一、简单介绍Word Embedding
在NLP任务中,我们需要对文本进行编码,使之成为计算机可以读懂的语言。在编码时,我们期望句子之间保持词语间的相似性。word embedding做的事情就是把一个词映射到低维的稠密空间,切语义相近的词向量离得比较近。
word2vec的缺点:
1、相同词对应的向量训练好就固定了。
2. 在不同的场景中,词的意思是相同的。(即便是skip-gram,学习到的只是多个场景的综合意思)
BERT就是改进这两个缺点。
二、BERT的概念
说白了就是transformer的encoder部分,并不需要标签,有语料就能训练了。
BERT模型,本质可以把其看做是新的word2Vec。对于现有的任务,只需把BERT的输出看做是word2vec,在其之上建立自己的模型即可了。
BERT架构
- 只有编码器的transformer
- 两个版本:
- base: blocks =12, hiddensize=768, heads = 12;
- large: blocks =24, hiddensize=1024, heads = 18;
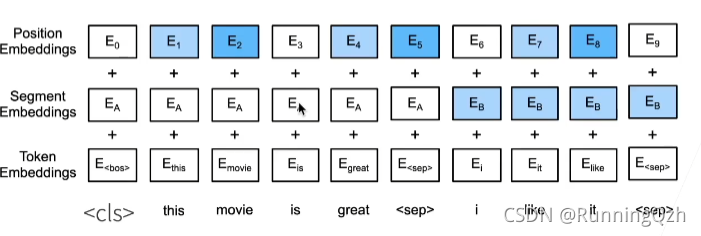
对输入的修改
- 每个样本是一个句子对
- 加入额外的片端嵌入
- 位置编码可学习
cls是句子的开头,sep是两个句子的结尾。
segmentEmbed 前面一个句子是0,后面是1.
postionEmbend是自己学的。



三、bert代码
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引。"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
其中传入两个句子的tokens,构造成cls+tokena+sep+tokenb+sep的输入格式,构造segment时,前一个要+2,因为手动加上了cls和sep,后一个+1,因为只手动加了一个sep。
class BERTEncoder(nn.Module):
"""BERT encoder."""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{
i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,`X`的形状保持不变:(批量大小,最大序列长度,`num_hiddens`)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X