LoRA与量化技术结合:QPiSSA方法降低量化误差的优势分析
量化技术:
量化技术是指将矩阵的值域划分为若干连续区域,并将每个区域内的所有值映射为相同的“量化”值。量化技术的主要目的是减少前向传播的内存消耗。这在深度学习中是一个重要的问题,因为随着模型的复杂性增加,内存消耗也会急剧增加。然而,量化技术在反向传播中会遇到问题,主要是因为量化后的梯度计算不够精确。
LoRA技术:
LoRA(Low-Rank Adaptation)是一种通过引入低秩适配器来减少反向传播内存需求的方法。LoRA的核心思想是将模型参数分解成低秩形式,保留高精度的适配器,以便在反向传播时能够精确地更新参数。因此,LoRA可以与量化技术结合使用,量化基本模型以提高前向传播的内存效率,同时保持LoRA适配器的全精度以保证反向传播的准确性。
QLoRA方法
QLoRA的工作原理:
QLoRA(Quantized LoRA)将基本模型量化为Normal Float 4-bit(NF4),并使用高斯零初始化来初始化全精度的A和B。QLoRA的量化误差公式如下:
Quantization Error of QLoRA
=
∥
W
−
(
nf4
(
W
)
+
A
B
)
∥
∗
=
∥
W
−
nf4
(
W
)
∥
∗
\text{Quantization Error of QLoRA} = \|W - (\text{nf4}(W) + AB)\|_* = \|W - \text{nf4}(W)\|_*
Quantization Error of QLoRA=∥W−(nf4(W)+AB)∥∗=∥W−nf4(W)∥∗
其中,
(
∥
M
∥
∗
)
(\|M\|_*)
(∥M∥∗)表示核范数(也称迹范数),定义为:
∥
M
∥
∗
=
trace
(
M
∗
M
)
=
∑
i
=
1
min
{
m
,
n
}
σ
i
(
M
)
\|M\|_* = \text{trace}(\sqrt{M^*M}) = \sum_{i=1}^{\min\{m,n\}} \sigma_i(M)
∥M∥∗=trace(M∗M)=i=1∑min{m,n}σi(M)
这里,
(
σ
i
(
M
)
)
(\sigma_i(M))
(σi(M))是矩阵M的第i个奇异值。
QPiSSA方法
QPiSSA的工作原理:
QPiSSA(Quantized PiSSA)与QLoRA不同,不对基本模型W进行量化,而是对残差模型Wres进行量化。QPiSSA的量化误差公式如下:
Quantization Error of QPiSSA
=
∥
W
−
(
nf4
(
W
r
e
s
)
+
A
B
)
∥
∗
=
∥
W
r
e
s
−
nf4
(
W
r
e
s
)
∥
∗
\text{Quantization Error of QPiSSA} = \|W - (\text{nf4}(Wres) + AB)\|_* = \|Wres - \text{nf4}(Wres)\|_*
Quantization Error of QPiSSA=∥W−(nf4(Wres)+AB)∥∗=∥Wres−nf4(Wres)∥∗
残差模型的优势:
残差模型Wres移除了大奇异值成分,使得Wres的分布比W更窄。这种分布的特点有助于减少量化误差。此外,NF4优化针对正态分布数据,因此对更接近高斯分布且标准差较小的Wres应用NF4量化技术更加合适。
实验与结果分析
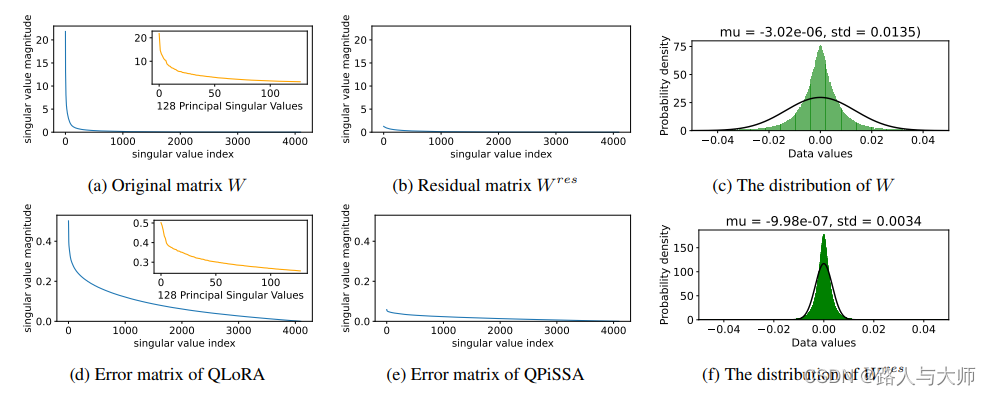
图表解读:
论文中图展示了不同矩阵(W和Wres)的奇异值分布,以及QLoRA和QPiSSA的误差矩阵和数据值分布。具体如下:
-
图a和图b:展示了原始矩阵W和残差矩阵Wres的奇异值分布。可以看到,Wres的奇异值分布比W更窄,表明Wres中大部分大奇异值成分已被移除。
-
图c和图f:展示了W和Wres的数据值分布。Wres的数据分布更接近高斯分布,且标准差较小,这使得NF4量化技术更适用于Wres。
-
图d和图e:展示了QLoRA和QPiSSA的误差矩阵。QPiSSA的误差矩阵显示其量化误差显著低于QLoRA。
结论
QPiSSA通过对残差模型进行量化,成功地减少了量化误差。由于Wres的分布更接近高斯分布且标准差较小,NF4量化技术在应用于Wres时更加有效。这些特点使得QPiSSA在实际应用中能够实现比QLoRA更低的量化误差,并且在模型微调性能方面也表现更优。