
第1章:异常处理简介
在Java里,异常就像是生活中的小插曲,有时候它们让咱们的程序出乱子,但处理得当,也能让咱们的代码更加健壮。Java中的异常处理,其实就是一种错误管理策略,让小黑在遇到问题时,能有序地解决,而不是让整个程序崩溃。
异常分为两大类:检查型异常(Checked Exceptions)和运行时异常(Runtime Exceptions)。检查型异常是那些编译期就需要咱们显式处理的异常,比如文件找不到时会抛出的FileNotFoundException。而运行时异常,如NullPointerException,则是编译期不检查的,它们多半是因为编码不当导致的。
处理异常的方式基本上就是“遇到问题,解决问题”。Java提供了try、catch和finally关键字,让小黑可以优雅地处理这些突如其来的问题。用try包围起可能出问题的代码,用catch来捕获并处理异常,最后用finally来执行那些无论如何都要执行的代码,比如资源的清理工作。
举个简单的例子,假设小黑要读取一个文件,但这个文件可能不存在,这时就可能会抛出FileNotFoundException:
try {
FileInputStream file = new FileInputStream("咱们的文件.txt");
// 做一些读取文件的操作
} catch (FileNotFoundException e) {
System.out.println("糟糕,文件找不到了!");
} finally {
System.out.println("不管发生了什么,小黑都会看到这句话。");
}
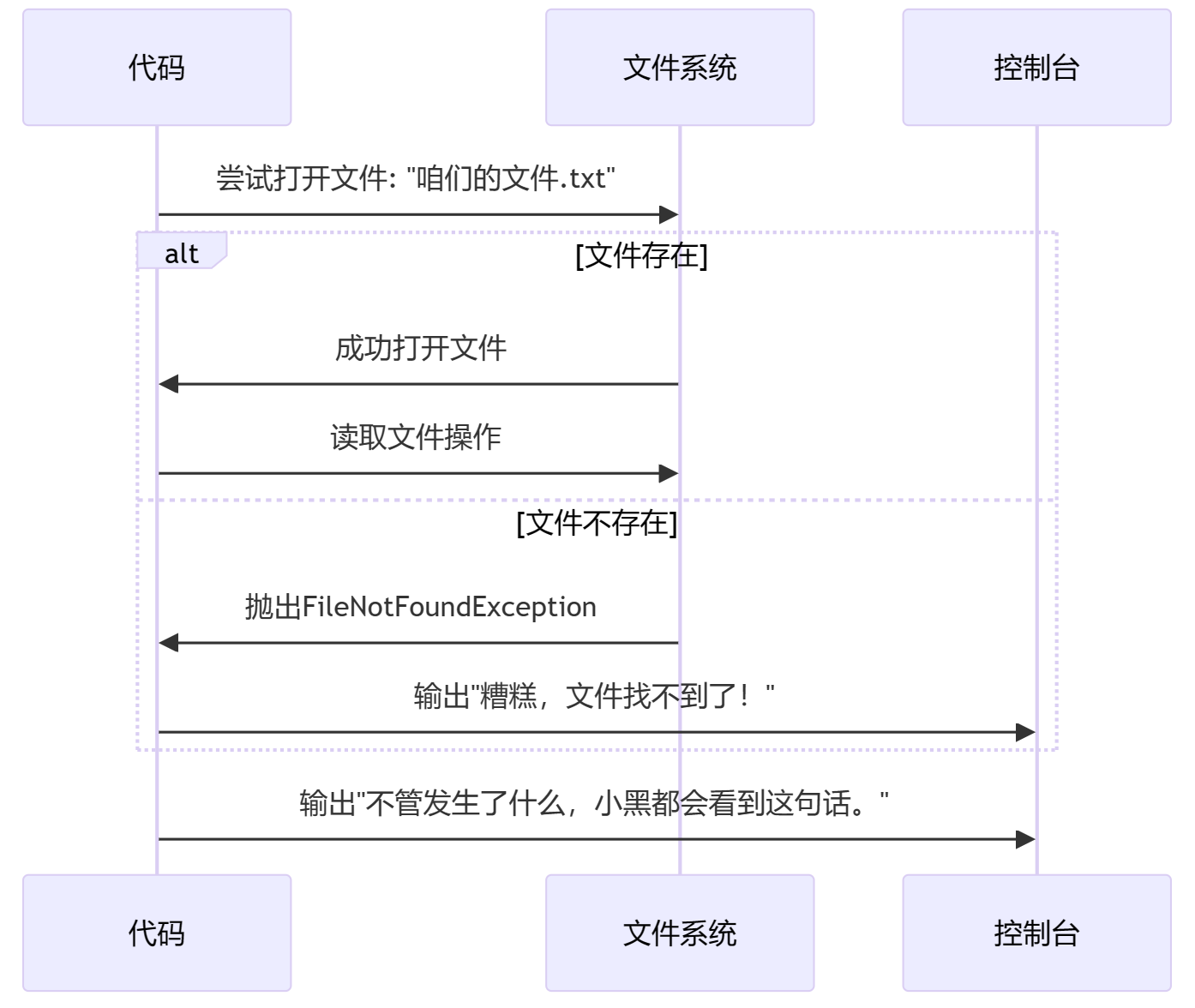
这段代码演示了基本的异常处理流程:尝试执行某些操作(try),如果出现了特定的异常(FileNotFoundException),就捕获它并做出响应(catch),最后无论是否发生异常都执行一些收尾工作(finally)。
第2章:Java异常体系结构
深入Java的异常体系,就像探索一个层次分明的家族树。在这棵树的顶端,是Throwable类,它是所有错误和异常的大家长。Throwable有两个重要的子类:Error和Exception。Error类代表那些严重的错误,如系统崩溃、虚拟机出错,通常这些情况下,小黑是没法处理的,所以这类错误一般不用小黑操心。
而Exception类下面,就是咱们经常需要处理的异常了。Exception又分为两大派系:检查型异常和运行时异常。运行时异常的特点是Java编译器不要求强制处理它们,它们都是RuntimeException的子类。检查型异常则不同,Java编译器会要求咱们必须处理这些异常,否则程序连编译都过不了。
来看看这个家族树的简化版:
ThrowableError(如OutOfMemoryError,通常不由程序员处理)ExceptionRuntimeException(如NullPointerException,ArrayIndexOutOfBoundsException)- 其他检查型异常(如
