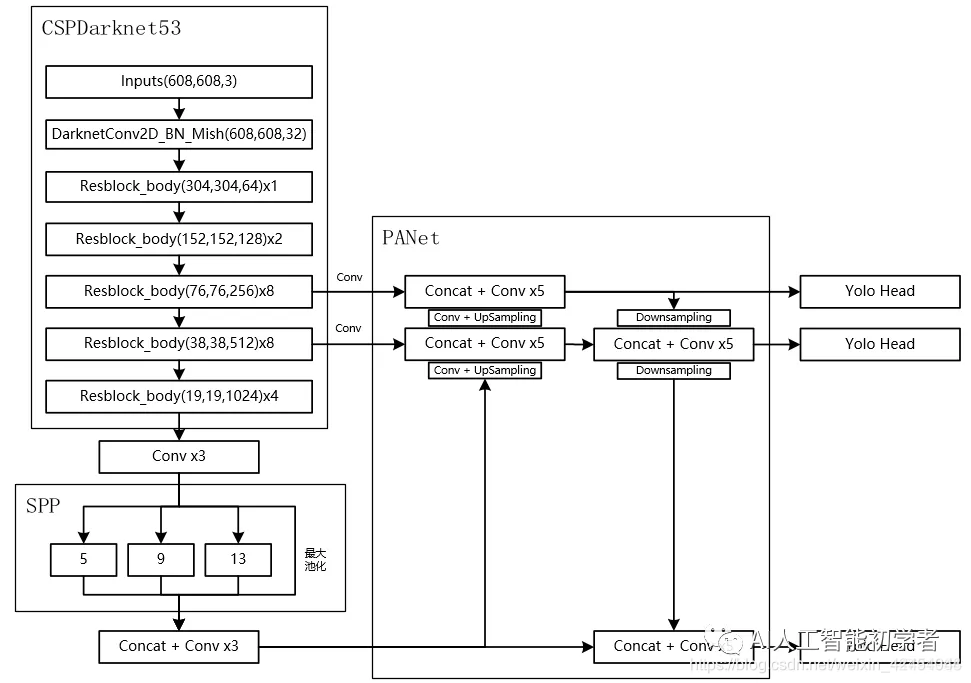
1. YOLO V4算法分析
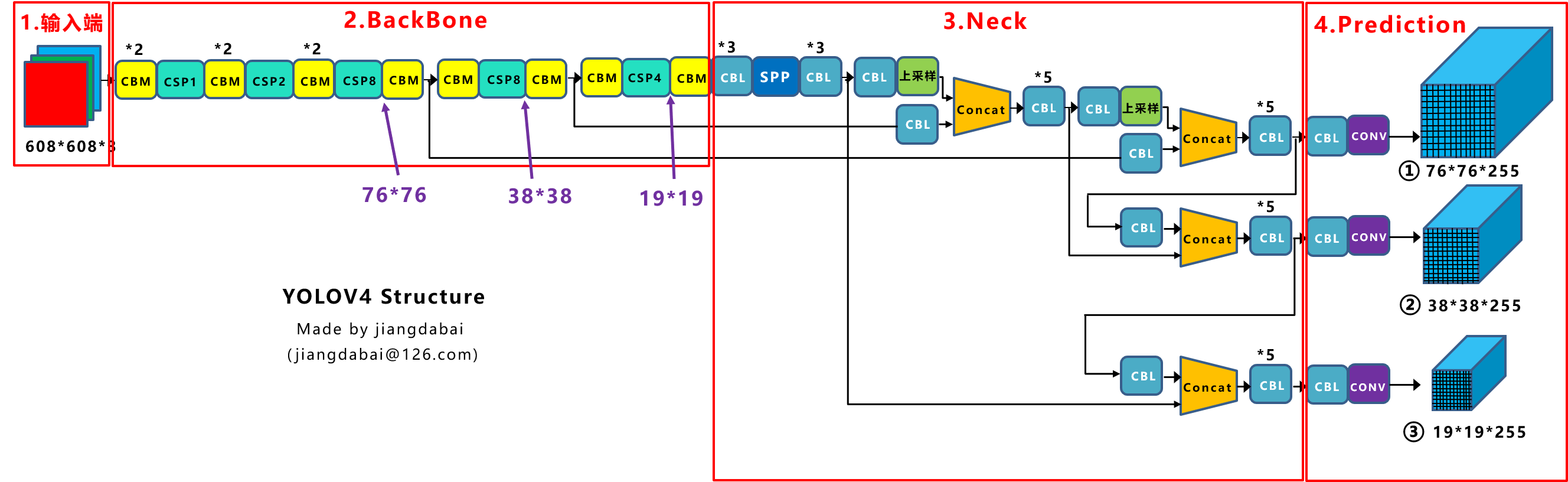
1.1 网络结构图
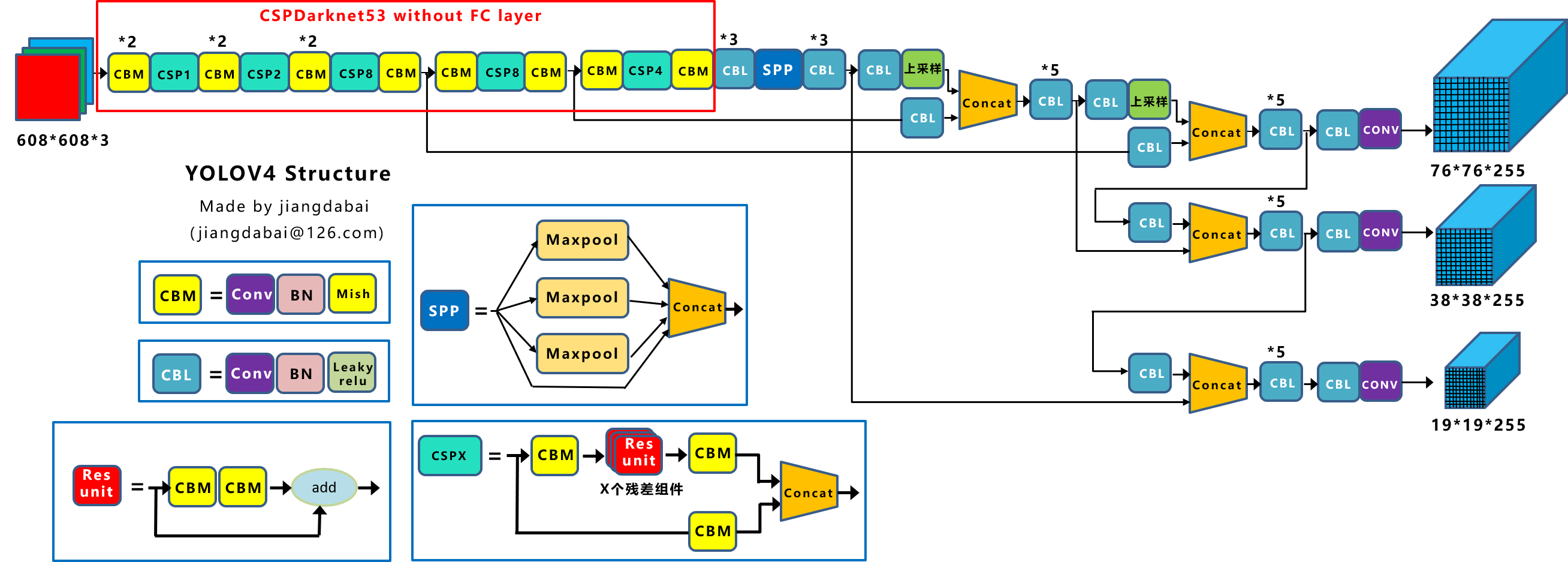
蓝色框中为网络中常用的几个模块:
CBM:Yolo v4网络结构中的最小组件,其由Conv(卷积)+ BN + Mish激活函数组成。
CBL:Yolo v4网络结构中的最小组件,其由Conv(卷积)+ BN + Leaky relu激活函数组成。
Res unit:残差组件,借鉴ResNet网络中的残差结构,让网络可以构建的更深。
CSPX:借鉴CSPNet网络结构,由三个CBM卷积层和X个Res unint模块Concat组成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
张量拼接与张量相加
Concat:张量拼接,会扩充两个张量的维度,例如26×26×256和26×26×512两个张量拼接,结果是26×26×768。
Add:张量相加,张量直接相加,不会扩充维度,例如104×104×128和104×104×128相加,结果还是104×104×128。
