B+树和B树都是多叉树,像我们常见的二叉查找树,AVL树,红黑树都属于二叉树。我们都知道,InnoDB的索引底层的数据结构就是B+树,那么为什么不是B树呢?
我们先通过这个网站(百度搜索 data structure visualization)可以在线直观的看到B+树和B树的结构的区别
我们分别往B+树和B树里面插入111,222,333,444,555这五条数据,看一下它的分布有什么不同
先看B+树
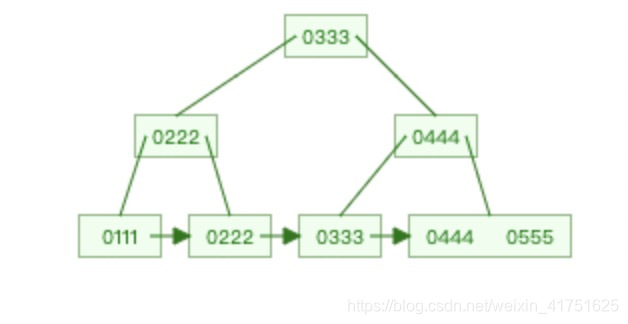
再来看B树
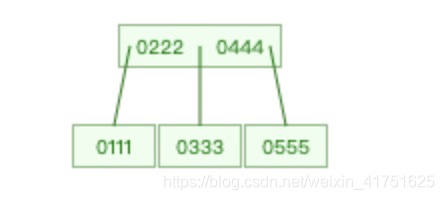
它们的区别如下:
1.B+树的所有数据都存放在叶子节点上,而B树的非叶子节点也存储数据。这样会导致B的查找效率要比B树要稳定。
2.B+树的叶子节点之间通过链表的形式相连,这样的话范围查找的效率更高。
3.B+树每个节点存储的关键字的个数等于度数,而B树每个节点存储的关键字个树为度数-1。
例如3阶的B树有三个孩子节点,只能存储例如15,30,那么三个节点的范围就是-∞到15,15到30,30到∞。而三阶的B+树,节点可以存储15,30,60也有三个子节点,存储的范围是15到30,
30到60,60到∞,相对比于B树,少了一个无穷小到最小值的一个范围,因为B+树是从最小值来作为起点的。
正式因为B+树的这三个特性,使得在查找时效率比B树要高,所以Innodb的索引的底层数据结构才会使用B+树来实现。