IOException,SQLException)
这个结构告诉咱们,异常处理不仅仅是捕获异常那么简单,了解异常的类型和层次,可以帮助小黑更精确地处理问题。以NullPointerException为例,它是RuntimeException的一个子类,通常是因为访问了未初始化的对象。
小黑偷偷告诉你一个买会员便宜的网站: 小黑整的视頻会园优惠站
第3章:异常处理机制
当小黑的Java程序在运行时遇到问题,Java提供了一套机制来应对,这就是咱们常说的异常处理机制。通过使用try、catch、finally这三个关键字,小黑可以优雅地处理程序中可能出现的各种异常情况。
使用try和catch
try块让小黑把可能出错的代码放在里面,一旦里面的代码抛出异常,就会跳到catch块。catch块就是用来捕获并处理这个异常的。咱们可以有多个catch块来捕获不同类型的异常。
来看一个例子,假设小黑要处理一个可能会因为除数为零而抛出ArithmeticException的除法操作:
try {
int 结果 = 10 / 0; // 这里会抛出ArithmeticException
} catch (ArithmeticException e) {
System.out.println("除数不能为零!");
}
这段代码尝试执行一个除法操作,但因为除数是零,所以会抛出ArithmeticException。catch块捕获到这个异常,并打印出一条友好的错误信息。
使用finally
finally块是可选的,它包含的代码无论是否发生异常都会执行。这对于资源的清理工作特别有用,比如关闭文件流或数据库连接。
FileInputStream file = null;
try {
file = new FileInputStream("咱们的文件.txt");
// 使用文件流进行一些操作
} catch (FileNotFoundException e) {
System.out.println("文件找不到!");
} finally {
if (file != null) {
try {
file.close(); // 确保文件流被关闭
} catch (IOException e) {
System.out.println("文件流关闭时出错!");
}
}
}
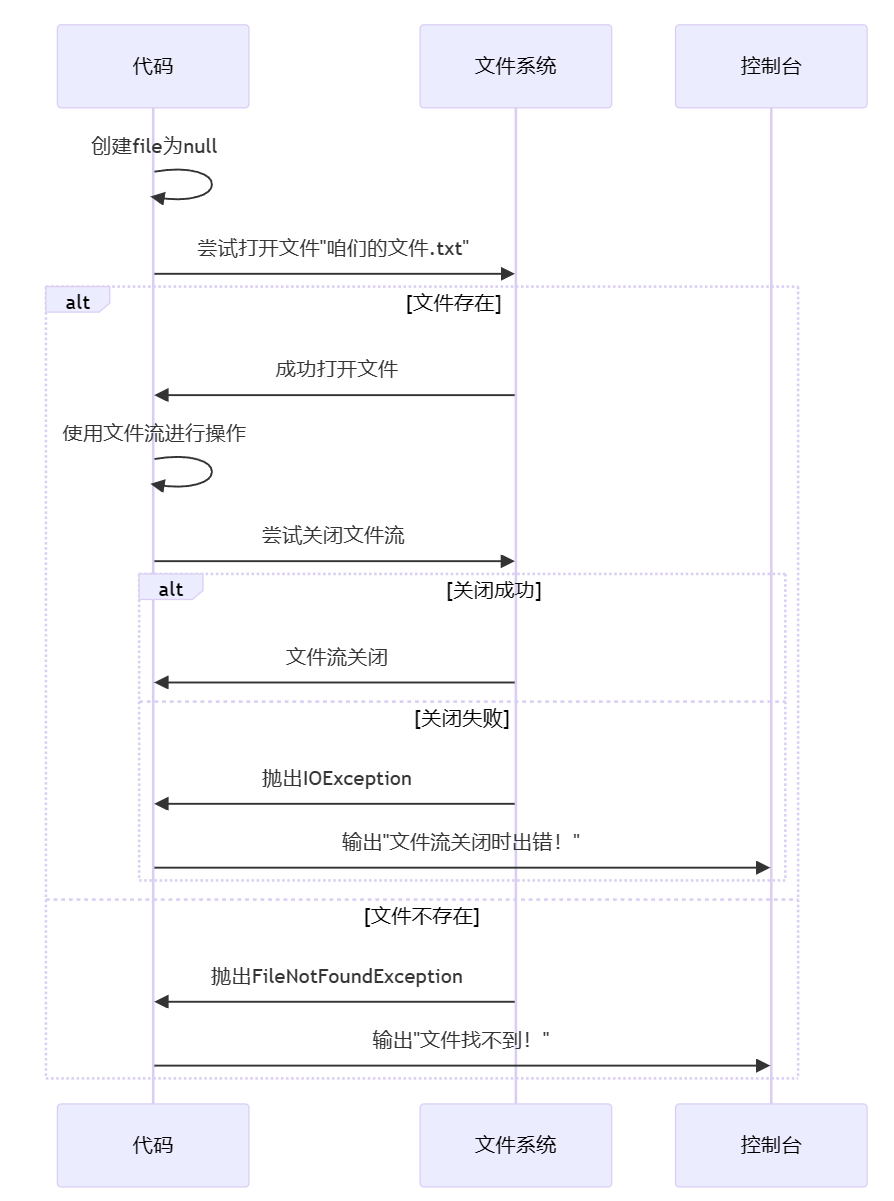
在这个例子中,无论文件是否成功打开,或者是否发生了FileNotFoundException,finally块都会执行,确保文件流被正确关闭。
多重捕获和捕获顺序
Java允许咱们在同一个try块后面跟多个catch块,用来捕获不同类型的异常。但要注意,子类的异常类型应该在父类异常类型之前捕获,否则会有编译错误,因为父类异常已经包含了子类异常,子类异常的catch块永远不会执行。
try {
// 可能抛出多种异常的代码
} catch (ArrayIndexOutOfBoundsException e) {
// 处理数组索引越界异常
} catch (Exception e) {
// 处理其他所有异常
