0.准备工作
下载jsoup的jar包,有两种方式:
- 使用maven框架进行构建
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
- 到 https://mvnrepository.com/artifact/org.jsoup/jsoup 下载jar包(jsoup-1.12.1.jar),然后加到类路径中。
1. 分析
豆瓣电影top25的第一个页面网址是 https://movie.douban.com/top250,我们检查该网页(google浏览器:ctrl+shift+c)可以发现,ol标签后面 li 标签即为每个电影的内容。
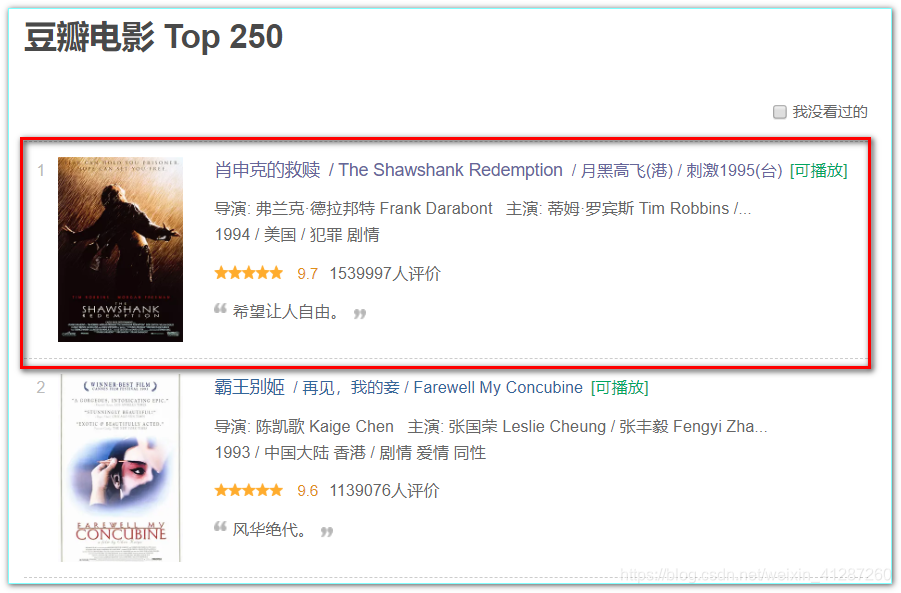
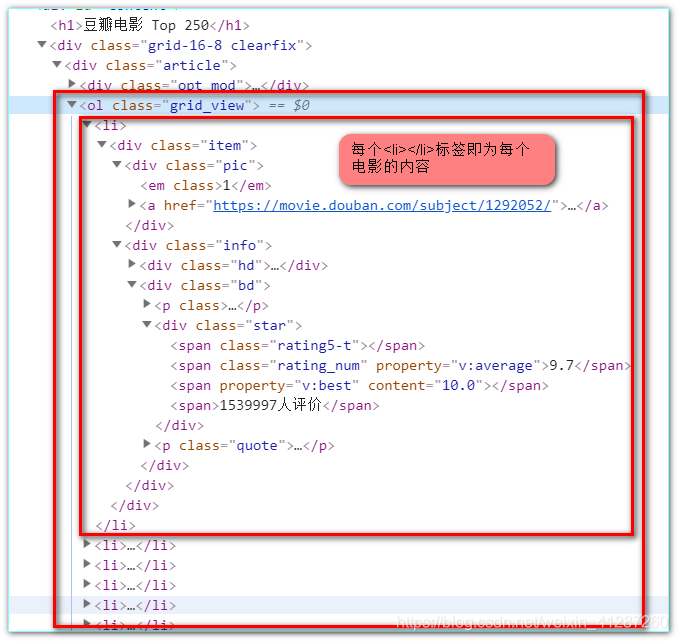
以下是格式化了的li标签的内容:(这是第一个电影《肖申克的救赎》)
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎"
src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span> <span class="title"> / The Shawshank Redemption</span> <span
class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span> <span class="rating_num" property="v:average">9.7</span> <span
property="v:best" content="10.0"></span> <span>1539997人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
</li>
之后的工作基本上围绕这段代码来开展。
2. 构思
讲代码之前我们要现有思路,下面是我的思路:
- 获取“单页-一个电影”的数据
- 获取“单页-所有电影-25个”的数据
- 获取“所有页面-所有电影-25+10=250个”的数据
虽然这和我一开始想法有些差异,但是方向是一样的。
3. 编程
3.1 定义一个bean,用于保存电影的数据
定义Movie类,用于保存电影的相关数据。包含:排名,电影名,电影的豆瓣页网址,(国家,放映年份),平均评分,评价人数,引用(一句话评语)。
注意:为了方便在控制台查看数据和保存数据,这里定义了两个tostring方法,第一个是自动生成的,便于在控制台查看数据;第二个是自己定义的,为了方便保存数据到本地txt,如果你需要保存TXT文件,请选择第二种形式。
Movie.java代码:
/**
* @Title Movie.java
* @Package xyz.yansheng.top250
* @Description TODO
* @author yansheng
* @date 2019-08-12 15:34:16
* @version v1.0
*/
package xyz.yansheng.top250;
/**
* <p>Title: Movie</p>
* <p>Description: 定义Movie类,用于保存电影的相关数据。包含:排名,电影名,电影的豆瓣页网址,(国家,放映年份),平均评分,评价人数,引用(一句话评语)。</p>
* <p>Company: </p>
* @author yansheng
* @date 2019-08-12 15:34:16
* @version v1.0
*/
public class Movie {
// 排名,电影名,电影的豆瓣页网址,(国家,放映年份),平均评分,评价人数,引用(一句话评语)
private Integer rank;
private String title;
private String url;
private Double ratingNum;
private Integer ratingPeopleNum;
private String quote;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public void setRank(Integer rank) {
this.rank = rank;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public Double getRatingNum() {
return ratingNum;
}
public void setRatingNum(Double ratingNum) {
this.ratingNum = ratingNum;
}
public Integer getRatingPeopleNum() {
return ratingPeopleNum;
}
public void setRatingPeopleNum(Integer ratingPeopleNum) {
this.ratingPeopleNum = ratingPeopleNum;
}
public String getQuote() {
return quote;
}
public void setQuote(String quote) {
this.quote = quote;
}
@Override
public String toString() {
// 形式1.为了方便控制台打印
return "Movie [rank=" + rank + ", title=" + title + ", url=" + url + ", ratingNum=" + ratingNum
+ ", ratingPeopleNum=" + ratingPeopleNum + ", quote=" + quote + "]";
// 形式2.为了方便保存数据到本地txt
// 在将数据写到本地txt保存时,建议用下面这个格式,数据比较干净,有利用导入到数据库等。
//return rank + "," + title + "," + url + "," + ratingNum + "," + ratingPeopleNum + "," + quote + "\n";
}
}
3.2 按照之前的构思进行编程
为了方便起见,我直接将这个方法定义在一个类中。所有方法在main方法里面进行测试,可以按照方法进行测试。
注意:方法4,选用第二种tostring方法(上面有提到的)。
下面这个是CrawlMovie.java文件中的main()方法,先看这个测试代码,你会比较容易理解主要的几个方法的作用:
public static void main(String[] args) {
// 1.获取“单页-一个电影”的数据
// 测试方法:Movie crawlMovie()
// crawlMovie();
// 2.获取“单页-所有电影-25个”的数据
// 测试方法:Movie crawlMovie()
/*final String URL = "https://movie.douban.com/top250";
ArrayList<Movie> movies2 = crawlMovies(URL);
for (Movie movie : movies2) {
System.out.println(movie.toString());
}*/
// 3.获取“所有页面-所有电影-25+10=250个”的数据
// 测试方法:ArrayList<Movie> crawlAllMovies()
ArrayList<Movie> movies3 = crawlAllMovies();
for (Movie movie : movies3) {
System.out.println(movie.toString());
}
// 4.为了简单起见,这里仅仅是将数据保存为txt文件,不保存到excel或者是数据库。
