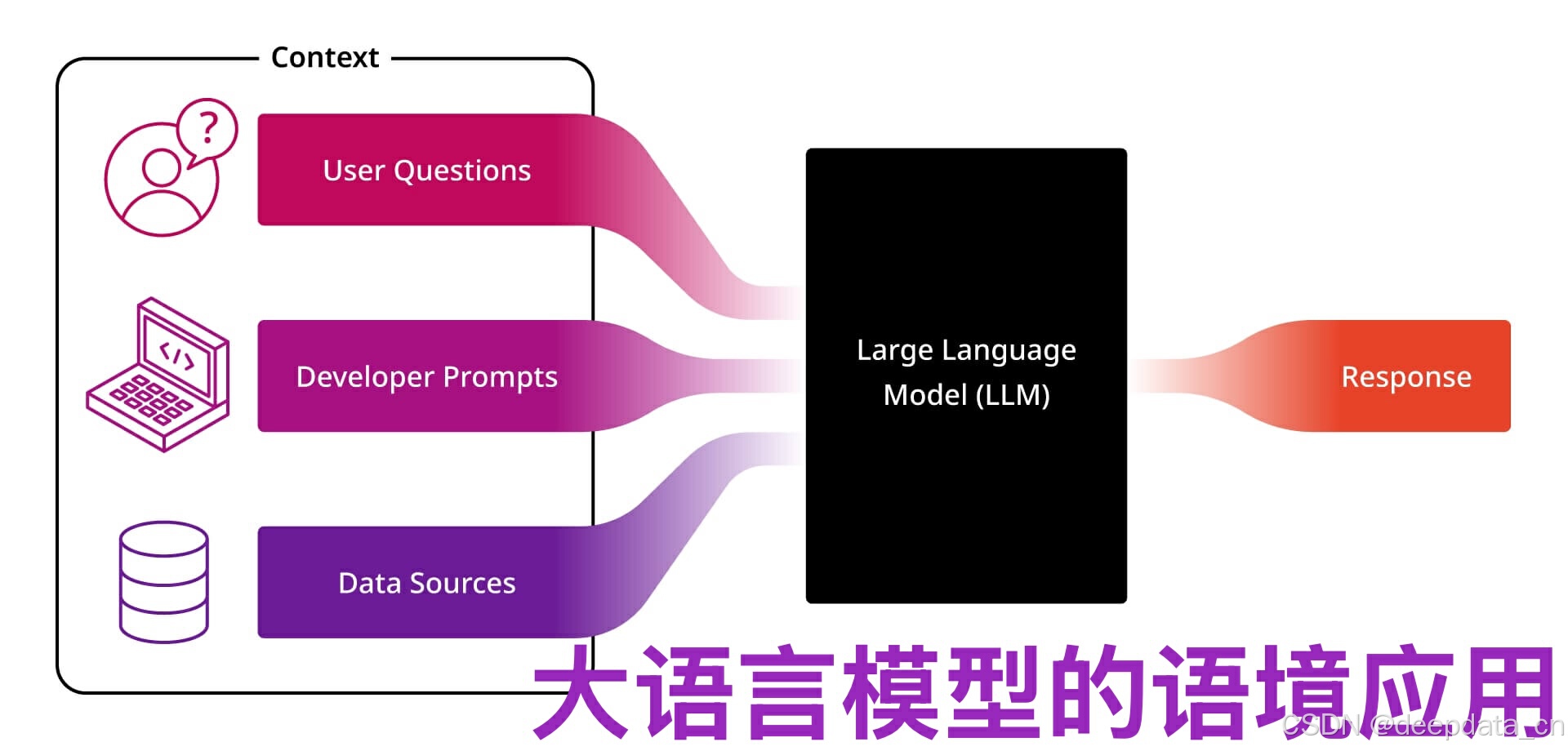
大语言模型的语境指的是在语言交互过程中,围绕特定文本或话语所存在的各种相关信息,这些信息能够帮助模型更好地理解和生成语言,使语言表达和理解更加准确、连贯和合理。
一、语境分类
1.上下文语境
文本上下文:在一段连续的文本中,位于目标文本前后的文字内容构成了文本上下文语境。比如在一篇文章中,前文提到的主题、事件、观点等信息,会为后续内容的理解提供基础。例如,前文描述了“人工智能在医疗领域的应用越来越广泛”,后面提到“它可以辅助医生进行疾病诊断”,这里的“它”就通过前文的文本上下文明确指向“人工智能”。
对话上下文:在对话场景中,之前轮次的对话内容就是当前对话的语境。每一轮对话都会基于前面的交流内容展开,形成一个连贯的语义链条。例如,在一个问诊对话中,患者先说“我最近头疼”,医生接着问“有没有其他症状”,这里医生的问题就是基于患者前面说的“头疼”这一语境提出的。
2.领域与主题语境
专业领域语境:不同的专业领域有其特定的术语、概念、知识体系和语言表达方式,这些构成了专业领域语境。比如在法律领域,会经常出现“诉讼”“证据”“法条”等专业词汇,以及特定的法律推理和论证方式。大语言模型在处理法律相关的文本或问题时,需要依据这个领域的语境来准确理解和生成内容。
主题语境:围绕特定主题所涉及的相关知识、背景信息和常见话题范围等构成了主题语境。例如,当主题是“环境保护”时,与之相关的气候变化、污染治理、可持续发展等方面的信息和词汇就形成了这个主题的语境,模型在处理该主题的文本时,会利用这些语境信息来生成相关内容。
3.文化与社会语境
文化背景语境:不同的文化具有不同的价值观、信仰、习俗、历史等,这些文化因素会影响语言的使用和理解。比如在一些文化中,红色象征着吉祥、幸福,而在另一些文化中可能有不同的含义。大语言模型在处理涉及文化相关的文本时,需要考虑这些文化背景语境,才能准确理解和表达相关内容。
社会环境语境:包括社会的时代特征、社会关系、社会规范等因素。例如在不同的历史时期,语言的表达方式和常用词汇会有所不同;在不同的社交场合,语言的风格和用词也会有差异。在正式的商务场合和休闲的朋友聚会中,人们使用的语言是不一样的,大语言模型需要根据这些社会环境语境来调整生成的语言。
3.意图与情感语境
意图语境:指的是说话者或文本作者的目的和意图。理解意图语境有助于模型更准确地解读文本和做出合适的回应。例如,一个文本的意图是推销产品,那么其中的语言可能会强调产品的优点和独特之处;如果意图是提供信息,语言会更侧重于客观事实的陈述。
情感语境:文本或话语中所蕴含的情感倾向和态度也构成了情感语境。它可以是积极、消极或中性的情感,也可以是更具体的如喜悦、愤怒、悲伤等情感。比如一条评论“这部电影太棒了,我非常喜欢”就表达了积极的情感语境,模型在处理这样的文本时,需要识别出其中的情感,并在生成回答时做出相应的情感回应或分析。
二、语境应用
1.对语境的理解与编码