}
通过这样的机制,Java让异常处理变得非常灵活和强大。小黑可以根据需要精确地控制异常处理的逻辑,从而写出既健壮又易于维护的代码。
第4章:自定义异常
在Java的异常处理中,小黑不仅可以使用Java提供的标准异常类,有时候为了让异常处理更加精准,还可以创建自定义的异常类。自定义异常让错误处理更加灵活,可以更好地满足特定需求。
为什么需要自定义异常
- 明确异常类型:通过自定义异常,可以创建更具体的错误类型,让异常处理更加清晰。
- 传递错误信息:自定义异常可以携带更多的错误信息,比如错误代码、详细描述等,有助于问题的诊断和解决。
- 统一异常处理:在一个大型项目中,定义统一的异常体系可以让异常处理更加规范化。
如何创建自定义异常
创建自定义异常其实很简单,只需要继承Exception类(或者它的任何子类),然后添加适合自己需要的构造器即可。如果小黑想让自定义的异常是非检查型(unchecked)的,那就应该继承RuntimeException。
来看一个简单的例子,假设小黑在开发一个学生管理系统,需要一个表示“学号不存在”的异常:
public class StudentNotFoundException extends Exception {
public StudentNotFoundException(String message) {
super(message);
}
}
这个StudentNotFoundException类继承了Exception,是一个检查型异常。它有一个接收错误消息作为参数的构造器,这个消息会传给父类的构造器。
使用自定义异常
有了自定义的异常类之后,就可以在代码中抛出和捕获它了。比如在学生管理系统中,当尝试查找一个不存在的学生时,可以抛出StudentNotFoundException:
public Student findStudentById(String studentId) throws StudentNotFoundException {
// 假设这里是查找学生的代码
if (学生不存在) {
throw new StudentNotFoundException("学号为" + studentId + "的学生不存在。");
}
return 学生;
}
在调用findStudentById方法的地方,需要捕获并处理StudentNotFoundException:
try {
Student student = findStudentById("12345");
// 做一些处理
} catch (StudentNotFoundException e) {
System.out.println(e.getMessage());
}
通过自定义异常,小黑让错误处理更加具体和清晰。不仅如此,这还有助于提升代码的可读性和可维护性,让其他开发者也能快速理解异常的意图。
自定义异常是Java异常处理中一个非常强大的特性,它让小黑能够根据具体的业务需求,设计出符合项目特色的异常体系。在实际开发中灵活运用,可以大大提升项目的质量和可维护性。
第5章:最佳实践:异常处理策略