// 测试方法:void writeMovie(ArrayList<Movie> movies)
writeMoviesToTxt(movies3);
}
CrawlMovie.java的所有代码:
/**
* @Title CrawlMovie.java
* @Package xyz.yansheng.top250
* @Description TODO
* @author yansheng
* @date 2019-08-12 15:47:06
* @version v1.0
*/
package xyz.yansheng.top250;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* <p>Title: </p>
* <p>Description: </p>
* <p>Company: </p>
* @author yansheng
* @date 2019-08-12 15:47:06
* @version v1.0
*/
public class CrawlMovie {
/**
* @Title main
* @author yansheng
* @version v1.0
* @date 2019-08-12 15:47:06
* @Description 爬取豆瓣电影top250:https://movie.douban.com/top250
*/
public static void main(String[] args) {
// 1.获取“单页-一个电影”的数据
// 测试方法:Movie crawlMovie()
// crawlMovie();
// 2.获取“单页-所有电影-25个”的数据
// 测试方法:Movie crawlMovie()
/*final String URL = "https://movie.douban.com/top250";
ArrayList<Movie> movies2 = crawlMovies(URL);
for (Movie movie : movies2) {
System.out.println(movie.toString());
}*/
// 3.获取“所有页面-所有电影-25+10=250个”的数据
// 测试方法:ArrayList<Movie> crawlAllMovies()
ArrayList<Movie> movies3 = crawlAllMovies();
for (Movie movie : movies3) {
System.out.println(movie.toString());
}
// 4.为了简单起见,这里仅仅是将数据保存为txt文件,不保存到excel或者是数据库。
// 测试方法:void writeMovie(ArrayList<Movie> movies)
writeMoviesToTxt(movies3);
}
// 1.获取“单页-一个电影”的数据
public static void crawlMovie() {
// 1.获取网页
final String URL = "https://movie.douban.com/top250";
Document document = null;
try {
document = Jsoup.connect(URL).get();
} catch (IOException e) {
e.printStackTrace();
}
// System.out.println("document:" + document);
Movie movie = new Movie();
// 2.选择具体的电影的项,注意first方法,这里先只选取第一个进行测试
Element itemElement = document.select("ol li").first();
// System.out.println("item:" + item.toString());
