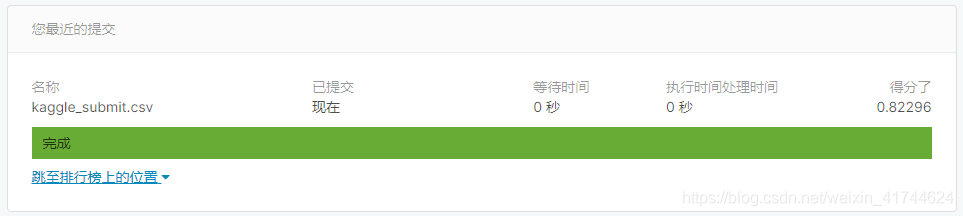
先附全代码预览
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 使用RandomForestClassifier,填补缺失的年龄
from sklearn.ensemble import RandomForestRegressor
train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
test= pd.read_csv("C:/Users/10158565/Desktop/kaggle/test.csv")
PassengerId=test['PassengerId']
all_data = pd.concat([train, test], ignore_index = True)
all_data['Title'] = all_data['Name'].apply(lambda x:x.split(',')[1].split('.')[0].strip())
Title_Dict = {}
Title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer'))
Title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))
Title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))
Title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))
Title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))
Title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))
all_data['FamilySize']=all_data['SibSp']+all_data['Parch']+1
def Fam_label(s):
if (s >= 2) & (s <= 4):
return 2
elif ((s > 4) & (s <= 7)) | (s == 1):
return 1
elif (s > 7):
return 0
all_data['FamilyLabel']=all_data['FamilySize'].apply(Fam_label)
all_data['Cabin'] = all_data['Cabin'].fillna('Unknown')
all_data['Deck']=all_data['Cabin'].str.get(0)
Ticket_Count = dict(all_data['Ticket'].value_counts())
all_data['TicketGroup'] = all_data['Ticket'].apply(lambda x:Ticket_Count[x])
# 把已有的数据特征值取出,放入到Random Forest Regressor中
age_df = all_data[['Age', 'Pclass','Sex','Title']]
# 把年龄做特征值转化,即根据上述放进来的特征值,把对应的转换为0、1两个数
age_df=pd.get_dummies(age_df)
# 分为已知年龄和未知年龄
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# 目标年龄值
y = known_age[:, 0]
# 特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补缺失数据
all_data.loc[ (all_data.Age.isnull()), 'Age' ] = predictedAges
# Embarked字段缺失量填充
all_data['Embarked'] = all_data['Embarked'].fillna('C')
# Fare字段缺失量填充
fare=all_data[(all_data['Embarked'] == "S") & (all_data['Pclass'] == 3)].Fare.median()
all_data['Fare']=all_data['Fare'].fillna(fare)
#同组识别
all_data['Surname']=all_data['Name'].apply(lambda x:x.split(',')[0].strip())
Surname_Count = dict(all_data['Surname'].value_counts())
all_data['FamilyGroup'] = all_data['Surname'].apply(lambda x:Surname_Count[x])
Female_Child_Group=all_data.loc[(all_data['FamilyGroup']>=2) & ((all_data['Age']<=12) | (all_data['Sex']=='female'))]
Male_Adult_Group=all_data.loc[(all_data['FamilyGroup']>=2) & (all_data['Age']>12) & (all_data['Sex']=='male')]