在Java开发中,正确地处理异常是保证代码质量的关键。但是,怎样的异常处理方式才是最佳实践呢?这一章,咱们将探讨一些在异常处理时应该遵循的原则和策略。
明确何时捕获异常
在决定在哪个层次捕获异常时,小黑应该考虑以下几点:
- 能否在当前层次解决:如果可以立即修正异常情况并继续执行,那么在当前层次捕获异常是有意义的。
- 异常信息的完整性:如果在更高的层次捕获异常可以提供更完整的错误信息,那么应该将异常传递上去。
- 避免过度捕获:捕获了异常但只是简单地打印日志,然后重新抛出,这种做法既没有解决问题,也使错误处理变得复杂。只有在真正需要处理异常的地方捕获它。
合理使用检查型和非检查型异常
- 检查型异常:当希望调用者必须处理某个问题时,使用检查型异常。它们通常用于外部错误,如文件不存在或网络问题。
- 非检查型异常:对于编程错误,如数组越界或空指针,使用非检查型异常。这些错误应该在开发过程中被发现并修正。
提供有用的错误信息
当抛出异常时,应该提供尽可能多的上下文信息,以帮助定位和解决问题。比如,不仅仅告诉调用者“文件读取错误”,而是应该说明哪个文件不能读取,原因是什么。
优先使用标准异常
在Java标准库中,已经定义了许多有用的异常类。在可能的情况下,优先使用这些标准异常。比如,如果某个方法的参数不合法,就抛出IllegalArgumentException,而不是自定义一个新的异常类。
异常链
在捕获一个异常并抛出另一个异常时,应该保留原始异常的信息。这可以通过异常链完成,即在创建新异常时,将原始异常作为一个参数传递给构造器。
try {
// 可能抛出IOException的代码
} catch (IOException e) {
throw new MyCustomException("更高级别的错误描述", e);
}
这样做的好处是即使在更高的层次处理异常,也不会丢失原始异常的信息,便于问题的定位和解决。
通过遵循这些原则和策略,小黑可以在Java项目中实现更有效、更清晰的异常处理。记住,良好的异常处理不仅可以提高代码的健壮性,还能提升开发效率和维护的便利性。
第6章:日志与异常处理
在Java中,正确地记录日志同异常处理一样重要。良好的日志策略不仅可以帮助咱们快速定位问题,还能提供程序运行状态的清晰视图。在处理异常时,结合日志记录,可以让问题诊断和后续处理变得更加高效。
为什么需要日志
- 问题追踪:当异常发生时,日志提供了一个查看应用程序历史行为的窗口,帮助咱们理解问题发生的上下文。
- 状态监控:通过记录关键操作的成功或失败,日志可以帮助监控系统的健康状况。
- 性能评估:日志还可以帮助分析程序性能,指出可能的瓶颈。
日志级别
选择合适的日志级别非常关键,这可以确保咱们记录的信息既有用又不会过多地干扰正常的程序运行。常见的日志级别包括:
- ERROR:严重问题,阻止程序的部分或全部功能正常运行。
- WARN:潜在的问题,可能会影响程序的性能或稳定性。
- INFO:重要的运行时事件,反映程序的正常运作。
- DEBUG:对调试有帮助的详细信息,通常只在开发或测试环境中启用。
- TRACE:更细粒度的调试信息,用于深入分析问题。
使用日志框架
在Java里,有几个流行的日志框架可以使日志记录变得简单而强大,如Log4j、SLF4J和Logback。这些框架提供了灵活的配置选项,包括日志级别、输出格式和目的地等。
以SLF4J为例,咱们可以这样记录一个异常:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Example {
private static final Logger logger = LoggerFactory.getLogger(Example.class);
public void doSomething() {
try {
// 可能抛出异常的代码
} catch (Exception e) {
logger.error("处理过程中发生错误", e);
}
}
}
在这个例子中,如果doSomething方法中的代码抛出了异常,咱们会在日志中记录一条错误级别的消息,并附上异常的堆栈跟踪。这样不仅记录了错误发生的事实,还提供了足够的细节来帮助分析和解决问题。
最佳实践
- 适时记录:在异常处理逻辑中适时记录日志,包括捕获异常、重要的业务逻辑节点等。
- 恰当的级别:根据消息的重要性选择合适的日志级别,避免过多无关紧要的信息干扰问题分析。
- 清晰的信息:在日志消息中提供清晰、准确的描述和足够的上下文信息,使其对问题定位真正有帮助。
结合良好的异常处理策略和日志记录实践,可以极大地提高Java应用的可靠性和维护性。通过日志,咱们不仅能够追踪到问题的源头,还能分析出现问题的环境和条件,为修复问题和优化系统提供强大的支持。
第7章:异常处理的性能考虑
当咱们在Java中处理异常时,不仅要考虑如何使代码更健壮、错误信息更清晰,还要考虑异常处理对性能的影响。虽然异常处理是Java程序不可或缺的一部分,但如果不当使用,它们可能会对性能产生负面影响。这一章,咱们将深入探讨异常处理的性能考虑,并提供一些优化的建议。
异常的成本
在Java中,创建和抛出异常的成本相对较高,原因如下:
- 堆栈追踪的生成:当异常被抛出时,JVM会生成异常的堆栈追踪信息,这个过程涉及到当前线程堆栈帧的遍历,这是一个耗时的操作。
- 异常对象的创建:每次抛出异常时,都会创建一个新的异常对象,这增加了垃圾收集器的负担。
避免不必要的异常
为了提高性能,咱们应该避免在正常的控制流程中使用异常。异常应该保留用于处理真正的错误情况,而不是用作常规的流程控制。例如,使用异常来处理用户输入错误或预期内的条件变化通常不是一个好的选择。
使用异常池
对于频繁抛出的异常,考虑使用异常池的技巧可以减少异常创建的开销。这意味着预先创建一组异常对象并在需要时重用它们,而不是每次都创建新的异常。这种方法需要小心使用,以避免共享异常对象导致的状态污染问题。
延迟加载堆栈追踪
如果异常主要用于传递错误状态,而不是立即进行错误诊断,那么可以考虑延迟加载或完全禁用堆栈追踪。一些日志框架和异常处理库支持这种操作,可以显著减少异常处理的开销。
代码示例
