
简介:本资源详细介绍了如何构建一个基于Python的循环神经网络(RNN)的情感分类系统,用于分析文本数据的情感倾向。系统利用了Python强大的数据处理和机器学习库,通过RNN及其变体LSTM和GRU来理解文本的上下文信息。系统开发包括数据预处理、模型构建、训练、评估和部署等步骤,适用于市场分析、客户满意度评估和舆情监控等应用。同时,该项目也适合作为学习NLP、深度学习和Python编程实践的毕业设计。
1. Python数据处理和机器学习应用
在当今的数据驱动时代,Python已成为数据科学和机器学习领域的主流工具之一。本章将探索Python在数据处理方面的强大功能,以及它如何推动机器学习应用的发展。
1.1 Python数据处理基础
Python数据处理的基石是其丰富的库生态系统。Pandas库提供了数据结构和数据分析工具,使我们能够轻松地导入、清洗、转换和重塑数据。NumPy和SciPy为数值计算提供了支持,Matplotlib和Seaborn则助力于数据可视化,让我们对数据有直观的理解。
示例代码块展示了如何使用Pandas进行数据清洗:
import pandas as pd
# 读取CSV文件数据
df = pd.read_csv('data.csv')
# 数据清洗示例:删除缺失值
df_cleaned = df.dropna()
# 数据转换示例:将字符串日期转换为日期时间格式
df_cleaned['date'] = pd.to_datetime(df_cleaned['date'])
# 输出清洗后的数据
print(df_cleaned.head())
1.2 机器学习应用
机器学习在处理复杂数据、识别模式和做出预测方面具有独特优势。Python的机器学习库如scikit-learn和TensorFlow,提供了各种算法和模型,从简单的线性回归到复杂的深度神经网络。
以下代码展示了如何使用scikit-learn进行简单的线性回归:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 假设已有特征数据X和目标变量y
X = df_cleaned.drop('target', axis=1).values
y = df_cleaned['target'].values
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型并拟合训练数据
model = LinearRegression()
model.fit(X_train, y_train)
# 使用模型进行预测并计算均方误差
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error: {mse}")
以上章节内容和代码块不仅体现了Python在数据处理和机器学习领域的应用,也逐步引导读者了解如何将理论与实践相结合。在接下来的章节中,我们将深入探讨循环神经网络及其在处理序列数据时的优化方法。
2. 循环神经网络(RNN)及其变体LSTM和GRU
2.1 循环神经网络基础
2.1.1 RNN的基本概念和工作机制
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。与传统全连接神经网络或卷积神经网络不同,RNN具有记忆功能,能够处理不同长度的输入序列,并且能够记住前一个状态的信息。
基本工作机制是这样的:当处理序列数据时,RNN会将当前的输入与上一时刻的隐藏状态结合起来,产生当前时刻的输出和新的隐藏状态。隐藏状态作为网络的记忆,可以让RNN在处理序列时考虑到之前的信息。这使得RNN非常适合处理和预测序列数据,例如自然语言处理中的文本、语音识别等。
一个RNN单元的数学表示可以是:
h_t = f(h_t-1, x_t)
其中,h_t是当前隐藏状态,h_t-1是上一时刻的隐藏状态,x_t是当前时刻的输入,f代表RNN单元的激活函数。
2.1.2 RNN在序列数据中的应用