Backbone中卷积层的数量:
每个CSPX中包含3+2×X个卷积层,因此整个主干网络Backbone中一共包含2+(3+2×1)+2+(3+2×2)+2+(3+2×8)+2+(3+2×8)+2+(3+2×4)+1=72。
1.2 YOLO V4的创新点
为了便于分析,将Yolov4的整体结构拆分成四大板块:
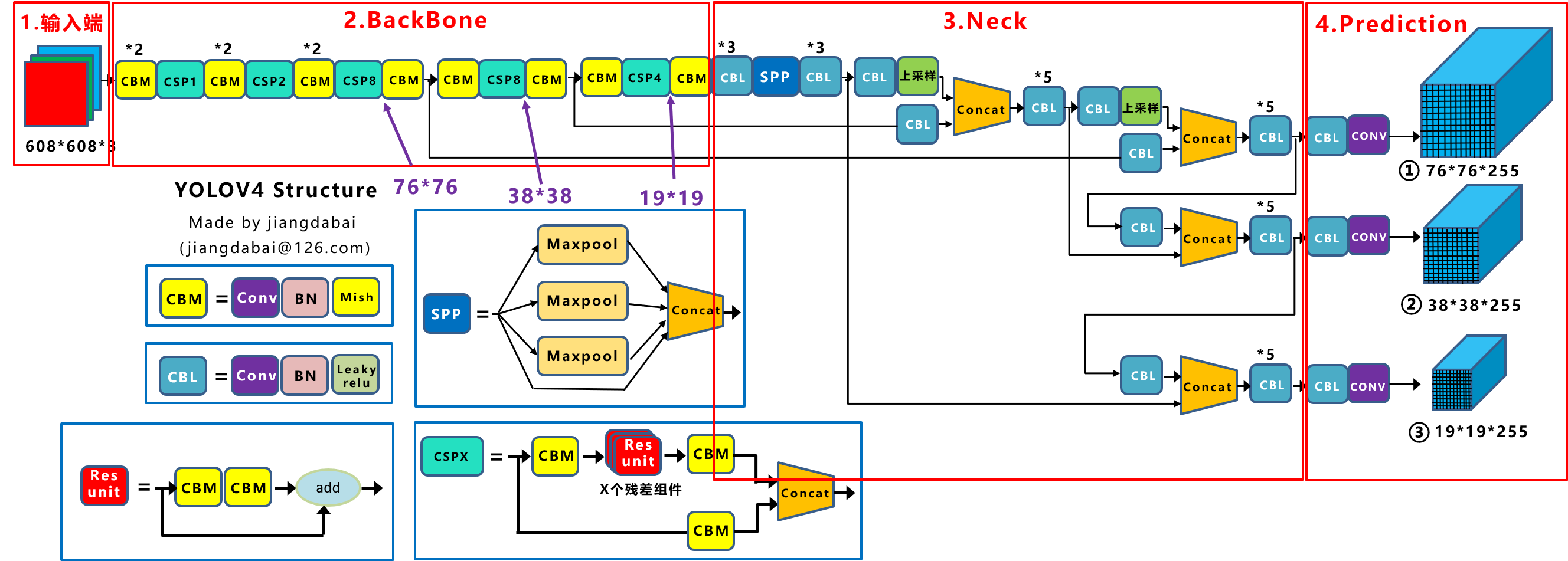
(2)BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock。
(3)Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
(4)Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
1.2.1 输入端的创新
(1)Mosaic数据增强
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。根据论文所说其拥有一个巨大的优点是丰富检测物体的背景! 且在BN计算的时候一下子会计算四张图片的数据!