假设咱们有一个方法,它在特定条件下频繁抛出异常,咱们可以通过预先创建异常对象来减少创建异常的开销:
public class ResourcePool {
private static final MyResourceException resourceException = new MyResourceException("资源不足");
public Resource acquireResource() {
if (资源不足) {
throw resourceException;
}
return 资源;
}
}
请注意,这个例子只是为了演示目的,实际应用中,重用异常对象需要谨慎考虑,因为它可能导致错误的堆栈追踪信息。
结论
在开发高性能的Java应用时,妥善管理异常处理是非常重要的。通过避免不必要的异常、优化异常对象的创建和管理,以及合理使用日志记录,可以在不牺牲代码可读性和健壮性的前提下,提高应用的性能。总之,合理的异常处理策略不仅能帮助咱们编写出更稳定的代码,还能在保持高性能的同时,提升用户体验。
第8章:总结与实践建议
经过前面七章的深入探讨,咱们已经对Java中的异常处理有了全面的了解。从基本概念、体系结构,到最佳实践、性能考虑,咱们一步步深入挖掘,希望这些内容能够帮助大家在实际开发中更加得心应手地处理异常。在本章节中,小黑将总结前面章节的要点,并提供一些实践建议,帮助大家形成健全的异常处理习惯。
关键要点回顾
- 理解Java异常体系:清楚地理解检查型异常与非检查型异常的区别,以及异常类的继承结构,有助于正确地使用异常。
- 异常处理机制的正确使用:掌握
try、catch、finally关键字的使用,以及如何正确地捕获和处理异常。 - 自定义异常的使用:在合适的场景下创建自定义异常,可以使错误信息更加清晰,有助于问题的快速定位和解决。
- 遵循最佳实践:明确何时捕获异常,合理使用检查型和非检查型异常,提供有用的错误信息,以及优先使用标准异常。
- 日志与异常处理的结合:合理地记录异常信息,选择合适的日志级别,以帮助问题的追踪和分析。
- 性能考虑:在保证代码健壮性的同时,注意异常处理的性能影响,避免不必要的异常和优化异常处理逻辑。
实践建议
- 预防优于治疗:在编码过程中,通过代码审查和测试来尽早发现并修正潜在的异常源,可以减少运行时异常的发生。
- 精准捕获异常:尽量捕获最具体的异常类型,而不是简单地使用
catch (Exception e),这样可以更精确地处理错误。 - 避免异常掩盖:在处理异常时,不应该忽略捕获到的异常,即使认为它们不重要。如果确实需要忽略,至少应该在日志中记录下来。
- 合理利用
finally:确保使用finally块来释放资源,如关闭文件流或数据库连接,即使前面的代码抛出了异常。 - 利用日志框架:选择合适的日志框架,并合理配置日志级别,这样即可以获得足够的运行时信息,又不会过多影响性能。
通过以上的学习和总结,希望大家能够更加自信地在Java项目中处理异常。记住,良好的异常处理策略不仅能提高代码的可读性和健壮性,还能提升开发和维护的效率。在日常开发中不断实践和优化,相信大家都能成为异常处理的高手。