分词与标记化:首先将输入的文本(包括问题本身以及相关的上下文语境)进行分词或标记化处理,把文本转化为模型能够处理的基本单元序列。例如,将句子“我喜欢吃苹果”分词为“我”“喜欢”“吃”“苹果”等标记,以便模型对每个部分进行分析。
嵌入表示:将这些标记映射为低维向量空间中的向量表示,即词嵌入或字符嵌入等。这样模型可以通过向量的运算和比较来捕捉词语之间的语义关系。如“苹果”和“香蕉”的向量在空间中距离较近,因为它们都属于水果范畴,而与“汽车”的向量距离较远。
编码语境信息:利用神经网络结构,如Transformer中的编码器,对这些嵌入向量进行处理,通过自注意力机制等方式捕捉文本中的长序列依赖关系,从而理解整个语境的语义信息。比如在处理一个多轮对话的语境时,模型能够根据之前的对话内容理解当前问题的背景和意图。
2.利用语境信息进行推理
知识融合:将编码后的语境信息与模型预训练中学习到的知识进行融合。模型会根据语境中的关键词和语义线索,从其庞大的知识储备中检索出相关的知识,并结合起来进行推理。例如,当问题是“苹果富含什么营养成分”时,模型会根据“苹果”这个关键词以及整个问题的语境,从预训练知识中提取关于苹果营养成分的信息来回答。
语义关联与推理:分析语境中词语之间的语义关联,进行逻辑推理。比如在语境中提到“水果对健康有益,苹果是一种水果”,当被问到“苹果对健康有好处吗”时,模型能够通过语义关联和简单的逻辑推理得出肯定的答案。
多轮对话中的语境推理:在多轮对话场景中,模型会记住之前轮次的对话内容作为语境,理解当前问题与之前对话的逻辑关系,进行连贯的回答。例如,在对话中先提到“我打算去超市”,后面又问“我应该带什么”,模型会结合前面提到的“去超市”这一语境,给出诸如“购物袋”等合理的回答。
3.生成符合语境的回答
解码器生成:基于对语境的理解和推理,利用Transformer中的解码器生成回答文本。解码器会根据输入的语境向量和模型参数,预测下一个可能的标记,并逐步生成完整的回答。在生成过程中,会不断参考语境信息,确保回答的连贯性和相关性。
调整回答风格和内容:根据语境的风格、语气和角色等因素,调整回答的风格和内容。如果语境是正式的商务交流,模型会生成较为严谨、规范的回答;如果是朋友之间的轻松对话,回答则会更口语化、亲切。比如在正式语境中回答“苹果的好处”可能会使用专业术语详细阐述营养成分等,而在朋友聊天中可能会简单说“苹果吃了对身体好,能补充维生素啥的”。
评估与优化回答:生成回答后,模型可能会根据语境信息对回答进行评估,检查回答是否符合语境要求、是否逻辑自洽等。如果发现问题,会对回答进行调整和优化,以提高回答的质量。
三、语境的影响
领域与主题语境对大语言模型性能的影响主要体现在准确性、泛化能力、可解释性、生成内容质量等方面:
1.对准确性的影响
专业词汇与概念理解:不同领域和主题有特定的专业词汇和概念。在医学领域,“心肌梗死”“冠状动脉造影”等术语有明确的专业含义。大语言模型若对这些词汇的理解不准确,在处理医学相关问题时就容易出现错误。例如,将“心肌梗死”的症状解释错误,导致回答不准确。而在金融领域,像“市盈率”“套期保值”等概念,模型也需要准确理解才能提供正确的金融分析和建议。
语义关系与逻辑推理:领域和主题语境中的语义关系和逻辑推理规则也具有独特性。在数学领域,逻辑推理非常严谨,模型需要理解定理、公式之间的逻辑关系才能正确解题。在法律领域,案件的事实认定、法律适用等都有严格的逻辑规则,模型要准确把握法律条文与具体案例之间的语义关系和逻辑联系,才能做出合理的法律分析和判断。如果模型对这些领域的逻辑关系理解有误,就会得出错误的结论,影响其准确性。
2.对泛化能力的影响
领域适应性:大语言模型在预训练阶段会接触到大量不同领域和主题的文本数据,但不同领域的语言风格、知识结构差异较大。当模型应用于新的特定领域时,如果该领域的语境与预训练数据中的分布差异较大,模型可能需要进行领域适配调整才能表现良好。例如,一个在通用文本上训练的模型,在处理航空航天领域的专业问题时,可能会因为对该领域的特殊语境不熟悉,而出现回答不专业、不准确的情况。
主题迁移性:即使在同一领域内,不同主题之间也存在差异。例如在科技领域,人工智能主题和新能源主题虽然都属于科技范畴,但涉及的具体知识和概念不同。模型需要具备良好的主题迁移能力,才能在不同主题之间灵活切换和准确处理。如果模型对某个主题的语境过于依赖或理解不深入,在遇到相关但不同的主题时,可能无法很好地泛化,导致性能下降。
3.对可解释性的影响
领域知识的复杂性:一些领域如物理学、生物学等,具有高度复杂的知识体系和理论框架。大语言模型在处理这些领域的问题时,其生成的回答可能涉及到复杂的专业知识和推理过程,使得解释模型的决策依据变得困难。例如,模型在解释一个物理现象的原理时,可能会给出一系列专业的物理概念和公式推导,但对于非专业人士来说,很难理解模型是如何从输入的问题和语境中得出这些结论的,从而影响了模型的可解释性。
主题相关的隐喻和象征:在一些文化、艺术等领域的主题中,经常会使用隐喻、象征等修辞手法,这些内容增加了语言的丰富性,但也给模型的解释带来了挑战。例如在文学作品中,“玫瑰”可能象征着爱情,但模型很难清晰地解释它是如何根据具体语境确定这种象征意义的,以及为什么选择这样的解释,这使得模型的输出在可解释性方面存在一定的困难。
4.对生成内容质量的影响
内容的专业性和深度:领域与主题语境决定了模型生成内容所需的专业性和深度。在学术研究领域,模型需要生成具有一定学术水平和深度的内容,如专业的研究论文、学术报告等。如果模型对该领域的语境理解不够深入,可能只能生成一些表面的、缺乏深度的内容。例如在计算机科学领域,对于复杂的算法分析和技术讨论,模型需要具备扎实的专业知识和对领域语境的准确把握,才能生成有价值、有深度的内容。
风格和连贯性:不同领域和主题有各自的语言风格和表达习惯。在新闻报道中,语言通常简洁明了、客观中立;而在文学创作中,语言则更注重文采和情感表达。模型需要根据不同的领域和主题语境,调整生成内容的风格和语气,以保证内容的连贯性和适应性。如果模型不能很好地适应这些风格差异,生成的内容可能会显得风格混乱、不伦不类,影响内容质量。