// 3.1电影排名
Element rankElement = itemElement.selectFirst("em");
String rankString = rankElement.text();
System.out.println("rankString:" + rankString.toString());
movie.setRank(new Integer(rankString));
// 3.2电影网址
Element urlElement = itemElement.select("div.hd a").first();
String urlString = urlElement.attr("href");
System.out.println("urlString:" + urlString.toString());
movie.setUrl(urlString);
// 3.3电影名
Element titleElement = urlElement.select("span.title").first();
String titleString = titleElement.text();
System.out.println("titleString:" + titleString.toString());
movie.setTitle(titleString);
// 3.4评分
Element ratingNumElement = itemElement.select("div.star span.rating_num").first();
String ratingNumString = ratingNumElement.text();
System.out.println("ratingNumString:" + ratingNumString.toString());
movie.setRatingNum(new Double(ratingNumString));
// 3.5评价人数
Element ratingPeopleNumElement = itemElement.select("div.star span").last();
String ratingPeopleNumString = ratingPeopleNumElement.text();
System.out.println("ratingPeopleNumString:" + ratingPeopleNumString.toString());
// 注意这里文本是:1539997人评价,我们需要选取其中人数,进行裁剪
movie.setRatingPeopleNum(
new Integer(ratingPeopleNumString.substring(0, ratingPeopleNumString.length() - 3)));
// 3.6 一句话简评
Element quoteElement = itemElement.select("p.quote span.inq").first();
String quoteString = quoteElement.text();
System.out.println("quoteString:" + quoteString.toString());
movie.setQuote(quoteString);
System.out.println(movie.toString());
}
// 2.获取“单页-所有电影-25*1=25个”的数据
public static ArrayList<Movie> crawlMovies(String URL) {
// 1.获取网页
//final String URL = "https://movie.douban.com/top250";
Document document = null;
try {
document = Jsoup.connect(URL).get();