1.2.2 BackBone的创新
(1)CSPDarknet53:
CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块。
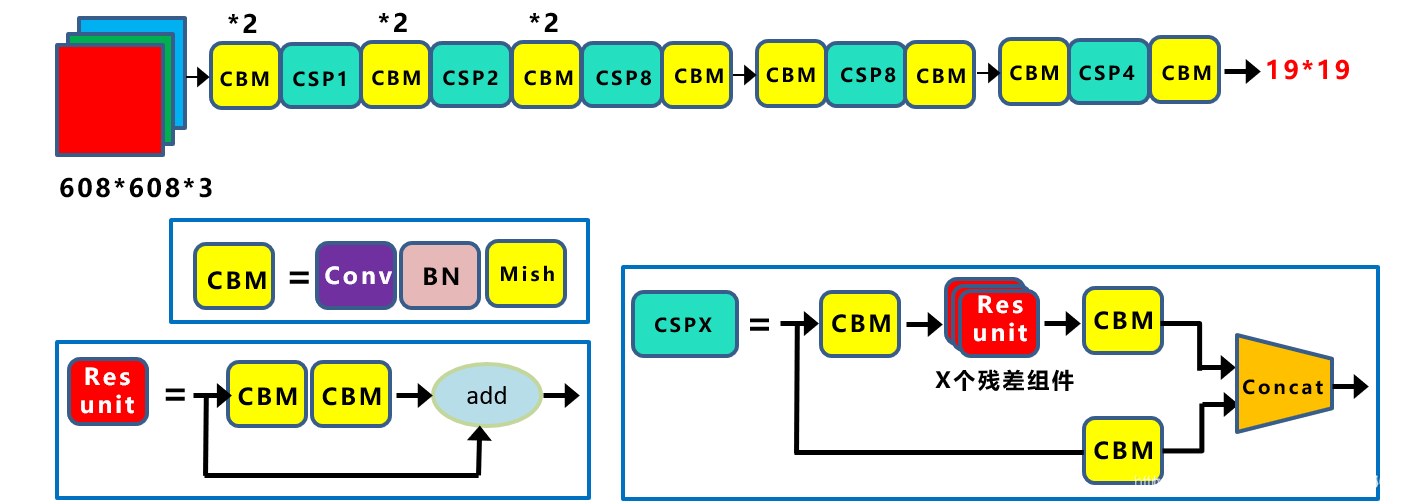
因为Backbone有5个CSP模块,若输入图像是608 * 608,则特征图变化的规律是:608->304->152->76->38->19
经过5次CSP模块后得到19*19大小的特征图。
优点一:增强CNN的学习能力,使得在轻量化的同时保持准确性。
优点二:降低计算瓶颈
优点三:降低内存成本
(2)Mish激活函数:
Mish激活函数是2019年下半年提出的激活函数,和leaky_relu激活函数的图形对比如下:
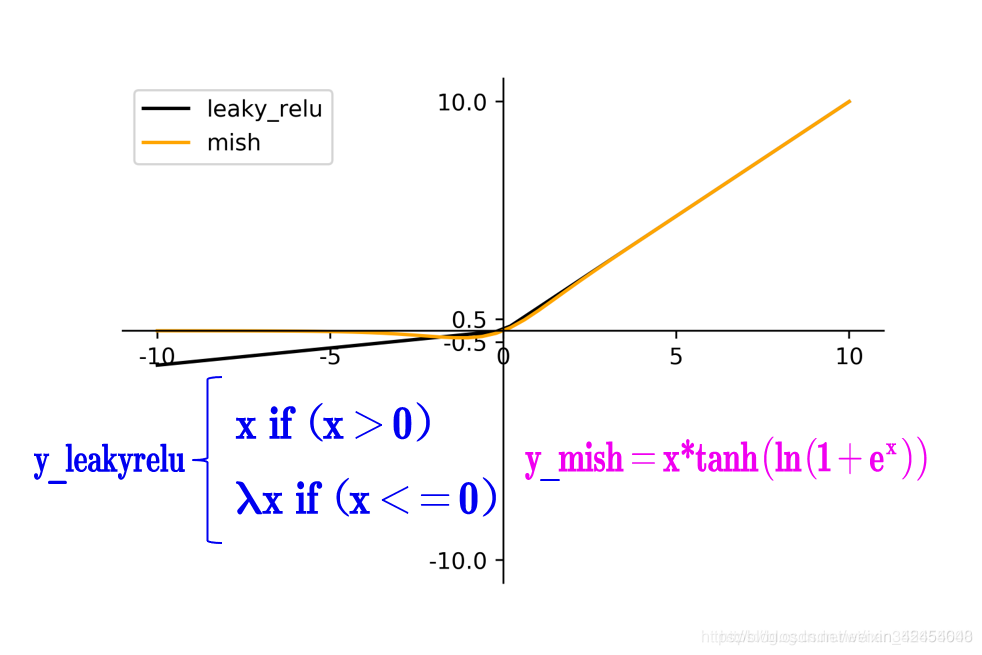
因此在设计Yolov4目标检测任务时,主干网络Backbone还是使用Mish激活函数。
(3)Dropblock:
Yolov4中使用的Dropblock,其实和常见网络中的Dropout功能类似,也是缓解过拟合的一种正则化方式。
传统的dropout对FC层效果更好,对conv层效果较差,因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。输入的信息仍旧能够被送到下一层,导致网络过拟合。而DropBlock则是将在特征图上连续的信息一起丢弃。
这种方式其实是借鉴2017年的Cutout数据增强的方式,cutout是将输入图像的部分区域清零,而Dropblock则是将Cutout 应用到每一个特征图。而且并不是用固定的归零比率,而是在训练时以一个小的比率开始,随着训练过程线性的增加这个比率。

优点一:Dropblock的效果优于Cutout
优点二:cutout只能作用于输入层,而Dropblock则是将Cutout应用到网络中的每一个特征图上