由于RNN能够处理序列数据,它在很多应用中都扮演着核心角色:
- 自然语言处理(NLP) :RNN用于机器翻译、语音识别、文本生成等领域。
- 时间序列分析 :在金融预测、天气预报等时间序列数据处理中。
- 音乐和视频处理 :RNN能够处理音频和视频中的时间序列信息,用于音乐生成或视频分析。
尽管RNN有诸多优势,但它在处理长序列数据时存在梯度消失或梯度爆炸的问题。这是由于长时间依赖信息的传递导致的。为了解决这个问题,研究人员提出了长短时记忆网络(LSTM)和门控循环单元(GRU)。
2.2 LSTM网络详解
2.2.1 LSTM的设计思想和结构特点
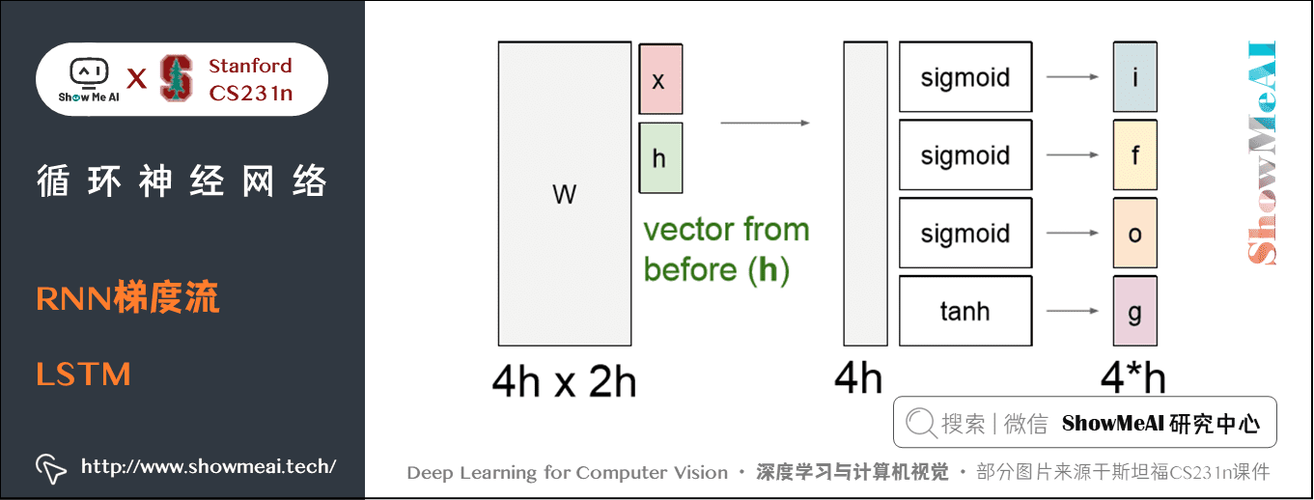
长短时记忆网络(Long Short-Term Memory,LSTM)是一种特殊的RNN,能够学习长期依赖信息。LSTM通过引入三个门控结构:遗忘门、输入门和输出门,有效地解决了传统RNN的梯度问题。
LSTM单元的主要结构包括:
- 遗忘门 :控制前一隐藏状态中哪些信息需要被遗忘。
- 输入门 :决定新输入数据的哪些部分需要被存储。
- 输出门 :决定下一个隐藏状态应该输出哪些信息。
LSTM的数学形式表示为:
f_t = σ(W_f * [h_{t-1}, x_t] + b_f) i_t = σ(W_i * [h_{t-1}, x_t] + b_i) o_t = σ(W_o * [h_{t-1}, x_t] + b_o) c_t = f_t * c_{t-1} + i_t * g(W_c * [h_{t-1}, x_t] + b_c) h_t = o_t * tanh(c_t)
其中,f_t、i_t和o_t分别是遗忘门、输入门和输出门的输出,c_t是细胞状态,h_t是当前隐藏状态。σ表示sigmoid函数,tanh是双曲正切函数,W和b分别是权重和偏置参数。
2.2.2 LSTM与传统RNN的对比分析
与传统RNN相比,LSTM有以下优势:
- 长期依赖性 :LSTM通过门控机制有效避免了梯度消失问题,能够更好地保留长时间序列的信息。
- 梯度稳定性 :遗忘门有助于丢弃不相关的信息,保持梯度稳定,避免梯度爆炸。
然而,LSTM也有它的缺点:
- 计算复杂性 :由于引入了多个门控结构,LSTM的计算量相对较大。
- 训练难度 :门控结构增加了模型训练的难度,有时需要更长时间的训练才能收敛。
2.3 GRU网络探索
2.3.1 GRU的基本原理
门控循环单元(Gated Recurrent Unit,GRU)是LSTM的变体,它简化了LSTM的结构。GRU通过合并遗忘门和输入门到一个更新门,并引入了一个新的“候选隐藏状态”,简化了LSTM中的状态存储机制。
GRU的两个主要门控结构是:
- 更新门 :决定应该保留多少旧信息和加入多少新信息。
- 重置门 :控制新输入信息的影响范围。
数学表示为:
z_t = σ(W_z * [h_{t-1}, x_t]) r_t = σ(W_r * [h_{t-1}, x_t]) h_t tilde = tanh(W * [r_t * h_{t-1}, x_t]) h_t = (1 - z_t) * h_{t-1} + z_t * h_t tilde
其中,z_t是更新门,r_t是重置门,h_t tilde是候选隐藏状态,h_t是当前隐藏状态。
2.3.2 GRU在时间序列分析中的优势
GRU相对于LSTM而言,模型参数更少,因此它在训练时更快,且在很多情况下需要的数据量更小。GRU在时间序列分析中表现良好,它能够在保持足够性能的同时减少计算量和模型复杂性。其在语音识别、手写识别和很多需要处理长序列数据的NLP任务中得到了广泛应用。
总结来说,LSTM和GRU的引入有效地解决了传统RNN在处理长序列数据时的梯度问题,使得序列学习任务得到了极大的进步。选择LSTM还是GRU,取决于具体的任务需求、计算资源和对模型复杂性的容忍度。在下一章节中,我们将深入探讨文本数据情感分类系统的设计和优化。
3. 文本数据情感分类系统
文本数据情感分类是自然语言处理领域的一个重要应用,它涉及到计算机理解和处理人类情感的能力,广泛应用于市场分析、公关舆情监控以及社交媒体内容管理等领域。本章将从理论基础到系统设计,详细探讨构建一个高效情感分类系统所需的各个环节。
3.1 情感分类的理论基础
3.1.1 情感分析的定义和应用场景
情感分析,也称为意见挖掘,是通过自然语言处理技术分析文本数据,识别和提取其中的情感倾向,如正面、负面或中立。这类技术常应用于评论分析、市场趋势预测和消费者反馈管理等场景。它使得企业能够量化地衡量客户对其产品或服务的满意度和感受,从而做出更加精准的决策。
3.1.2 情感分类的常见问题和挑战
情感分类面临诸多挑战,如讽刺、双关语的识别困难,主观性和上下文依赖性强,不同领域的专业术语影响等。此外,处理多语言数据时,需要考虑翻译或语言之间的情感表达差异,这无疑增加了系统的复杂度。
3.2 情感分类系统的设计
3.2.1 系统框架和功能模块
一个典型的情感分类系统一般包括数据采集、预处理、特征提取、模型训练、评估和部署等模块。数据采集模块负责收集文本数据;预处理模块进行数据清洗和分词等;特征提取模块则负责提取文本特征;模型训练模块利用预处理后的数据来训练情感分类模型;评估模块则对模型的性能进行评价;最后,模型部署模块将训练好的模型部署到实际应用中。
# 示例:一个简单的文本分类系统框架(伪代码)
import preprocessing as pre
import feature_extraction as fe
import model_training as mt
def text_classification_system(data):
# 数据预处理
processed_data = pre.clean_and_tokenize(data)
# 特征提取
features = fe.extract_features(processed_data)
# 模型训练
trained_model = mt.train_model(features)
# 模型评估(此处略过评估过程)
# 模型部署(此处略过部署过程)
return trained_model
3.2.2 情感分类算法的选择和优化
情感分类算法的选择取决于具体应用的需求和数据的特性。常见的算法包括朴素贝叶斯、支持向量机、深度学习方法等。深度学习方法,如循环神经网络(RNN)、卷积神经网络(CNN)和Transformer,因其强大的特征学习能力而越来越受到青睐。在算法选择后,通常需要对模型参数进行优化,以提高分类的准确性。
# 示例:朴素贝叶斯分类器应用(伪代码)
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
# 假设已有一组预处理后的文本数据及其标签
X_train, y_train = pre.get_data()
# 将文本数据转换为词频特征
vectorizer = CountVectorizer()
X_train_vectors = vectorizer.fit_transform(X_train)
# 使用朴素贝叶斯分类器进行训练
clf = MultinomialNB()
clf.fit(X_train_vectors, y_train)
# 对新的文本数据进行情感分类
def classify_new_text(text):
text_vector = vectorizer.transform([text])
prediction = clf.predict(text_vector)
return prediction[0]
在本章中,我们首先介绍了情感分析的定义和应用场景,并探讨了情感分类面临的挑战。接着,我们讲述了情感分类系统设计的框架和各功能模块,以及如何选择和优化情感分类算法。下一章节将深入探讨数据预处理的方法,这是任何文本分析系统不可或缺的重要环节。
4. 数据预处理方法
数据预处理是任何数据密集型任务的重要环节,特别是在自然语言处理和机器学习项目中。预处理的目的是确保输入到模型中的数据是干净、一致且具有描述性特征的,这样才能提高模型的效果。在本章节中,我们将探讨文本数据的清洗和特征提取方法、词向量表示,以及如何构建情感词汇表。
4.1 文本数据清洗和特征提取
文本数据清洗和特征提取是自然语言处理的基石。原始文本数据常常包含大量无关信息,如标点符号、停用词、拼写错误等,这些都会干扰模型学习到真正的语言规律。因此,清洗文本并提取重要特征对于任何NLP任务来说都是至关重要的。
4.1.1 文本清洗的步骤和方法
首先,文本清洗通常包括以下步骤:
- 移除HTML或XML标记,保留干净的文本内容。
- 转换字符到统一的格式(例如,将所有字符转换为小写)。
- 移除标点符号和特殊字符。
- 分词,将句子分解为单词或词组。
- 移除停用词,即语言中频繁出现但对理解文本意义贡献较小的词汇(如“的”,“是”,“在”等)。
- 词干提取或词形还原,将单词还原为基本形式。
下面是一个使用Python进行文本清洗的简单示例:
import re
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# 示例文本
text = "NLTK is a leading platform for building Python programs to work with human language data."
# 移除标点符号
text = re.sub(r'[^\w\s]', '', text)
# 转换为小写
text = text.lower()
# 分词
words = text.split()
# 移除停用词
stop_words = set(stopwords.words('english'))
words = [word for word in words if word not in stop_words]
# 词形还原
lemmatizer = WordNetLemmatizer()
words = [lemmatizer.lemmatize(word) for word in words]
# 输出清洗后的文本
print(words)
4.1.2 特征提取技术及其重要性
特征提取是指从原始数据中提取出有助于预测或分类的数值特征。在文本数据中,最常用的特征提取技术是词袋模型(Bag of Words)和TF-IDF(Term Frequency-Inverse Document Frequency)。这些技术把文本数据转换成数值向量形式,以便机器学习算法可以处理。
词袋模型忽略了单词的顺序和语法结构,只关注单词出现的频率。而TF-IDF则在词袋模型的基础上,进一步考虑了单词在文档中的重要性,通过减小常见词汇的影响来增强模型的区分能力。
下面是一个使用Python的 sklearn 库来提取TF-IDF特征的示例:
from sklearn.feature_extraction.text import TfidfVectorizer
# 示例文本数据
texts = [
"NLTK is a leading platform for building Python programs",
"NLP is a field of computer science and artificial intelligence",
"Python is a widely used programming language"
]
# 初始化TF-IDF向量化器
tfidf_vectorizer = TfidfVectorizer()
# 拟合并转换文本数据
tfidf_matrix = tfidf_vectorizer.fit_transform(texts)
# 输出TF-IDF矩阵
print(tfidf_matrix.toarray())
# 查看每个单词对应的索引
print(tfidf_vectorizer.get_feature_names_out())