} catch (IOException e) {
e.printStackTrace();
}
// System.out.println("document:" + document);
// 2.选择具体的电影的项,注意这里和上面第一个不同,这里是选取的所有电影的项
Elements itemElement = document.select("ol li");
ArrayList<Movie> movies = new ArrayList<Movie>(25);
for (Element element : itemElement) {
Movie movie = new Movie();
// 3.1电影排名
Element rankElement = element.selectFirst("em");
String rankString = rankElement.text();
movie.setRank(new Integer(rankString));
// 3.2电影网址
Element urlElement = element.select("div.hd a").first();
String urlString = urlElement.attr("href");
movie.setUrl(urlString);
// 3.3电影名
Element titleElement = urlElement.select("span.title").first();
String titleString = titleElement.text();
movie.setTitle(titleString);
// 3.4评分
Element ratingNumElement = element.select("div.star span.rating_num").first();
String ratingNumString = ratingNumElement.text();
movie.setRatingNum(new Double(ratingNumString));
// 3.5评价人数
Element ratingPeopleNumElement = element.select("div.star span").last();
String ratingPeopleNumString = ratingPeopleNumElement.text();
movie.setRatingPeopleNum(
new Integer(ratingPeopleNumString.substring(0, ratingPeopleNumString.length() - 3)));
// 3.6 一句话简评
Element quoteElement = element.select("p.quote span.inq").first();
// 注意:这里可能会没有简评,如125的《我不是药神》,字符串会为null,如果是null,置为空字符串,否则会出现NPE问题
String quoteString = null;
if (quoteElement == null) {
quoteString = "";
} else {
quoteString = quoteElement.text();
}
movie.setQuote(quoteString);
movies.add(movie);
}
return movies;
}
// 3.获取“所有页面-所有电影-25+10=250个”的数据
public static ArrayList<Movie> crawlAllMovies() {
ArrayList<Movie> movies = new ArrayList<Movie>(250);
/*注意查看网址之间的特点,然后拼接字符串:
* 第1页. https://movie.douban.com/top250
* 2. https://movie.douban.com/top250?start=25&filter=