优点三:Dropblock可以定制各种组合,在训练的不同阶段可以修改删减的概率,从空间层面和时间层面,和cutout相比都有更精细的改进。
Yolov4中直接采用了更优的Dropblock,对网络的正则化过程进行了全面的升级改进。
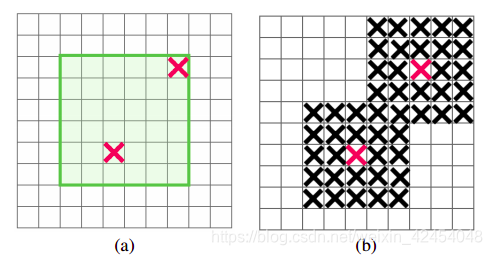
下图是一个简单示例。(a)为输入图像,狗的头、脚等区域具有相关性。(b)为以dropout的方式随机丢弃信息,此时能从临近区域获取相关信息(带x的为丢弃信息的mask)。c为DropBlock的方式,将一定区域内的特征全部丢弃。
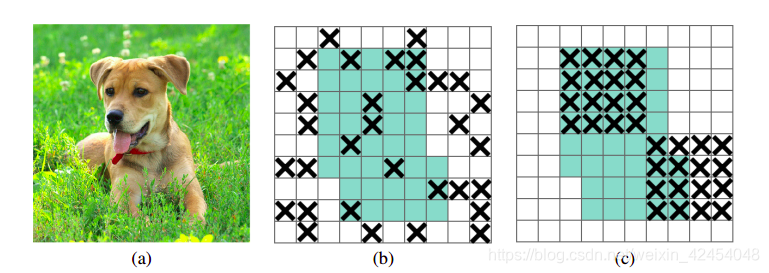

2~4:若处于推理模式,则不丢弃任何特征。
5:生成mask M,每个点均服从参数为γ的伯努利分布(伯努利分布,随机变量x以概率γ和1-γ取1和0)。需要注意的是,只有mask的绿色有效区域内的点服从该分布,如下图a所示,这样确保步骤6不会处理边缘区域。
6:对于M中为0的点,以该点为中心,创建一个长宽均为block_size的矩形,该矩形内所有值均置0。如上图b所示。
7:将mask应用于特征图上:A=AM
8 对特征进行归一化:A=Acount(M)/count_ones(M)。此处count指M的像素数(即特征图的宽*高),count_ones指M中值为1的像素数。
具体细节
block_size:所有特征图的block_size均相同,文中为7时大部分情况下最好。
γ:并未直接设置γ,而是从keep_prob来推断γ,这两者关系如下(feat_size为特征图的大小):
γ = 1 − k e e p _ p r o b b l o c k _ s i z e 2 f e a t _ s i z e 2 ( f e a t _ s i z e − b l o c k _ s i z e + 1 ) 2 \gamma =\frac{1-keep\_prob}{block\_siz{{e}^{2}}}\frac{feat\_siz{{e}^{2}}}{{{(feat\_size-block\_size+1)}^{2}}} γ=block_size21−keep_prob(feat_size−block_size+1)2feat_size2
keep_prob:固定keep_prob时DropBlock效果不好,而在训练初期使用过小的keep_prob会又会影响学习到的参数。因而随着训练的进行DropBlock将keep_prob从1线性降低到目标值(如0.9)。
1.2.3 Neck的创新
在目标检测领域,为了更好的提取融合特征,通常在Backbone和输出层,会插入一些层,这个部分称为Neck。相当于目标检测网络的颈部,也是非常关键的。
Yolov4的Neck结构主要采用了SPP模块、FPN+PAN的方式。
(1)SPP模块:
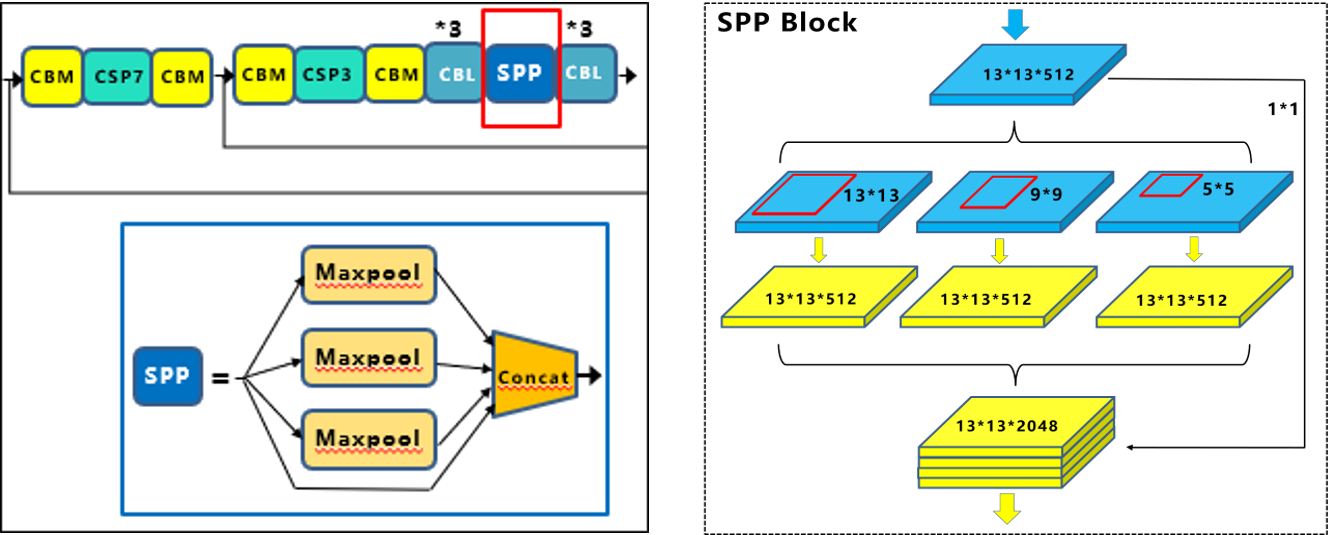
注意:这里最大池化采用padding操作,移动的步长为1,比如13×13的输入特征图,使用5×5大小的池化核池化,padding=2,因此池化后的特征图仍然是13×13大小。
采用SPP模块的方式,比单纯的使用k×k最大池化的方式,极大地增加感受野,显著的分离了最重要的上下文特征。
(2)FPN :
FPN的意义:
原始图像经过层层卷积后分辨率逐渐降低,导致小物体的丢失。特征金字塔一直是多尺度目标检测中的一个基本的组成部分,但是由于特征金字塔计算量大,会拖慢整个检测速度,所以大多数方法为了检测速度而尽可能的去避免使用特征金字塔,而是只使用高层的特征来进行预测。**高层的特征虽然包含了丰富的语义信息,但是由于低分辨率,很难准确地保存物体的位置信息。与之相反,低层的特征虽然语义信息较少,但是由于分辨率高,就可以准确地包含物体位置信息。**所以如果可以将低层的特征和高层的特征融合起来,就能得到一个识别和定位都准确的目标检测系统。
FPN的实现方式:
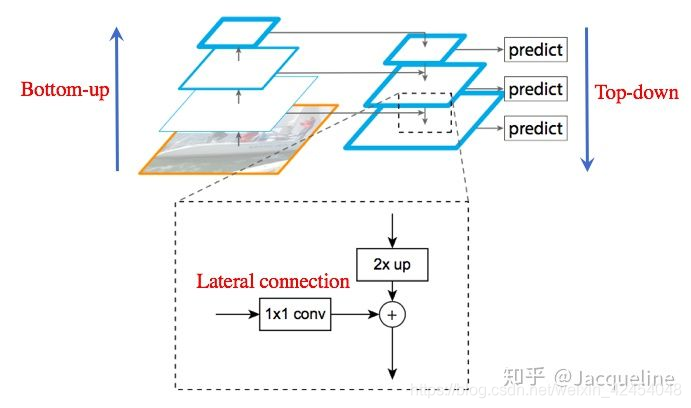
a. Bottom-up:
Bottom-up的过程就是将图片输入到卷积网络中提取特征的过程中。卷积输出的feature map的尺寸有的是不变的,有的是成2倍的减小的。对于那些输出的尺寸不变的层,把他们归为一个组,提取每个组中最后一层卷积输出的特征。即不同组之间的特征图尺寸大小为2倍关系。
b. Top-down:
Top-down的过程就是将高层得到的feature map进行上采样然后往下传递,这样做是因为,高层的特征包含丰富的语义信息,经过top-down的传播就能使得这些语义信息传播到低层特征上,使得低层特征也包含丰富的语义信息。
c. Lateral connection:
下图所示,lateral connection主要包括三个步骤:
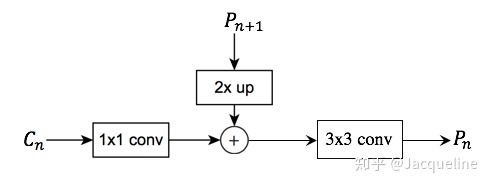
(1) 对于每个组输出的feature map 都先进行一个11的卷积降低维度。
(2) 然后再将得到的特征和上一层上采样得到特征图 进行融合(直接相加),因为每个组输出的特征图之间是2倍的关系,所以上一层上采样得到的特征图的大小和本层的大小一样,就可以直接将对应元素相加 。
(3) 相加完之后需要进行一个33的卷积才能得到本层的特征输出 。使用这个3*3卷积的目的是为了消除上采样产生的混叠效应(插值生成的图像灰度不连续,在灰度变化的地方可能出现明显的锯齿状)。
YOLO V4 中FPN的使用
CSPDarknet53中,每个CSP模块前面的卷积核都是3×3大小,相当于下采样操作。因此可以看到三个紫色箭头处的特征图是76×76、38×38、19×19。完成下采样后,再自顶向下,通过上采样(放大图像)将高层信息与低层信息进行拼接(Concat),此为FPN过程。
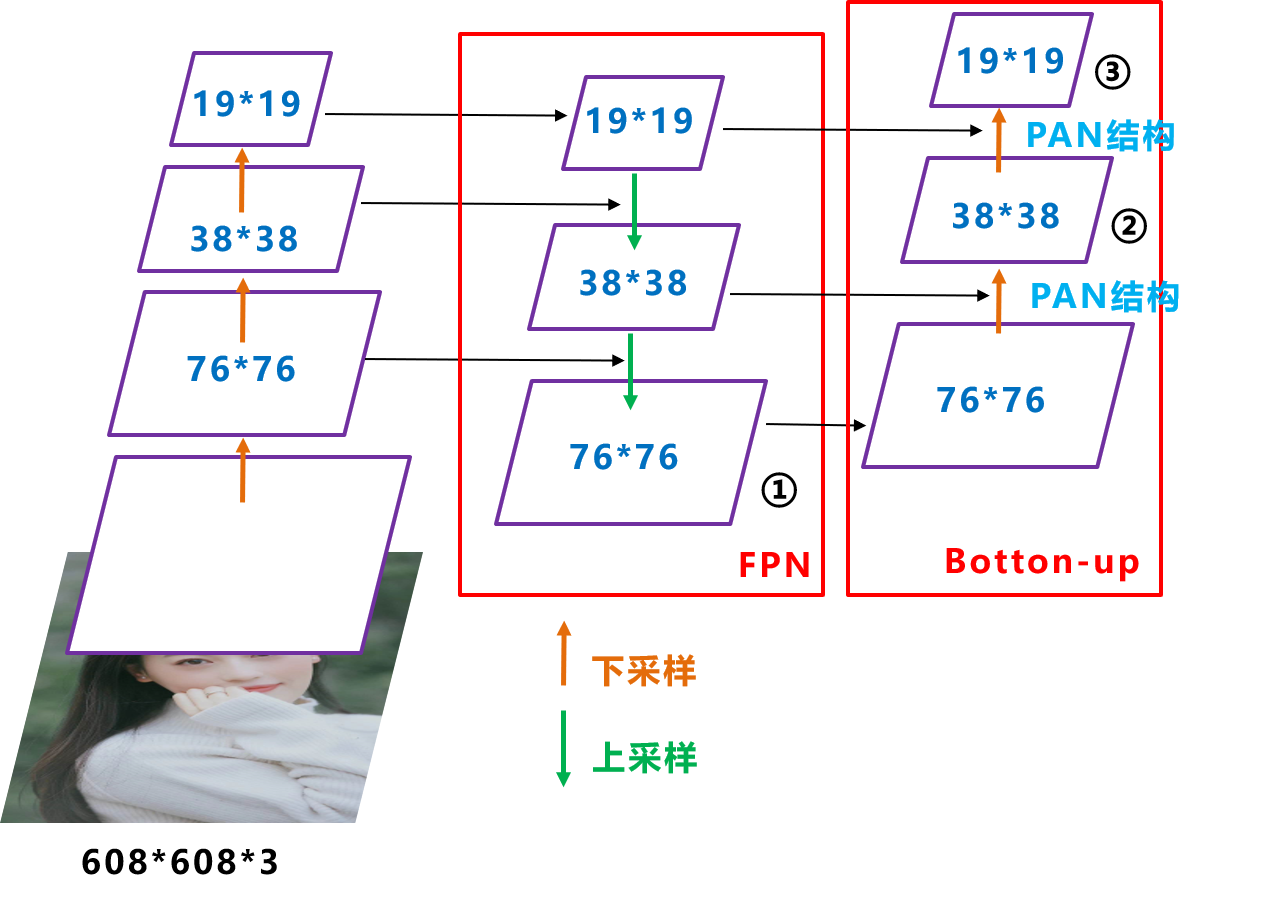
(3)PAN:
Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。其中包含两个PAN结构。
FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行特征聚合
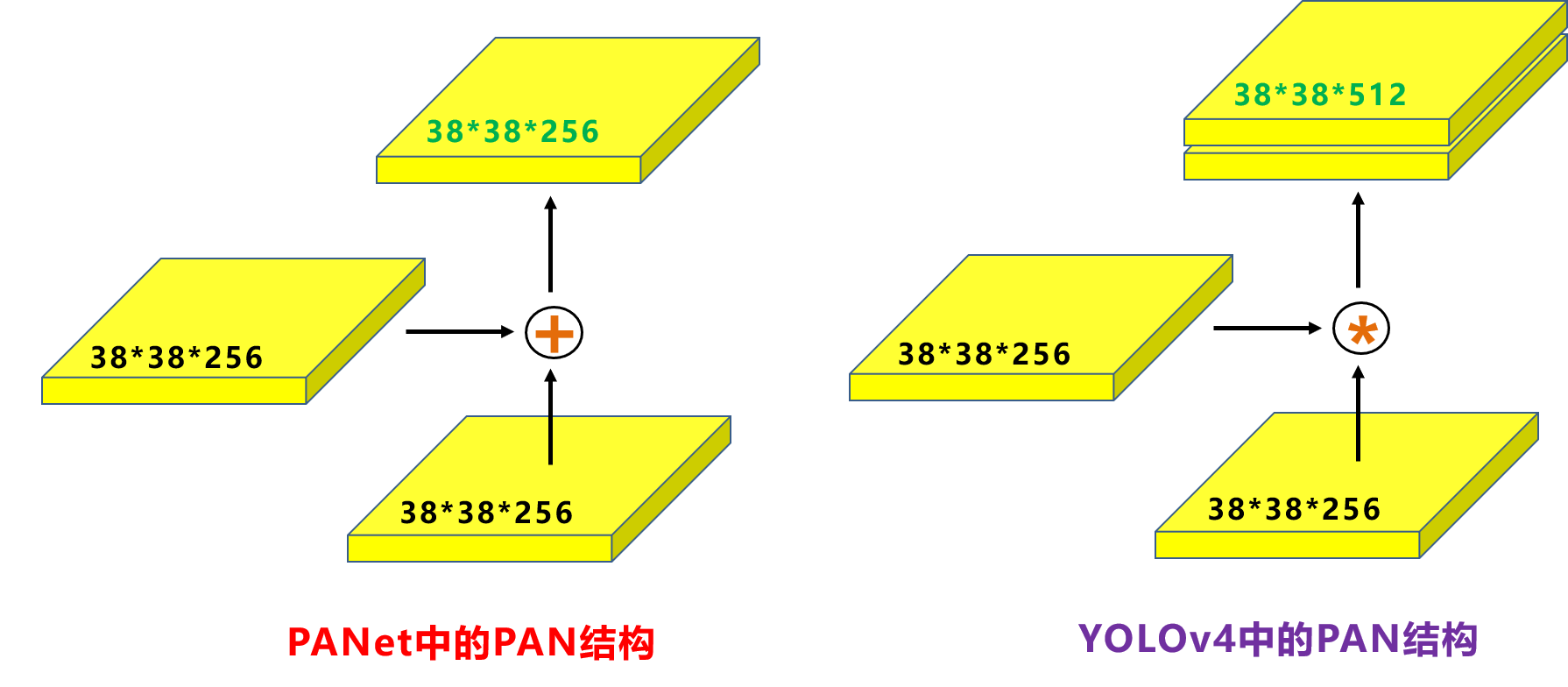
注意:
原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4中则采用concat(route)操作,特征图融合后的尺寸发生了变化。
1.2.4 Prediction创新
(1)CIOU_loss:
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数) 两部分构成。
Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
a. IOU_loss:
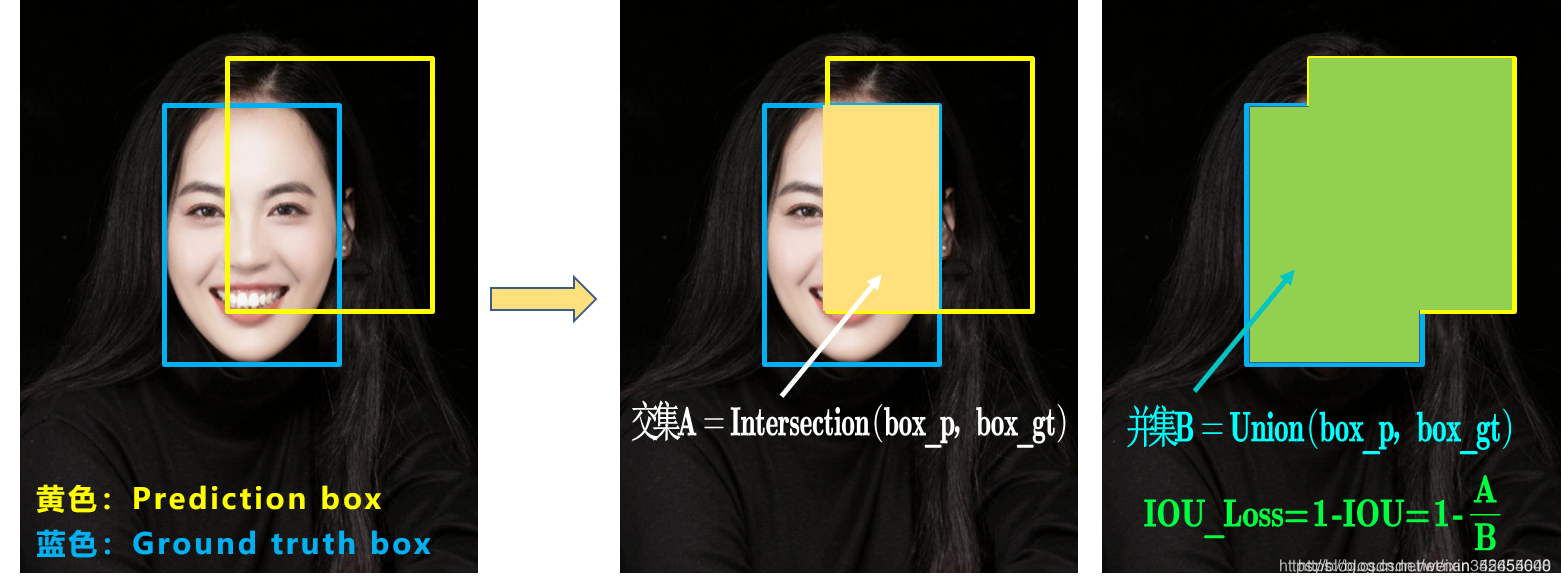
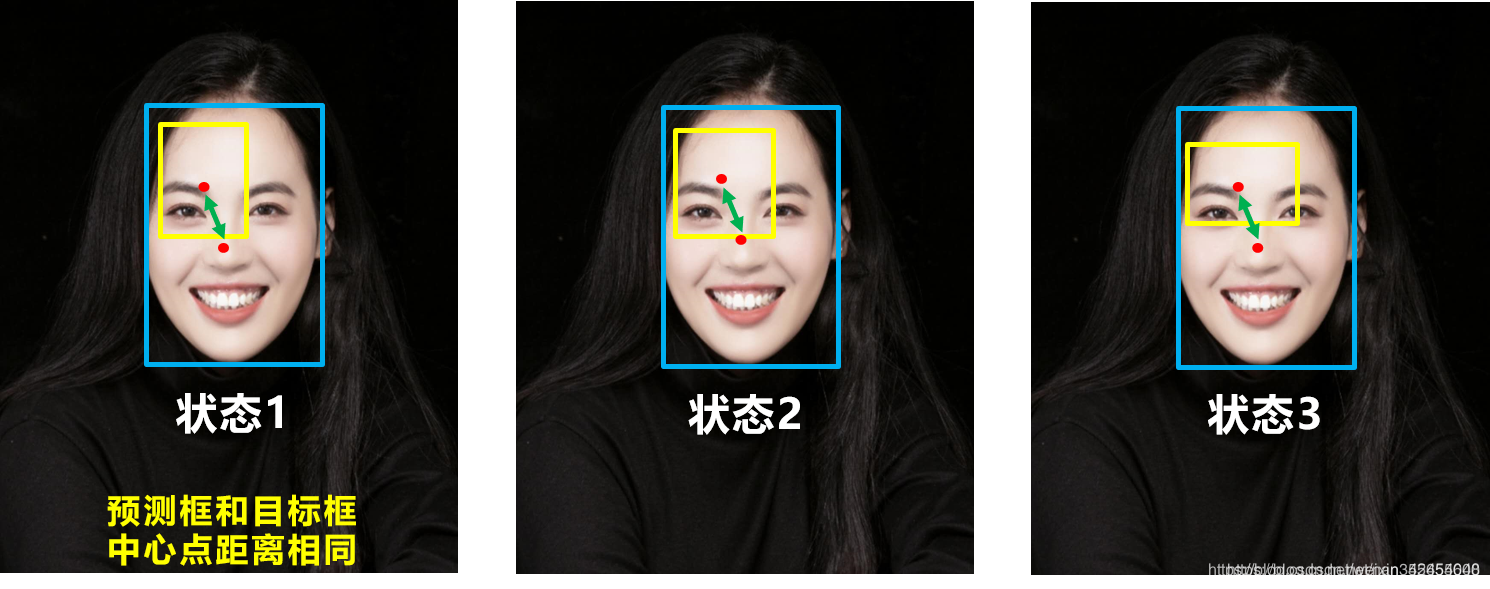
问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
因此2019年出现了GIOU_Loss来进行改进。

b. GIOU_loss:
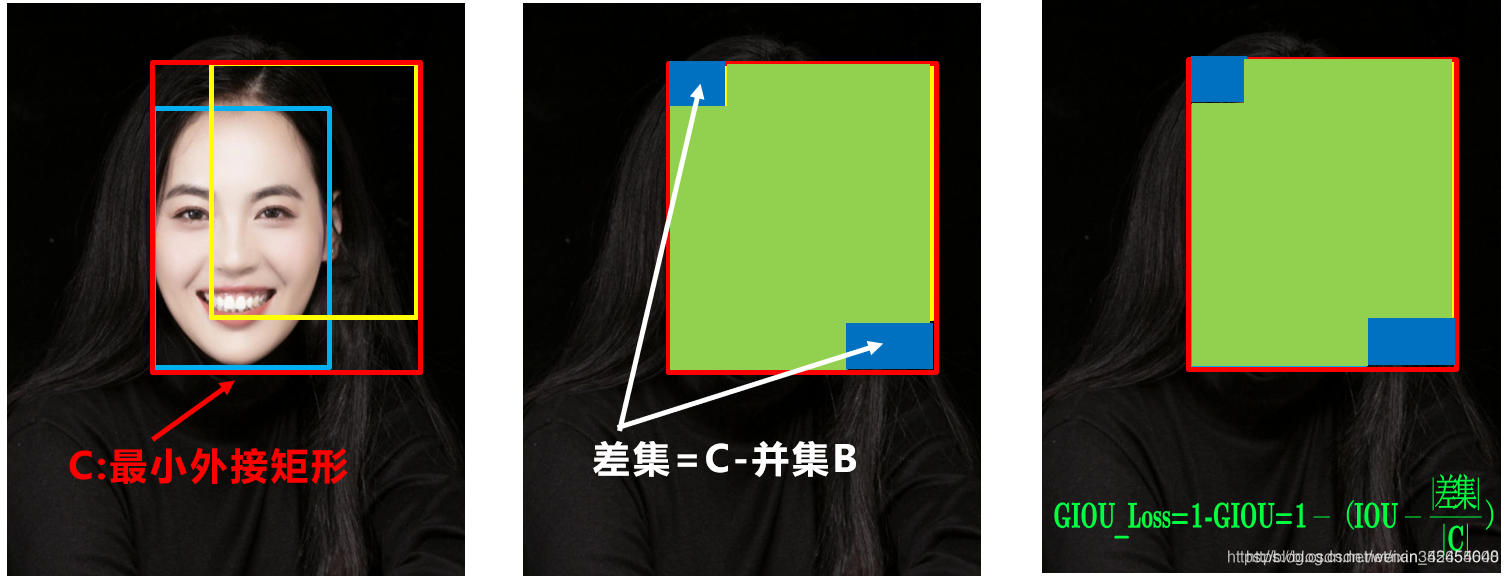
但为什么仅仅说缓解呢?因为还存在一种不足:

基于这个问题,2020年的AAAI又提出了DIOU_Loss。
c. DIOU_loss:
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
针对IOU和GIOU存在的问题,作者从两个方面进行考虑
一:如何最小化预测框和目标框之间的归一化距离?
二:如何在预测框和目标框重叠时,回归的更准确?
针对第一个问题,提出了DIOU_Loss(Distance_IOU_Loss)

d. CIOU_loss:
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。
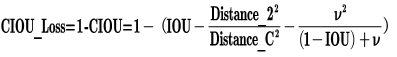
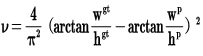
各个Loss函数的不同点:
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
(2)DIOU_nms:
nms主要用于预测框的筛选,常用的目标检测算法中,一般采用普通的nms的方式。而Yolo v4将其中计算IOU的部分替换成DIOU的方式:

1.2.5 训练过程创新
(1)Label Smoothing平滑:
公式:
new_onehot_labels = onehot_labels * (1 - label_smoothing) + label_smoothing / num_classes
当label_smoothing的值为0.01得时候,公式变成如下所示:
new_onehot_labels = y * (1 - 0.01) + 0.01 / num_classes
其实Label Smoothing平滑就是将标签进行一个平滑,原始的标签是0、1,在平滑后变成0.005(如果是二分类)、0.995,也就是说对分类准确做了一点惩罚,让模型不可以分类的太准确,太准确容易过拟合。
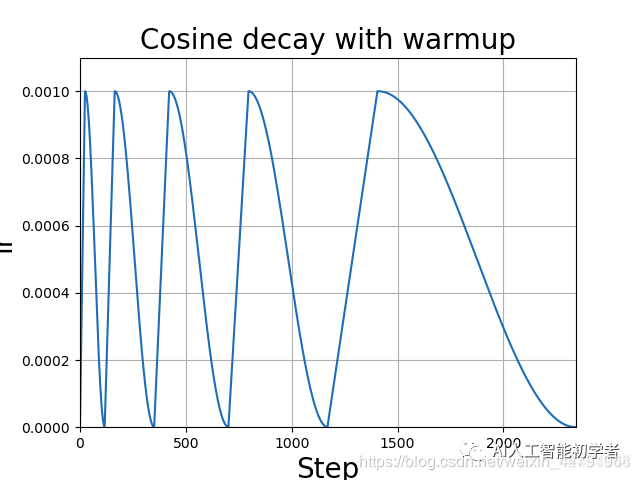
(2)学习率余弦退火衰减:
余弦退火衰减法,学习率会先上升再下降,上升的时候使用线性上升,下降的时候模拟cos函数下降。执行多次。
效果如图所示: