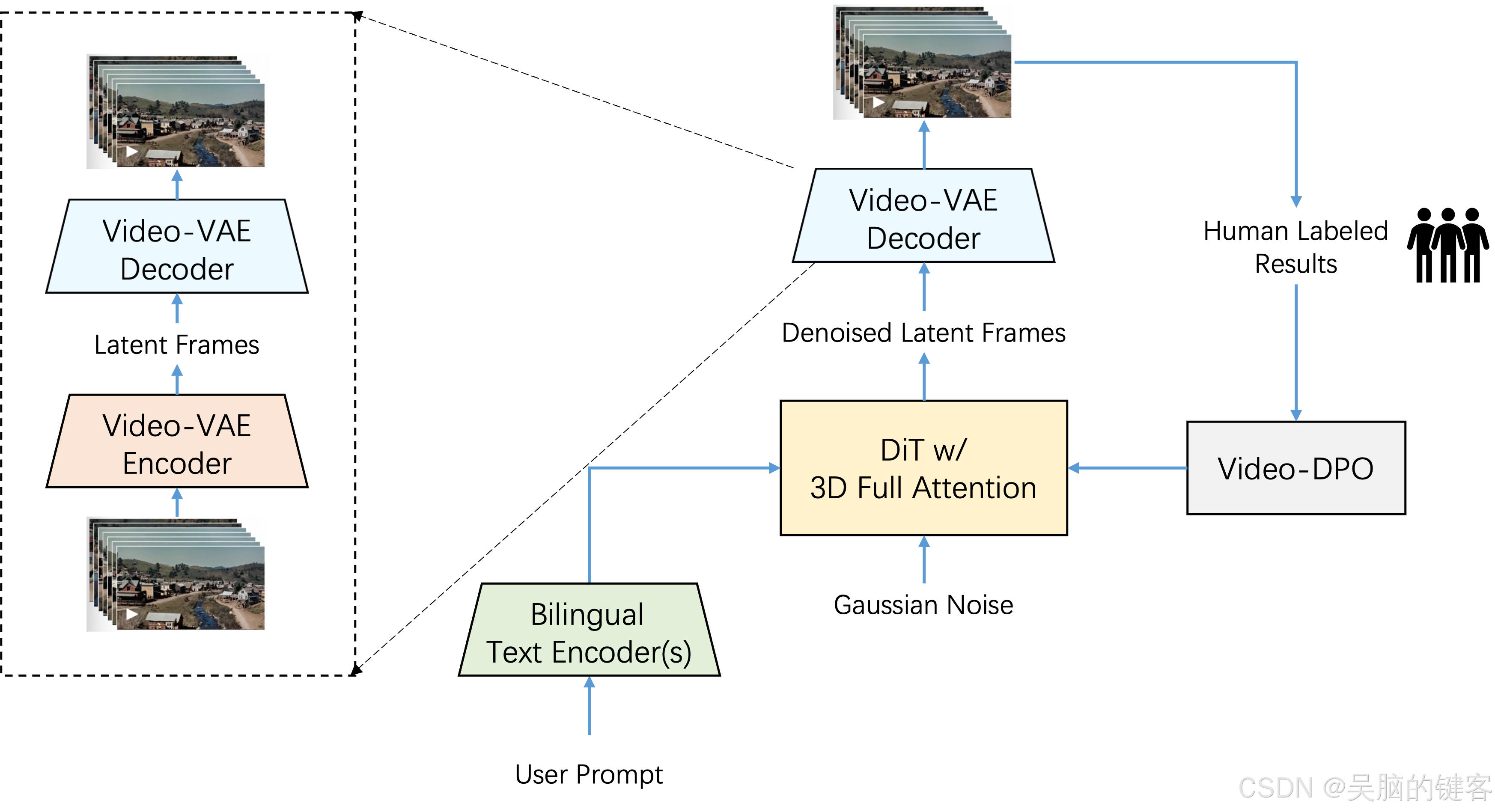
我们提出了 Step-Video-T2V,这是一种最先进的(SoTA)文本到视频预训练模型,拥有 300 亿个参数,能够生成多达 204 帧的视频。为了提高训练和推理效率,我们提出了视频深度压缩 VAE,实现了 16x16 的空间压缩率和 8x 的时间压缩率。直接偏好优化(DPO)应用于最后阶段,以进一步提高生成视频的视觉质量。Step-Video-T2V 的性能在新颖的视频生成基准 Step-Video-T2V-Eval 上进行了评估,结果表明,与开源引擎和商业引擎相比,Step-Video-T2V 的文本视频质量更高。

模型概要
在 Step-Video-T2V 中,视频由高压缩视频-VAE 表示,空间压缩率为 16x16,时间压缩率为 8x。用户提示使用两个双语预训练文本编码器进行编码,以处理英文和中文。三维全神贯注的 DiT 采用流匹配技术进行训练,并将输入噪声去噪为潜在帧,同时将文本嵌入和时间步作为调节因素。为进一步提高生成视频的视觉质量,还采用了基于视频的 DPO 方法,该方法可有效减少伪影,确保视频输出更流畅、更逼真。
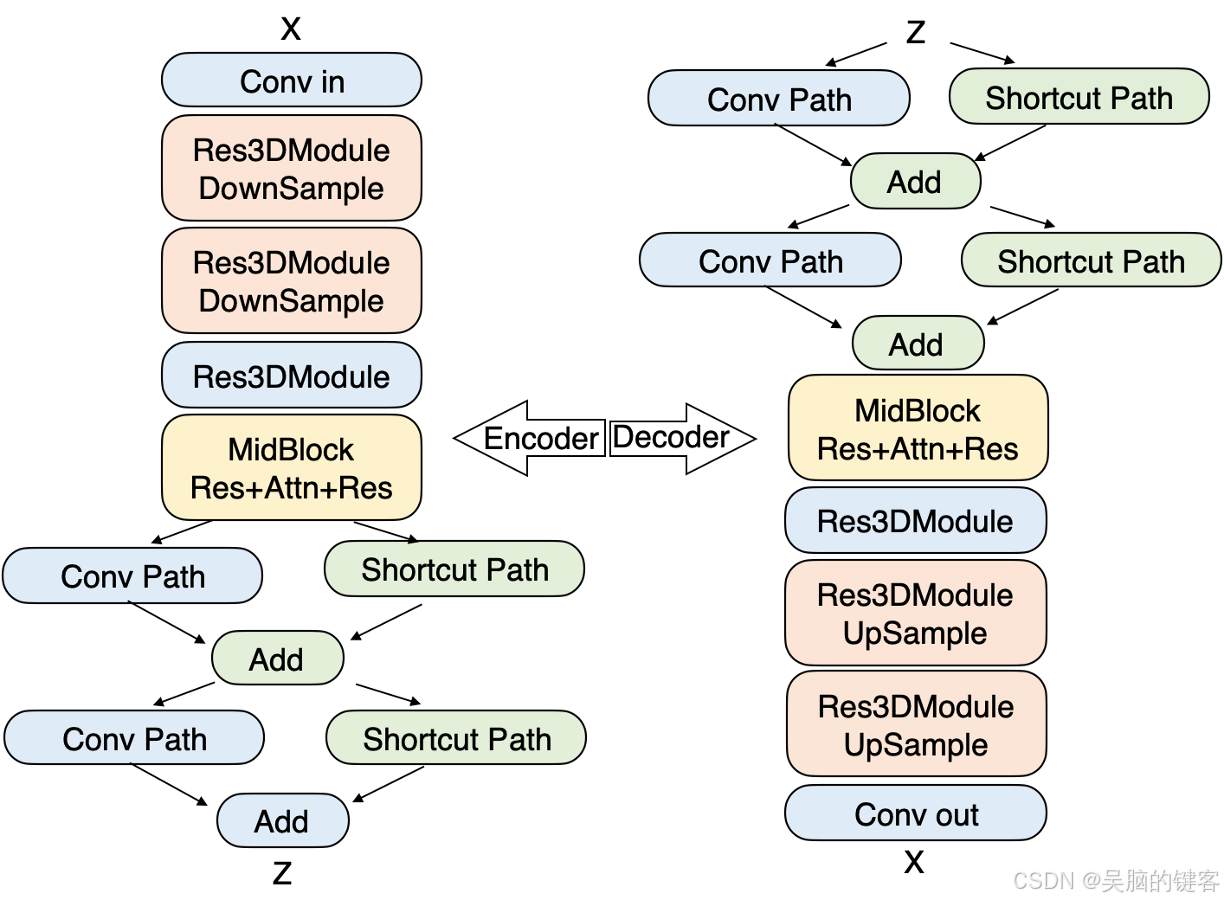
1. Video-VAE
深度压缩变异自动编码器(VideoVAE)专为视频生成任务而设计,可实现 16x16 空间压缩率和 8x 时间压缩率,同时保持出色的视频重建质量。这种压缩不仅加快了训练和推理速度,而且符合扩散过程对浓缩表示的偏好。
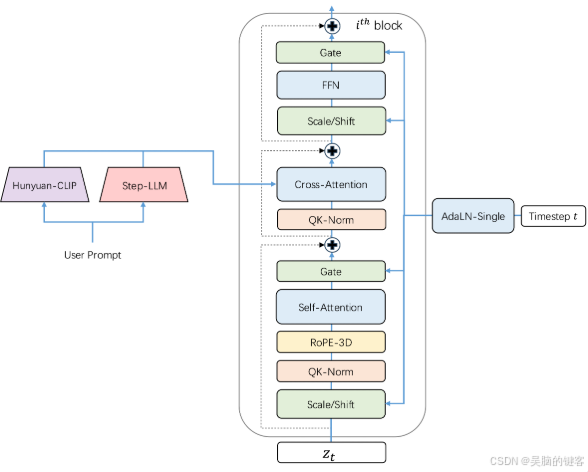
2. DiT w/ 3D Full Attention
Step-Video-T2V 建立在 DiT 架构上,该架构有 48 层,每层包含 48 个注意力头,每个注意力头的维度设置为 128。利用 AdaLN-Single 将时间步条件纳入其中,同时在自我注意机制中引入 QK-Norm 以确保训练的稳定性。此外,还采用了 3D RoPE,在处理不同视频长度和分辨率的序列时发挥了关键作用。
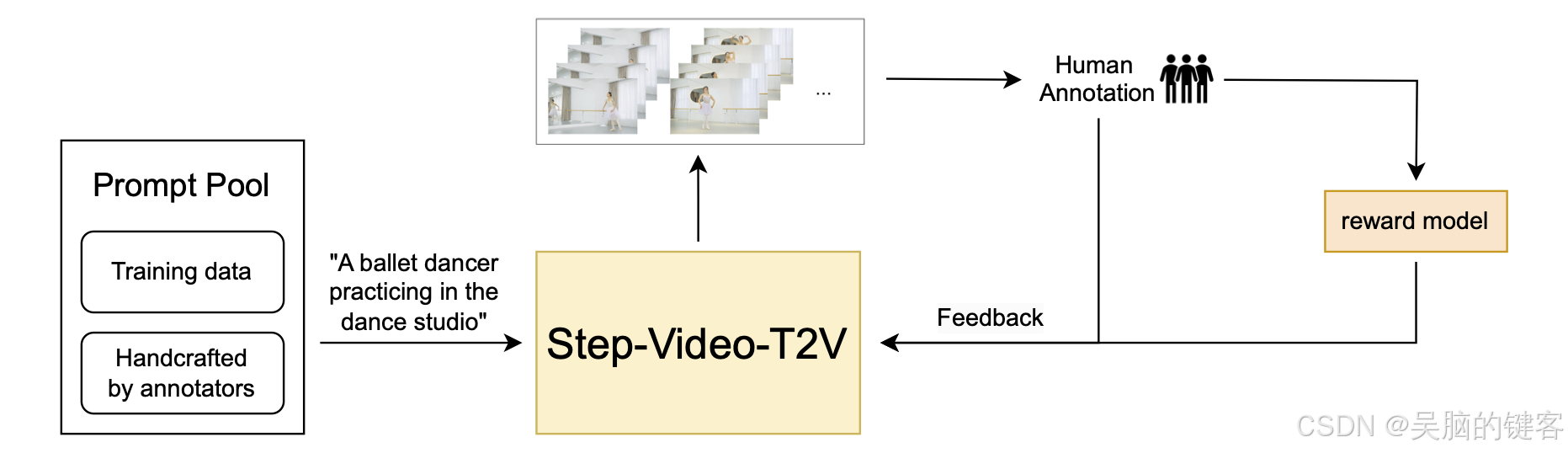
3. Video-DPO
在 Step-Video-T2V 中,我们通过直接偏好优化 (Direct Preference Optimization,DPO) 将人类反馈纳入其中,以进一步提高生成视频的视觉质量。DPO 利用人类偏好数据对模型进行微调,确保生成的内容更符合人类的期望。整个 DPO 流程如下所示,突出了它在提高视频生成过程的一致性和质量方面的关键作用。
模型下载
| Models | 🤗Huggingface | 🤖Modelscope |
|---|---|---|
| Step-Video-T2V | download | download |
| Step-Video-T2V-Turbo (Inference Step Distillation) | download | download |
模型使用
📜 要求
下表显示了运行 Step-Video-T2V 模型(batch size = 1,不含 cfg 蒸馏)生成视频的要求:
| Model | height/width/frame | Peak GPU Memory | 50 steps w flash-attn | 50 steps w/o flash-attn |
|---|---|---|---|---|
| Step-Video-T2V | 768px768px204f | 78.55 GB | 860 s | 1437 s |
| Step-Video-T2V | 544px992px204f | 77.64 GB | 743 s | 1232 s |
| Step-Video-T2V | 544px992px136f | 72.48 GB | 408 s | 605 s |
- 需要支持 CUDA 的英伟达™(NVIDIA®)GPU。