* 3. https://movie.douban.com/top250?start=50&filter=
*
* 通过观察我们可以发现:(如果有怀疑直接到浏览器测试拼接的网址是否正确)
* (1)前面都是一样的:“https://movie.douban.com/top250”,
* (2)后面加一个查询串:“?start=25*(-1)”,其中i表示页数,根据意思我们可以知道其实是:指定指定该页是从排名第几的电影开始,
* 即如果是“?start=20”,那么该页第一个就是21。
* (3)按照(2)的意思,其实第一个页面就是:https://movie.douban.com/top250?start=0&filter=
* (4)而最后面的"&filter=",其实有没有都无所谓。
*/
String prefix = "https://movie.douban.com/top250";
// 为了方便起见我先将网址拼接好,后面直接就可以用了
ArrayList<String> urlList = new ArrayList<String>(10);
for (int i = 0; i < 11; i++) {
String url = prefix + "?start=" + new Integer(i * 25).toString() + "&filter=";
urlList.add(url);
}
// 这里直接调用上面的方法2(找到每页的电影),将得到的(25个电影)集合添加到(250个电影)集合,通过循环遍历10个页面。
for (String url : urlList) {
movies.addAll(crawlMovies(url));
}
return movies;
}
// 4.为了简单起见,这里仅仅是将数据保存为txt文件,不保存到excel或者是数据库。
public static void writeMoviesToTxt(ArrayList<Movie> movies) {
// 4.1 先将每个电影对象转化为字符串
ArrayList<String> moviesString = new ArrayList<String>(250);
for (Movie movie : movies) {
moviesString.add(movie.toString());
}
// 4.2写字节流
try (FileOutputStream out = new FileOutputStream("豆瓣电影top250.txt");) {
for (String string : moviesString) {
out.write(string.getBytes());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
4.效果图
-
控制台输出:(部分截图)
-
保存的txt文件:(部分截图)
-
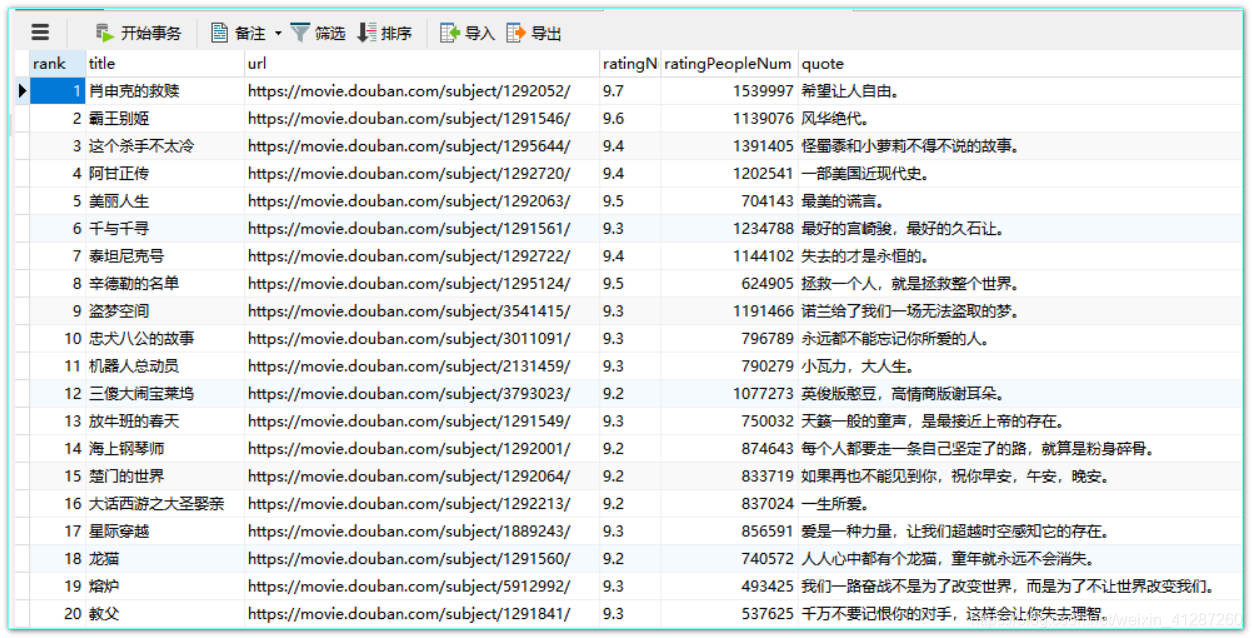
处理后的excel表格数据:(部分截图)
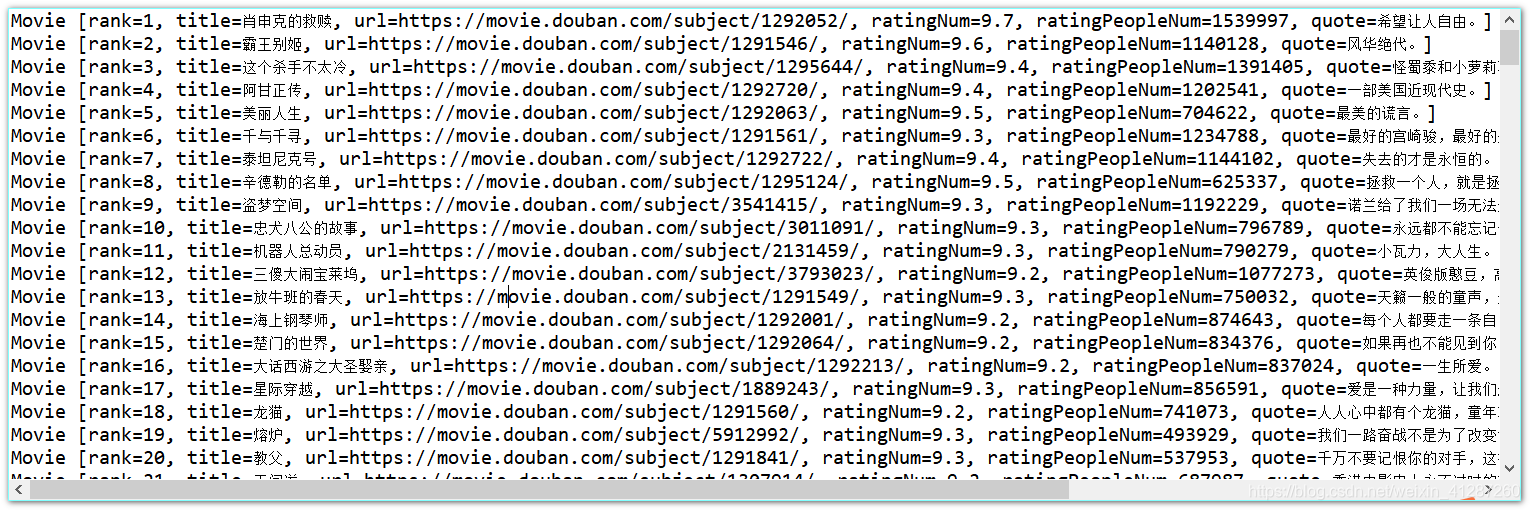

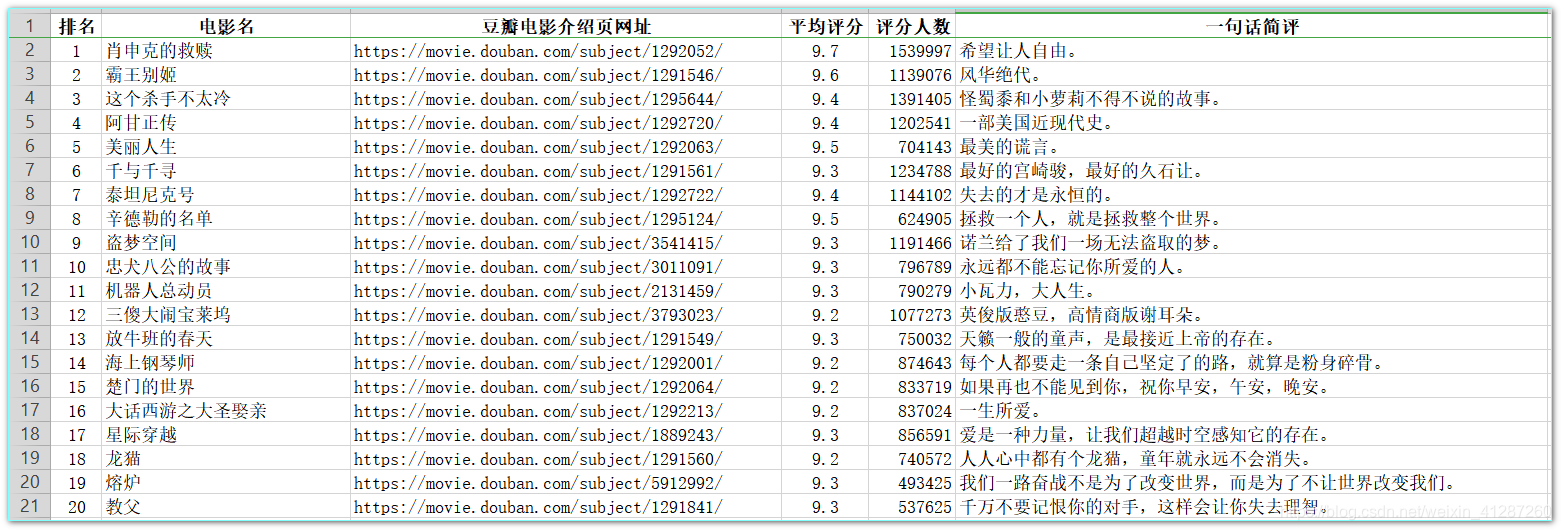
通过观察我们可以发现,不是评分高排名就靠前!!
5.获取资源
5.1GitHub
github仓库:https://github.com/yansheng836/jsoup-test#user-content-2-爬取豆瓣电影top250
5.2百度云
资源列表:
说明:
- Excel表格数据是经过处理的,该程序没有实现该功能(保存数据到excel的功能)。
movie.sql是mysql数据库的一个表的转储sql文件,直接在mysql执行该文件可得到以数据库表:
百度云盘链接:https://pan.baidu.com/s/1fXr8psMndIzdu5r656m1ow
提取码:f36z