情感分析的基本流程通常包括:
- 自定义爬虫抓取文本信息;
- 使用Jieba工具进行中文分词、词性标注;
- 定义情感词典提取每行文本的情感词;
- 通过情感词构建情感矩阵,并计算情感分数;
- 结果评估,包括将情感分数置于0.5到-0.5之间,并可视化显示。
SnowNLP
SnowNLP是一个常用的Python文本分析库,是受到TextBlob启发而发明的。由于当前自然语言处理库基本都是针对英文的,而中文没有空格分割特征词,Python做中文文本挖掘较难,后续开发了一些针对中文处理的库,例如SnowNLP、Jieba、BosonNLP等。注意SnowNLP处理的是unicode编码,所以使用时请自行decode成unicode。
Snownlp主要功能包括:
- 中文分词(算法是Character-Based Generative Model)
- 词性标注(原理是TnT、3-gram 隐马)
- 情感分析
- 文本分类(原理是朴素贝叶斯)
- 转换拼音、繁体转简体
- 提取文本关键词(原理是TextRank)
- 提取摘要(原理是TextRank)、分割句子
- 文本相似(原理是BM25)
安装和其他库一样,使用pip安装即可。
pip install snownlp
1、snownlp 常见功能及用法:
-
# -*- coding: utf-8 -*-
-
from snownlp
import SnowNLP
-
s = SnowNLP(
u"这本书质量真不太好!")
-
-
print(
"1、中文分词:\n",s.words)
-
"""
-
中文分词:
-
这 本书 质量 真 不 太 好 !
-
"""
-
-
-
print(
"2、词性标注:\n",s.tags)
-
-
-
print(
"3、情感倾向分数:\n",s.sentiments)
-
"""
-
情感分数:
-
0.420002029202
-
"""
-
-
print(
"4、转换拼音:\n",s.pinyin)
-
-
-
print(
"5、输出前4个关键词:\n",s.keywords(
4))
-
-
-
print(
"6、输出关键(中心)句:\n",s.summary(
1))
-
-
-
print(
"7.1、输出tf:\n",s.tf)
-
-
-
print(
"7.2、输出idf:\n",s.idf)
-
-
-
n = SnowNLP(
'「繁體字」「繁體中文」的叫法在臺灣亦很常見。')
-
print(
"8、繁简体转换:\n",n.han)
-
"""
-
繁简体转换:
-
「繁体字」「繁体中文」的叫法在台湾亦很常见。
-
"""

除此之外,还可以进行文本相似度计算:

