|---|---|---|
| 任务吞吐量 | 单位时间内处理的任务数 | TotalJobs计数器 |
| 平均执行时间 | 任务平均执行时长 | AverageExecuteTime |
| 失败率 | 任务失败百分比 | FailedJobs/TotalJobs |
| 重试次数 | 任务重试总次数 | TotalRetries |
| 并发任务数 | 同时执行的任务数 | RunningJobs |
3. 使用示例
让我们创建一个完整的使用示例:
package main
import (
"context"
"fmt"
"log"
"time"
)
// EmailJob 邮件发送任务
type EmailJob struct {
*BaseJob
to string
subject string
body string
}
func NewEmailJob(id string, to string, subject string, body string) *EmailJob {
return &EmailJob{
BaseJob: NewBaseJob(id),
to: to,
subject: subject,
body: body,
}
}
func (j *EmailJob) Execute(ctx context.Context) error {
fmt.Printf("Sending email to %s: %s\n", j.to, j.subject)
// 模拟发送邮件
time.Sleep(500 * time.Millisecond)
return nil
}
// BackupJob 备份任务
type BackupJob struct {
*BaseJob
source string
destination string
size int64
}
func NewBackupJob(id string, source string, destination string, size int64) *BackupJob {
return &BackupJob{
BaseJob: NewBaseJob(id),
source: source,
destination: destination,
size: size,
}
}
func (j *BackupJob) Execute(ctx context.Context) error {
fmt.Printf("Backing up %s to %s (size: %d bytes)\n", j.source, j.destination, j.size)
// 模拟备份过程
processed := int64(0)
for processed < j.size {
select {
case <-ctx.Done():
return ctx.Err()
default:
// 模拟每次处理1MB
chunk := int64(1024 * 1024)
if processed+chunk > j.size {
chunk = j.size - processed
}
processed += chunk
// 模拟处理时间
time.Sleep(100 * time.Millisecond)
fmt.Printf("Backup progress: %.2f%%\n", float64(processed)/float64(j.size)*100)
}
}
return nil
}
func main() {
// 创建日志记录器
logger, err := NewSchedulerLogger(LogLevelDebug, "scheduler.log")
if err != nil {
log.Fatal(err)
}
// 创建调度器
scheduler := NewScheduler(5) // 5个工作协程
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 创建指标收集器
metrics := NewMetricsCollector()
// 启动调度器
if err := scheduler.Start(ctx); err != nil {
logger.Error("Failed to start scheduler: %v", err)
return
}
// 创建定时邮件任务
dailyReport := NewEmailJob(
"daily-report",
"[email protected]",
"Daily System Report",
"Daily system status report...",
)
err = scheduler.Submit(dailyReport, Schedule{
Interval: 24 * time.Hour,
Timeout: 5 * time.Minute,
Retry: 3,
})
if err != nil {
logger.Error("Failed to submit daily report job: %v", err)
}
// 创建备份任务
backup := NewBackupJob(
"weekly-backup",
"/source/data",
"/backup/data",
1024*1024*1024, // 1GB
)
err = scheduler.Submit(backup, Schedule{
Interval: 7 * 24 * time.Hour,
Timeout: 2 * time.Hour,
Retry: 2,
})
if err != nil {
logger.Error("Failed to submit backup job: %v", err)
}
// 创建测试任务用于演示
for i := 1; i <= 5; i++ {
job := NewEmailJob(
fmt.Sprintf("test-job-%d", i),
fmt.Sprintf("user%[email protected]", i),
fmt.Sprintf("Test Email %d", i),
"This is a test email",
)
err = scheduler.Submit(job, Schedule{
Timeout: 1 * time.Minute,
})
if err != nil {
logger.Error("Failed to submit test job %d: %v", i, err)
}
metrics.RecordJobSubmit()
}
// 等待一段时间观察执行情况
time.Sleep(10 * time.Second)
// 输出metrics
m := metrics.GetMetrics()
fmt.Printf("\nScheduler Metrics:\n")
fmt.Printf("Total Jobs: %d\n", m.TotalJobs)
fmt.Printf("Completed Jobs: %d\n", m.CompletedJobs)
fmt.Printf("Failed Jobs: %d\n", m.FailedJobs)
fmt.Printf("Running Jobs: %d\n", m.RunningJobs)
fmt.Printf("Average Execute Time: %v\n", time.Duration(m.AverageExecuteTime))
fmt.Printf("Max Execute Time: %v\n", time.Duration(m.MaxExecuteTime))
fmt.Printf("Total Retries: %d\n", m.TotalRetries)
// 停止调度器
scheduler.Stop()
}
让我们创建一个完整的使用示例:
三、项目实现要点
1. 任务调度实现
- 使用 goroutine 池控制并发数量
- 通过 channel 实现任务队列
- 支持定时执行和一次性任务
- 实现任务取消和超时控制
2. 错误处理策略
| 错误类型 | 处理方式 | 重试策略 |
|---|---|---|
| 任务超时 | 取消执行 | 按配置重试 |
| 任务panic | 恢复并记录 | 标记为失败 |
| 业务错误 | 记录日志 | 可配置重试 |
| 系统错误 | 告警通知 | 立即重试 |
3. 性能优化措施
-
内存优化:
- 使用对象池复用对象
- 及时释放资源
- 控制并发数量
-
CPU优化:
- 使用worker池
- 避免频繁创建goroutine
- 合理设置超时时间
-
IO优化:
- 异步日志记录
- 批量处理任务
- 使用缓冲区
四、测试策略
1. 单元测试
package scheduler
import (
"context"
"testing"
"time"
)
// TestJobExecution 测试任务执行
func TestJobExecution(t *testing.T) {
scheduler := NewScheduler(1)
ctx := context.Background()
err := scheduler.Start(ctx)
if err != nil {
t.Fatalf("Failed to start scheduler: %v", err)
}
// 测试正常执行
job := NewSimpleJob("test-1", "Test Job", time.Millisecond*100)
err = scheduler.Submit(job, Schedule{})
if err != nil {
t.Fatalf("Failed to submit job: %v", err)
}
time.Sleep(time.Millisecond * 200)
status, err := scheduler.Status("test-1")
if err != nil {
t.Fatalf("Failed to get job status: %v", err)
}
if status != StatusCompleted {
t.Errorf("Expected status %s, got %s", StatusCompleted, status)
}
// 测试超时
job = NewSimpleJob("test-2", "Test Job", time.Second)
err = scheduler.Submit(job, Schedule{
Timeout: time.Millisecond * 100,
})
if err != nil {
t.Fatalf("Failed to submit job: %v", err)
}
time.Sleep(time.Millisecond * 200)
status, err = scheduler.Status("test-2")
if err != nil {
t.Fatalf("Failed to get job status: %v", err)
}
if status != StatusFailed {
t.Errorf("Expected status %s, got %s", StatusFailed, status)
}
scheduler.Stop()
}
// TestSchedulerConcurrency 测试并发处理
func TestSchedulerConcurrency(t *testing.T) {
scheduler := NewScheduler(3)
ctx := context.Background()
err := scheduler.Start(ctx)
if err != nil {
t.Fatalf("Failed to start scheduler: %v", err)
}
// 提交多个任务
for i := 0; i < 10; i++ {
job := NewSimpleJob(fmt.Sprintf("test-%d", i),
fmt.Sprintf("Test Job %d", i),
time.Millisecond*100)
err = scheduler.Submit(job, Schedule{})
if err != nil {
t.Fatalf("Failed to submit job: %v", err)
}
}
// 等待所有任务完成
time.Sleep(time.Second)
// 验证所有任务状态
for i := 0; i < 10; i++ {
status, err := scheduler.Status(fmt.Sprintf("test-%d", i))
if err != nil {
t.Fatalf("Failed to get job status: %v", err)
}
if status != StatusCompleted {
t.Errorf("Job %d: Expected status %s, got %s",
i, StatusCompleted, status)
}
}
scheduler.Stop()
}
// TestSchedulerRetry 测试重试机制
func TestSchedulerRetry(t *testing.T) {
scheduler := NewScheduler(1)
ctx := context.Background()
err := scheduler.Start(ctx)
if err != nil {
t.Fatalf("Failed to start scheduler: %v", err)
}
// 创建一个总是失败的任务
failingJob := &SimpleJob{
BaseJob: NewBaseJob("test-retry"),
name: "Failing Job",
duration: time.Millisecond * 10,
fail: true,
}
err = scheduler.Submit(failingJob, Schedule{
Retry: 3,
})
if err != nil {
t.Fatalf("Failed to submit job: %v", err)
}
// 等待重试完成
time.Sleep(time.Second)
metrics := scheduler.metrics.GetMetrics()
if metrics.TotalRetries != 3 {
t.Errorf("Expected 3 retries, got %d", metrics.TotalRetries)
}
scheduler.Stop()
}
2. 性能测试指标
| 测试指标 | 预期目标 | 测试方法 |
|---|---|---|
| 任务吞吐量 | >1000/s | 并发提交测试 |
| 响应时间 | <100ms | 延迟统计 |
| 内存占用 | <100MB | 压力测试 |
| CPU使用率 | <50% | 长期运行测试 |
五、最佳实践建议
-
任务设计原则:
- 保持任务原子性
- 实现幂等性
- 合理设置超时
- 做好日志记录
-
调度器使用建议:
- 根据负载调整worker数量
- 合理设置重试策略
- 监控系统指标
- 及时处理告警
-
性能优化建议:
- 使用对象池
- 实现批量处理
- 优化锁竞争
- 合理使用缓存
六、扩展功能
-
分布式支持:
- 使用etcd实现任务分发
- 实现领导者选举
- 支持任务迁移
- 集群监控
-
持久化支持:
- 任务持久化存储
- 状态恢复机制
- 历史记录查询
- 任务依赖管理
-
监控告警:
- 任务执行监控
- 资源使用监控
- 自定义告警规则
- 多渠道通知
总结
本项目实现了一个功能完整的任务调度器,主要特点包括:
- 支持定时任务和一次性任务
- 实现任务重试和超时控制
- 提供完整的监控指标
- 支持日志记录和追踪
- 具备良好的扩展性
建议在使用过程中注意以下几点:
- 合理配置并发数量
- 及时处理任务失败
- 监控系统指标
- 定期维护任务
后续可以考虑添加更多高级特性,如:
- 任务优先级
- 资源配额
- 任务编排
- 可视化管理
怎么样今天的内容还满意吗?再次感谢观众老爷的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!