背景
提供免费算力支持,有交流群有值班教师答疑的华为昇思训练营进入第十一天了。
今天是第十一天,从第十天开始,进入了应用实战阶段,前九天都是基础入门阶段,具体的学习内容可以看链接
基础学习部分
昇思25天学习打卡营第一天|快速入门
昇思25天学习打卡营第二天|张量 Tensor
昇思25天学习打卡营第三天|数据集Dataset
昇思25天学习打卡营第四天|数据变换Transforms
昇思25天学习打卡营第五天|网络构建
昇思25天学习打卡营第六天|函数式自动微分
昇思25天学习打卡营第七天|模型训练
昇思25天学习打卡营第八天|保存与加载
昇思25天学习打卡营第九天|使用静态图加速
应用实践部分
昇思25天学习打卡营第十天|CycleGAN图像风格迁移互换
学习内容
GAN基础原理
这部分原理介绍参考GAN图像生成。
DCGAN原理
DCGAN(深度卷积对抗生成网络,Deep Convolutional Generative Adversarial Networks)是GAN的直接扩展。不同之处在于,DCGAN会分别在判别器和生成器中使用卷积和转置卷积层。
它最早由Radford等人在论文Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks中进行描述。判别器由分层的卷积层、BatchNorm层和LeakyReLU激活层组成。输入是3x64x64的图像,输出是该图像为真图像的概率。生成器则是由转置卷积层、BatchNorm层和ReLU激活层组成。输入是标准正态分布中提取出的隐向量 z z z,输出是3x64x64的RGB图像。
本教程将使用动漫头像数据集来训练一个生成式对抗网络,接着使用该网络生成动漫头像图片。
数据准备与处理
首先我们将数据集下载到指定目录下并解压。
下载后的数据集目录结构如下:
./faces/faces
├── 0.jpg
├── 1.jpg
├── 2.jpg
├── 3.jpg
├── 4.jpg
...
├── 70169.jpg
└── 70170.jpg
数据处理
首先为执行过程定义一些输入:
batch_size = 128 # 批量大小
image_size = 64 # 训练图像空间大小
nc = 3 # 图像彩色通道数
nz = 100 # 隐向量的长度
ngf = 64 # 特征图在生成器中的大小
ndf = 64 # 特征图在判别器中的大小
num_epochs = 3 # 训练周期数
lr = 0.0002 # 学习率
beta1 = 0.5 # Adam优化器的beta1超参数
定义create_dataset_imagenet函数对数据进行处理和增强操作。
import numpy as np
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
def create_dataset_imagenet(dataset_path):
"""数据加载"""
dataset = ds.ImageFolderDataset(dataset_path,
num_parallel_workers=4,
shuffle=True,
decode=True)
# 数据增强操作
transforms = [
vision.Resize(image_size),
vision.CenterCrop(image_size),
vision.HWC2CHW(),
lambda x: ((x / 255).astype("float32"))
]
# 数据映射操作
dataset = dataset.project('image')
dataset = dataset.map(transforms, 'image')
# 批量操作
dataset = dataset.batch(batch_size)
return dataset
dataset = create_dataset_imagenet('./faces')
通过create_dict_iterator函数将数据转换成字典迭代器,然后使用matplotlib模块可视化部分训练数据。
import matplotlib.pyplot as plt
def plot_data(data):
# 可视化部分训练数据
plt.figure(figsize=(10, 3), dpi=140)
for i, image in enumerate(data[0][:30], 1):
plt.subplot(3, 10, i)
plt.axis("off")
plt.imshow(image.transpose(1, 2, 0))
plt.show()
sample_data = next(dataset.create_tuple_iterator(output_numpy=True))
plot_data(sample_data)

构造网络
当处理完数据后,就可以来进行网络的搭建了。按照DCGAN论文中的描述,所有模型权重均应从mean为0,sigma为0.02的正态分布中随机初始化。
生成器
生成器G的功能是将隐向量z映射到数据空间。由于数据是图像,这一过程也会创建与真实图像大小相同的 RGB 图像。在实践场景中,该功能是通过一系列Conv2dTranspose转置卷积层来完成的,每个层都与BatchNorm2d层和ReLu激活层配对,输出数据会经过tanh函数,使其返回[-1,1]的数据范围内。
DCGAN论文生成图像如下所示:
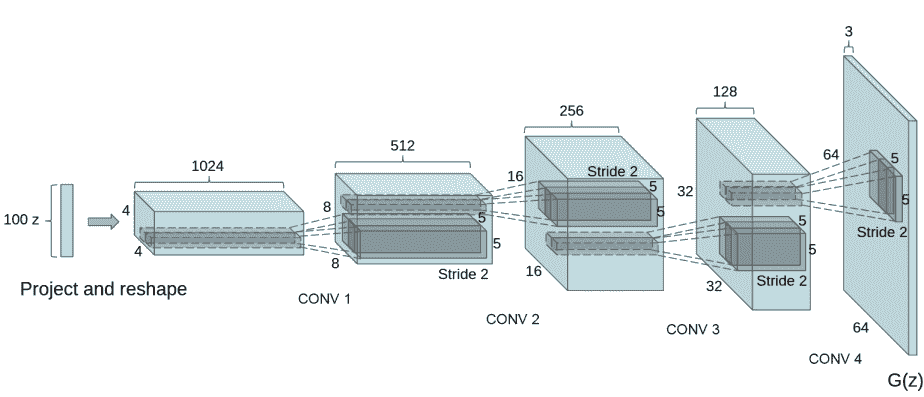
图片来源:Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks.
我们通过输入部分中设置的nz、ngf和nc来影响代码中的生成器结构。nz是隐向量z的长度,ngf与通过生成器传播的特征图的大小有关,nc是输出图像中的通道数。
判别器
如前所述,判别器D是一个二分类网络模型,输出判定该图像为真实图的概率。通过一系列的Conv2d、BatchNorm2d和LeakyReLU层对其进行处理,最后通过Sigmoid激活函数得到最终概率。
DCGAN论文提到,使用卷积而不是通过池化来进行下采样是一个好方法,因为它可以让网络学习自己的池化特征。
模型训练
损失函数
当定义了D和G后,接下来将使用MindSpore中定义的二进制交叉熵损失函数BCELoss。
# 定义损失函数
adversarial_loss = nn.BCELoss(reduction='mean')
优化器
这里设置了两个单独的优化器,一个用于D,另一个用于G。这两个都是lr = 0.0002和beta1 = 0.5的Adam优化器。
训练模型
训练分为两个主要部分:训练判别器和训练生成器。
-
训练判别器
训练判别器的目的是最大程度地提高判别图像真伪的概率。按照Goodfellow的方法,是希望通过提高其随机梯度来更新判别器,所以我们要最大化 l o g D ( x ) + l o g ( 1 − D ( G ( z ) ) log D(x) + log(1 - D(G(z)) logD(x)+log(1−D(G(z))的值。
-
训练生成器
如DCGAN论文所述,我们希望通过最小化 l o g ( 1 − D ( G ( z ) ) ) log(1 - D(G(z))) log(1−D(G(z)))来训练生成器,以产生更好的虚假图像。
在这两个部分中,分别获取训练过程中的损失,并在每个周期结束时进行统计,将fixed_noise批量推送到生成器中,以直观地跟踪G的训练进度。
结果展示
运行下面代码,描绘D和G损失与训练迭代的关系图:
plt.figure(figsize=(10, 5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses, label="G", color='blue')
plt.plot(D_losses, label="D", color='orange')
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
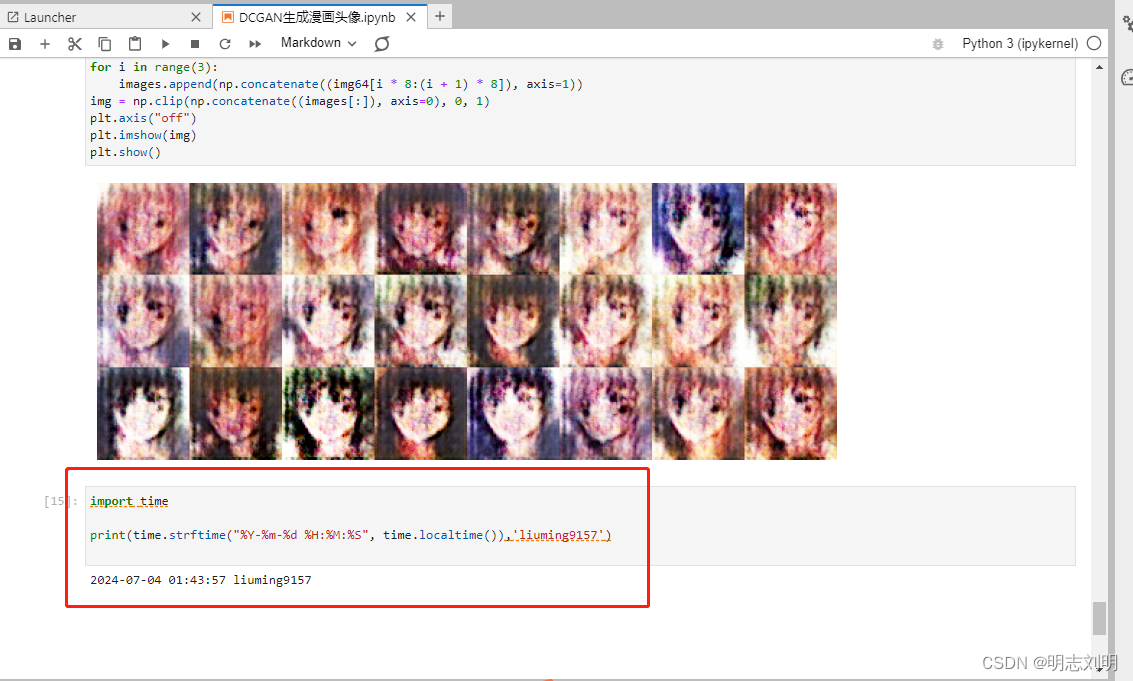
可视化训练过程中通过隐向量fixed_noise生成的图像。
import matplotlib.pyplot as plt
import matplotlib.animation as animation
def showGif(image_list):
show_list = []
fig = plt.figure(figsize=(8, 3), dpi=120)
for epoch in range(len(image_list)):
images = []
for i in range(3):
row = np.concatenate((image_list[epoch][i * 8:(i + 1) * 8]), axis=1)
images.append(row)
img = np.clip(np.concatenate((images[:]), axis=0), 0, 1)
plt.axis("off")
show_list.append([plt.imshow(img)])
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True)
ani.save('./dcgan.gif', writer='pillow', fps=1)
showGif(image_list)

总结
随着训练次数的增多,图像质量也越来越好。如果增大训练周期数,当num_epochs达到50以上时,生成的动漫头像图片与数据集中的较为相似。