文中所用图片如无声明来源网络和论文。
Paper: The Three-Dimensional Normal-Distributions Transform— an Efficient Representation for Registration,Surface Analysis, and Loop Detection
下载地址
这是Martin Magnusson的2009年博士论文
文章目录
写在前面
研究NDT算法开始由于我们在校园无人车项目中的车辆定位方案中使用了这种方法,此外autoware无人驾驶方案中核心定位算法也是NDT算法。作为一种常用的点云匹配算法,拿来欣赏学习实在是一种享受,那种透过数学推导看到算法背后的思想后,真的是佩服做出来这些算法的前辈们!这篇文章还没有写完,后续慢慢填上去,如有任何问题欢迎下方留言探讨。
Abstract
对原始采样点云进行应用NDT算法之后,可以将扫描到的表面使用一个光滑的函数,这个函数有可解析的一阶导数和二阶导数。这样的表示方法有一些比较好的特性可以利用,它使得可以利用标准优化方法,如:牛顿法,进行scan registration。这个算法将2d registration扩展到3d, 并进行了一些提升。
使用技术,克服了普通registration算法中的离散表示问题:
- multiresolution discretisation
- trilinear interpolation
相比于icp算法,ndt对于比较差的initial pose估计更加快速,精确,鲁棒。
更进一步,提出了kernel-based extension 3d NDT算法用于注册coloured data。
- original algorithm 对于每一个quantum of space使用one metric normal distribution
- colour-NDT使用三个components,每一个使用一种颜色。这种表示允许仅有少量geometric features的coloured scans可以被注册。当3d点和图像数据都可以获得,使用图像数据的lcoal visual freatures进行scan registration是可能的。然后基于local features的方法通常只是用获得的3d点中的一小部分用于注册。相反,colured-NDT使用所有获得的3d点。
这篇论文提出结合使用local visual features和colourNDT的方法,在存在强重复纹理或扫描之间的动态变化的情况下,对彩色3D点云进行稳健配准。
同样基于NDT,提出了一种使用3D激光扫描为移动机器人执行基于外观的回环检测的新方法。
使用3d方法的两个难题:
- 如何处理大量数据
- 如何有效获得3d旋转不变性
所提出的方法仅使用3D点云的外观来检测循环并且不需要pose信息,它利用NDT表面表示来创建基于局部表面方向(local surface orientation)和平滑度(smoothness)的特征直方图(features histogram)。
- 表面形状直方图将输入数据压缩两到三个数量级。由于高压缩率,可以有效地匹配直方图以比较两次扫描的外观。
- 通过align扫描到的主要表面取向,来实现旋转不变性。
Chapter 1 Introduction
使用NDT后,扫描的表面使用具有一阶和二阶解析导数的光滑连续函数来表示,这样的表示有几种优势。
当执行3D成像时,通常情况是在单次扫描中不能捕获整个感兴趣区域;是因为遮挡,因为它太大,或者因为有问题的对象本身就是碎片。因此,通常需要执行3D扫描配准,以便生成完整的模型。为了对齐分段扫描(解决拼图游戏,可以这么说),有必要找到每次扫描的正确position和orientation; 就是它的pose。
1.1 Contributions
- 3D-NDT surface representation
- 3D-NDT registration with extensions
通过使用多分辨率离散化技术和三线性插值,可以克服基本3D-NDT配准算法中存在的一些离散化问题 - Colour-NDT registration
- Appearance-based loop detection from 3D laser scans
- Boulder detection from 3D laser scans
Chapter2 Common concepts
2.1 rotation
NDT中使用欧拉角zyx来表示,在这种情况下使用欧拉角的基本原理是避免在数值优化方法中加入非线性约束。对于执行扫描配准时遇到的相对较小的角度,不太可能发生万向节锁定。因此,通过更容易的问题公式来评估欧拉角的潜在缺点。
2.2 registration
当两帧scans匹配上了,称为in registration。如何决定registration的ground truth的问题会在chapter6讨论。
局部的registration需要一个比较近的初始值,如果离得太远,则无法进行很好的匹配,这和global的registration不同。
scan registration的应用:
- pose tracking,机器人定位
- modelling(三维重建),比如矿井下的map
2.3 sampling
在许多情况下,尤其是在走廊和隧道中进行扫描时,扫描仪位置附近的点分布比远处更密集。如果以均匀随机的方式对点进行采样,则采样的子集将具有类似的不均匀分布。从扫描的远端的重要几何结构中取样会很少或没有点,会导致配准不好。
为了克服这个问题,通常使用某种形式的空间分布式采样,以确保样本密度在整个扫描体积上均匀。
在当前工作中完成此操作的方式是通过创建具有相同大小的单元格的网格结构并将扫描点放置在相应的单元格中。该采样网格的单元尺寸通常在0.1和0.2米之间。从随机单元格中抽取随机点,直到达到所需的点数。如果cell分布足够,这种策略将给出均匀的点分布。
2.4 slam
slam主要的step:
- registration,
- pose-covariance estimation,
- loop detection,
- relaxation.
registrater机器人的连续视图以跟踪机器人的pose(localization)并构建metric map(mapping)。对于每个视图(或从一组视图生成的submaps),将node插入到scene graphe中,其edge将当前submap连接到其neighbours。还需要估计相邻submaps之间的相对pose的covariance,并将其附加到edge of graph。 一旦机器人检测到它已返回到先前访问过的位置,就可以计算在遍历回环上累积的error。基于与每个edge相关联的covariance估计,通过执行relaxation of the graph,将地图重新形成为consistent state。
Chapter3 Range sensing
通常,较短的波长导致更高的距离分辨率(更准确的范围读数)和更少的镜面反射(从发光表面读取的读数更少),但由于吸收和散射(衰减)而导致更短的最大范围。 空气中的气体和颗粒吸收并散射能量,使得较少的光束返回到接收器,从而降低了测量的可靠性。
- radar
因为雷达使用相对较长的波长,所以它可以在很长的范围内使用,尽管与波长较短的传感器相比分辨率较差。 此外,雷达不易受到灰尘,雾,雨,雪,真空或光线条件变化的影响。 雷达的一个独特功能是它可以检测多个物体向下范围。 然而,它不会穿透钢铁或坚硬的岩石 - lidar
与雷达和声纳的光束相比,激光束可以高度聚焦,没有旁瓣。 这也是短波长的影响。
与雷达相比,激光传感器的主要缺点是在扫描多尘或有雾环境时对衰减和散射的敏感性,尽管红外激光在穿透烟雾和灰尘方面比可见光更好。
最近的激光雷达设备可以测量每个光束的多个回波,因此可以测量灰尘和超出它的表面。
可以使用三角测量或通过测量发射光束的飞行时间或其相移来测量到物体的距离;- Triangulation
- time of flight
- sonar
- steroeo vision
- Time-of-flight cameras
Chapter5 Related work on scan registration
点云匹配算法有很多种,下面的是一些经典算法
- ICP
- IDC
- PIC
- Point-based probabilistic registration
- NDT
- Gaussian fields
- Quadratic patches
- Likelihood-field matching
- CRF matching
- Branch-and-bound registration
- Registration using local geometric features
Chapter6 The normal-distributions transform
6.1 NDT for representing surfaces
但是,使用点云来表示曲面有许多限制。例如,点云不包含有关表面特征的明确信息,例如方向,平滑度或孔。根据传感器配置,点云也可能效率低下,需要不必要的大量存储。 为了获得远离传感器位置的足够的sample resolution,通常需要以从传感器附近的表面产生大量冗余数据的方式配置传感器。
NDT是一种method for representing a surface。
它首先由Biber和Straßer于2003年7提出,作为2D扫描配准的方法。 Biber和Straßer后来在与Sven Fleck 8的联合论文中详细阐述了该方法,同样在扫描配准和映射的背景下。
NDT的这种transform的核心思想是将点云映射到平滑表面来表示,使用一组局部概率密度函数(PDF)来描述,每个PDF描述表面的一部分的形状。
该算法的第一步是将扫描所占用的空间细分为单元网格(2D情况下的正方形或3D中的立方体),基于cell内的点的分布计算每个cell的PDF。
每个cell中的PDF可以被解释为cell内表面点 x ⃗ \vec{x} x的generative process(生成过程)。 换句话说,假设可以通过对该cell内点的分布的刻画来生成 x ⃗ \vec{x} x的位置。
假设参考扫描表面点 surface point的位置是由D-dimensional normal random process(D维正态随机过程)产生的,则测量得到 x ⃗ \vec{x} x的概率是
p
(
x
⃗
)
=
1
(
2
π
)
D
/
2
∣
Σ
∣
exp
(
−
(
x
⃗
−
μ
⃗
)
T
Σ
−
1
(
x
⃗
−
μ
⃗
)
2
)
p(\vec{x})=\frac{1}{(2 \pi)^{D / 2} \sqrt{|\mathbf{\Sigma}|}} \exp \left(-\frac{(\vec{x}-\vec{\mu})^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}(\vec{x}-\vec{\mu})}{2}\right)
p(x)=(2π)D/2∣Σ∣1exp(−2(x−μ)TΣ−1(x−μ))
其中
(
(
2
π
)
D
/
2
∣
Σ
∣
)
−
1
\left((2 \pi)^{D / 2} \sqrt{|\boldsymbol{\Sigma}|}\right)^{-1}
((2π)D/2∣Σ∣)−1可以用一个常数
c
0
c_0
c0来表示。均值和方差使用下面的公式来计算
μ
⃗
=
1
m
∑
k
=
1
m
y
⃗
k
Σ
=
1
m
−
1
∑
k
=
1
m
(
y
⃗
k
−
μ
⃗
)
(
y
⃗
k
−
μ
⃗
)
T
\begin{aligned} \vec{\mu} &=\frac{1}{m} \sum_{k=1}^{m} \vec{y}_{k} \\ \boldsymbol{\Sigma} &=\frac{1}{m-1} \sum_{k=1}^{m}\left(\vec{y}_{k}-\vec{\mu}\right)\left(\vec{y}_{k}-\vec{\mu}\right)^{\mathrm{T}} \end{aligned}
μΣ=m1k=1∑myk=m−11k=1∑m(yk−μ)(yk−μ)T
其中
y
⃗
k
=
1
,
…
,
m
\vec{y}_{k=1, \dots, m}
yk=1,…,m是cell中point的位置。
正态分布给出了点云的分段平滑表示,具有连续导数。每个PDF都可以看作是局部表面的近似值,描述了表面的位置及其方向和平滑度。 2D激光扫描及其相应的正态分布如下图所示。 下下图显示了矿井隧道扫描的3D正态分布。
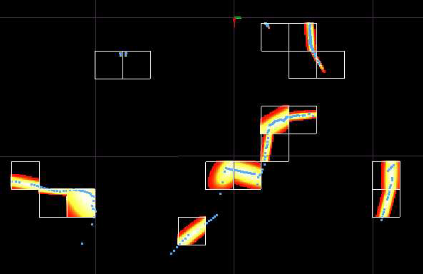
来自矿井隧道的2D激光扫描(显示为点)和描述表面形状的PDF。 在这种情况下,每个cell是边长为2米的正方形。 更亮的区域代表更高的概率。 仅针对超过五个点的cell计算PDF。

从上方看到的隧道剖面的3D-NDT表面表示。 更明亮,更密集的部分代表更高的概率。 cell的边长为1米。
由于目前的工作主要集中在正态分布上,让我们更仔细地研究单变量和多变量正态分布的特征。在一维情况下,正态分布的随机变量
x
x
x具有一定的期望值
μ
\mu
μ,并且关于该值的不确定性用方差
σ
\sigma
σ表示,相当于维度
D
=
1
D=1
D=1。
p
(
x
)
=
1
σ
2
π
exp
(
−
(
x
−
μ
)
2
2
σ
2
)
p(x)=\frac{1}{\sigma \sqrt{2 \pi}} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right)
p(x)=σ2π1exp(−2σ2(x−μ)2)
这是多变量的正态分布表示,
p
(
x
⃗
)
=
1
(
2
π
)
D
/
2
∣
Σ
∣
exp
(
−
(
x
⃗
−
μ
⃗
)
T
Σ
−
1
(
x
⃗
−
μ
⃗
)
2
)
p(\vec{x})=\frac{1}{(2 \pi)^{D / 2} \sqrt{|\mathbf{\Sigma}|}} \exp \left(-\frac{(\vec{x}-\vec{\mu})^{\mathrm{T}} \boldsymbol{\Sigma}^{-1}(\vec{x}-\vec{\mu})}{2}\right)
p(x)=(2π)D/2∣Σ∣1exp(−2(x−μ)TΣ−1(x−μ))
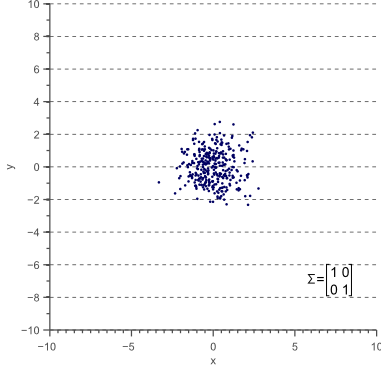
协方差矩阵的对角元素表示每个变量的方差variance,而非对角元素表示对应两个变量的协方差covariance。
下图显示了三种不同维度的正态分布情况,

在2D和3D情况下,可以从协方差矩阵的特征向量和特征值来评估表面取向orientation和平滑度smoothness。 特征向量描述了分布的主要组成部分; 也就是说,一组正交矢量对应于变量的协方差的主导方向。
根据方差的性质,2D正态分布可以是点状(如果方差相似)或线形(如果一个比另一个大得多),或者介于两者之间的任何东西。
点状分布如下图类似,
线状分布如下图类似,
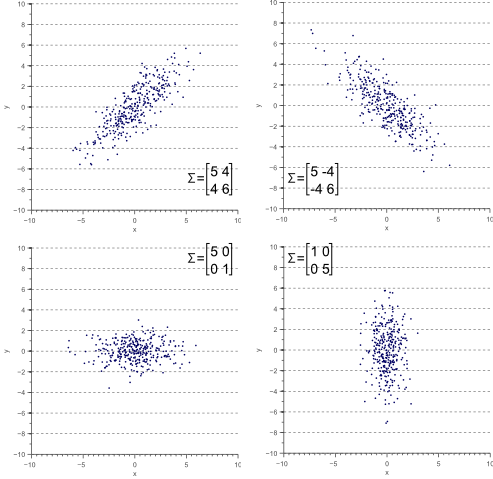
在3D情况下,如下图所示,正态分布可以描述一个点或球体(如果方差的幅度在所有方向上相似),一条线(如果一个方向上的方差远大于另外两个方向) 或平面(如果一个方向的方差远小于另外两个方向)。

不同形状的3D正态分布,取决于 Σ \mathbf{\Sigma} Σ的特征值之间的关系。箭头方向是分布的特征向量方向,长度由特征向量对应的特征值决定。
总结: 通过上面的内容解释了
- 如何使用PDF刻画一个cell内点的分布情况
- 点的分布在不同维度(一维二维三维)下,协方差矩阵的物理含义
6.2 NDT scan registration
6.2.1 优化目标函数构建
使用NDT进行扫描配准时,目标是找到当前帧的pose,使得可以最大化当前帧位于参考帧上的可能性,也就是说需要估计一个当前帧相对参考帧的
R
,
t
R,t
R,t,这里使用
p
⃗
\vec{p}
p来表示这个变换。
current scan point cloud 表示如下,
X
=
{
x
⃗
1
,
…
,
x
⃗
n
}
\mathcal{X}=\left\{\vec{x}_{1}, \ldots, \vec{x}_{n}\right\}
X={x1,…,xn}
假设有一个空间变换函数,
T
(
p
⃗
,
x
⃗
)
T(\vec{p}, \vec{x})
T(p,x)将空间中的点
x
⃗
\vec x
x通过
p
⃗
\vec p
p变换到另外一个位置。
给定扫描点的一些PDF,
p
(
x
⃗
)
p(\vec x)
p(x)(多变量的正态分布表示),最佳变换
p
⃗
\vec p
p应该是最大化下面似然函数时候的
p
⃗
\vec p
p
Ψ
=
∏
k
=
1
n
p
(
T
(
p
⃗
,
x
⃗
k
)
)
\Psi=\prod_{k=1}^{n} p\left(T\left(\vec{p}, \vec{x}_{k}\right)\right)
Ψ=∏k=1np(T(p,xk))
等价于最小化下面的式子,
−
log
Ψ
=
−
∑
k
=
1
n
log
(
p
(
T
(
p
⃗
,
x
⃗
k
)
)
)
-\log \Psi=-\sum_{k=1}^{n} \log \left(p\left(T\left(\vec{p}, \vec{x}_{k}\right)\right)\right)
−logΨ=−∑k=1nlog(p(T(p,xk)))
这里解释一下为什么是最大化这个似然函数?
- T ( p ⃗ , x ⃗ ) T(\vec{p}, \vec{x}) T(p,x)是经过source pointcloud,记为 p s o u r c e p_{source} psource经 p ⃗ \vec p p变换到target pointcloud后的点,记为 p t a r g e t p_{target} ptarget
- p ( x ) p(x) p(x)表示的是描述 p t a r g e t p_{target} ptarget中一个点在所在cell中的PDF
- 那么 p ( T ( p ⃗ , x ⃗ k ) ) p(T(\vec{p}, \vec{x}_{k})) p(T(p,xk))则表示 p s o u r c e p_{source} psource经过经 p ⃗ \vec p p变换到 p t a r g e t p_{target} ptarget坐标系下后在target pointcloud分布下的PDF
- 我们的变换 p ⃗ \vec p p越接近真实值,那么 p ( T ( p ⃗ , x ⃗ k ) ) p(T(\vec{p}, \vec{x}_{k})) p(T(p,xk))就越贴近 p t a r g e t p_{target} ptarget中点的分布,如果所有的点都一一对应上了,相当于所有点的变换这件事情同时发生,所以用连乘机的形式表示,这其实就是最大似然函数的直观意义
举一个二维的例子如下图,
6.2.2 对目标函数进行数学形式的简化
PDF不一定限于正态分布。 任何可以在局部捕获表面点结构并且对异常值稳健的PDF都是合适的。 正态分布的负对数似然增长在远离均值的点处无界。 因此,扫描数据中的异常值可能对结果产生很大影响。 在这项工作中(如Biber,Fleck和Straßer8的论文),使用了正态分布和均匀分布的混合,我称之为混合分布。
p ‾ ( x ⃗ ) = c 1 exp ( − ( x ⃗ − μ ⃗ ) T Σ − 1 ( x ⃗ − μ ⃗ ) 2 ) + c 2 p o \overline{p}(\vec{x})=c_{1} \exp \left(-\frac{(\vec{x}-\vec{\mu})^{\mathrm{T}} \mathbf{\Sigma}^{-1}(\vec{x}-\vec{\mu})}{2}\right)+c_{2} p_{o} p(x)=c1exp(−2(x−μ)TΣ−1(x−μ))+c2po
- p 0 p_0 p0 是异常值的预期比率。 使用此函数,可以限制异常值的影响,如下图所示。
- 常数c1和c2可以通过求
p
‾
(
x
⃗
)
\overline p(\vec x)
p(x)的概率质量得到,它equals one
within the space spanned by a cell。
(什么鬼?)详细的解释参考论文【A Probabilistic Framework for Robust andAccurate Matching of Point Clouds】总之在数学上可以用来近似处理。
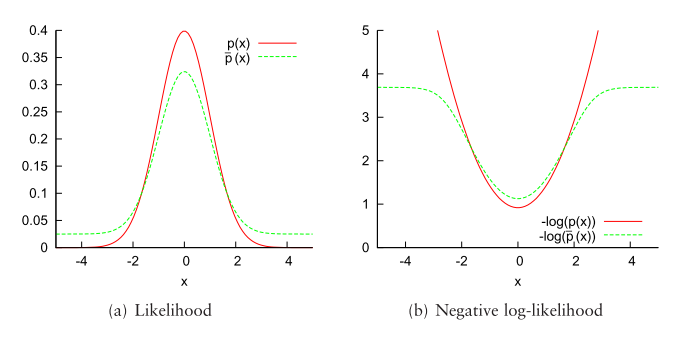
上图是比较正态分布
p
(
x
⃗
)
p(\vec x)
p(x)和混合模型
p
‾
(
x
⃗
)
\overline p(\vec x)
p(x)。
负对数似然是进行NDT registration时的目标函数,其导数表征了一次特定测量的偏差。(不太理解)
p
(
x
)
p(x)
p(x)对于非常大的
x
x
x的,the influence grows without bounds,但是
p
‾
(
x
⃗
)
\overline p(\vec x)
p(x)却是有界限的。
回顾一下我们的目标函数,
− log Ψ = − ∑ k = 1 n log ( p ( T ( p ⃗ , x ⃗ k ) ) ) -\log \Psi=-\sum_{k=1}^{n} \log \left(p\left(T\left(\vec{p}, \vec{x}_{k}\right)\right)\right) −logΨ=−∑k=1nlog(p(T(p,xk)))
我们要处理的目标函数中的每一个子项 − log ( p ( T ( p ⃗ , x ⃗ k ) ) ) -\log(p(T(\vec p, \vec x_k))) −log(p(T(p,xk)))具有下列式子的形式(使用前面说的混合模型 p ‾ \overline p p来描述分布),
− log ( c 1 exp ( − ( ( x ⃗ − μ ⃗ ) T Σ − 1 ( x ⃗ − μ ⃗ ) ) / 2 ) + c 2 ) -\log \left(c_{1} \exp \left(-\left((\vec{x}-\vec{\mu})^{\mathrm{T}} \mathbf{\Sigma}^{-1}(\vec{x}-\vec{\mu})\right) / 2\right)+c_{2}\right) −log(c1exp(−((x−μ)TΣ−1(x−μ))/2)+c2)
遗憾是的这个形式没有simplest的一阶导数和二阶导数,像上面的图中展示的那样,我们可以用一个高斯函数来近似负对数函数,也就是可以用
p ~ ( x ) = d 1 exp ( − d 2 x 2 / ( 2 σ 2 ) ) + d 3 \tilde{p}(x)=d_{1} \exp \left(-d_{2} x^{2} /\left(2 \sigma^{2}\right)\right)+d_{3} p~(x)=d1exp(−d2x2/(2σ2))+d3
来近似
p ‾ ( x ) = − log ( c 1 exp ( − x 2 / ( 2 σ 2 ) ) + c 2 ) \overline{p}(x)=-\log \left(c_{1} \exp \left(-x^{2} /\left(2 \sigma^{2}\right)\right)+c_{2}\right) p(x)=−log(c1exp(−x2/(2σ2))+c2),
通过拟合参数
d
1
,
d
2
,
d
3
d_1,d_2,d_3
d1,d2,d3使得
p
~
(
x
)
\tilde{p}(x)
p~(x)近似
p
‾
(
x
)
\overline{p}(x)
p(x),for
x
=
0
,
x
=
σ
,
x
=
∞
x=0, x=\sigma, x=\infty
x=0,x=σ,x=∞, 解方程求得
d
3
=
−
log
(
c
2
)
d
1
=
−
log
(
c
1
+
c
2
)
−
d
3
d
2
=
−
2
log
(
(
−
log
(
c
1
exp
(
−
1
/
2
)
+
c
2
)
−
d
3
)
/
d
1
)
\begin{aligned} d_{3} &=-\log \left(c_{2}\right) \\ d_{1} &=-\log \left(c_{1}+c_{2}\right)-d_{3} \\ d_{2} &=-2 \log \left(\left(-\log \left(c_{1} \exp (-1 / 2)+c_{2}\right)-d_{3}\right) / d_{1}\right) \end{aligned}
d3d1d2=−log(c2)=−log(c1+c2)−d3=−2log((−log(c1exp(−1/2)+c2)−d3)/d1)
使用这种高斯近似,则当前扫描中的一个点对NDT的影响可以使用下面的评分函数描述,
p
~
(
x
⃗
k
)
=
−
d
1
exp
(
−
d
2
2
(
x
⃗
k
−
μ
⃗
k
)
T
Σ
k
−
1
(
x
⃗
k
−
μ
⃗
k
)
)
\tilde{p}\left(\vec{x}_{k}\right)=-d_{1} \exp \left(-\frac{d_{2}}{2}\left(\vec{x}_{k}-\vec{\mu}_{k}\right)^{\mathrm{T}} \Sigma_{k}^{-1}\left(\vec{x}_{k}-\vec{\mu}_{k}\right)\right)
p~(xk)=−d1exp(−2d2(xk−μk)TΣk−1(xk−μk))(由于
d
3
d_3
d3是一个常量,所以在进行优化的目标函数中可以舍去)
这种形式具有simplest的一阶导数和二阶导数,但在优化中使用时仍具有相同的一般属性。
优化的目标函数变成下面的形式
s
(
p
⃗
)
=
−
∑
k
=
1
n
p
~
(
T
(
p
⃗
,
x
⃗
k
)
)
s(\vec{p})=-\sum_{k=1}^{n} \tilde{p}\left(T\left(\vec{p}, \vec{x}_{k}\right)\right)
s(p)=−∑k=1np~(T(p,xk))
6.2.3 协方差矩阵的逆 Σ − 1 \mathbf{\Sigma}^{-1} Σ−1求解
似然函数hu需要协方差矩阵的逆,
Σ
−
1
\mathbf{\Sigma}^{-1}
Σ−1。如果cell中的点完全共面或共线,则协方差矩阵是奇异的就无法求逆转。 在3D情况下,从三点或更少点计算的协方差矩阵将始终是奇异的。因此,仅为包含五个以上点的cell计算PDF。 此外,作为对数值问题的预防措施,只要发现
Σ
\mathbf{\Sigma}
Σ is slightly inflated whenever it is found to be nearly singular。 如果
Σ
\mathbf{\Sigma}
Σ的最大特征值
λ
3
\lambda_3
λ3大于
λ
1
\lambda_1
λ1或
λ
2
\lambda_2
λ2的100倍,则较小的特征值
λ
j
\lambda_j
λj被替换为
λ
j
=
λ
3
/
100
\lambda_j=\lambda_3/ 100
λj=λ3/100。
Λ
′
=
[
λ
1
′
0
0
0
λ
2
′
0
0
0
λ
3
]
\Lambda^{\prime}=\left[ \begin{array}{ccc}{\lambda_{1}^{\prime}} & {0} & {0} \\ {0} & {\lambda_{2}^{\prime}} & {0} \\ {0} & {0} & {\lambda_{3}}\end{array}\right]
Λ′=⎣⎡λ1′000λ2′000λ3⎦⎤
使用 Σ ′ = V Λ ′ V \boldsymbol{\Sigma}^{\prime}=\mathbf{V} \boldsymbol{\Lambda}^{\prime} \mathbf{V} Σ′=VΛ′V来代替 Σ \mathbf{\Sigma} Σ, V \mathbf{V} V中包含的是 Σ \mathbf{\Sigma} Σ的特征向量。
6.2.4 对目标函数进行优化求解
回顾一下目标函数为,
s
(
p
⃗
)
=
−
∑
k
=
1
n
p
~
(
T
(
p
⃗
,
x
⃗
k
)
)
s(\vec{p})=-\sum_{k=1}^{n} \tilde{p}\left(T\left(\vec{p}, \vec{x}_{k}\right)\right)
s(p)=−∑k=1np~(T(p,xk))
其中,
p
~
(
x
⃗
k
)
=
−
d
1
exp
(
−
d
2
2
(
x
⃗
k
−
μ
⃗
k
)
T
Σ
k
−
1
(
x
⃗
k
−
μ
⃗
k
)
)
\tilde{p}\left(\vec{x}_{k}\right)=-d_{1} \exp \left(-\frac{d_{2}}{2}\left(\vec{x}_{k}-\vec{\mu}_{k}\right)^{\mathrm{T}} \Sigma_{k}^{-1}\left(\vec{x}_{k}-\vec{\mu}_{k}\right)\right)
p~(xk)=−d1exp(−2d2(xk−μk)TΣk−1(xk−μk))
使用Newton法进行求解优化 s ( p ⃗ ) s(\vec{p}) s(p),核心是求解下面的式子 H Δ p ⃗ = − g ⃗ \mathbf{H} \Delta \vec{p}=-\vec{g} HΔp=−g,其中,
- H H H是 s ( p ⃗ ) s(\vec{p}) s(p)的hessian matrix
- g ⃗ \vec{g} g是 s ( p ⃗ ) s(\vec{p}) s(p)的gradient vector,或者叫做 s ( p ⃗ ) s(\vec{p}) s(p)的雅克比矩阵的转置 J T J^T JT
定义
x
⃗
k
′
≡
T
(
p
⃗
,
x
⃗
k
)
−
μ
⃗
k
\vec{x}_{k}^{\prime} \equiv T\left(\vec{p}, \vec{x}_{k}\right)-\vec{\mu}_{k}
xk′≡T(p,xk)−μk,换句话说,$\vec{x}{k}^{\prime}
是
点
是点
是点\vec{x}{k} $变换到reference cell后与reference cell的center的差值。
将目标函数写成,
s
(
p
⃗
)
=
∑
k
=
1
n
d
1
exp
(
−
d
2
2
(
x
⃗
k
′
)
T
Σ
k
−
1
x
⃗
k
′
)
s(\vec{p})=\sum_{k=1}^{n} d_{1} \exp (-\frac{d_{2}}{2}(\vec{x}_{k}^{\prime})^{\mathrm{T}} \Sigma_{k}^{-1}\vec{x}_{k}^{\prime})
s(p)=∑k=1nd1exp(−2d2(xk′)TΣk−1xk′)
The entries
g
i
g_i
gi of the gradient vector
g
⃗
\vec g
g can be written,
g
i
=
δ
s
δ
p
i
=
∑
k
=
1
n
d
1
d
2
x
⃗
k
′
T
Σ
k
−
1
δ
x
⃗
k
′
δ
p
i
exp
(
−
d
2
2
x
⃗
k
′
T
Σ
k
−
1
x
⃗
k
′
)
g_{i}=\frac{\delta s}{\delta p_{i}}=\sum_{k=1}^{n} d_{1} d_{2} \vec{x}_{k}^{\prime \mathrm{T}} \boldsymbol{\Sigma}_{k}^{-1} \frac{\delta \vec{x}_{k}^{\prime}}{\delta p_{i}} \exp \left(\frac{-d_{2}}{2} \vec{x}_{k}^{\prime \mathrm{T}} \mathbf{\Sigma}_{k}^{-1} \vec{x}_{k}^{\prime}\right)
gi=δpiδs=∑k=1nd1d2xk′TΣk−1δpiδxk′exp(2−d2xk′TΣk−1xk′)
其中 p i p_i pi是 p p p的第 i i i的量,比如有三维(6个)和二维(3个)两种情况。
The entries
H
i
j
H_{ij}
Hij of the Hessian matrix
H
H
H are
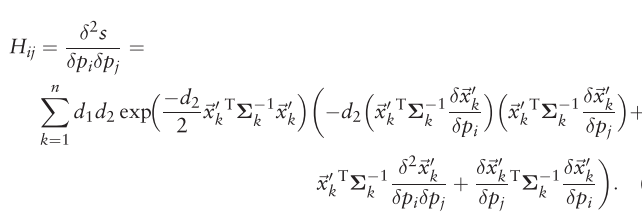
6.2.5 算法流程如下

6.2.5.1 2D NDT公式细节
优化变量为, p ⃗ = [ t x , t y , ϕ ] ⊤ \vec{p}=\left[t_{x}, t_{y}, \phi\right]^{\top} p=[tx,ty,ϕ]⊤
T 2 ( p ⃗ , x ⃗ ) = [ cos ϕ − sin ϕ sin ϕ cos ϕ ] x ⃗ + [ t x t y ] T_{2}(\vec{p}, \vec{x})=\left[ \begin{array}{cc}{\cos \phi} & {-\sin \phi} \\ {\sin \phi} & {\cos \phi}\end{array}\right] \vec{x}+\left[ \begin{array}{c}{t_{x}} \\ {t_{y}}\end{array}\right] T2(p,x)=[cosϕsinϕ−sinϕcosϕ]x+[txty]
δ x ⃗ ′ / δ p i = J 2 = [ 1 0 − x 1 sin ϕ − x 2 cos ϕ 0 1 x 1 cos ϕ − x 2 sin ϕ ] \delta \vec{x}^{\prime} / \delta p_{i}=\mathrm{J}_{2}=\left[ \begin{array}{ccc}{1} & {0} & {-x_{1} \sin \phi-x_{2} \cos \phi} \\ {0} & {1} & {x_{1} \cos \phi-x_{2} \sin \phi}\end{array}\right] δx′/δpi=J2=[1001−x1sinϕ−x2cosϕx1cosϕ−x2sinϕ]
δ 2 x ⃗ ′ δ p i δ p j = { [ − x 1 cos ϕ + x 2 sin ϕ − x 1 sin ϕ − x 2 cos ϕ ] if i = j = 3 [ 0 0 ] otherwise \frac{\delta^{2} \vec{x}^{\prime}}{\delta p_{i} \delta p_{j}}=\left\{\begin{array}{ll}{\left[ \begin{array}{cc}{-x_{1} \cos \phi+x_{2} \sin \phi} \\ {-x_{1} \sin \phi-x_{2} \cos \phi}\end{array}\right]} & {\text { if } i=j=3} \\ {\left[ \begin{array}{c}{0} \\ {0}\end{array}\right]} & {\text { otherwise }}\end{array}\right. δpiδpjδ2x′=⎩⎪⎪⎨⎪⎪⎧[−x1cosϕ+x2sinϕ−x1sinϕ−x2cosϕ][00] if i=j=3 otherwise
6.2.5.2 3D NDT公式细节
优化变量为, p ⃗ 6 = [ t x , t y , t z , ϕ x , ϕ y , ϕ z ] T \vec{p}_{6}=\left[t_{x}, t_{y}, t_{z}, \phi_{x}, \phi_{y}, \phi_{z}\right]^{\mathrm{T}} p6=[tx,ty,tz,ϕx,ϕy,ϕz]T
T E ( p ⃗ 6 , x ⃗ ) = R x R y R z x ⃗ + t ⃗ = [ c y c z − c y s z s y c x s z + s x s y c z c x c z − s x s y s z − s x c y s x s z − c x s y c z c x s y s z + s x c z c x c y ] x ⃗ + [ t x t y t z ] T_{E}\left(\vec{p}_{6}, \vec{x}\right)=\mathbf{R}_{x} \mathbf{R}_{y} \mathbf{R}_{z} \vec{x}+\vec{t}=\left[ \begin{array}{ccc}{c_{y} c_{z}} & {-c_{y} s_{z}} & {s_{y}} \\ {c_{x} s_{z}+s_{x} s_{y} c_{z}} & {c_{x} c_{z}-s_{x} s_{y} s_{z}} & {-s_{x} c_{y}} \\ {s_{x} s_{z}-c_{x} s_{y} c_{z}} & {c_{x} s_{y} s_{z}+s_{x} c_{z}} & {c_{x} c_{y}}\end{array}\right] \vec{x}+\left[ \begin{array}{c}{t_{x}} \\ {t_{y}} \\ {t_{z}}\end{array}\right] TE(p6,x)=RxRyRzx+t=⎣⎡cyczcxsz+sxsyczsxsz−cxsycz−cyszcxcz−sxsyszcxsysz+sxczsy−sxcycxcy⎦⎤x+⎣⎡txtytz⎦⎤
中间量一阶导数,
(
δ
/
δ
p
i
)
T
E
(
p
⃗
6
,
x
⃗
)
=
J
E
=
[
1
0
0
0
c
f
0
1
0
a
d
g
0
0
1
b
e
h
]
\left(\delta / \delta p_{i}\right) T_{E}\left(\vec{p}_{6}, \vec{x}\right)= \mathrm{J}_{E}=\left[ \begin{array}{llllll}{1} & {0} & {0} & {0} & {c} & {f} \\ {0} & {1} & {0} & {a} & {d} & {g} \\ {0} & {0} & {1} & {b} & {e} & {h}\end{array}\right]
(δ/δpi)TE(p6,x)=JE=⎣⎡1000100010abcdefgh⎦⎤
其中,
a
=
x
1
(
−
s
x
s
z
+
c
x
s
y
c
z
)
+
x
2
(
−
s
x
c
z
−
c
x
s
y
s
z
)
+
x
3
(
−
c
x
c
y
)
b
=
x
1
(
c
x
s
z
+
s
x
s
y
c
z
)
+
x
2
(
−
s
x
s
y
s
z
+
c
x
c
z
)
+
x
3
(
−
s
x
c
y
)
c
=
x
1
(
−
s
y
c
z
)
+
x
2
(
s
y
s
z
)
+
x
3
(
c
y
)
\begin{aligned} a &=x_{1}\left(-s_{x} s_{z}+c_{x} s_{y} c_{z}\right)+x_{2}\left(-s_{x} c_{z}-c_{x} s_{y} s_{z}\right)+x_{3}\left(-c_{x} c_{y}\right) \\ b &=x_{1}\left(c_{x} s_{z}+s_{x} s_{y} c_{z}\right)+x_{2}\left(-s_{x} s_{y} s_{z}+c_{x} c_{z}\right)+x_{3}\left(-s_{x} c_{y}\right) \\ c &=x_{1}\left(-s_{y} c_{z}\right)+x_{2}\left(s_{y} s_{z}\right)+x_{3}\left(c_{y}\right) \end{aligned}
abc=x1(−sxsz+cxsycz)+x2(−sxcz−cxsysz)+x3(−cxcy)=x1(cxsz+sxsycz)+x2(−sxsysz+cxcz)+x3(−sxcy)=x1(−sycz)+x2(sysz)+x3(cy)
d
=
x
1
(
s
x
c
y
c
z
)
+
x
2
(
−
s
x
c
y
s
z
)
+
x
3
(
s
x
s
y
)
e
=
x
1
(
−
c
x
c
y
c
z
)
+
x
2
(
c
x
c
y
s
z
)
+
x
3
(
−
c
x
s
y
)
f
=
x
1
(
−
c
y
s
z
)
+
x
2
(
−
c
y
c
z
)
g
=
x
1
(
c
x
c
z
−
s
x
s
y
s
z
)
+
x
2
(
−
c
x
s
z
−
s
x
s
y
c
z
)
h
=
x
1
(
s
x
c
z
+
c
x
s
y
s
z
)
+
x
2
(
c
x
s
y
c
z
−
s
x
s
z
)
\begin{aligned} d &=x_{1}\left(s_{x} c_{y} c_{z}\right)+x_{2}\left(-s_{x} c_{y} s_{z}\right)+x_{3}\left(s_{x} s_{y}\right) \\ e &=x_{1}\left(-c_{x} c_{y} c_{z}\right)+x_{2}\left(c_{x} c_{y} s_{z}\right)+x_{3}\left(-c_{x} s_{y}\right) \\ f &=x_{1}\left(-c_{y} s_{z}\right)+x_{2}\left(-c_{y} c_{z}\right) \\ g &=x_{1}\left(c_{x} c_{z}-s_{x} s_{y} s_{z}\right)+x_{2}\left(-c_{x} s_{z}-s_{x} s_{y} c_{z}\right) \\ h &=x_{1}\left(s_{x} c_{z}+c_{x} s_{y} s_{z}\right)+x_{2}\left(c_{x} s_{y} c_{z}-s_{x} s_{z}\right) \end{aligned}
defgh=x1(sxcycz)+x2(−sxcysz)+x3(sxsy)=x1(−cxcycz)+x2(cxcysz)+x3(−cxsy)=x1(−cysz)+x2(−cycz)=x1(cxcz−sxsysz)+x2(−cxsz−sxsycz)=x1(sxcz+cxsysz)+x2(cxsycz−sxsz)
中间量二阶导数,
(
δ
2
/
(
δ
p
i
δ
p
j
)
)
T
E
(
p
⃗
6
,
x
⃗
)
=
H
E
=
[
H
⃗
11
⋯
H
⃗
16
⋮
⋱
⋮
H
⃗
61
⋯
H
⃗
66
]
=
[
0
→
0
→
0
→
0
→
0
→
0
→
0
→
0
→
0
→
0
→
0
→
0
→
0
→
0
→
0
→
a
⃗
0
→
0
→
0
→
0
→
0
→
b
⃗
b
⃗
c
⃗
0
→
0
→
0
→
c
⃗
e
⃗
f
⃗
]
\left(\delta^{2} /\left(\delta p_{i} \delta p_{j}\right)\right) T_{E}\left(\vec{p}_{6}, \vec{x}\right)=\mathrm{H}_{E}=\left[ \begin{array}{ccc}{\vec{H}_{11}} & {\cdots} & {\vec{H}_{16}} \\ {\vdots} & {\ddots} & {\vdots} \\ {\vec{H}_{61}} & {\cdots} & {\vec{H}_{66}}\end{array}\right]=\left[ \begin{array}{cccccc}{\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} \\ {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} \\ {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} & {\vec{a}} & {\overrightarrow{0}} & {\overrightarrow{0}} \\ {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} & {\vec{b}} & {\vec{b}} & {\vec{c}} \\ {\overrightarrow{0}} & {\overrightarrow{0}} & {\overrightarrow{0}} & {\vec{c}} & {\vec{e}} & {\vec{f}}\end{array}\right]
(δ2/(δpiδpj))TE(p6,x)=HE=⎣⎢⎡H11⋮H61⋯⋱⋯H16⋮H66⎦⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎡00000000000000000abc000be000cf⎦⎥⎥⎥⎥⎥⎥⎤
其中,
a
⃗
=
[
x
1
(
−
c
x
s
z
−
s
x
s
y
c
z
)
+
x
2
(
−
c
x
c
z
+
s
x
s
y
s
z
)
+
x
3
(
s
x
c
y
)
x
1
(
−
s
x
s
z
+
c
x
s
y
c
z
)
+
x
2
(
−
c
x
s
y
s
z
−
s
x
c
z
)
+
x
3
(
−
c
x
c
y
)
]
\vec{a}=\left[ \begin{array}{c}{x_{1}\left(-c_{x} s_{z}-s_{x} s_{y} c_{z}\right)+x_{2}\left(-c_{x} c_{z}+s_{x} s_{y} s_{z}\right)+x_{3}\left(s_{x} c_{y}\right)} \\ {x_{1}\left(-s_{x} s_{z}+c_{x} s_{y} c_{z}\right)+x_{2}\left(-c_{x} s_{y} s_{z}-s_{x} c_{z}\right)+x_{3}\left(-c_{x} c_{y}\right)}\end{array}\right]
a=[x1(−cxsz−sxsycz)+x2(−cxcz+sxsysz)+x3(sxcy)x1(−sxsz+cxsycz)+x2(−cxsysz−sxcz)+x3(−cxcy)]
b
⃗
=
[
0
x
1
(
c
x
c
y
c
z
)
+
x
2
(
−
c
x
c
y
s
z
)
+
x
3
(
c
x
s
y
)
x
1
(
s
x
c
y
c
z
)
+
x
2
(
−
s
x
c
y
s
z
)
+
x
3
(
s
x
s
y
)
]
\vec{b}=\left[ \begin{array}{c}{0} \\ {x_{1}\left(c_{x} c_{y} c_{z}\right)+x_{2}\left(-c_{x} c_{y} s_{z}\right)+x_{3}\left(c_{x} s_{y}\right)} \\ {x_{1}\left(s_{x} c_{y} c_{z}\right)+x_{2}\left(-s_{x} c_{y} s_{z}\right)+x_{3}\left(s_{x} s_{y}\right)}\end{array}\right]
b=⎣⎡0x1(cxcycz)+x2(−cxcysz)+x3(cxsy)x1(sxcycz)+x2(−sxcysz)+x3(sxsy)⎦⎤
c
⃗
=
[
x
1
(
−
s
x
c
z
−
c
x
s
y
s
z
)
+
x
2
(
−
s
x
s
z
−
c
x
s
y
c
z
)
x
1
(
c
x
c
z
−
s
x
s
y
s
z
)
+
x
2
(
−
s
x
s
y
c
z
−
c
x
s
z
)
]
\vec{c}=\left[ \begin{array}{c}{x_{1}\left(-s_{x} c_{z}-c_{x} s_{y} s_{z}\right)+x_{2}\left(-s_{x} s_{z}-c_{x} s_{y} c_{z}\right)} \\ {x_{1}\left(c_{x} c_{z}-s_{x} s_{y} s_{z}\right)+x_{2}\left(-s_{x} s_{y} c_{z}-c_{x} s_{z}\right)}\end{array}\right]
c=[x1(−sxcz−cxsysz)+x2(−sxsz−cxsycz)x1(cxcz−sxsysz)+x2(−sxsycz−cxsz)]
d
⃗
=
[
x
1
(
−
c
y
c
z
)
+
x
2
(
c
y
s
z
)
+
x
3
(
−
s
y
)
x
1
(
−
s
x
s
y
c
z
)
+
x
2
(
s
x
s
y
s
z
)
+
x
3
(
s
x
c
y
)
x
1
(
c
x
s
y
c
z
)
+
x
2
(
−
c
x
s
y
s
z
)
+
x
3
(
−
c
x
c
y
)
]
\vec{d}=\left[ \begin{array}{c}{x_{1}\left(-c_{y} c_{z}\right)+x_{2}\left(c_{y} s_{z}\right)+x_{3}\left(-s_{y}\right)} \\ {x_{1}\left(-s_{x} s_{y} c_{z}\right)+x_{2}\left(s_{x} s_{y} s_{z}\right)+x_{3}\left(s_{x} c_{y}\right)} \\ {x_{1}\left(c_{x} s_{y} c_{z}\right)+x_{2}\left(-c_{x} s_{y} s_{z}\right)+x_{3}\left(-c_{x} c_{y}\right)}\end{array}\right]
d=⎣⎡x1(−cycz)+x2(cysz)+x3(−sy)x1(−sxsycz)+x2(sxsysz)+x3(sxcy)x1(cxsycz)+x2(−cxsysz)+x3(−cxcy)⎦⎤
e
⃗
=
[
x
1
(
s
y
s
z
)
+
x
2
(
s
y
c
z
)
x
1
(
−
s
x
c
y
s
z
)
+
x
2
(
−
s
x
c
y
c
z
)
x
1
(
c
x
c
y
s
z
)
+
x
2
(
c
x
c
y
c
z
)
]
\vec{e}=\left[ \begin{array}{c}{x_{1}\left(s_{y} s_{z}\right)+x_{2}\left(s_{y} c_{z}\right)} \\ {x_{1}\left(-s_{x} c_{y} s_{z}\right)+x_{2}\left(-s_{x} c_{y} c_{z}\right)} \\ {x_{1}\left(c_{x} c_{y} s_{z}\right)+x_{2}\left(c_{x} c_{y} c_{z}\right)}\end{array}\right]
e=⎣⎡x1(sysz)+x2(sycz)x1(−sxcysz)+x2(−sxcycz)x1(cxcysz)+x2(cxcycz)⎦⎤
f
⃗
=
[
x
1
(
−
c
y
c
z
)
+
x
2
(
c
y
s
z
)
x
1
(
−
c
x
s
z
−
s
x
s
y
c
z
)
+
x
2
(
−
c
x
c
z
+
s
x
s
y
s
z
)
x
1
(
−
s
x
s
z
+
c
x
s
y
c
z
)
+
x
2
(
−
c
x
s
y
s
z
−
s
x
c
z
)
]
\vec{f}=\left[ \begin{array}{c}{x_{1}\left(-c_{y} c_{z}\right)+x_{2}\left(c_{y} s_{z}\right)} \\ {x_{1}\left(-c_{x} s_{z}-s_{x} s_{y} c_{z}\right)+x_{2}\left(-c_{x} c_{z}+s_{x} s_{y} s_{z}\right)} \\ {x_{1}\left(-s_{x} s_{z}+c_{x} s_{y} c_{z}\right)+x_{2}\left(-c_{x} s_{y} s_{z}-s_{x} c_{z}\right)}\end{array}\right]
f=⎣⎡x1(−cycz)+x2(cysz)x1(−cxsz−sxsycz)+x2(−cxcz+sxsysz)x1(−sxsz+cxsycz)+x2(−cxsysz−sxcz)⎦⎤
6.3 3D-NDT extensions
- 3D-NDT最重要的参数是 cell size
- size too large, less precise registration
- cell的影响区域只延伸到其边界,如果cells太小, registration will only succeed if the two scans are initially close together
- 另一个问题是,对于较小的cell,可能根本不使用具有低点密度的部分扫描,因为计算可信的协方差矩阵至少需要5个点
- Using smaller cells also requires more memory
因此,cell的最佳尺寸和分布取决于输入数据的形状和密度,还取决于我们对scan表示的保真度的要求。
使用方形或立方体cell的固定格子需要用户选择良好的cell尺寸。
更灵活的cell结构将是优选的:在可能的情况下使用大cell并且在单个正态分布不能令人满意地描述表面的地方进行更精细的细分。 本节介绍了许多用于创建NDT cell结构和相关似然函数的替代方法
6.3.1 Fixed discretisation
不考虑刚才提到的缺点,使用固定单元格的好处是初始化和使用单元结构的开销非常小。 每个单元只需要计算一组参数,每个单元的定位都很简单。 对于算法的性能而言,更重要的是点对单元查找可以在恒定时间内非常快速地完成,因为单元可以存储在简单的阵列中。
6.3.2 Octree discretisation
八叉树是一种常用的树形结构,可用于存储三维空间的hierarchical discretisation。在八叉树中,每个节点表示空间的有界分区。每个内部节点有八个子节点,表示其父节点的空间分区的全等和非重叠细分。创建八叉树时,根节点的大小适合包含整个参考扫描。然后递归地构建树,分割包含多于一定数量点的所有节点。所有数据点都包含在八叉树的叶节点中。八叉树与kD树非常相似,但每个内部节点有八个而不是两个子节点。
如前所述,八叉树版本的3D-NDT以fixed regular cells开始,不同之处在于每个单元格是八叉树的根节点。分布的方差大于特定阈值的单元被递归地分割,形成八叉树林。
对于NDT的效率而言,点到cell查找速度快是很重要的,这是使用forest of octrees的主要原因,而不是具有跨越所有扫描的根节点的单个八叉树。对于许多类型的扫描数据,可以指定合理的基本单元尺寸,从而仅需要分割扫描表面特别不均匀的部分中的少数单元。因此,对于大多数点,找到正确的单元只需要单个数组访问,而每个点遍历一个八叉树需要更多的时间。森林需要比单个树更多的内存,特别是如果每棵树的根节点的单元格大小很小,但是对于本文提出的实验,这种影响可以忽略不计
6.3.3 Iterative discretisation
另一种选择是使用每次运行的最终pose作为下一次运行的初始pose,以连续更精细的cell分辨率执行多次NDT运行。 第一次运行有利于将对齐的scan更紧密地结合在一起,后面的运行可以改善粗略的初始匹配。
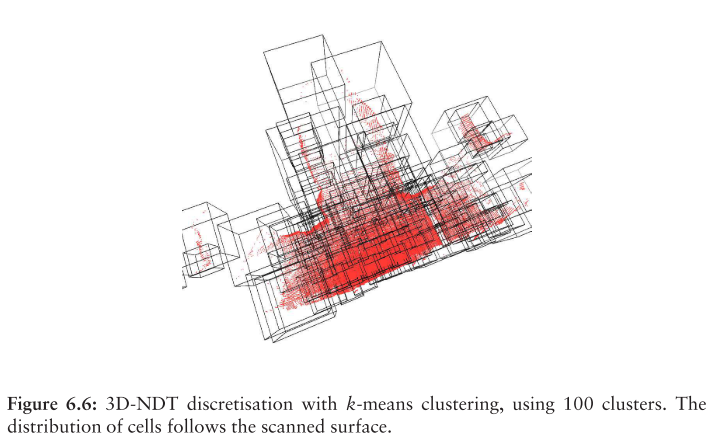
6.3.4 Adaptive clustering
更自适应的离散化方法是使用聚类算法,该算法基于扫描点的位置将扫描点划分为多个聚类,并且为每个聚类使用一个NDT单元。一种易于实现的常见聚类算法是k-means聚类[29],
6.3.6 Trilinear interpolation
p ^ ( x ⃗ ) = ∑ b = 1 8 − d 1 ( b ) w ( x ⃗ , μ ⃗ b ) exp ( − d 2 ( b ) 2 ( x ⃗ − μ ⃗ b ) T Σ b − 1 ( x ⃗ − μ ⃗ b ) ) \hat{p}(\vec{x})=\sum_{b=1}^{8}-d_{1(b)} w\left(\vec{x}, \vec{\mu}_{b}\right) \exp \left(-\frac{d_{2(b)}}{2}\left(\vec{x}-\vec{\mu}_{b}\right)^{\mathrm{T}} \Sigma_{b}^{-1}\left(\vec{x}-\vec{\mu}_{b}\right)\right) p^(x)=∑b=18−d1(b)w(x,μb)exp(−2d2(b)(x−μb)TΣb−1(x−μb))

将NDT应用于矿井隧道扫描的图示,具有(右)和不带(左)三线性插值。 密度较大的区域代表较大的分数值。 (暗网格图案不代表较小的分数值,但仅显示底层单元格的边界)
- trilinear interpolation耗时4倍
- cell间更平滑
PCL代码细节
代码中的公式均和论文一致,感兴趣的可以详细查看pcl源码pcl/registration/include/pcl/registration/impl/ndt.hpp文件
//
template<typename PointSource, typename PointTarget> void
pcl::NormalDistributionsTransform<PointSource, PointTarget>::computeTransformation (PointCloudSource &output, const Eigen::Matrix4f &guess)
{
nr_iterations_ = 0;
converged_ = false;
double gauss_c1, gauss_c2, gauss_d3;
// Initializes the guassian fitting parameters (eq. 6.8) [Magnusson 2009]
gauss_c1 = 10 * (1 - outlier_ratio_);
gauss_c2 = outlier_ratio_ / pow (resolution_, 3);
gauss_d3 = -log (gauss_c2);
gauss_d1_ = -log ( gauss_c1 + gauss_c2 ) - gauss_d3;
gauss_d2_ = -2 * log ((-log ( gauss_c1 * exp ( -0.5 ) + gauss_c2 ) - gauss_d3) / gauss_d1_);
if (guess != Eigen::Matrix4f::Identity ())
{
// Initialise final transformation to the guessed one
final_transformation_ = guess;
// Apply guessed transformation prior to search for neighbours
transformPointCloud (output, output, guess);
}
// Initialize Point Gradient and Hessian
point_gradient_.setZero ();
point_gradient_.block<3, 3>(0, 0).setIdentity ();
point_hessian_.setZero ();
Eigen::Transform<float, 3, Eigen::Affine, Eigen::ColMajor> eig_transformation;
eig_transformation.matrix () = final_transformation_;
// Convert initial guess matrix to 6 element transformation vector
Eigen::Matrix<double, 6, 1> p, delta_p, score_gradient;
Eigen::Vector3f init_translation = eig_transformation.translation ();
Eigen::Vector3f init_rotation = eig_transformation.rotation ().eulerAngles (0, 1, 2);
p << init_translation (0), init_translation (1), init_translation (2),
init_rotation (0), init_rotation (1), init_rotation (2);
Eigen::Matrix<double, 6, 6> hessian;
double score = 0;
double delta_p_norm;
// Calculate derivates of initial transform vector, subsequent derivative calculations are done in the step length determination.
score = computeDerivatives (score_gradient, hessian, output, p);
while (!converged_)
{
// Store previous transformation
previous_transformation_ = transformation_;
// Solve for decent direction using newton method, line 23 in Algorithm 2 [Magnusson 2009]
Eigen::JacobiSVD<Eigen::Matrix<double, 6, 6> > sv (hessian, Eigen::ComputeFullU | Eigen::ComputeFullV);
// Negative for maximization as opposed to minimization
delta_p = sv.solve (-score_gradient);
//Calculate step length with guarnteed sufficient decrease [More, Thuente 1994]
delta_p_norm = delta_p.norm ();
if (delta_p_norm == 0 || delta_p_norm != delta_p_norm)
{
trans_probability_ = score / static_cast<double> (input_->points.size ());
converged_ = delta_p_norm == delta_p_norm;
return;
}
delta_p.normalize ();
delta_p_norm = computeStepLengthMT (p, delta_p, delta_p_norm, step_size_, transformation_epsilon_ / 2, score, score_gradient, hessian, output);
delta_p *= delta_p_norm;
transformation_ = (Eigen::Translation<float, 3> (static_cast<float> (delta_p (0)), static_cast<float> (delta_p (1)), static_cast<float> (delta_p (2))) *
Eigen::AngleAxis<float> (static_cast<float> (delta_p (3)), Eigen::Vector3f::UnitX ()) *
Eigen::AngleAxis<float> (static_cast<float> (delta_p (4)), Eigen::Vector3f::UnitY ()) *
Eigen::AngleAxis<float> (static_cast<float> (delta_p (5)), Eigen::Vector3f::UnitZ ())).matrix ();
p = p + delta_p;
// Update Visualizer (untested)
if (update_visualizer_ != 0)
update_visualizer_ (output, std::vector<int>(), *target_, std::vector<int>() );
if (nr_iterations_ > max_iterations_ ||
(nr_iterations_ && (std::fabs (delta_p_norm) < transformation_epsilon_)))
{
converged_ = true;
}
nr_iterations_++;
}
// Store transformation probability. The realtive differences within each scan registration are accurate
// but the normalization constants need to be modified for it to be globally accurate
trans_probability_ = score / static_cast<double> (input_->points.size ());
}