文章目录
大家好,我是 👉【Python当打之年(点击跳转)】
本期利用 python 分析一下「某瓣电影Top250数据」 ,看看各年份上映电影数量、各电影类型占比,各地区上映电影数量,电影评分分布,电影时长区间,电影导演、主演分布情况 等等,希望对大家有所帮助,如有疑问或者需要改进的地方可以联系小编。
涉及到的库:
- Pandas — 数据处理
- Pyecharts — 数据可视化
🏳️🌈 1. 导入模块
import pandas as pd
from pyecharts.charts import Bar
from pyecharts.charts import Scatter
from pyecharts.charts import Pie
from pyecharts.charts import Funnel
from pyecharts.charts import WordCloud
from pyecharts.charts import Line
from pyecharts.charts import Liquid
from pyecharts.charts import Grid
from pyecharts.commons.utils import JsCode
from pyecharts import options as opts
import warnings
warnings.filterwarnings('ignore')
🏳️🌈 2. Pandas数据处理
2.1 读取数据
df_movies = pd.read_excel("./TOP250.xlsx")
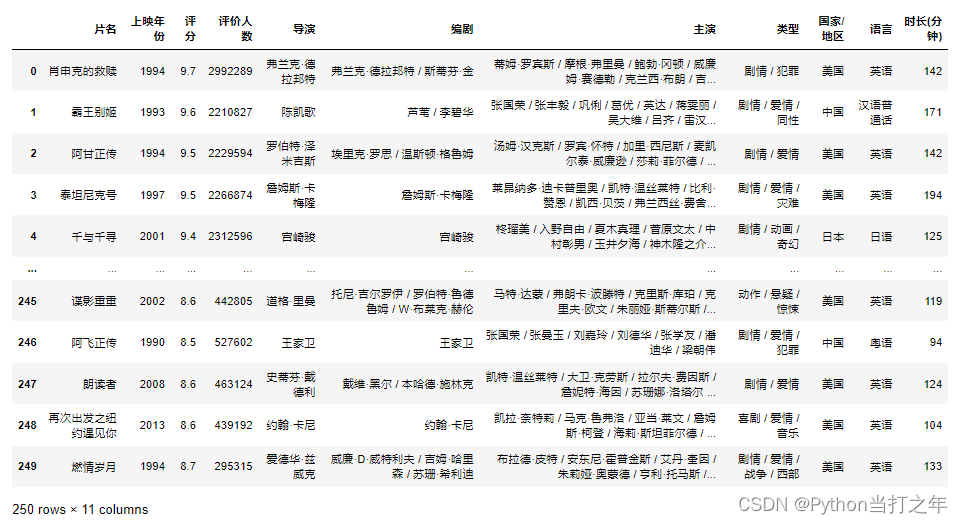
2.2 查看数据信息
df_movies.info()

2.3 查看数据描述信息
df_movies.describe()
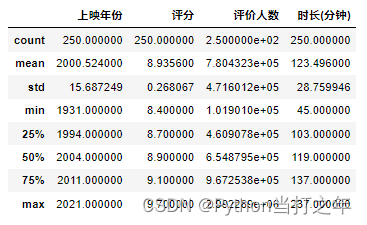
- 评分最高9.7,最低8.4,时长最长237分钟,最短45分钟
2.4 将中国地区语言修改为中文
df_movies.loc[df_movies["国家/地区"] == "中国", "语言"] = '中文'
🏳️🌈 3. Pyecharts数据可视化
3.1 各年份上映电影数量
def get_bar1():
bar = (
Bar()
.add_xaxis(x_data)
.add_yaxis('', y_data)
.set_global_opts(
title_opts=opts.TitleOpts(