- 该模型在四个 GPU 上进行测试。
- 建议:我们建议使用具有 80GB 内存的 GPU,以获得更好的生成质量。
*已测试操作系统:Linux
*文本编码器(step_llm)中的自注意仅支持 CUDA 功能 sm_80 sm_86 和 sm_90
🔧 依赖和安装
- Python>=3.10.0(建议使用 Anaconda 或 Miniconda)
- PyTorch >= 2.3-cu121
- CUDA Toolkit
- FFmpeg
git clone https://github.com/stepfun-ai/Step-Video-T2V.git
conda create -n stepvideo python=3.10
conda activate stepvideo
cd Step-Video-T2V
pip install -e .
pip install flash-attn --no-build-isolation ## flash-attn is optional
🚀 推理脚本
Multi-GPU 并行部署
- 我们对文本编码器、VAE 解码和 DiT 采用了解耦策略,以优化 DiT 对 GPU 资源的利用。因此,需要一个专用 GPU 来处理文本编码器嵌入和 VAE 解码的 API 服务。
python api/call_remote_server.py --model_dir where_you_download_dir & ## We assume you have more than 4 GPUs available. This command will return the URL for both the caption API and the VAE API. Please use the returned URL in the following command.
parallel=4 # or parallel=8
url='127.0.0.1'
model_dir=where_you_download_dir
torchrun --nproc_per_node $parallel run_parallel.py --model_dir $model_dir --vae_url $url --caption_url $url --ulysses_degree $parallel --prompt "一名宇航员在月球上发现一块石碑,上面印有“stepfun”字样,闪闪发光" --infer_steps 50 --cfg_scale 9.0 --time_shift 13.0
Single-GPU 推理和量化
- ModelScope 的开源项目 DiffSynth-Studio 提供单 GPU 推理和量化支持,可显著减少所需的 VRAM。更多信息请参阅 其示例。
🚀 最佳实践推理设置
Step-Video-T2V 在推理设置中表现出强劲的性能,能持续生成高保真和动态的视频。然而,我们的实验表明,推理超参数的变化会对视频保真度和动态性之间的权衡产生重大影响。为了达到最佳效果,我们建议采用以下最佳实践来调整推理参数:
| Models | infer_steps | cfg_scale | time_shift | num_frames |
|---|---|---|---|---|
| Step-Video-T2V | 30-50 | 9.0 | 13.0 | 204 |
| Step-Video-T2V-Turbo (Inference Step Distillation) | 10-15 | 5.0 | 17.0 | 204 |
基准
我们发布了Step-Video-T2V Eval这一新基准,其中包含来自真实用户的 128 条中文提示。该基准旨在评估生成的 11 个不同类别视频的质量:体育、美食、风景、动物、节日、组合概念、超现实、人物、三维动画、摄影和风格。
在线引擎
《Step-Video-T2V》在线版可在 跃问视频上观看,您还可以在其中探索一些令人印象深刻的示例。