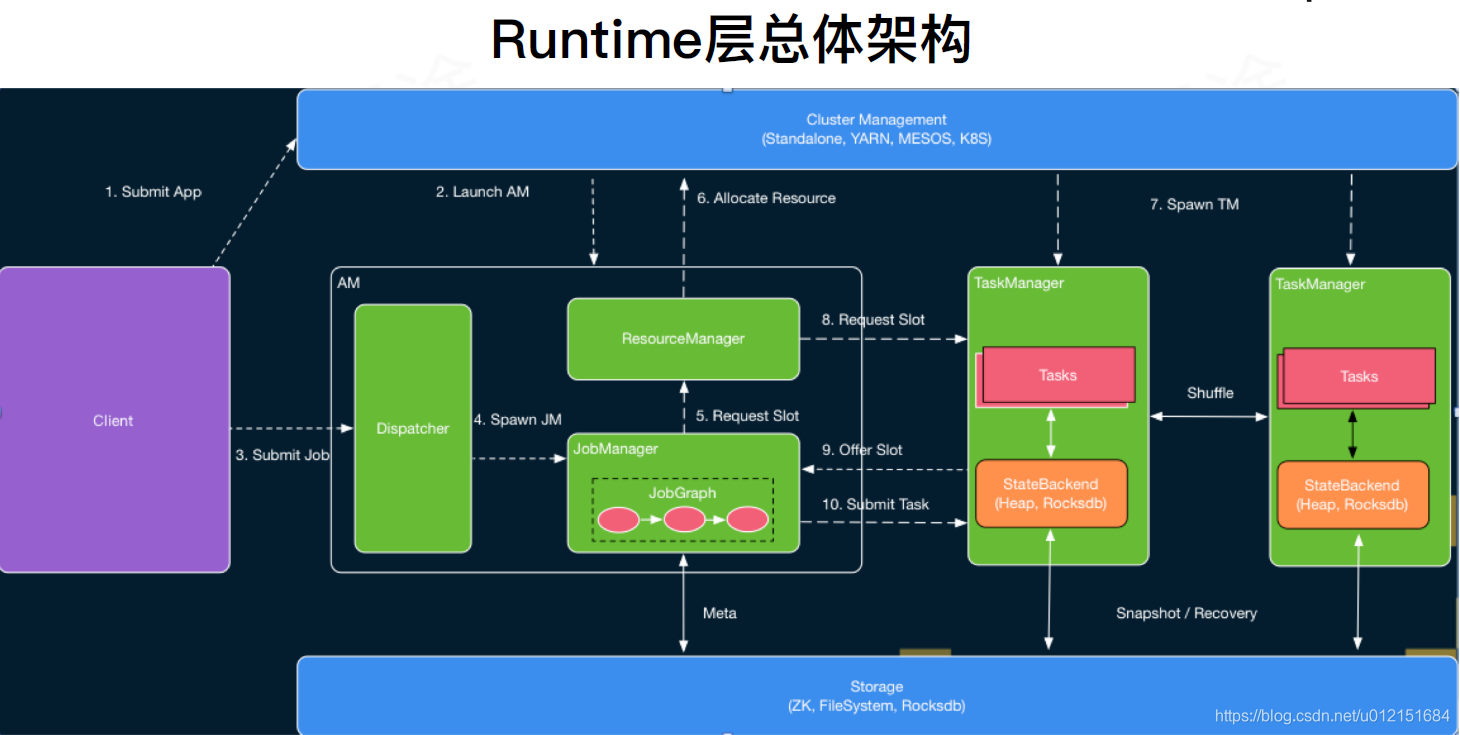
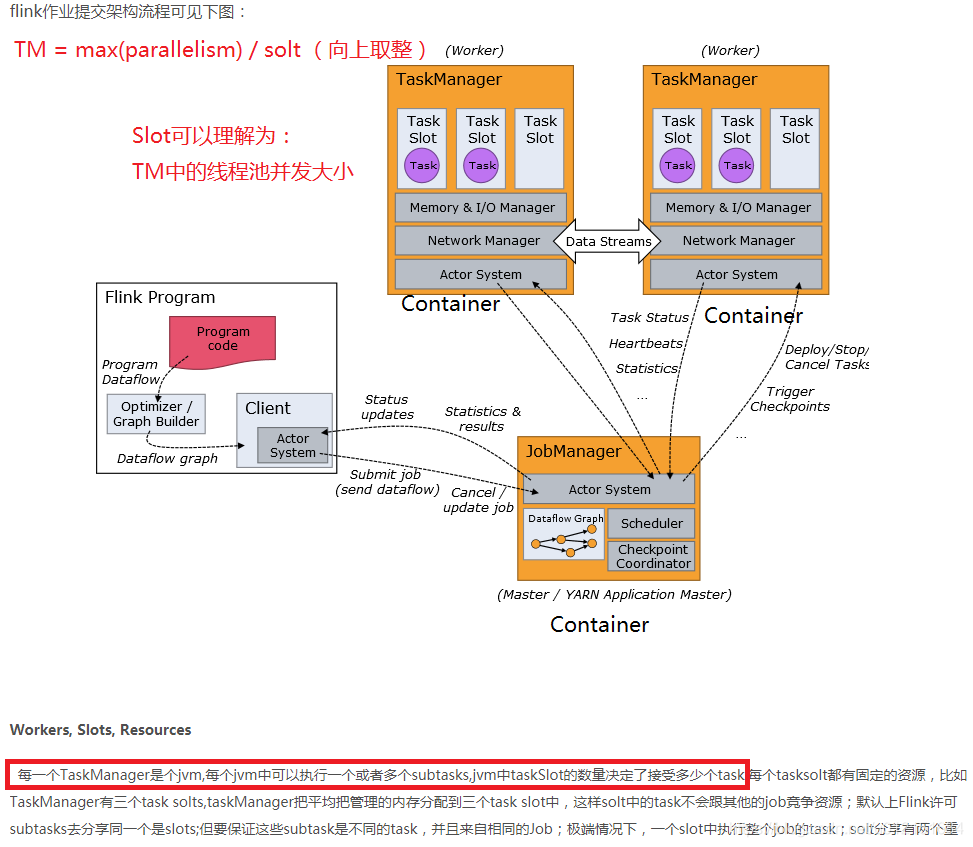
MiniCluster的启动流程:
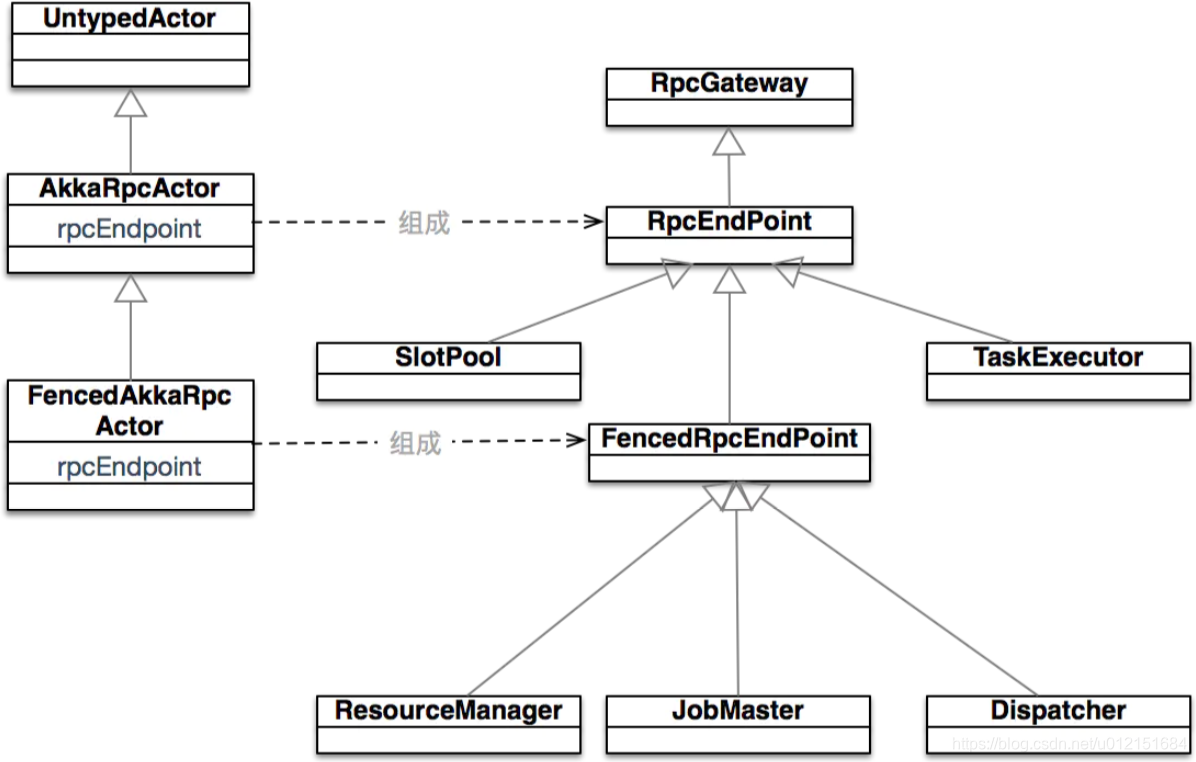
首先来看最简单的本地模式MiniCluster的启动流程,以此来分析Flink的具体启动流程以及内部各组件之间的交互形式。MiniCluster可以看做是内嵌的Flink运行时环境,所有的组件都在独立的本地线程中运行。MiniCluster的启动入口在LocalStreamEnvironment#execute(jobName)中。其基本的相关的主要类图和actor模型如下:
在MiniCluster#start启动源码中,启动流程大致分为三个阶段:
- 初始化配置信息、创建一些辅助的服务,如RpcService,HighAvailabilityServices,BlobServer,HeartbeatServices等
- 启动ResourceManager、TaskManager等
- 启动Dispatcher等
在MiniCluster中,其集群中的各个角色分配及作用如下:
- ResouceManager
- 负责容器的分配
- 使用FencedAkkaRpcActor实现,其rpcEndpoint为org.apache.flink.runtime.resourcemanager.ResourceManager
- JobMaster
- 负责任务执行计划的调度和执行,
- 使用FencedAkkaRpcActor实现,其rpcEndpoint为org.apache.flink.runtime.jobmaster.JobMaster
- JobMaster持有一个SlotPool的Actor,用来暂存TaskExecutor提供给JobMaster并被接受的slot。JobMaster的Scheduler组件从这个SlotPool中获取资源以调度job的task
- Dispatcher
- 主要职责是接收从Client端提交过来的job并生成一个JobMaster去负责这个job在集群资源管理器上执行。
- 不是所有部署方式都需要用到dispatcher,比如yarn-cluster 的部署方式可能就不需要
- 使用FencedAkkaRpcActor实现,其rpcEndpoint为 org.apache.flink.runtime.dispatcher.StandaloneDispatcher
- 主要职责是接收从Client端提交过来的job并生成一个JobMaster去负责这个job在集群资源管理器上执行。
- TaskExecutor
- TaskExecutor会与ResouceManager和JobMaster两者进行通信。
- 会向ResourceManager报告自身的可用资源;并维护本身slot的状态
- 根据slot的分配结果,接收JobMaster的命令在对应的slot上执行指定的task。
- TaskExecutor还需要向以上两者定时上报心跳信息。
- 使用AkkaRpcActor实现,其rpcEndpoint为org.apache.flink.runtime.taskexecutor.TaskExecutor
- TaskExecutor会与ResouceManager和JobMaster两者进行通信。
/**
* Starts the mini cluster, based on the configured properties.
* @throws Exception This method passes on any exception that occurs during the startup of the mini cluster.
*/
public void start() throws Exception {
synchronized (lock) {
checkState(!running, "FlinkMiniCluster is already running");
LOG.info("Starting Flink Mini Cluster");
LOG.debug("Using configuration {}", miniClusterConfiguration);
// MiniCluster初始化配置信息
final Configuration configuration = miniClusterConfiguration.getConfiguration();
final Time rpcTimeout = miniClusterConfiguration.getRpcTimeout();
final int numTaskManagers = miniClusterConfiguration.getNumTaskManagers();
final boolean useSingleRpcService = miniClusterConfiguration.getRpcServiceSharing() == RpcServiceSharing.SHARED;
try {
initializeIOFormatClasses(configuration); // 初始化fs write or dir是否允许over_write
LOG.info("Starting Metrics Registry");
metricRegistry = createMetricRegistry(configuration); // 创建指标监控服务
this.jobManagerMetricGroup = MetricUtils.instantiateJobManagerMetricGroup( //
metricRegistry,
"localhost",
ConfigurationUtils.getSystemResourceMetricsProbingInterval(configuration));
final RpcService jobManagerRpcService;
final RpcService resourceManagerRpcService;
final RpcService[] taskManagerRpcServices = new RpcService[numTaskManagers];
// bring up all the RPC services // 根据conf信息 构建对应的rpc服务 (本地运行的话 rpc服务是通用的 适用于多个服务)
LOG.info("Starting RPC Service(s)");
// we always need the 'commonRpcService' for auxiliary calls
commonRpcService = createRpcService(configuration, rpcTimeout, false, null);
// TODO: Temporary hack until the metric query service is ported to the RpcEndpoint
metricQueryServiceActorSystem = MetricUtils.startMetricsActorSystem(
configuration,
commonRpcService.getAddress(),
LOG);
metricRegistry.startQueryService(metricQueryServiceActorSystem, null);
if (useSingleRpcService) { // rpc服务是否可share
for (int i = 0; i < numTaskManagers; i++) {
taskManagerRpcServices[i] = commonRpcService;
}
jobManagerRpcService = commonRpcService;
resourceManagerRpcService = commonRpcService;
this.resourceManagerRpcService = null;
this.jobManagerRpcService = null;
this.taskManagerRpcServices = null;
}
else {
// start a new service per component, possibly with custom bind addresses
final String jobManagerBindAddress = miniClusterConfiguration.getJobManagerBindAddress();
final String taskManagerBindAddress = miniClusterConfiguration.getTaskManagerBindAddress();
final String resourceManagerBindAddress = miniClusterConfiguration.getResourceManagerBindAddress();