Female_Child_Group=Female_Child_Group.groupby('Surname')['Survived'].mean()
Dead_List=set(Female_Child_Group[Female_Child_Group.apply(lambda x:x==0)].index)
print(Dead_List)
Male_Adult_List=Male_Adult_Group.groupby('Surname')['Survived'].mean()
Survived_List=set(Male_Adult_List[Male_Adult_List.apply(lambda x:x==1)].index)
print(Survived_List)
#惩罚修改
train=all_data.loc[all_data['Survived'].notnull()]
test=all_data.loc[all_data['Survived'].isnull()]
test.loc[(test['Surname'].apply(lambda x:x in Dead_List)),'Sex'] = 'male'
test.loc[(test['Surname'].apply(lambda x:x in Dead_List)),'Age'] = 60
test.loc[(test['Surname'].apply(lambda x:x in Dead_List)),'Title'] = 'Mr'
test.loc[(test['Surname'].apply(lambda x:x in Survived_List)),'Sex'] = 'female'
test.loc[(test['Surname'].apply(lambda x:x in Survived_List)),'Age'] = 5
test.loc[(test['Surname'].apply(lambda x:x in Survived_List)),'Title'] = 'Miss'
all_data=pd.concat([train, test])
all_data=all_data[['Survived','Pclass','Sex','Age','Fare','Embarked','Title','FamilyLabel','Deck','TicketGroup']]
all_data=pd.get_dummies(all_data)
train=all_data[all_data['Survived'].notnull()]
test=all_data[all_data['Survived'].isnull()].drop('Survived',axis=1)
X = train.as_matrix()[:,1:]
y = train.as_matrix()[:,0]
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.feature_selection import SelectKBest
pipe=Pipeline([('select',SelectKBest(k=20)),
('classify', RandomForestClassifier(random_state = 10, max_features = 'sqrt'))])
param_test = {'classify__n_estimators':list(range(20,50,2)),
'classify__max_depth':list(range(3,60,3))}
gsearch = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='roc_auc', cv=10)
gsearch.fit(X,y)
print(gsearch.best_params_, gsearch.best_score_)
from sklearn.pipeline import make_pipeline
select = SelectKBest(k = 20)
clf = RandomForestClassifier(random_state = 10, warm_start = True,
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt')
pipeline = make_pipeline(select, clf)
pipeline.fit(X, y)
from sklearn import cross_validation, metrics
cv_score = cross_validation.cross_val_score(pipeline, X, y, cv= 10)
print("CV Score : Mean - %.7g | Std - %.7g " % (np.mean(cv_score), np.std(cv_score)))
predictions = pipeline.predict(test)
submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": predictions.astype(np.int32)})
submission.to_csv(r"C:/Users/10158565/Desktop/kaggle_submit.csv", index=False)
………………………………………………………………………………
详解来了详解来了详解来了详解来了详解来了详解来了详解来了详解来了
数据概览
官方给出了三个文档,其中train是训练数据,我们将其导入到工作中
此时我们观察到,数据中有几个字段存在空值,并且Survived字段中的0,1分别代表死亡和存活,也正是我们想探究的量

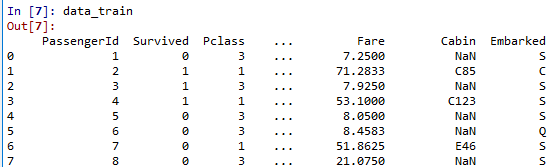
•PassengerID(ID)
•Survived(是否存活)
•Pclass(客舱等级)
•Name(姓名)
•Sex(性别)
•Age(年龄)
•Parch(直系亲友)
•SibSp(旁系亲友)
•Ticket(票编号)
•Fare(票价)
•Cabin(客舱编号)
•Embarked(港口)
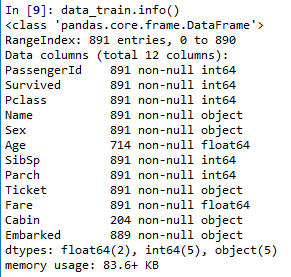
data_train.info()
由于缺失的数据会影响到分析结果,使用info()查看统计字段的结果(Age,Cabin,Embarked都是缺失不满891的字段,使用时需注意)
各字段与获救关联性分析
按照数据给出的所有字段,分析字段和Survived字段的联系
PassengerId: 从1-n往后排肯定是没什么关系了
Pclass:
import pandas as pd
data_train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
survived=data_train.Pclass[data_train.Survived == 1].value_counts()
nsurvived=data_train.Pclass[data_train.Survived == 0].value_counts()
df=pd.DataFrame({'suivived':survived,'nsurvived':nsurvived})
df.plot(kind='bar',stacked=True,title='Pclass')
可以看出,不同的客舱等级会影响到幸存率,一等舱的幸存率明显高

Name:
至于名称这个变量,博主一开始是想到可能会有什么血统影响(遗传跑得快),或者是什么皇室血统优先跑啥的,然后展开了一下…
emmm这个姓氏整理的有点不规则,等后续有时间再数据治理吧,先假装没关系…
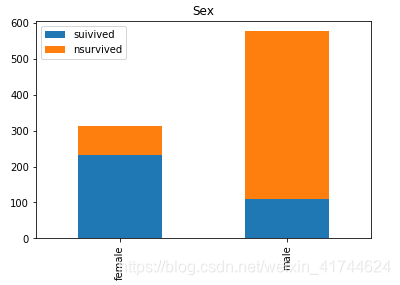
Sex:

import pandas as pd
data_train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
survived=data_train.Sex[data_train.Survived == 1].value_counts()
nsurvived=data_train.Sex[data_train.Survived == 0].value_counts()
df=pd.DataFrame({'suivived':survived,'nsurvived':nsurvived})
df.plot(kind='bar',stacked=True,title='Name')
可以看出,不同的性别也会影响幸存率,女士幸存率更高
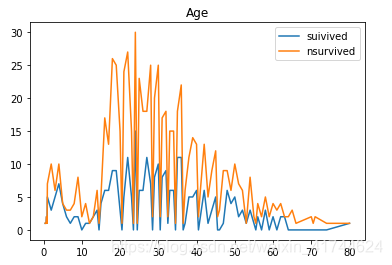
Age:
import pandas as pd
import matplotlib.pyplot as plt
data_train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
survived=data_train.Age[data_train.Survived == 1].value_counts()
nsurvived=data_train.Age[data_train.Survived == 0].value_counts()
df=pd.DataFrame({'suivived':survived,'nsurvived':nsurvived})
df.plot(stacked=True,title='Age')
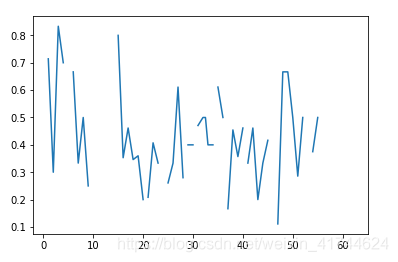
plt.figure()
ss=survived/(survived+nsurvived)
plt.plot(ss)
Age是有缺失值的
但从第一幅图是看不出来特别大的区别的,但从第二幅中的幸存率来看,0~15的区间内幸存率会普遍高(尊老爱幼吧),为什么排除尊老呢,因为如果用以上方法探究,舱位的分布随年龄递增,可能是因为年龄大头等舱多才收到影响导致幸存率高吧(其实就是取两段年龄段有点麻烦,有空回来再优化吧哈哈)。
那我们可以考虑年龄偏小幸存率高这个是拥有可信度的~
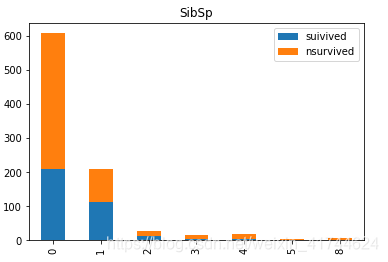
Sibsp:
import pandas as pd
data_train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
survived=data_train.SibSp[data_train.Survived == 1].value_counts()
nsurvived=data_train.SibSp[data_train.Survived == 0].value_counts()
df=pd.DataFrame({'suivived':survived,'nsurvived':nsurvived})
df.plot(kind='bar',stacked=True,title='SibSp')
旁系亲友数量在1~两个间的获救率更高一些
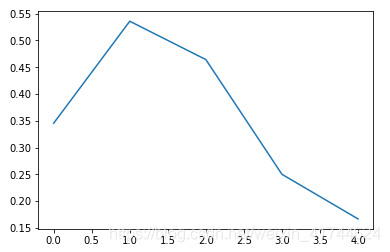
Parch:
import pandas as pd
import matplotlib.pyplot as plt
data_train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
survived=data_train.Parch[data_train.Survived == 1].value_counts()
nsurvived=data_train.Parch[data_train.Survived == 0].value_counts()
df=pd.DataFrame({'suivived':survived,'nsurvived':nsurvived})
df.plot(kind='bar',stacked=True,title='Parch')
plt.figure()
ss=survived/(survived+nsurvived)
plt.plot(ss)
直系亲属在1、3的获救概率比较高
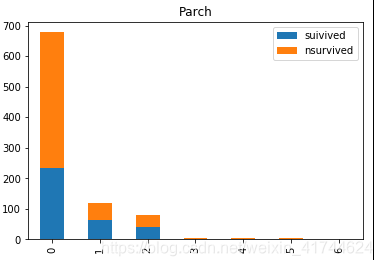
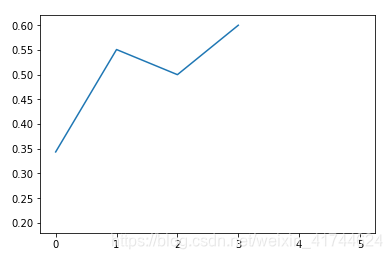
Ticket:
因为票也是随机生成的,同理乘客ID 所以不考虑做影响因素(实际已画图验证,毫无规律)
Fare:
import pandas as pd
import matplotlib.pyplot as plt
data_train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
survived=data_train.Fare[data_train.Survived == 1].value_counts()
nsurvived=data_train.Fare[data_train.Survived == 0].value_counts()
df=pd.DataFrame({'suivived':survived,'nsurvived':nsurvived})
df.plot(stacked=True,title='Fare')
plt.figure()
ss=survived/(survived+nsurvived)
plt.plot(ss)
票价就相当于舱位,票价高的舱位好,之前也验证了获救率高
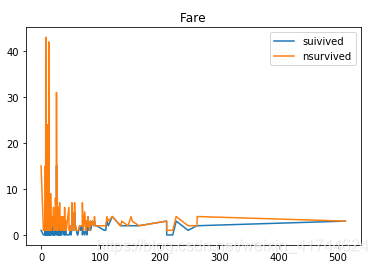
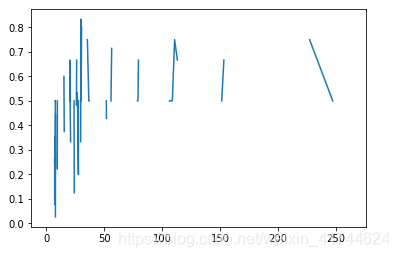
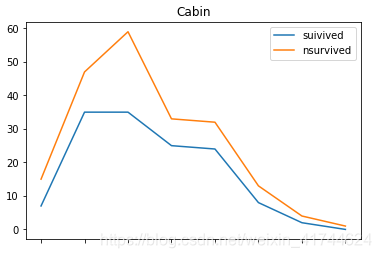
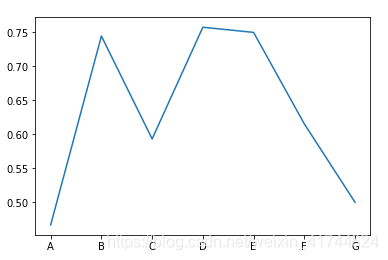
Cabin:
首先观察Cabin的信息缺失了很多,并且按照有道翻译理解是不同类别的甲板位置(A,B,C,D),所以根据信息取首字母来判别一下。
import pandas as pd
import matplotlib.pyplot as plt
data_train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
survived=data_train.Cabin.str.get(0)[data_train.Survived == 1].value_counts()
nsurvived=data_train.Cabin.str.get(0)[data_train.Survived == 0].value_counts()
df=pd.DataFrame({'suivived':survived,'nsurvived':nsurvived})
df.plot(stacked=True,title='Cabin')
plt.figure()
ss=survived/(survived+nsurvived)
plt.plot(ss)
可以看出来,B\D\E的幸存率高一些
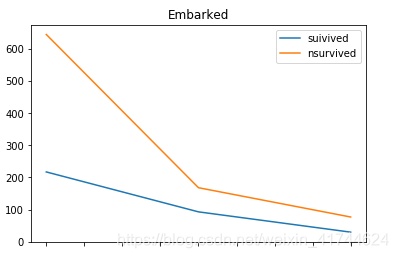
Embarked:
import pandas as pd
import matplotlib.pyplot as plt
data_train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
survived=data_train.Embarked[data_train.Survived == 1].value_counts()
nsurvived=data_train.Embarked[data_train.Survived == 0].value_counts()
df=pd.DataFrame({'suivived':survived,'nsurvived':nsurvived})
df.plot(stacked=True,title='Embarked')
plt.figure()
ss=survived/(survived+nsurvived)
plt.plot(ss)
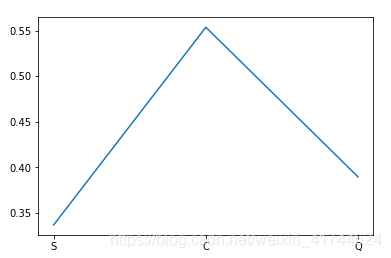
可以看出来,C港口的幸存率明显高一些
数据预处理
缺失值填充
Age:
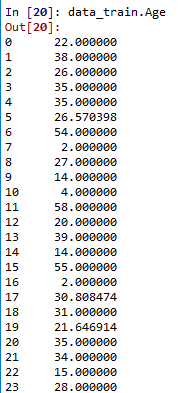
由上一部分我们发现的Age缺失:
用scikit-learn中的RandomForest来拟合一下缺失的年龄数据(注:RandomForest是一个用在原始数据中做不同采样,建立多颗DecisionTree,再进行average等等来降低过拟合现象,提高结果的机器学习算法)
(这一段是博主度娘来的处理方法,后续深入研究了RandomForest会附一篇教程链接在这个位置,此处立一个flag)
import pandas as pd
# 使用RandomForestClassifier,填补缺失的年龄
from sklearn.ensemble import RandomForestRegressor
data_train = pd.read_csv("C:/Users/10158565/Desktop/kaggle/train.csv")
# 把已有的数据特征值取出,放入到Random Forest Regressor中
age_df = data_train[['Age', 'Pclass','Fare', 'Parch', 'SibSp']]
# 把年龄做特征值转化,即根据上述放进来的特征值,把对应的转换为0、1两个数
age_df=pd.get_dummies(age_df)
# 分为已知年龄和未知年龄
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# 目标年龄值
y = known_age[:, 0]
# 特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补缺失数据
data_train.loc[ (data_train.Age.isnull()), 'Age' ] = predictedAges
此时Age列已经被处理完毕。
说明一下get_dummies:
因为逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化。
什么叫做因子化呢?举个例子:
以Cabin为例,原本一个属性维度,因为其取值可以是[‘yes’,‘no’],而将其平展开为’Cabin_yes’,'Cabin_no’两个属性
原本Cabin取值为yes的,在此处的"Cabin_yes"下取值为1,在"Cabin_no"下取值为0
原本Cabin取值为no的,在此处的"Cabin_yes"下取值为0,在"Cabin_no"下取值为1
我们使用pandas的"get_dummies"来完成这个工作,并拼接在原来的"data_train"之上
Embarked:
Embarked缺失量为2,很少,缺失Embarked信息的乘客的Pclass均为1,且Fare均为80,因为Embarked为C且Pclass为1的乘客的Fare中位数为80,所以缺失值填充为C。
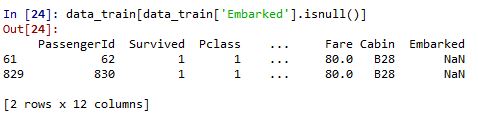
data_train['Embarked'] = data_train['Embarked'].fillna('C')
同组识别
按照对于数据的理解,对能够组合起来的项目进行分组查看
本思想为:按照理解,年龄和性别都是导致幸存率差异的问题,那么同一家庭中,女性和儿童与男性对比,幸存率会更高,那么就需要调整违反规律的组别(家庭)(从分组后人数大于1的组中对比)
data_train['Surname']=data_train['Name'].apply(lambda x:x.split(',')[0].strip())
Surname_Count = dict(data_train['Surname'].value_counts())
data_train['FamilyGroup'] = data_train['Surname'].apply(lambda x:Surname_Count[x])
Female_Child_Group=data_train.loc[(data_train['FamilyGroup']>=2) & ((data_train['Age']<=15) | (data_train['Sex']=='female'))]
Male_Adult_Group=data_train.loc[(data_train['FamilyGroup']>=2) & (data_train['Age']>15) & (data_train['Sex']=='male')]
查看结果:
Female_Child=pd.DataFrame(Female_Child_Group.groupby('Surname')['Survived'].mean().value_counts())
Female_Child.columns=['GroupCount']
Female_Child
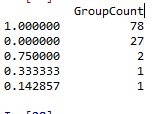
发现绝大部分女性和儿童组的平均存活率都为1或0,即同组(同一家庭中)的女性和儿童要么全部幸存,要么全部遇难。
再来看一下男性
Male_Adult=pd.DataFrame(Male_Adult_Group.groupby('Surname')['Survived'].mean().value_counts())
Male_Adult.columns=['GroupCount']
Male_Adult
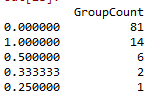
绝大部分成年男性组的平均存活率也为1或0。
因为普遍规律是女性和儿童幸存率高,成年男性幸存较低,所以我们把不符合普遍规律的反常组选出来单独处理。把女性和儿童组中幸存率为0的组设置为遇难组,把成年男性组中存活率为1的设置为幸存组,推测处于遇难组的女性和儿童幸存的可能性较低,处于幸存组的成年男性幸存的可能性较高。
Female_Child_Group=Female_Child_Group.groupby('Surname')['Survived'].mean()
Dead_List=set(Female_Child_Group[Female_Child_Group.apply(lambda x:x==0)].index)
print(Dead_List)
Male_Adult_List=Male_Adult_Group.groupby('Surname')['Survived'].mean()
Survived_List=set(Male_Adult_List[Male_Adult_List.apply(lambda x:x==1)].index)
print(Survived_List)

为了使处于这两种反常组中的样本能够被正确分类,对测试集中处于反常组中的样本的Age,Sex进行惩罚修改。
train=all_data.loc[all_data['Survived'].notnull()]
test=all_data.loc[all_data['Survived'].isnull()]
test.loc[(test['Surname'].apply(lambda x:x in Dead_List)),'Sex'] = 'male'
test.loc[(test['Surname'].apply(lambda x:x in Dead_List)),'Age'] = 60
test.loc[(test['Surname'].apply(lambda x:x in Dead_List)),'Title'] = 'Mr'
test.loc[(test['Surname'].apply(lambda x:x in Survived_List)),'Sex'] = 'female'
test.loc[(test['Surname'].apply(lambda x:x in Survived_List)),'Age'] = 5
test.loc[(test['Surname'].apply(lambda x:x in Survived_List)),'Title'] = 'Miss'
特征转换
选取特征,转换为数值变量,划分训练集和测试集
all_data=pd.concat([train, test])
all_data=all_data[['Survived','Pclass','Sex','Age','Fare','Embarked','Title','FamilyLabel','Deck','TicketGroup']]
all_data=pd.get_dummies(all_data)
train=all_data[all_data['Survived'].notnull()]
test=all_data[all_data['Survived'].isnull()].drop('Survived',axis=1)
X = train.as_matrix()[:,1:]
y = train.as_matrix()[:,0]
建模和优化
参数优化
用网格搜索自动化选取最优参数(事实上网上有很多更加优化的参数…)
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.feature_selection import SelectKBest
pipe=Pipeline([('select',SelectKBest(k=20)),
('classify', RandomForestClassifier(random_state = 10, max_features = 'sqrt'))])
param_test = {'classify__n_estimators':list(range(20,50,2)),
'classify__max_depth':list(range(3,60,3))}
gsearch = GridSearchCV(estimator = pipe, param_grid = param_test, scoring='roc_auc', cv=10)
gsearch.fit(X,y)
print(gsearch.best_params_, gsearch.best_score_)
训练模型
from sklearn.pipeline import make_pipeline
select = SelectKBest(k = 20)
clf = RandomForestClassifier(random_state = 10, warm_start = True,
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt')
pipeline = make_pipeline(select, clf)
pipeline.fit(X, y)
交叉验证
from sklearn import cross_validation, metrics
cv_score = cross_validation.cross_val_score(pipeline, X, y, cv= 10)
print("CV Score : Mean - %.7g | Std - %.7g " % (np.mean(cv_score), np.std(cv_score)))
预测
predictions = pipeline.predict(test)
submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": predictions.astype(np.int32)})
submission.to_csv(r"C:/Users/10158565/Desktop/kaggle_submit.csv", index=False)
当前分数
排名亮点,哎嘿嘿