title='1-各年份上映电影数量',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='2%',
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color='#228be6',font_size=20)
),
visualmap_opts=opts.VisualMapOpts(
is_show=False,
range_color=range_color
),
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(is_show=True, linestyle_opts=opts.LineStyleOpts(type_='dashed'))
)
)
)
return bar
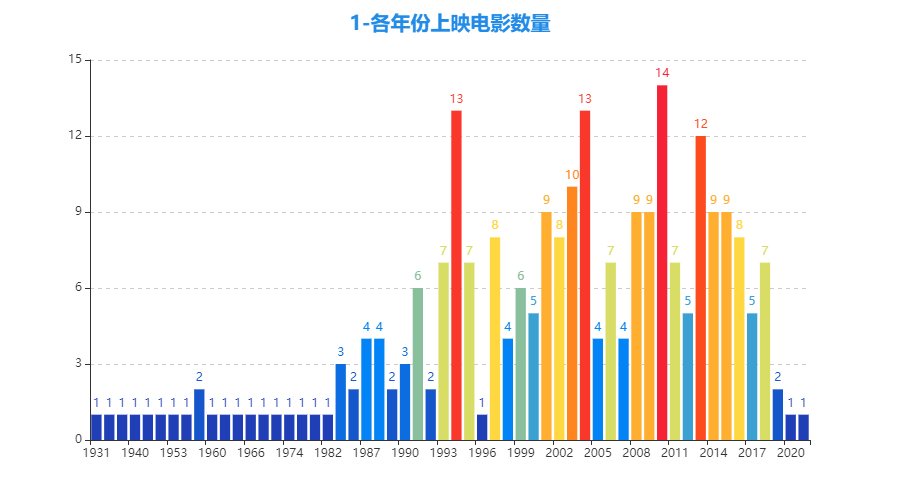
- 2010年上榜电影14部最多,其次是2004年、1994年的13部,以及2013年的12部。
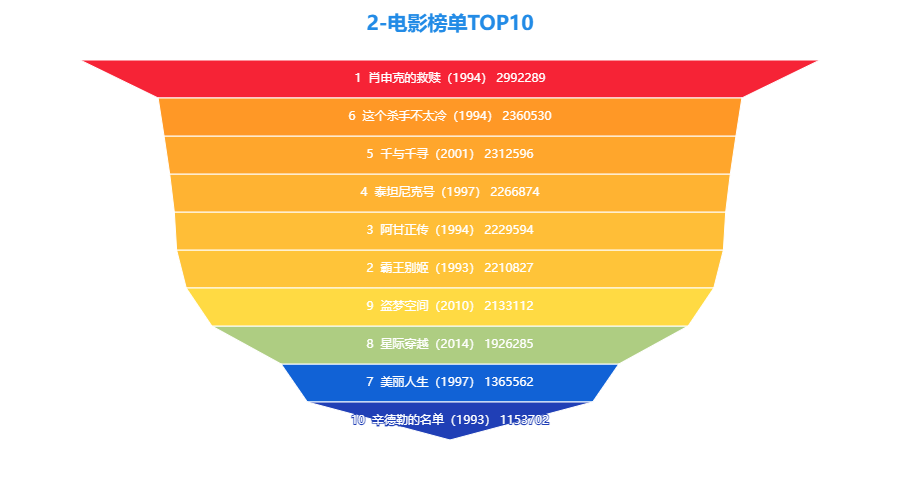
3.2 电影榜单TOP10
def get_funnel():
funnel = (
Funnel()
.add("", [list(z) for z in zip(x_data, y_data)])
.set_series_opts(label_opts=opts.LabelOpts(position="inside", formatter='{b} {c}'))
.set_global_opts(
title_opts=opts.TitleOpts(
title='2-电影榜单TOP10',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='2%',
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color='#228be6',font_size=20)
),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(
is_show=False,
range_color=range_color
)
)
)
return funnel
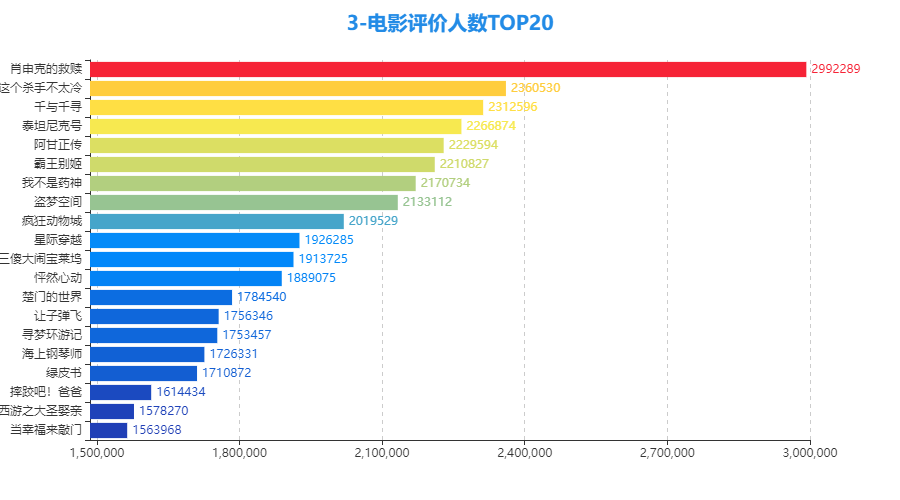
3.3 电影评价人数前二十
def get_map(x_data, y_data)
map0 = (
Map(
init_opts=opts.InitOpts(width='1000px', height='600px')
)
.add("",
[list(z) for z in zip(x_data, y_data)],
maptype="china",
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='3-各省星巴克门店数量分布',
pos_top='2%',
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color='#228be6',font_size=20)
),
visualmap_opts=opts.VisualMapOpts(
is_show=True,
pos_top='70%',
pos_left='20%',
range_color=range_color
)
)
)
return map0
3.4 各地区上映电影数量
def get_funnel():
line = (
Line()
.add_xaxis(x_data)
.add_yaxis('地区上映数量', y_data)
.set_global_opts(
title_opts=opts.TitleOpts(
title='4-各地区上映电影数量',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='2%',
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color='#228be6',font_size=20)
),
visualmap_opts=opts.VisualMapOpts(
is_show=False,
range_color=range_color,
)
)
)
return line
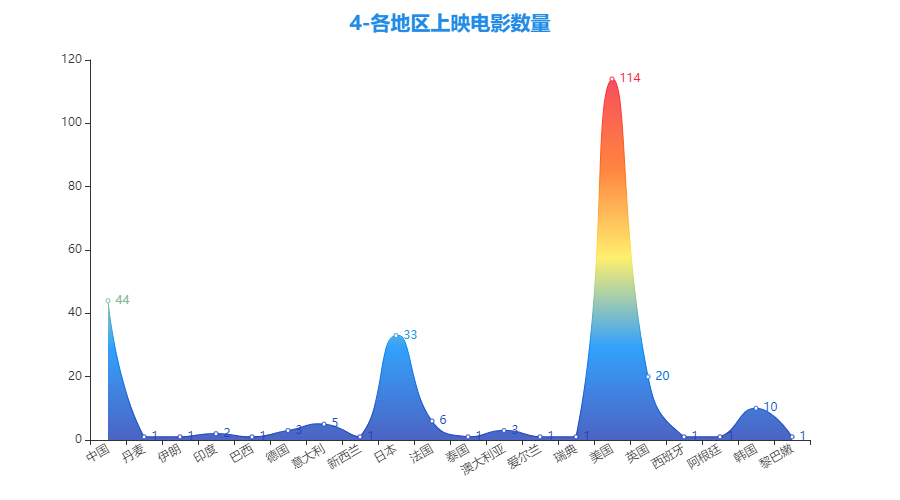
- 从上榜电影地区分布上看,美国以144部排名第一,其次是中国的44部和日本的33部排名第二、三位。
3.5 各电影类型占比
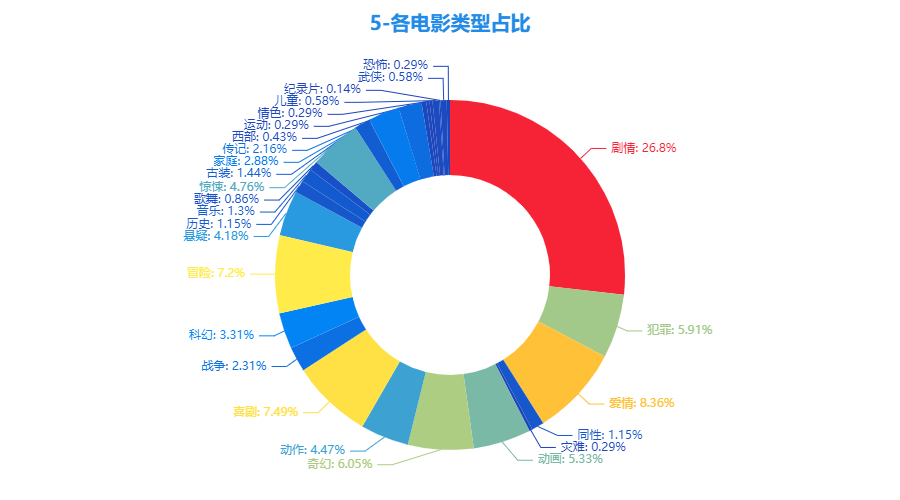
- 从上榜电影类型分布上看,剧情类电影占比最高(26.8%),其次是爱情类(8.36%),喜剧类(7.49%),冒险类(7.2%)
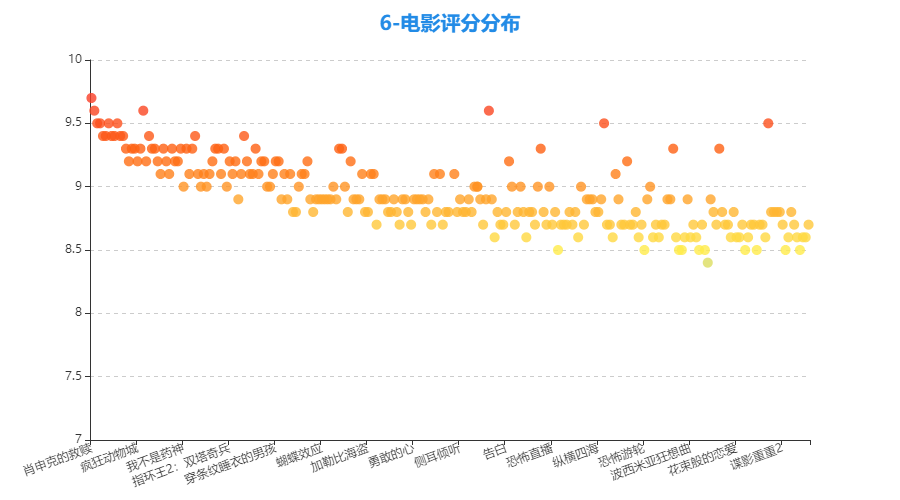
3.6 电影评分分布
3.7 电影时长区间
def get_pie():
pie = (
Pie()
.add("",
[list(z) for z in zip(x_data, y_data)],
radius=["30%", "70%"],
label_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)")
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='7-电影时长区间',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='2%',
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color='#228be6',font_size=20)
),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(
is_show=False,
range_color=range_color,
),
)
)
return pie
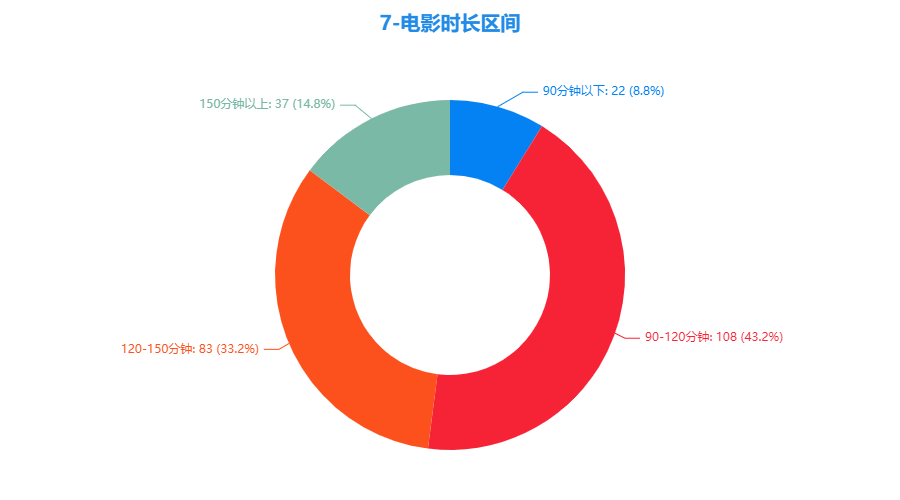
- 43.2%的电影在90-120分钟这个时间段内,即一个半小时至两个小时。
- 150分分钟以上的电影有37部,占比14.8%。
3.8 中文-英语电影数量占比
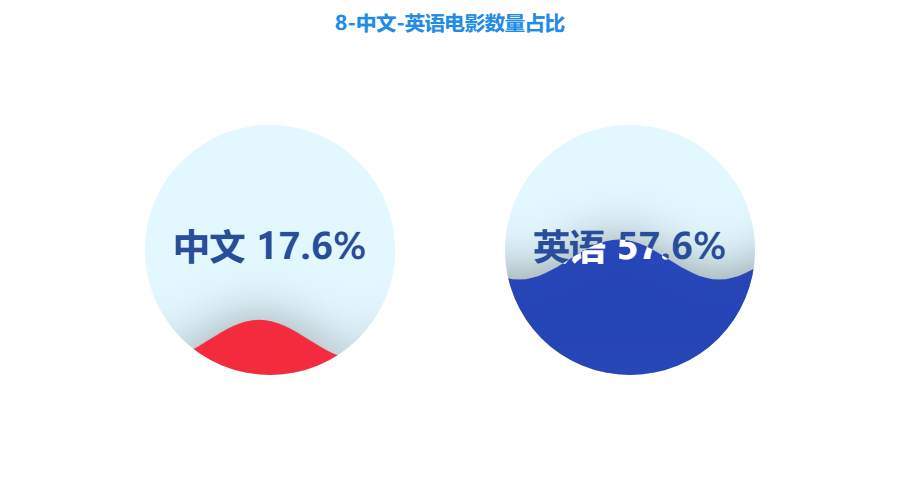
- 中文语种电影44部,占比17.6%,英语语种电影144部,占比57.6%。
3.9 电影片名词云
def get_wordcloud():
wordcloud = (
WordCloud()
.add("",words,word_size_range=[10, 50])
.set_global_opts(
title_opts=opts.TitleOpts(
title='9-电影主演词云',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='2%',
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(color='#228be6',font_size=20)
)
)
)
return wordcloud

3.10 电影主演词云

🏳️🌈 4. 可视化项目源码+数据
以上就是本期为大家整理的全部内容了,赶快练习起来吧,原创不易,喜欢的朋友可以点赞、收藏也可以分享(注明出处)让更多人知道。