通过上述步骤,原始文本数据被清洗并转换为结构化的数值数据,为后续的机器学习模型训练做好了准备。
在接下来的章节中,我们将进一步探讨如何使用词向量技术来表示词汇,并创建情感词汇表,以此为文本数据赋予情感色彩,为情感分类任务打下基础。
5. 模型构建和参数设置
5.1 模型的选择和构建过程
5.1.1 模型选择的考量因素
在模型选择的过程中,首先要根据问题的性质来决定适合的模型类型。对于分类问题,可以考虑决策树、随机森林、支持向量机(SVM)、神经网络等。对于回归问题,则可以考虑线性回归、岭回归、神经网络等。除了问题类型,还应该考虑以下因素:
- 数据量:对于大数据集,复杂的模型(如深度学习模型)可能更为合适;而对于小数据集,可能更适合使用简单模型。
- 计算资源:不同的模型对于计算资源的需求不同。例如,深度学习模型通常需要更强的计算能力。
- 预处理需求:有些模型对数据的预处理要求较高,比如需要特征缩放等。
- 解释性:如果需要对模型的结果进行解释,可能会选择一些可解释性强的模型,如决策树。
- 性能指标:最终选择模型时,需要参考性能指标(如准确率、召回率等),以确定模型是否满足业务需求。
5.1.2 模型构建的步骤和技巧
构建模型通常涉及以下几个步骤:
- 数据准备:将数据分为训练集、验证集和测试集。
- 特征工程:根据问题构建特征,可能包括特征选择和特征构造。
- 模型初始化:选择基础模型结构并初始化参数。
- 训练模型:使用训练集数据来训练模型。
- 超参数调优:在验证集上进行超参数调整,以提高模型性能。
在构建模型时,可以采取以下技巧:
- 数据增强:通过旋转、平移、缩放等手段增加训练数据的多样性。
- 集成学习:通过组合多个模型来提高整体性能。
- 正则化:使用L1、L2正则化避免模型过拟合。
- 交叉验证:采用交叉验证方法评估模型的泛化能力。
5.2 参数调优和模型优化
5.2.1 参数调优的方法和策略
参数调优通常旨在通过改变模型的超参数来提高模型的性能。常用的参数调优方法包括:
- 网格搜索(Grid Search):尝试模型的所有参数组合,找到最优参数设置。
- 随机搜索(Random Search):随机选择参数设置进行试验,能更快找到好的参数组合。
- 贝叶斯优化:使用贝叶斯原理来指导搜索过程,高效地寻找最优参数。
- 基于梯度的优化:如Adam、RMSprop等自适应学习率优化算法,能够自动调整学习率。
在进行参数调优时,推荐使用以下策略:
- 优先调整关键参数:并非所有参数都同等重要,优先调整影响模型性能最大的参数。
- 使用验证集:使用验证集来进行参数调优,避免过拟合训练数据。
- 保持模型简单:避免过度调参,简单模型往往更稳定且易于解释。
- 参数调整范围:合理设置参数调整的范围和间隔,以获得有效的搜索空间。
5.2.2 模型优化的技术路径
模型优化是一个持续的过程,涉及到模型结构、训练策略、后处理技术等多个方面。技术路径包括:
- 结构优化:通过神经架构搜索(NAS)寻找更优的网络结构。
- 知识蒸馏:将大型模型的知识转移到小型模型中,减少计算量。
- 训练加速:采用分布式训练、半精度浮点数(FP16)等技术加速模型训练。
- 迁移学习:利用预训练模型进行迁移学习,快速适应新任务。
- 模型剪枝和量化:减少模型大小和计算量,适用于边缘设备。
模型优化的最终目标是找到一个在性能和资源消耗之间取得平衡的解决方案。通过不断的测试、评估和调整,可以逐步提高模型的准确性和效率。
简介:本资源详细介绍了如何构建一个基于Python的循环神经网络(RNN)的情感分类系统,用于分析文本数据的情感倾向。系统利用了Python强大的数据处理和机器学习库,通过RNN及其变体LSTM和GRU来理解文本的上下文信息。系统开发包括数据预处理、模型构建、训练、评估和部署等步骤,适用于市场分析、客户满意度评估和舆情监控等应用。同时,该项目也适合作为学习NLP、深度学习和Python编程实践的毕业设计。