问题要求
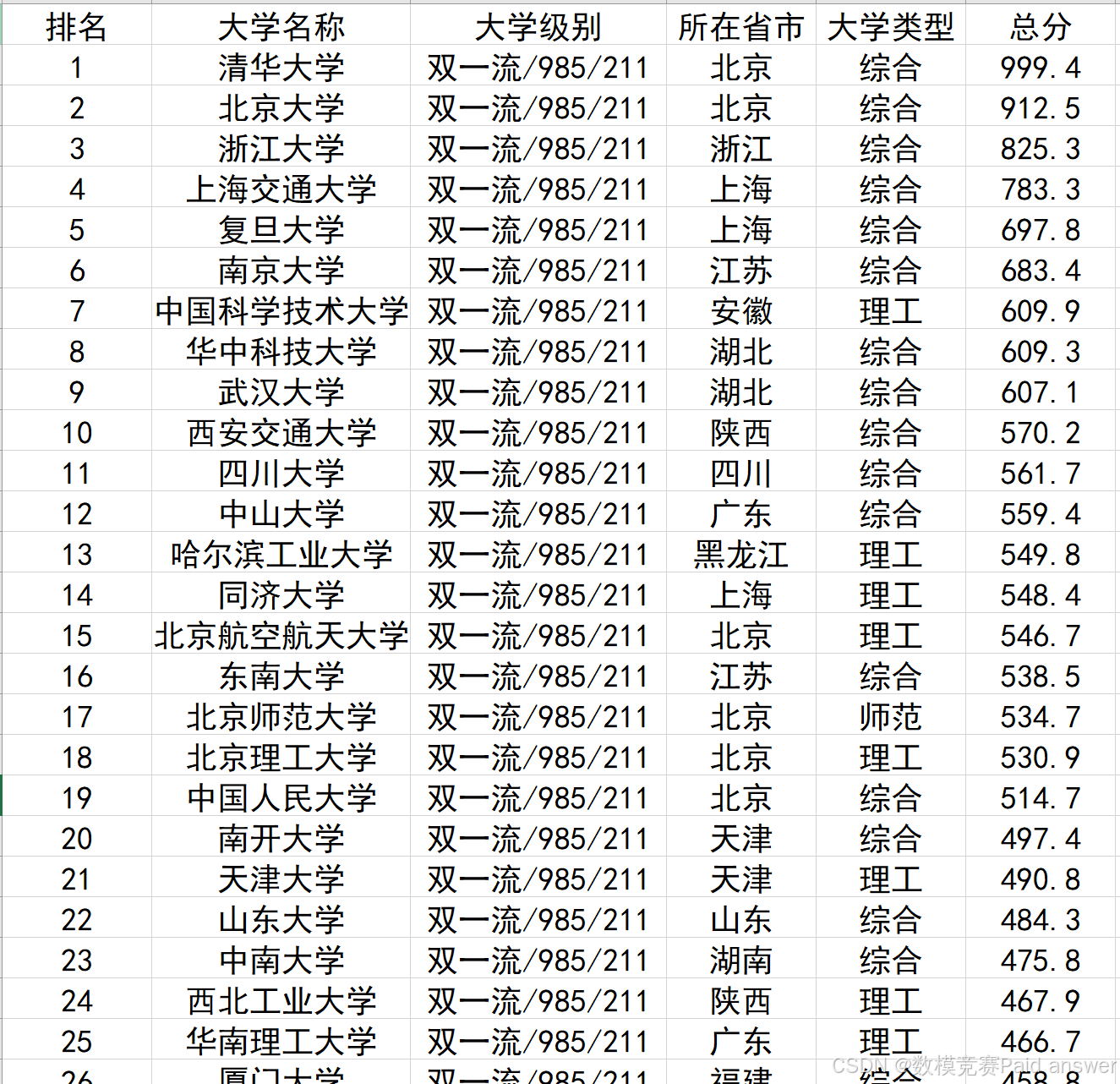
从https://www.shanghairanking.cn/rankings/bcur/202411中,爬取中国大学排名(主榜)共计594 所学校的信息。
1.从第一页开始爬,到最后一页(第二十页)。
2.将每所大学的信息保存进 CSV 文件中的一行,从左到右依次为:
第一列 排名
第二列 中文名称
第三列 是否为985/211/双一流
第四列 省市
第五列 类型
第六列 总分

全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可
非慈善耶稣
为防止空手套白狼 我这里仅展现一点点代码 全部代码见下方“ 只会建模 QQ名片” 点击QQ名片即可
for i in range(0, length):
list0 = list_total[i]
# 大学中文名
name_cn = re.findall('class="name-cn">(.*?) </a>', list0)
# 大学英文名
name_en = re.findall('class="name-en">(.*?) </a>', list0)
# 大学级别
tags = re.findall('class="tags">(.*?)</p>', list0)
# 无级别 比如不是 985/211的学校
# 空列表==false
if not tags:
tags = ['无']
# 大学所在省市 和 大学类型
list_province_category = re.findall(
'<td data-v-3fe7d390="" class="">\n (.*?)\n <!----></td>',
list0)
# 大学总分
score = re.findall('<td data-v-3fe7d390="" class="">\n (.*?)\n </td>', list0)
# 办学层次
School_level = re.findall(
'<td data-v-3fe7d390="" class="">\n (.*?)\n </td>',
list0)
list_0 = name_cn + name_en + tags + list_province_category + score + School_level
list_information.append(list_0)