SnowNLP情感分析也是基于情感词典实现的,其简单的将文本分为两类,积极和消极,返回值为情绪的概率,越接近1为积极,接近0为消极。

2、统计各情感分数段出现的评率并绘制对应的柱状图
对txt文件逐行进行情感倾向值计算,代码如下:
-
# -*- coding: utf-8 -*-
-
from snownlp
import SnowNLP
-
import codecs
-
import os
-
-
source =
open(
"data.txt",
"r", encoding=
'utf-8')
-
line = source.readlines()
-
sentimentslist = []
-
for i
in line:
-
s = SnowNLP(i)
-
print(s.sentiments)
-
sentimentslist.append(s.sentiments)
-
-
import matplotlib.pyplot
as plt
-
import numpy
as np
-
plt.hist(sentimentslist, bins = np.arange(
0,
1,
0.01), facecolor =
'g')
-
plt.xlabel(
'Sentiments Probability')
-
plt.ylabel(
'Quantity')
-
plt.title(
'Analysis of Sentiments')
-
plt.show()
结果如下:
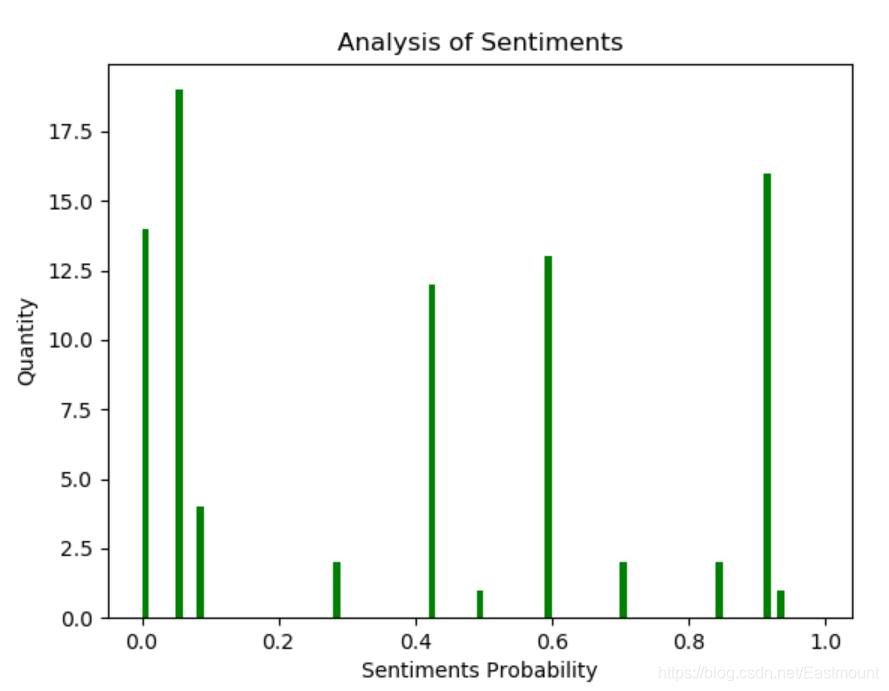
3、利用新的数据训练情感分析模型
在实际的项目中,需要根据实际的数据重新训练情感分析的模型,大致分为如下的几个步骤:
- 准备正负样本,并分别保存,如正样本保存到
pos.txt,负样本保存到neg.txt; - 利用snownlp训练新的模型
- 保存好新的模型
重新训练情感分析的代码如下所示:
-
#coding:UTF-8
-
-
from snownlp
import sentiment
-
-
if __name__ ==
"__main__":
-
# 重新训练模型
-
sentiment.train(
'./neg.txt',
'./pos.txt')
-
# 保存好新训练的模型
-
sentiment.save(
'sentiment.marshal')
使用训练后的模型需注意:
-
注意:若是想要利用新训练的模型进行情感分析,需要修改代码中的调用模型的位置。
-
data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),
'sentiment.marshal')
4、snownlp情感分析的源码解析
snownlp中支持情感分析的模块在sentiment文件夹中,其核心代码为__init__.py
如下是Sentiment类的代码:
-
class
Sentiment(
object):
-
-
def
__init__(
self):
-
self.classifier = Bayes()
# 使用的是Bayes的模型
-
-
def
save(
self, fname, iszip=True):
-
self.classifier.save(fname, iszip)
# 保存最终的模型
-
-
def
load(
self, fname=data_path, iszip=True):
-
self.classifier.load(fname, iszip)
# 加载贝叶斯模型
-
-
# 分词以及去停用词的操作
-
def
handle(
self, doc):
-
words = seg.seg(doc)
# 分词
-
words = normal.filter_stop(words)
# 去停用词
-
return words
# 返回分词后的结果
-
-
def
train(
self, neg_docs, pos_docs):
-
data = []
-
# 读入负样本
-
for sent
in neg_docs:
-
data.append([self.handle(sent),
'neg'])
-
# 读入正样本
-
for sent
in pos_docs:
-
data.append([self.handle(sent),
'pos'])
-
# 调用的是Bayes模型的训练方法
-
self.classifier.train(data)
-
-
def
classify(
self, sent):
-
# 1、调用sentiment类中的handle方法
-
# 2、调用Bayes类中的classify方法
-
ret, prob = self.classifier.classify(self.handle(sent))
# 调用贝叶斯中的classify方法
-
if ret ==
'pos':
-
return prob
-
return
1-probclass Sentiment(
object):
-
-
def
__init__(
self):
-
self.classifier = Bayes()
# 使用的是Bayes的模型
-
-
def
save(
self, fname, iszip=True):
-
self.classifier.save(fname, iszip)
# 保存最终的模型
-
-
def
load(
self, fname=data_path, iszip=True):
-
self.classifier.load(fname, iszip)
# 加载贝叶斯模型
-
-
# 分词以及去停用词的操作
-
def
handle(
self, doc):
-
words = seg.seg(doc)
# 分词
-
words = normal.filter_stop(words)
# 去停用词
-
return words
# 返回分词后的结果
-
-
def
train(
self, neg_docs, pos_docs):
-
data = []
-
# 读入负样本
-
for sent
in neg_docs:
-
data.append([self.handle(sent),
'neg'])
-
# 读入正样本
-
for sent
in pos_docs:
-
data.append([self.handle(sent),
'pos'])
-
# 调用的是Bayes模型的训练方法
-
self.classifier.train(data)
-
-
def
classify(
self, sent):
-
# 1、调用sentiment类中的handle方法
-
# 2、调用Bayes类中的classify方法
-
ret, prob = self.classifier.classify(self.handle(sent))
# 调用贝叶斯中的classify方法
-
if ret ==
'pos':
-
return prob
-
return
1-prob
从上述的代码中,classify函数和train函数是两个核心的函数,其中,train函数用于训练一个情感分类器,classify函数用于预测。在这两个函数中,都同时使用到的handle函数,handle函数的主要工作为:
- 对输入文本分词
- 去停用词
情感分类的基本模型是贝叶斯模型Bayes,对于贝叶斯模型,可以参见文章简单易学的机器学习算法——朴素贝叶斯。
中文自然语言分析系统:http://ictclas.nlpir.org/nlpir/
本文参考于: