先看下数据:
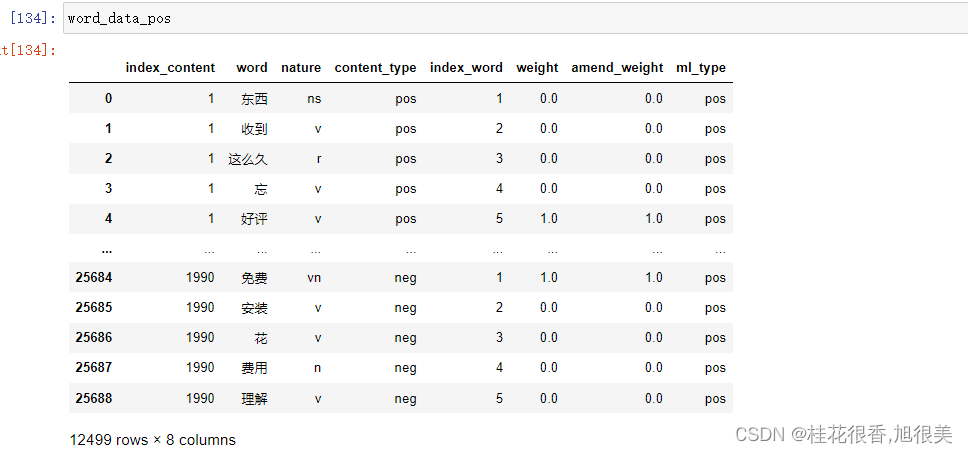
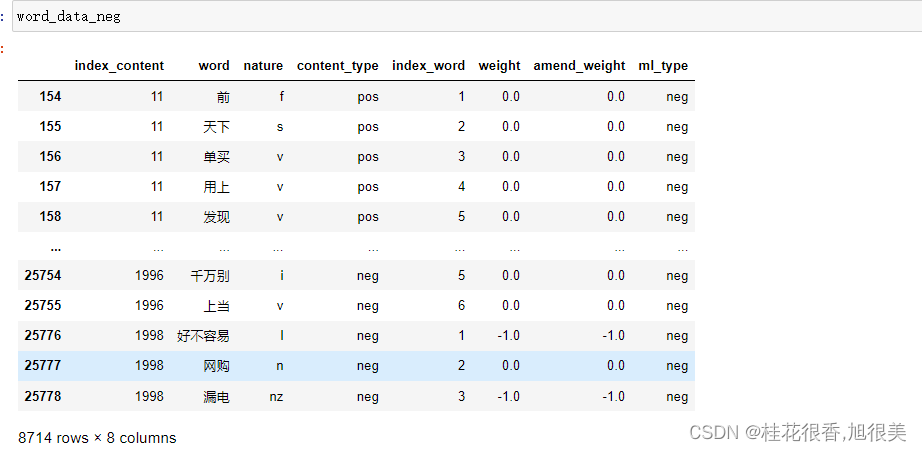
1、建立词典、语料库
from gensim import corpora,models #主题挖掘,提取关键信息
#建立词典,去重
pos_dict=corpora.Dictionary([ [i] for i in word_data_pos.word]) #shape=(n,1)
neg_dict=corpora.Dictionary([ [i] for i in word_data_neg.word])
#建立语料库
pos_corpus=[ pos_dict.doc2bow(j) for j in [ [i] for i in word_data_pos.word] ] #shape=(n,(2,1))
neg_corpus=[ neg_dict.doc2bow(j) for j in [ [i] for i in word_data_neg.word] ]
2、主题数寻优
#构造主题数寻优函数
def cos(vector1,vector2):
'''
函数功能:余玄相似度函数
值越小越相似
'''
dot_product=0.0
normA=0.0
normB=0.0
for a,b in zip(vector1,vector2):
dot_product +=a*b
normA +=a**2
normB +=b**2
if normA==0.0 or normB==0.0:
return None
else:
return ( dot_product/((normA*normB)**0.5) )

#主题数寻优
#这个函数可以重复调用,解决其他项目的问题
def LDA_k(x_corpus,x_dict):
'''
函数功能:
'''
#初始化平均余玄相似度
mean_similarity=[]
mean_similarity.append(1)
#循环生成主题并计算主题间相似度
for i in np.arange(2,11):
lda=models.LdaModel(x_corpus,num_topics=i,id2word=x_dict) #LDA模型训练
for j in np.arange(i):
term=lda.show_topics(num_words=50)
#提取各主题词
top_word=[] #shape=(i,50)
for k in np.arange(i):
top_word.append( [''.join(re.findall('"(.*)"',i)) for i in term[k][1].split('+')]) #列出所有词
#构造词频向量
word=sum(top_word,[]) #列车所有词
unique_word=set(word) #去重
#构造主题词列表,行表示主题号,列表示各主题词
mat=[] #shape=(i,len(unique_word))
for j in np.arange(i):
top_w=top_word[j]
mat.append( tuple([ top_w.count(k) for k in unique_word ])) #统计list中元素的频次,返回元组
#两两组合。方法一
p=list(itertools.permutations(list(np.arange(i)),2)) #返回可迭代对象的所有数学全排列方式。
y=len(p) # y=i*(i-1)
top_similarity=[0]
for w in np.arange(y):
vector1=mat[p[w][0]]
vector2=mat[p[w][1]]
top_similarity.append(cos(vector1,vector2))
# #两两组合,方法二
# for x in range(i-1):
# for y in range(x,i):
#计算平均余玄相似度
mean_similarity.append(sum(top_similarity)/ y)
return mean_similarity
#计算主题平均余玄相似度
pos_k=LDA_k(pos_corpus,pos_dict)
neg_k=LDA_k(neg_corpus,neg_dict)

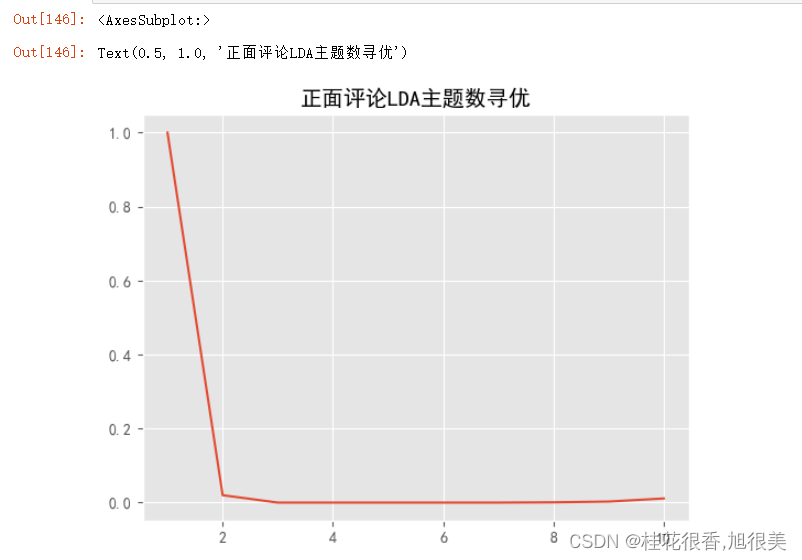
pd.Series(pos_k,index=range(1,11)).plot()
plt.title('正面评论LDA主题数寻优')
plt.show()
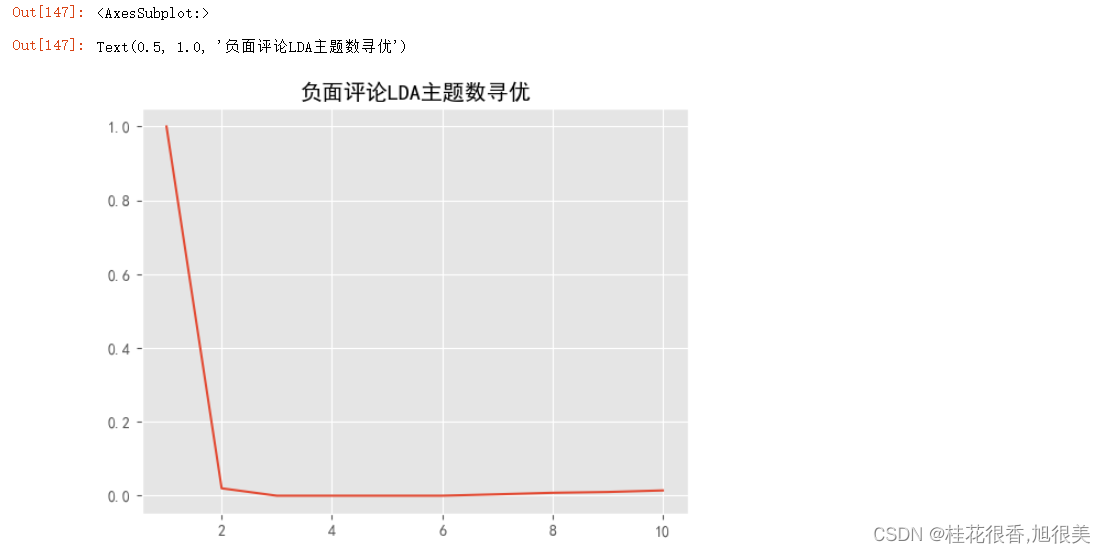
pd.Series(neg_k,index=range(1,11)).plot()
plt.title('负面评论LDA主题数寻优')
plt.show()
pos_lda=models.LdaModel(pos_corpus,num_topics=2,id2word=pos_dict)
neg_lda=models.LdaModel(neg_corpus,num_topics=2,id2word=neg_dict)
pos_lda.print_topics(num_topics=10)
neg_lda.print_topics(num_topics=10)