jobManagerRpcService = createRpcService(configuration, rpcTimeout, true, jobManagerBindAddress);
resourceManagerRpcService = createRpcService(configuration, rpcTimeout, true, resourceManagerBindAddress);
for (int i = 0; i < numTaskManagers; i++) {
taskManagerRpcServices[i] = createRpcService(
configuration, rpcTimeout, true, taskManagerBindAddress);
}
this.jobManagerRpcService = jobManagerRpcService;
this.taskManagerRpcServices = taskManagerRpcServices;
this.resourceManagerRpcService = resourceManagerRpcService;
}
// create the high-availability services // 构建ha高可用服务
LOG.info("Starting high-availability services");
haServices = HighAvailabilityServicesUtils.createAvailableOrEmbeddedServices(
configuration,
commonRpcService.getExecutor());
blobServer = new BlobServer(configuration, haServices.createBlobStore()); // 构建分布式文件存储服务
blobServer.start();
heartbeatServices = HeartbeatServices.fromConfiguration(configuration); // 心跳服务
// bring up the ResourceManager(s)
// 启动构建ResourceManger服务及其内部组件,主要托管给resourceManagerRunner类,其内部持有ResourceManger实例;
// 并启动ResourceManager#start()以此来启动资源管理器的服务
LOG.info("Starting ResourceManger");
resourceManagerRunner = startResourceManager(
configuration,
haServices,
heartbeatServices,
metricRegistry,
resourceManagerRpcService,
new ClusterInformation("localhost", blobServer.getPort()),
jobManagerMetricGroup);
// 构建分布式存储服务
blobCacheService = new BlobCacheService(
configuration, haServices.createBlobStore(), new InetSocketAddress(InetAddress.getLocalHost(), blobServer.getPort())
);
// bring up the TaskManager(s) for the mini cluster
LOG.info("Starting {} TaskManger(s)", numTaskManagers);
taskManagers = startTaskManagers( // 启动对应数量的TaskManager
configuration,
haServices,
heartbeatServices,
metricRegistry,
blobCacheService,
numTaskManagers,
taskManagerRpcServices);
// starting the dispatcher rest endpoint
LOG.info("Starting dispatcher rest endpoint.");
dispatcherGatewayRetriever = new RpcGatewayRetriever<>(
jobManagerRpcService,
DispatcherGateway.class,
DispatcherId::fromUuid,
20,
Time.milliseconds(20L));
final RpcGatewayRetriever<ResourceManagerId, ResourceManagerGateway> resourceManagerGatewayRetriever = new RpcGatewayRetriever<>(
jobManagerRpcService,
ResourceManagerGateway.class,
ResourceManagerId::fromUuid,
20,
Time.milliseconds(20L));
// 注册开启rest web服务端(主要是RestServerEndpoint)
// 其会web端的JobSubmitHandler(供web端进行job任务的提交)
// 之后便会对web端的所有REST接口服务进行handler注册(主要包括web页面展示的job、metric、checkpoint、savepoint等等)
this.dispatcherRestEndpoint = new DispatcherRestEndpoint(
RestServerEndpointConfiguration.fromConfiguration(configuration),
dispatcherGatewayRetriever,
configuration,
RestHandlerConfiguration.fromConfiguration(configuration),
resourceManagerGatewayRetriever,
blobServer.getTransientBlobService(),
WebMonitorEndpoint.createExecutorService(
configuration.getInteger(RestOptions.SERVER_NUM_THREADS, 1),
configuration.getInteger(RestOptions.SERVER_THREAD_PRIORITY),
"DispatcherRestEndpoint"),
new AkkaQueryServiceRetriever(
metricQueryServiceActorSystem,
Time.milliseconds(configuration.getLong(WebOptions.TIMEOUT))),
haServices.getWebMonitorLeaderElectionService(),
new ShutDownFatalErrorHandler());
dispatcherRestEndpoint.start(); //
restAddressURI = new URI(dispatcherRestEndpoint.getRestBaseUrl());
// bring up the dispatcher that launches JobManagers when jobs submitted
LOG.info("Starting job dispatcher(s) for JobManger");
final HistoryServerArchivist historyServerArchivist = HistoryServerArchivist.createHistoryServerArchivist(configuration, dispatcherRestEndpoint);
//
dispatcher = new StandaloneDispatcher(
jobManagerRpcService,
Dispatcher.DISPATCHER_NAME + UUID.randomUUID(),
configuration,
haServices,
resourceManagerRunner.getResourceManageGateway(),
blobServer,
heartbeatServices,
jobManagerMetricGroup,
metricRegistry.getMetricQueryServicePath(),
new MemoryArchivedExecutionGraphStore(),
Dispatcher.DefaultJobManagerRunnerFactory.INSTANCE,
new ShutDownFatalErrorHandler(),
dispatcherRestEndpoint.getRestBaseUrl(),
historyServerArchivist);
dispatcher.start(); // 启动基本的调度分发服务(其内部持有jobmaster去进行具体的任务执行与分发)
resourceManagerLeaderRetriever = haServices.getResourceManagerLeaderRetriever();
dispatcherLeaderRetriever = haServices.getDispatcherLeaderRetriever();
resourceManagerLeaderRetriever.start(resourceManagerGatewayRetriever);
dispatcherLeaderRetriever.start(dispatcherGatewayRetriever);
}
catch (Exception e) {
// cleanup everything
try {
close();
} catch (Exception ee) {
e.addSuppressed(ee);
}
throw e;
}
// create a new termination future
terminationFuture = new CompletableFuture<>();
// now officially mark this as running
running = true;
LOG.info("Flink Mini Cluster started successfully");
}
}1、HighAvailabilityServices
HighAvailabilityServicesUtils是创建HighAvailabilityServices的工具类,其主要通过配置config中的high-availability选项来进行具体高可用服务组件的选择及实例化;其通过工厂设计模式来进行具体对象的实例化;主要分为三类:
- NONE:EmbeddedHaServices
- ZOOKEEPER:ZooKeeperHaServices
- FACTORY_CLASS:自定义实现(在配置中指定对应的className)
在没有配置HA的情况下会创建EmbeddedHaServices。EmbeddedHaServices不具备高可用的特性,适用于ResourceMangaer,TaksManager,JobManager等所有组件都运行在同一个进程的情况。EmbeddedHaService为各组件创建的选举服务为EmbeddedLeaderElectionService,一旦有参与选举的LeaderContender加入,该contender就被选择为leader。
public static HighAvailabilityServices createAvailableOrEmbeddedServices(Configuration config, Executor executor) throws Exception {
HighAvailabilityMode highAvailabilityMode = LeaderRetrievalUtils.getRecoveryMode(config); // 选择对应的ha模式
switch (highAvailabilityMode) {
case NONE:
return new EmbeddedHaServices(executor);
case ZOOKEEPER:
BlobStoreService blobStoreService = BlobUtils.createBlobStoreFromConfig(config);
return new ZooKeeperHaServices(
ZooKeeperUtils.startCuratorFramework(config),
executor,
config,
blobStoreService);
case FACTORY_CLASS:
return createCustomHAServices(config, executor);
default:
throw new Exception("High availability mode " + highAvailabilityMode + " is not supported.");
}
}
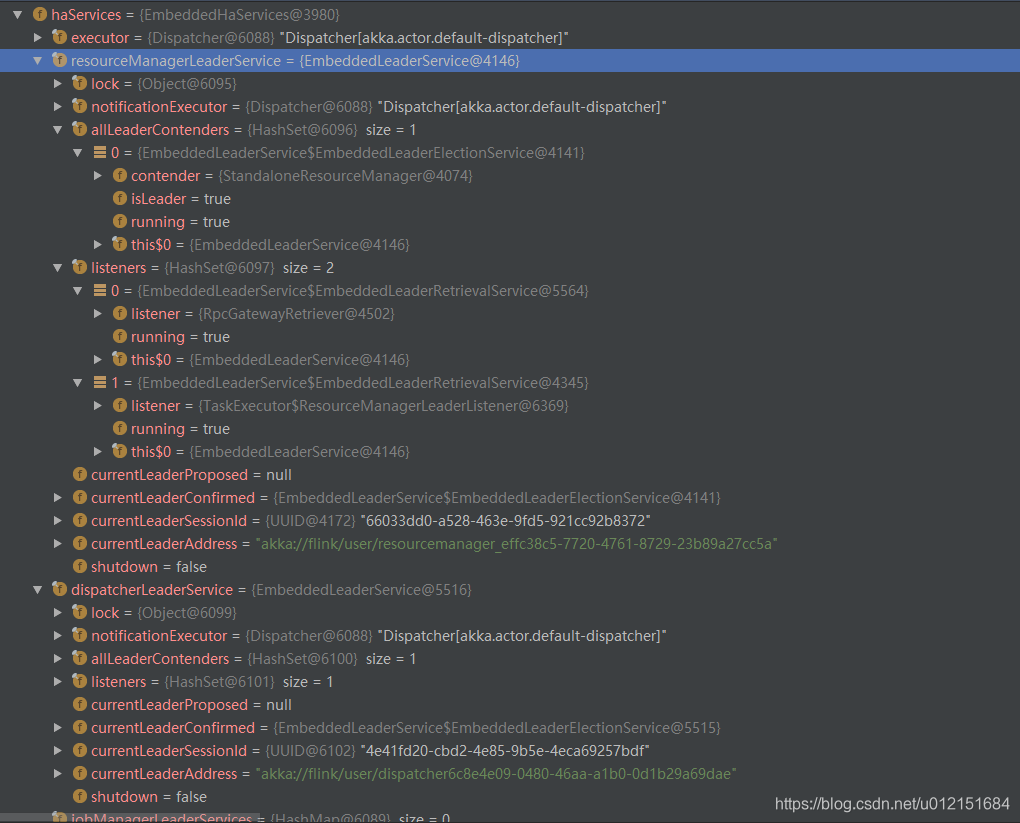
// EmbeddedHaServices高可用服务 其内部主要用于保存对应组件的leaderService服务; 其内部主要保存以下几种组件ha服务(不同EmbeddedLeaderService实例)
private final EmbeddedLeaderService resourceManagerLeaderService; // 用于RM选举相关
private final EmbeddedLeaderService dispatcherLeaderService; // 用于dispatcher选举相关
private final HashMap<JobID, EmbeddedLeaderService> jobManagerLeaderServices; // 用于JobManager选举相关;一个job任务对应一个
private final EmbeddedLeaderService webMonitorLeaderService; // webmonitor其中ha最主要相关的两个服务:
1、LeaderElectionService用于组件参与leader选举(其相关的接口如下);start方法就是将当前的组件加入Leader选举;
当某个组件被选举为leader时,会回调该组件实现的grantLeadership方法(第一次被选举为leader),当某个组件不再是leader时,会回调该组件实现的revokeLeadership方法。
public interface LeaderElectionService {
void start(LeaderContender contender) throws Exception; // 将当前组件加入到leader选举
void stop() throws Exception;
void confirmLeaderSessionID(UUID leaderSessionID);
boolean hasLeadership(@Nonnull UUID leaderSessionId);
}
public interface LeaderContender {
void grantLeadership(UUID leaderSessionID);
void revokeLeadership();
String getAddress();
void handleError(Exception exception);
}2、LeaderRetrievalListener用于leader改变后通知回调,其主要用于获取其他组件Leader的功能
LeaderRetrievalService非常简洁,提供了start和stop方法,并且start方法只能被调用一次,在ZK模式中因为它只会监听一条ZK上的路径(即一个组件的变化);
在启动LeaderRetrievalService的方法中需要接收参数LeaderRetrievalListener,将实现这个接口的类的实例作为参数传入这个方法;
在相应组件leader发生变化时会回调notifyLeaderAddress方法,在LeaderRetrievalService抛出异常的时候会调用handleError方法;
public interface LeaderRetrievalService {
void start(LeaderRetrievalListener listener) throws Exception;
void stop() throws Exception;
}
public interface LeaderRetrievalListener {
void notifyLeaderAddress(@Nullable String leaderAddress, @Nullable UUID leaderSessionID);
void handleError(Exception exception);
}其部分运行debug实例示例如下:
2、ResourceManager
在创建HighAvailabilityServices之后,就会启动ResourceManager。ResourceManagerRunner#startResourceManager会创建ResourceManager和对应的ResourceManagerRuntimeServices;其中ResourceManagerRuntimeServices主要工作类似于工厂类;其主要负责SlotManager和JobLeaderIdService服务的初始化实例创建,(其中JobLeaderIdService服务主要作用是为每个job任务选择出对应ha可用的JobMaster,并将该job任务分配该JobMatser)
JobLeaderIdService#addJob()
/**
* Add a job to be monitored to retrieve the job leader id.
*
* @param jobId identifying the job to monitor
* @throws Exception if the job could not be added to the service
*/
public void addJob(JobID jobId) throws Exception {
Preconditions.checkNotNull(jobLeaderIdActions);
LOG.debug("Add job {} to job leader id monitoring.", jobId);
if (!jobLeaderIdListeners.containsKey(jobId)) {
LeaderRetrievalService leaderRetrievalService = highAvailabilityServices.getJobManagerLeaderRetriever(jobId); // 从ha中选择出合适的leader
JobLeaderIdListener jobIdListener = new JobLeaderIdListener(jobId, jobLeaderIdActions, leaderRetrievalService);
jobLeaderIdListeners.put(jobId, jobIdListener);
}
}ResourceManager资源管理器其继承了FencedRpcEndpoint实现了RPC服务,其内部组件主要包含
- 上诉的SlotManager和JobLeaderIdService服务、高可用leader选举服务leaderElectionService等
- 心跳管理器taskManagerHeartbeatManager、jobManagerHeartbeatManager
- 指标监控服务MetricRegistry等
- 所有已注册的TaskExecutors
之后其会调用ResourceManager#start()方法来启动此RM;在ResourceManager启动的回调函数中,会通过HighAvailabilityServices获取到选举服务,从而参与到选举之中。并启动JobLeaderIdService,管理向当前ResourceManager注册的作业的leader id。其主要启动服务内容如下:
ResourceManager#start()方法:
public void start() throws Exception {
// start a leader
super.start(); // 调用父类RPC接口;以此启动RPC服务
leaderElectionService = highAvailabilityServices.getResourceManagerLeaderElectionService(); // 可用的ha leader选举服务
initialize(); // 初始化 do nothing;不做任何操作
try {
// 将该RM加入并选举作为leader;
// 并在里面启动SlotManager相关的周期性超时检测线程(主要包括checkTaskManagerTimeouts、checkSlotRequestTimeouts)
leaderElectionService.start(this);
} catch (Exception e) {
throw new ResourceManagerException("Could not start the leader election service.", e);
}
try {
jobLeaderIdService.start(new JobLeaderIdActionsImpl()); //
} catch (Exception e) {
throw new ResourceManagerException("Could not start the job leader id service.", e);
}
registerSlotAndTaskExecutorMetrics(); // 添加slots指标监控,taskSlotsAvailable、taskSlotsTotal、numRegisteredTaskManagers
}3、TaskExecutor
之后便是启动对应的TaskManager,TaskManager的启动流程类似于ResourceManager,也是委托给TaskManagerRunner#startTaskManager();TaskManagerRunner内部的主要工作包括参数校验和初始化组件如下:
- 先初始化config参数配置,主要包括network、memory、JVM内存或堆外内存等等
- 其次启动对应的network、I/O manager、memory manager、BroadcastVariableManager、TaskSlotTable、JobManagerTable、TaskExecutorLocalStateStoresManager等等
- 最终根据上诉的内部组件启动TaskExecutor实例
TaskExecutor任务管理器也继承了RpcEndpoint实现了RPC服务;其主要的内部组件包含(其实也就是TaskManagerRunner初始化的组件):
- 高可用服务HighAvailabilityServices
- 心跳管理器jobManagerHeartbeatManager、resourceManagerHeartbeatManager
- 上诉对应的network、I/O manager、memory manager、BroadcastVariableManager、TaskSlotTable、JobManagerTable、TaskExecutorLocalStateStoresManager等等组件
- 其次会和ResourceManager建立连接EstablishedResourceManagerConnection、TaskExecutorToResourceManagerConnection;(在TM#start()的时候建立)
以及和对应JobManager建立的连接jobManagerConnections;
之后其会调用TaskManager#start()方法来启动此TM;在TaskManager启动的回调函数中,会通过HighAvailabilityServices获取到选举服务,从而参与到选举之中。并启动JobLeaderIdService,管理向当前ResourceManager注册的作业的leader id。其主要启动服务内容如下:
TaskExecutor#start()方法:
public void start() throws Exception {
super.start(); // 调用父类RPC接口;以此启动RPC服务
// start by connecting to the ResourceManager
try {
// 采用LeaderRetrievalService进行选举出leader后的回调通知;其会调用listener中的notifyLeaderAddress()方法;
// 进行RM的连接; 向RM注册自己以及建立相关的心跳连接;建立连接(resourceManagerConnection = new TaskExecutorToResourceManagerConnection(......., ResourceManagerRegistrationListener))
// 其在连接建立成功之后;会通过ResourceManagerRegistrationListener监听RM连接成功回调函数进行 将slot资源通过RPC向RM进行上报
resourceManagerLeaderRetriever.start(new ResourceManagerLeaderListener());
} catch (Exception e) {
onFatalError(e);
}
// tell the task slot table who's responsible for the task slot actions //
taskSlotTable.start(new SlotActionsImpl());
// start the job leader service
// 开启jobLeaderService服务并添加回调监听;等待jobmanager参与leader选举,监听回调JobLeaderListenerImpl进行establishJobManagerConnection
// 也向其jobmanager提供其管理的job任务jobId对应申请的slot资源状态;offerSlotsToJobManager(jobId);
jobLeaderService.start(getAddress(), getRpcService(), haServices, new JobLeaderListenerImpl()); //
fileCache = new FileCache(taskManagerConfiguration.getTmpDirectories(), blobCacheService.getPermanentBlobService());
startRegistrationTimeout();
}其连接主要是通过LeaderRetrievalListener来进行的,首先其会注册自己的监听器ResourceManagerLeaderListener,之后便等待leader选举并发送执行NotifyOfLeaderCall通知;其会调用对应注册监听器ResourceManagerLeaderListener的listener.notifyLeaderAddress(); 方法产生回调;一旦获取ResourceManager的leader被确定以及Call通知之后,就可以获取到ResourceManager对应的RpcGateway,之后便会异步的与对应的RM建立连接reconnectToResourceManager;在成功建立连接到RM之后,便会通过RPC异步的调用resourceManager.registerTaskExecutor();向RM注册自己以及建立相关的心跳连接;在注册成功之后,其注册成功信息会通过ResourceManagerRegistrationListener监听函数异步回调;向RM上报自己的slot资源;
/**
* The listener for leader changes of the resource manager.
*/
private final class ResourceManagerLeaderListener implements LeaderRetrievalListener {
@Override
public void notifyLeaderAddress(final String leaderAddress, final UUID leaderSessionID) {
// 获得ResourceManager的地址, 和ResourceManager建立连接(主要是TaskExecutorToResourceManagerConnection和EstablishedResourceManagerConnection)
runAsync(
() -> notifyOfNewResourceManagerLeader(
leaderAddress,
ResourceManagerId.fromUuidOrNull(leaderSessionID)));
}
@Override
public void handleError(Exception exception) {
onFatalError(exception);
}
}private RetryingRegistration<F, G, S> createNewRegistration() {
// 创建生成对应的注册连接;该处为TaskExecutorToResourceManagerConnection.ResourceManagerRegistration
RetryingRegistration<F, G, S> newRegistration = checkNotNull(generateRegistration());
CompletableFuture<Tuple2<G, S>> future = newRegistration.getFuture();
future.whenCompleteAsync(
(Tuple2<G, S> result, Throwable failure) -> {
if (failure != null) {
if (failure instanceof CancellationException) {
// we ignore cancellation exceptions because they originate from cancelling
// the RetryingRegistration
log.debug("Retrying registration towards {} was cancelled.", targetAddress);
} else {
// this future should only ever fail if there is a bug, not if the registration is declined
onRegistrationFailure(failure);
}
} else {
targetGateway = result.f0;
// 成功后异步回调执行connection连接确认及TM slot资源上报
// 其异步注册的监听器为ResourceManagerRegistrationListener
onRegistrationSuccess(result.f1);
}
}, executor);
return newRegistration;
}public void startRegistration() { // 向RM的注册
......
try {
// trigger resolution of the resource manager address to a callable gateway
final CompletableFuture<G> resourceManagerFuture;
if (FencedRpcGateway.class.isAssignableFrom(targetType)) {
resourceManagerFuture = (CompletableFuture<G>) rpcService.connect( // rpc连接
targetAddress,
fencingToken,
targetType.asSubclass(FencedRpcGateway.class));
} else {
resourceManagerFuture = rpcService.connect(targetAddress, targetType);
}
// upon success, start the registration attempts
CompletableFuture<Void> resourceManagerAcceptFuture = resourceManagerFuture.thenAcceptAsync(
(G result) -> {
log.info("Resolved {} address, beginning registration", targetName);
register(result, 1, initialRegistrationTimeout);
//注册主体 // 其会调用ResourceManagerRegistration#invokeRegistration()来进行实际的注册
},
rpcService.getExecutor());
// upon failure, retry, unless this is cancelled
...... // 注册失败会重试
}4、DispatcherRestEndpoint、WebMonitorEndpoint
web界面展示接口相关,其主要初始化web相关的服务及接口;主要包括jobmanager、taskmanager信息及日志监控、web job submit初始化、metric监控指标、checkpoint检查点、savepoint保存点等等web界面可查询到的指标;并且将服务以netty 其handler以及接口初始化log日志信息如下(部分):
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.cluster.ClusterConfigHandler@48f4713c under GET@/jobmanager/config.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.metrics.JobManagerMetricsHandler@4ba6ec50 under GET@/jobmanager/metrics.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.legacy.ConstantTextHandler@642413d4 under GET@/v1/jobmanager/stdout.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobIdsHandler@fb2e3fd under GET@/v1/jobs.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobSubmitHandler@43a09ce2 under POST@/jobs.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.metrics.AggregatingJobsMetricsHandler@3f183caa under GET@/v1/jobs/metrics.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobsOverviewHandler@7b66322e under GET@/v1/jobs/overview.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobDetailsHandler@63538bb4 under GET@/v1/jobs/:jobid.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobAccumulatorsHandler@5a50d9fc under GET@/v1/jobs/:jobid/accumulators.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.checkpoints.CheckpointingStatisticsHandler@106d77da under GET@/v1/jobs/:jobid/checkpoints.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobConfigHandler@767f6ee7 under GET@/v1/jobs/:jobid/config.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobExceptionsHandler@7b6c6e70 under GET@/jobs/:jobid/exceptions.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.metrics.JobMetricsHandler@3a894088 under GET@/jobs/:jobid/metrics.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobPlanHandler@370c1968 under GET@/jobs/:jobid/plan.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.savepoints.SavepointHandlers$SavepointStatusHandler@15eb0ae9 under GET@/jobs/:jobid/savepoints/:triggerid.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobVertexDetailsHandler@65e0b505 under GET@/jobs/:jobid/vertices/:vertexid.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobVertexAccumulatorsHandler@67de7a99 under GET@/jobs/:jobid/vertices/:vertexid/accumulators.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobVertexBackPressureHandler@795f5d51 under GET@/jobs/:jobid/vertices/:vertexid/backpressure.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.metrics.JobVertexMetricsHandler@34aeacd1 under GET@/jobs/:jobid/vertices/:vertexid/metrics.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.metrics.AggregatingSubtasksMetricsHandler@4098dd77 under GET@/jobs/:jobid/vertices/:vertexid/subtasks/metrics.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.SubtaskCurrentAttemptDetailsHandler@43aeb5e0 under GET@/jobs/:jobid/vertices/:vertexid/subtasks/:subtaskindex.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.SubtaskExecutionAttemptDetailsHandler@2274160 under GET@/jobs/:jobid/vertices/:vertexid/subtasks/:subtaskindex/attempts/:attempt.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.SubtaskExecutionAttemptAccumulatorsHandler@65383667 under GET@/jobs/:jobid/vertices/:vertexid/subtasks/:subtaskindex/attempts/:attempt/accumulators.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.metrics.SubtaskMetricsHandler@63cd2cd2 under GET@/jobs/:jobid/vertices/:vertexid/subtasks/:subtaskindex/metrics.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.SubtasksTimesHandler@557a84fe under GET@/jobs/:jobid/vertices/:vertexid/subtasktimes.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.JobVertexTaskManagersHandler@6deee370 under GET@/jobs/:jobid/vertices/:vertexid/taskmanagers.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.savepoints.SavepointDisposalHandlers$SavepointDisposalTriggerHandler@423c5404 under POST@/savepoint-disposal.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.metrics.AggregatingTaskManagersMetricsHandler@5a02bfe3 under GET@/taskmanagers/metrics.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.taskmanager.TaskManagerLogFileHandler@3c79088e under GET@/taskmanagers/:taskmanagerid/log.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.job.metrics.TaskManagerMetricsHandler@4a37191a under GET@/taskmanagers/:taskmanagerid/metrics.
DEBUG: org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Register handler org.apache.flink.runtime.rest.handler.taskmanager.TaskManagerStdoutFileHandler@5854a18 under GET@/taskmanagers/:taskmanagerid/stdout.5、StandaloneDispatcher
在 MiniCluster 模式下,其会创建一个StandaloneDispatcher,该类继承自Dispatcher;其是任务调度执行分发的基类,主要作用是提交任务到JobManager,持久化存储,异常恢复任务等等;其主要的组件为:
- RPC服务、blobServer、heartbeatServices等;
- archivedExecutionGraphStore(用于ExecutionGraph的存储)
- jobManagerRunnerFactory工厂类(该工厂类主要用于实例化JobManagerRunner,该类内部持有具体需要执行的jobGraph、jobMaster等组件)
在实例化JobManagerRunner过程中;其会生成对应的jobMaster;其jobmaster对应的作用是(核心主体):
- 工作图的调度执行和管理
- 资源管理(Leader、Gateway、心跳等)
- 任务管理
- 调度分配
- BackPressure控制
在构建完成之后;会调用其dispatcher.start()方法;启动并注册自己的回调函数,其当前的Dispatcher也会通过LeaderElectionService参与选举。
Dispatcher#start()
public void start() throws Exception {
super.start(); // 启动rpc服务
submittedJobGraphStore.start(this);
leaderElectionService.start(this); // 当前组件参与leader选举
registerDispatcherMetrics(jobManagerMetricGroup);
}6、提交JobGraph
在MiniCluster构建完成之后,其会通过MiniCluster#executeJobBlocking来提交JobGraph并等待运行完成,提交JobGraph和请求运行结果的逻辑如下,都是通过RPC调用来实现,其会先通过RPC调用向Dispatcher提交JobGraph,之后便异步等待任务执行结果:
MiniCluster#executeJobBlocking
public JobExecutionResult executeJobBlocking(JobGraph job) throws JobExecutionException, InterruptedException {
checkNotNull(job, "job is null");
final CompletableFuture<JobSubmissionResult> submissionFuture = submitJob(job); // 提交任务
final CompletableFuture<JobResult> jobResultFuture = submissionFuture.thenCompose(
(JobSubmissionResult ignored) -> requestJobResult(job.getJobID())); // 请求job任务状态
final JobResult jobResult;
try {
jobResult = jobResultFuture.get(); // 获取异步结果并返回
} catch (ExecutionException e) {
throw new JobExecutionException(job.getJobID(), "Could not retrieve JobResult.", ExceptionUtils.stripExecutionException(e));
}
try {
return jobResult.toJobExecutionResult(Thread.currentThread().getContextClassLoader());
} catch (IOException | ClassNotFoundException e) {
throw new JobExecutionException(job.getJobID(), e);
}
}其主要的submitJob执行流程如下(通过RPC调用dispatcherGateway.submitJob(jobGraph, rpcTimeout)向Dispatcher提交JobGraph):
public CompletableFuture<JobSubmissionResult> submitJob(JobGraph jobGraph) {
final DispatcherGateway dispatcherGateway;
try {
dispatcherGateway = getDispatcherGateway(); // 通过Dispatcher的gateway retriever获取DispatcherGateway
} catch (LeaderRetrievalException | InterruptedException e) {
ExceptionUtils.checkInterrupted(e);
return FutureUtils.completedExceptionally(e);
}
// we have to allow queued scheduling in Flip-6 mode because we need to request slots
// from the ResourceManager
jobGraph.setAllowQueuedScheduling(true);
final CompletableFuture<InetSocketAddress> blobServerAddressFuture = createBlobServerAddress(dispatcherGateway);
final CompletableFuture<Void> jarUploadFuture = uploadAndSetJobFiles(blobServerAddressFuture, jobGraph);
// 通过RPC调用向Dispatcher提交JobGraph
final CompletableFuture<Acknowledge> acknowledgeCompletableFuture = jarUploadFuture.thenCompose(
(Void ack) -> dispatcherGateway.submitJob(jobGraph, rpcTimeout));
return acknowledgeCompletableFuture.thenApply(
(Acknowledge ignored) -> new JobSubmissionResult(jobGraph.getJobID()));
}Dispatcher在接收到提交JobGraph的请求后,会将提交的JobGraph保存在SubmittedJobGraphStore中(用于故障恢复),并为提交的JobGraph启动JobManager:
- Dispatcher接手job之后,会实例化一个JobManagerRunner,然后用这个runner启动job;
- JobManagerRunner接下来把job交给了JobMaster去处理;
- JobMaster使用ExecutionGraph的方法启动了整个执行图;整个任务就启动起来了。
Dispatcher#createJobManagerRunner(jobGraph) // 创建JobManagerRunner(实例化JobMaster); 并启动该JobManagerRunner
private CompletableFuture<JobManagerRunner> createJobManagerRunner(JobGraph jobGraph) {
final RpcService rpcService = getRpcService();
final CompletableFuture<JobManagerRunner> jobManagerRunnerFuture = CompletableFuture.supplyAsync(
CheckedSupplier.unchecked(() ->
jobManagerRunnerFactory.createJobManagerRunner(
ResourceID.generate(),
jobGraph,
configuration,
rpcService,
highAvailabilityServices,
heartbeatServices,
blobServer,
jobManagerSharedServices,
new DefaultJobManagerJobMetricGroupFactory(jobManagerMetricGroup),
fatalErrorHandler)),
rpcService.getExecutor());
// 启动的JobManagerRunner会竞争leader,一旦被选举为leader,其就会调用verifyJobSchedulingStatusAndStartJobManager;
// 就会启动执行jobMaster.start(); 在jobMaster内部分别启动slotPool超时监控线程、建立和ResourceManager的ResourceManagerConnection连接;
// 一旦连接建立之后, JobMaster就可以通过RPC调用和ResourceManager进行通信了; 在此之后就进入了任务调度执行的流程
return jobManagerRunnerFuture.thenApply(FunctionUtils.uncheckedFunction(this::startJobManagerRunner));
}
JobManagerRunner#start()
public void start() throws Exception {
try {
leaderElectionService.start(this);
} catch (Exception e) {
log.error("Could not start the JobManager because the leader election service did not start.", e);
throw new Exception("Could not start the leader election service.", e);
}
}
JobMaster#startJobExecution#startJobMasterServices
private void startJobMasterServices() throws Exception {
// start the slot pool make sure the slot pool now accepts messages for this leader
slotPool.start(getFencingToken(), getAddress());
//TODO: Remove once the ZooKeeperLeaderRetrieval returns the stored address upon start
// try to reconnect to previously known leader
reconnectToResourceManager(new FlinkException("Starting JobMaster component."));
// job is ready to go, try to establish connection with resource manager
// - activate leader retrieval for the resource manager
// - on notification of the leader, the connection will be established and
// the slot pool will start requesting slots
resourceManagerLeaderRetriever.start(new ResourceManagerLeaderListener());
}Standalone Cluster模式的启动流程:
在windows或者linux环境下通过 /flink/bin/start-cluster.bat 或者 start-cluster.sh来启动对应的flink集群Standalone Cluster模式;
在启动脚本中可以看到主要的组件实例化入口类为:
# 简化shell启动脚本后,其组件实例化入口类主要为下:
case $DAEMON in
(taskexecutor) CLASS_TO_RUN=org.apache.flink.runtime.taskexecutor.TaskManagerRunner
(zookeeper) CLASS_TO_RUN=org.apache.flink.runtime.zookeeper.FlinkZooKeeperQuorumPeer
(historyserver) CLASS_TO_RUN=org.apache.flink.runtime.webmonitor.history.HistoryServer
(standalonesession) CLASS_TO_RUN=org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint
(standalonejob) CLASS_TO_RUN=org.apache.flink.container.entrypoint.StandaloneJobClusterEntryPoint
esac可以看到在Standalone模式下;Standalone Cluster有两种启动方式,即standalonesession模式和standalonejob方式,它们主要区别在于Dispatcher的实现方式不同。standalonesession模式的入口类是StandaloneSessionClusterEntrypoint,继承自SessionClusterEntrypoint;与此对应的是以standalonejob方式启动JobManager的入口类是StandaloneJobClusterEntryPoint,继承自JobClusterEntrypoint。它们都由公共父类ClusterEntrypoint派生而来,区别在于生成的DispatcherResourceManagerComponent不同。(此处主要讨论standalonesession)模式;
首先通过集群启动的入口类StandaloneSessionClusterEntrypoint#main()函数可以看到,首先会先解析flink当前java进程的启动命令,加载配置文件flink-conf.yaml并将其转化为flink环境内可识别的configuration信息,之后便调用flink集群base class去启动当前的集群环境:
// StandaloneSessionClusterEntrypoint#main()函数
public static void main(String[] args) {
// startup checks and logging (启动log输出当前配置环境java及启动的jvm参数等基本信息)
EnvironmentInformation.logEnvironmentInfo(LOG, StandaloneSessionClusterEntrypoint.class.getSimpleName(), args);
SignalHandler.register(LOG);
JvmShutdownSafeguard.installAsShutdownHook(LOG);
EntrypointClusterConfiguration entrypointClusterConfiguration = null;
final CommandLineParser<EntrypointClusterConfiguration> commandLineParser = new CommandLineParser<>(new EntrypointClusterConfigurationParserFactory());
try {
entrypointClusterConfiguration = commandLineParser.parse(args);
} catch (FlinkParseException e) {
LOG.error("Could not parse command line arguments {}.", args, e);
commandLineParser.printHelp(StandaloneSessionClusterEntrypoint.class.getSimpleName());
System.exit(1);
}
// 配置加载当前 flink-conf.yaml 中的配置设置信息
Configuration configuration = loadConfiguration(entrypointClusterConfiguration);
StandaloneSessionClusterEntrypoint entrypoint = new StandaloneSessionClusterEntrypoint(configuration);
// Standalone Cluster模式启动
ClusterEntrypoint.runClusterEntrypoint(entrypoint);
}在ClusterEntrypoint.runClusterEntrypoint(entrypoint)集群启动JobManager过程中;其主要的源代码如下:
private void runCluster(Configuration configuration) throws Exception {
synchronized (lock) {
// 初始化基础的服务类,主要包括创建commonRpcService(基础rpc服务提供基础的ip:port), haServices, blobServer, heartbeatServices, metricRegistry监控服务等等
// 这里生成的HighAvailabilityServices区别于MiniCluster模式; 由于Standalone模式下各组件不在同一个进程中, 因而需要从配置中加载配置:
// 1、如果采用基于Zookeeper的HA模式,则创建ZooKeeperHaServices,基于zookeeper获取leader通信地址
// 2、如果没有配置HA, 则创建StandaloneHaServices, 并从配置文件中获取各组件的RPC地址信息(resourceManagerRpcUrl、dispatcherRpcUrl、jobManagerRpcUrl)。
initializeServices(configuration);
// write host information into configuration
configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress());
configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
// 生成DispatcherResourceManagerComponentFactory, 由具体子类实现
final DispatcherResourceManagerComponentFactory<?> dispatcherResourceManagerComponentFactory = createDispatcherResourceManagerComponentFactory(configuration);
// 创建DispatcherResourceManagerComponent, 其内部持有并启动ResourceManager, Dispatcher
clusterComponent = dispatcherResourceManagerComponentFactory.create(
configuration,
commonRpcService,
haServices,
blobServer,
heartbeatServices,
metricRegistry,
archivedExecutionGraphStore,
new AkkaQueryServiceRetriever(
metricQueryServiceActorSystem,
Time.milliseconds(configuration.getLong(WebOptions.TIMEOUT))),
this);
clusterComponent.getShutDownFuture().whenComplete(...); // 执行完成, 关闭各项服务
}
}在生成具体的DispatcherResourceManagerComponentFactory类的过程中,其针对不同的Standalone模式交由其具体子类去实现;
- standalonesession模式的入口类StandaloneSessionClusterEntrypoint;其具体生成的工厂类委托给SessionDispatcherResourceManagerComponentFactory,该工厂类内部持有对应的负责创建相应组件的细化工厂类;其对应的组件实例化工厂类为:SessionDispatcherFactory-->StandaloneDispatcher;
StandaloneResourceManagerFactory-->StandaloneResourceManager;
SessionRestEndpointFactory-->DispatcherRestEndpoint; - standalonejob方式的入口类StandaloneJobClusterEntryPoint;其具体生成的工厂类委托给在JobDispatcherResourceManagerComponentFactory,该工厂类内部持有对应的负责创建相应组件的细化工厂类;其对应的组件实例化工厂类为:JobDispatcherFactory-->MiniDispatcher;
StandaloneResourceManagerFactory-->StandaloneResourceManager;
JobRestEndpointFactory-->MiniDispatcherRestEndpoint;
在standalonejob方式中;一个MiniDispatcher和一个JobGraph绑定,一旦绑定的JobGraph执行结束,则关闭MiniDispatcher,进而停止JobManager进程
其后续的具体组件实例化创建以及组件服务启动都在clusterComponent=dispatcherResourceManagerComponentFactory.create()中;主要创建以及启动的组件(主要是resourceManager、dispatcher、webMonitorEndpoint组件)如下,其各个组件具体启动方式、服务内部的启动流程以及作用和MiniCluster中的一致,这里不再赘述。
@Override
public DispatcherResourceManagerComponent<T> create(...) throws Exception {
......
LeaderRetrievalService dispatcherLeaderRetrievalService = null;
LeaderRetrievalService resourceManagerRetrievalService = null;
WebMonitorEndpoint<U> webMonitorEndpoint = null;
ResourceManager<?> resourceManager = null;
JobManagerMetricGroup jobManagerMetricGroup = null;
T dispatcher = null;
try {
dispatcherLeaderRetrievalService = highAvailabilityServices.getDispatcherLeaderRetriever();
resourceManagerRetrievalService = highAvailabilityServices.getResourceManagerLeaderRetriever();
final LeaderGatewayRetriever<DispatcherGateway> dispatcherGatewayRetriever = new RpcGatewayRetriever<>(
rpcService,
DispatcherGateway.class,
DispatcherId::fromUuid,
10,
Time.milliseconds(50L));
final LeaderGatewayRetriever<ResourceManagerGateway> resourceManagerGatewayRetriever = new RpcGatewayRetriever<>(
rpcService,
ResourceManagerGateway.class,
ResourceManagerId::fromUuid,
10,
Time.milliseconds(50L));
webMonitorEndpoint = restEndpointFactory.createRestEndpoint();
log.debug("Starting Dispatcher REST endpoint.");
webMonitorEndpoint.start();
jobManagerMetricGroup = MetricUtils.instantiateJobManagerMetricGroup(
metricRegistry,
rpcService.getAddress(),
ConfigurationUtils.getSystemResourceMetricsProbingInterval(configuration));
resourceManager = resourceManagerFactory.createResourceManager(
configuration,
ResourceID.generate(),
rpcService,
highAvailabilityServices,
heartbeatServices,
metricRegistry,
fatalErrorHandler,
new ClusterInformation(rpcService.getAddress(), blobServer.getPort()),
webMonitorEndpoint.getRestBaseUrl(),
jobManagerMetricGroup);
final HistoryServerArchivist historyServerArchivist = HistoryServerArchivist.createHistoryServerArchivist(configuration, webMonitorEndpoint);
dispatcher = dispatcherFactory.createDispatcher(
configuration,
rpcService,
highAvailabilityServices,
resourceManager.getSelfGateway(ResourceManagerGateway.class),
blobServer,
heartbeatServices,
jobManagerMetricGroup,
metricRegistry.getMetricQueryServicePath(),
archivedExecutionGraphStore,
fatalErrorHandler,
webMonitorEndpoint.getRestBaseUrl(),
historyServerArchivist);
log.debug("Starting ResourceManager.");
resourceManager.start();
resourceManagerRetrievalService.start(resourceManagerGatewayRetriever);
log.debug("Starting Dispatcher.");
dispatcher.start();
dispatcherLeaderRetrievalService.start(dispatcherGatewayRetriever);
return createDispatcherResourceManagerComponent(
dispatcher,
resourceManager,
dispatcherLeaderRetrievalService,
resourceManagerRetrievalService,
webMonitorEndpoint,
jobManagerMetricGroup);
} catch (Exception exception) {
// clean up all started components
......
}
}TaskManager的启动
TaskManager的启动入口在CLASS_TO_RUN=org.apache.flink.runtime.taskexecutor.TaskManagerRunner中,它的启动流程和MiniCluster模式下基本一致,从flink-conf.yaml文件中加载对应的config文件配置(jobmanager地址等等),启动对应的TaskExecutor,并向ResourceManager注册自己;其和MiniCluster模式下的区别在于:
- 运行在独立的进程中;
- HighAvailabilityServices的创建要依赖配置文件获取;
- TaskManagerRunner会创建TaskExecutor,TaskExecutor通过HighAvailabilityServices获取ResourceManager的通信地址,并和ResourceManager建立连接;
Yarn Cluster模式的启动流程:
Yarn Cluster模式的启动入口在FlinkYarnSessionCli中;首先根据命令行参数(--ship、jar、jobManagerMemory、container、slots等等)解析并创建对应的YarnConfiguration;之后便创建YarnClusterDescriptor(其内部持有YarnClient客户端、yarnConfiguration、JarPath等等),接着调用YarnClusterDescriptor#deploySessionCluster来触发Yarn Cluster集群的部署;其实际上会调用启动AbstractYarnClusterDescriptor#deployInternal方法,主要就是通过YarnClient向yarn集群提交AppMaster应用,启动对应的ApplicationMaster。
// AbstractYarnClusterDescriptor#deployInternal
protected ClusterClient<ApplicationId> deployInternal(
ClusterSpecification clusterSpecification,
String applicationName,
String yarnClusterEntrypoint,
@Nullable JobGraph jobGraph,
boolean detached) throws Exception {
// ------------------ Check if configuration is valid --------------------
validateClusterSpecification(clusterSpecification);
if (UserGroupInformation.isSecurityEnabled()) {......} // hasKerberos鉴权
isReadyForDeployment(clusterSpecification); // 配置及请求yarn最大资源检查
// ------------------ Check if the specified queue exists --------------------
checkYarnQueues(yarnClient); // yarn queue检查
// ------------------ Add dynamic properties to local flinkConfiguraton ------
Map<String, String> dynProperties = getDynamicProperties(dynamicPropertiesEncoded);
for (Map.Entry<String, String> dynProperty : dynProperties.entrySet()) {
flinkConfiguration.setString(dynProperty.getKey(), dynProperty.getValue());
}
// ------------------ Check if the YARN ClusterClient has the requested resources --------------
// Create application via yarnClient
final YarnClientApplication yarnApplication = yarnClient.createApplication(); // 创建申请Yarn AppMaster
final GetNewApplicationResponse appResponse = yarnApplication.getNewApplicationResponse();
......... // cluster资源检查
LOG.info("Cluster specification: {}", validClusterSpecification);
final ClusterEntrypoint.ExecutionMode executionMode = detached ? // 执行模式选择(是否长连接输出应用信息:提交后本地断开)
ClusterEntrypoint.ExecutionMode.DETACHED
: ClusterEntrypoint.ExecutionMode.NORMAL;
flinkConfiguration.setString(ClusterEntrypoint.EXECUTION_MODE, executionMode.toString());
// 启动Yarn AppMaster应用;在启动AppMaster过程中,主要是构建提交的应用上下文ApplicationSubmissionContext appContext = yarnApplication.getApplicationSubmissionContext();
// appContext里面定义了Yarn container启动的资源、jar、config等等信息;其中比较重要的是:
// ContainerLaunchContext amContainer = setupApplicationMasterContainer(); 里面设置了 启动Application Master进程的java cmd指令
// ContainerLaunchContext amContainer中指定了 启动的入口class类;该处分别指向YarnSessionClusterEntrypoint或者YarnJobClusterEntrypoint;
// 之后便调用yarnClient.submitApplication(appContext); 向Yarn提交该应用
ApplicationReport report = startAppMaster(
flinkConfiguration,
applicationName,
yarnClusterEntrypoint,
jobGraph,
yarnClient,
yarnApplication,
validClusterSpecification);
// Correctly initialize the Flink config
.........
// the Flink cluster is deployed in YARN. Represent cluster
return createYarnClusterClient(
this,
validClusterSpecification.getNumberTaskManagers(),
validClusterSpecification.getSlotsPerTaskManager(),
report,
flinkConfiguration,
true);
}在YarnCluster模式下;根据sessioncluster和jobcluster者两种启动的区别,提交到Yarn中ApplicationMatser的入口类分别为YarnSessionClusterEntrypoint和YarnJobClusterEntrypoint,其最终的父类都是继承自ClusterEntrypoint,最终集群启动过程都是依托给ClusterEntrypoint.runClusterEntrypoint(entrypoint)中;其启动过程与上述Standalone Cluster过程一致。主要的区别点在于Dispatcher分别为StandaloneDispatcher和MiniDispatcher。ResourceManager的具体实现类为YarnResourceManager。
和Standalone Cluster不同的是,Yarn Cluster模式下启动的Flink集群,其TaskManager是由YarnResourceManager根据JobMaster的请求动态向Yarn的ResourceManager进行申请的。在JobMaster向flink其启动的内部组件的ResourceManager申请资源时,如果当前没有足够的资源分配,则YarnResourceManager会向Yarn集群的ResourceManager申请新的container,并启动TaskManager。
/**
* The yarn implementation of the resource manager. Used when the system is started
* via the resource framework YARN.
*/
// 其内部主要持有的组件 以及 向yarn申请新container的方法
public class YarnResourceManager extends ResourceManager<YarnWorkerNode> implements AMRMClientAsync.CallbackHandler {
/** Default heartbeat interval between this resource manager and the YARN ResourceManager. */
private final int yarnHeartbeatIntervalMillis;
private final Configuration flinkConfig;
private final YarnConfiguration yarnConfig;
private final int numberOfTaskSlots;
private final int defaultTaskManagerMemoryMB;
private final int defaultCpus;
/** The heartbeat interval while the resource master is waiting for containers. */
private final int containerRequestHeartbeatIntervalMillis;
/** Client to communicate with the Resource Manager (YARN's master). */
private AMRMClientAsync<AMRMClient.ContainerRequest> resourceManagerClient; // Yarn ResourceManager Client
/** Client to communicate with the Node manager and launch TaskExecutor processes. */
private NMClient nodeManagerClient; //
/** The number of containers requested, but not yet granted. */
private int numPendingContainerRequests;
private final Map<ResourceProfile, Integer> resourcePriorities = new HashMap<>();
private final Collection<ResourceProfile> slotsPerWorker;
private final Resource resource;
......
}申请到对应的Container资源后,通过YarnRM的回调函数,构建TaskManager启动命令以及ContainerLaunchContext,以此来启动对应的TaskExecutor:
// YarnResourceManager
// 向Yarn申请container
private void requestYarnContainer() {
resourceManagerClient.addContainerRequest(getContainerRequest());
// make sure we transmit the request fast and receive fast news of granted allocations
resourceManagerClient.setHeartbeatInterval(containerRequestHeartbeatIntervalMillis);
numPendingContainerRequests++;
log.info("Requesting new TaskExecutor container with resources {}. Number pending requests {}.",
resource,
numPendingContainerRequests);
}
// 申请到container资源后,异步回调
@Override
public void onContainersAllocated(List<Container> containers) {
runAsync(() -> {
final Collection<AMRMClient.ContainerRequest> pendingRequests = getPendingRequests();
final Iterator<AMRMClient.ContainerRequest> pendingRequestsIterator = pendingRequests.iterator();
for (Container container : containers) {
log.info(
"Received new container: {} - Remaining pending container requests: {}",
container.getId(),
numPendingContainerRequests);
if (numPendingContainerRequests > 0) {
removeContainerRequest(pendingRequestsIterator.next());
final String containerIdStr = container.getId().toString();
final ResourceID resourceId = new ResourceID(containerIdStr);
workerNodeMap.put(resourceId, new YarnWorkerNode(container));
try {
// Context information used to start a TaskExecutor Java process
// 构建TaskManager启动的ContainerLaunchContext信息
ContainerLaunchContext taskExecutorLaunchContext = createTaskExecutorLaunchContext(
container.getResource(),
containerIdStr,
container.getNodeId().getHost());
// 远程提交执行 启动TaskManager
nodeManagerClient.startContainer(container, taskExecutorLaunchContext);
} catch (Throwable t) {
log.error("Could not start TaskManager in container {}.", container.getId(), t);
// release the failed container
workerNodeMap.remove(resourceId);
resourceManagerClient.releaseAssignedContainer(container.getId());
// and ask for a new one
requestYarnContainerIfRequired();
}
} else {
// return the excessive containers
log.info("Returning excess container {}.", container.getId());
resourceManagerClient.releaseAssignedContainer(container.getId());
}
}
// if we are waiting for no further containers, we can go to the
// regular heartbeat interval
if (numPendingContainerRequests <= 0) {
resourceManagerClient.setHeartbeatInterval(yarnHeartbeatIntervalMillis);
}
});
}
// 构建TaskManager启动的ContainerLaunchContext信息(并指定container启动的类为YarnTaskExecutorRunner)
private ContainerLaunchContext createTaskExecutorLaunchContext(Resource resource, String containerId, String host)
throws Exception {
// init the ContainerLaunchContext
final String currDir = env.get(ApplicationConstants.Environment.PWD.key());
final ContaineredTaskManagerParameters taskManagerParameters =
ContaineredTaskManagerParameters.create(flinkConfig, resource.getMemory(), numberOfTaskSlots);
log.debug("TaskExecutor {} will be started with container size {} MB, JVM heap size {} MB, " +
"JVM direct memory limit {} MB",
containerId,
taskManagerParameters.taskManagerTotalMemoryMB(),
taskManagerParameters.taskManagerHeapSizeMB(),
taskManagerParameters.taskManagerDirectMemoryLimitMB());
Configuration taskManagerConfig = BootstrapTools.cloneConfiguration(flinkConfig);
log.debug("TaskManager configuration: {}", taskManagerConfig);
// 构建TaskManager的启动container上下文并指定启动类为:YarnTaskExecutorRunner
// 构建TaskManager进程启动的java cmd指令 java ${jvmmem} ${javaOps} -Dxxx class xxx 1> xxx/taskmanager.out 2> xxx/taskmanager.err
ContainerLaunchContext taskExecutorLaunchContext = Utils.createTaskExecutorContext(
flinkConfig,
yarnConfig,
env,
taskManagerParameters,
taskManagerConfig,
currDir,
YarnTaskExecutorRunner.class, // 入口类
log);
// set a special environment variable to uniquely identify this container
taskExecutorLaunchContext.getEnvironment()
.put(ENV_FLINK_CONTAINER_ID, containerId);
taskExecutorLaunchContext.getEnvironment()
.put(ENV_FLINK_NODE_ID, host);
return taskExecutorLaunchContext;
}