发送端:
应用层协议的每个包到达传输层,如果是tcp,会可能出现以下情况:
1)应用层的每个包被拆成多个tcp报文,分别发送,这是拆包;
2)应用层的多个包组成一个tcp报文发送,这是粘包;
接收端:
发送端的数据通过网络传输到了接受端的tcp缓冲区,不知道如何组成一个应用层的包,这必须由应用层解决,方法如下:
1)定长:应用层指定每个包的长度,如果数据不够,用空格补充,缺点是不够灵活,不能发送超出这个长度的包;
2)分割符:指定分割符,接收端一直读取数据直到读取到指定的分割符;
3)指定长度+数据:比如先发送4个字节的长度,表示后面要发送数据的字节数;
Http怎么解决拆包粘包的?
http请求报文格式
1)请求行:以\r\n结束;
2)请求头:以\r\n结束;
3)\r\n;
3)数据;
http响应报文格式
1)响应行:以\r\n结束;
2)响应头:以\r\n结束;
3)\r\n;
4)数据;
1)遇到第一个\r\n表示读取请求行或响应行结束;
2) 遇到\r\n\r\n表示读取请求头或响应头结束;
3)怎么读取body数据呢?
- 根据请求头或响应头的Content-Length,单位是字节;
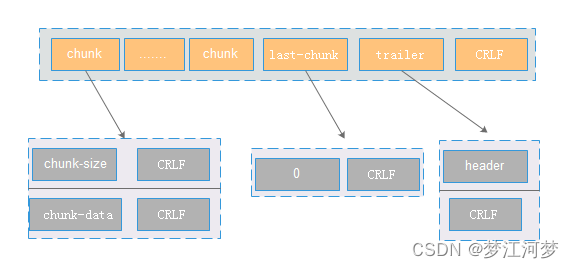
- chunked协议,取代Content-Length,如果请求头或者响应头有Transfer-Encoding: chunked,表示根据chunked协议协议读取数据,具体如下图:
读取第一个chunk,遇到CRLF表示读取长度完毕,接下来是第一个chunk的数据,也是以CRLF结束。当遇到长度为0的chunk,表示数据读取完毕。
思考:
这两种读取数据的方式本质都是一样的,有啥区别吗?