Request库使用
Python的Request库是python的一个远程网页请求库,和我们直接打开浏览器请求差不太多。这里总结下该库的使用,几乎是学习爬虫必备,哪怕是直接请求远程API,开发web系统,也会使用到该库。库的安装pip install requests
安装好之后,最简单的使用方法啊,直接res =requests.get(“http://www.baidu.com”)就可以拿到访问结果,然后print(res)。这证明该模块安装成功。
(1)返回的参数
如果有些需要请求头的,直接将请求头加入进去。Headers = {}
request库的请求返回结果主要有, res对象的相关参数。
res.status_code 状态码 200 表示成功 就是http协议的请求码
content 二进制的响应形式,支持图片的响应,批量下载图片到本地需要用到该参数,图片站的请求。一般的比如抓取壁纸/游戏英雄图片/美女图片的时候,需要储存到本地。会用的比较多。
保存图片的方法:
if response.status_code == 200:
with open(save_path, 'wb') as file:
file.write(response.content)
print(f"图片已保存到 {save_path}")
else:
print(f"请求失败,状态码:{response.status_code}")
text 文本html或者json响应。需要注意的是有些网站太老,里面可能是gbk格式的,这个时候,需要将获取的编码转换成utf-8的编码格式。否则会出现类似 UnicodeEncodeError: 'gbk' codec can't encode character '\x82' in position 325: illegal multibyte sequence 的错误
res = requests.get('https://xxx.com/')
print(res.text.encode('utf-8', errors='ignore'))
headers 返回的请求头信息,跟发送的请求头信息类似,有时候,我们需要读取返回头的信息用来处理。
Cookies 一般接口都不返回cookies 但是一些网址的请求是会写入cookie的所以这个时候需要记录,特别是登录类型的,返回cookie,后续会需要验证cookie身份
Json()
| 如果响应内容是JSON格式的,这个方法可以将JSON字符串转换为Python字典。 如果不是json结构体 直接报错 |
Encoding 编码方式 检查网页编码 可以让本地正确还原内容,特别是外国网页的时候。
(2)请求的参数
一般一个网页 为了防止盗链或者普通机器人采集一些图片之类的,会在headers头部加入校验 一个是Reffer 来源检测 (基本图片站都会检测来源,否则莫名其妙的请求都会消耗其带宽,任意网站的引用网址,都会请求获取图片)例如我们引用QQ空间或者微信文章里面的图片,会屏蔽正确图片显示,并告知该图片来源于QQ/WX,请求头User-Agent 表示请求的客户端,这个一般写自己常用的一个客户端即可,一般只要不是空,很多网站不会仔细检查,但是如果是空,服务器必然知道是程序请求的,可能会拒绝这次访问。
头部检测是基本检测,data发送请求是核心关键。一般的data请求格式。Data = {},爬虫很多情况下都是获取get的数据
如果远程直接请求获取到的就是json字符串(一般是远程API),数据交互本来就是API进行的,主要应用场景比如远程获取服务器端的指令执行下一步的操作。 这个时候需要使用到json库
response = requests.get(url,headers=headers)
info =json.loads(response.text)
页面的解析获取 使用 from bs4 import BeautifulSoup 获取解析函数(pquery库性能更高一些,但是由于大部分能用的示例爬虫都是bs4风格,如果不掌握beautifulSoup不方便调很多已经成型的爬虫例子,所以基本该库的掌握是必备的)。
beautifulSoup的相关语法使用:
假设解析后的对象 soup =BeautifulSoup(html,'html.parser')
查找div模块 class 是box的方法
first_box = soup.find('div', {'class': 'box'}) 格式是标签 属性 值
如果是要获取全部的 变成
box = soup.find_all('div', {'class': 'box'})。
进一步: 如果是需要获取某个大模块里面的 就是某个模块里面的某些模块。
Soup.find(“commentlist”).find("p") 模块对象是可以无限find叠加下去一直寻找到某个具体的对象的这点非常方便。
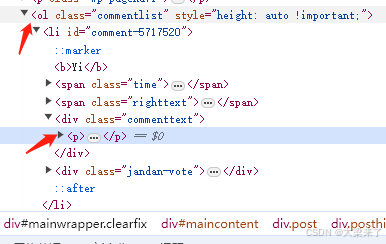
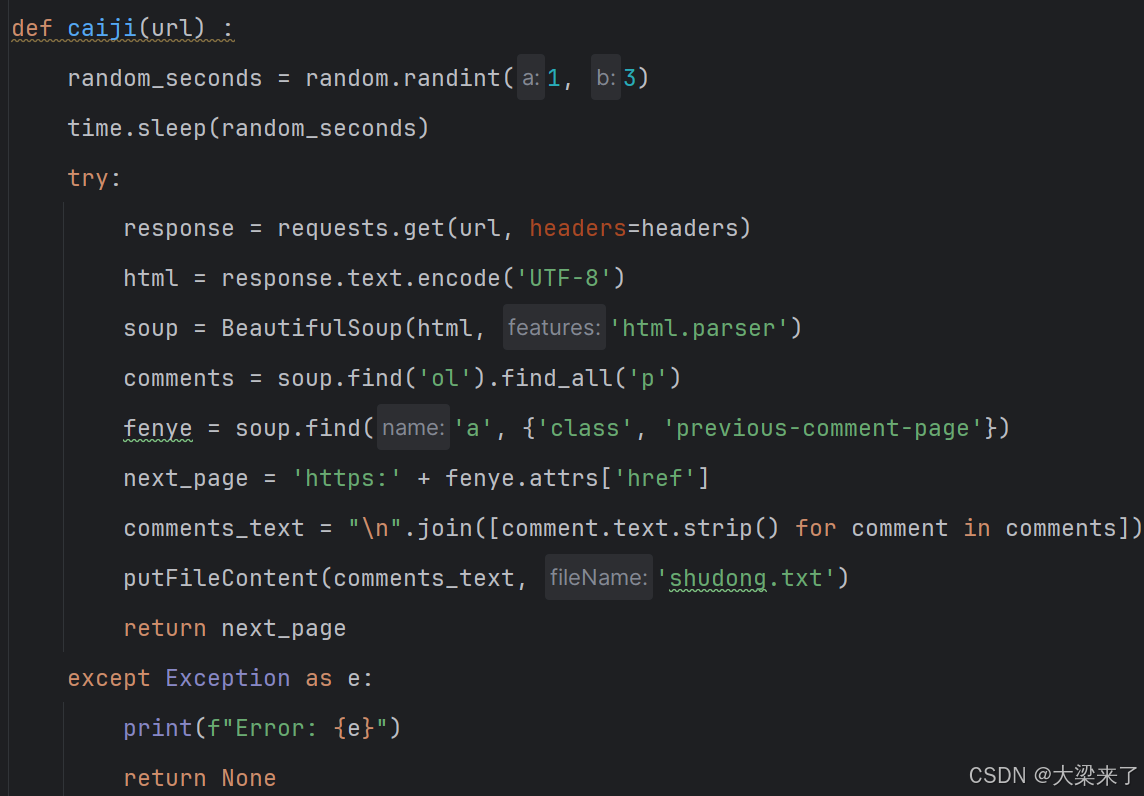
将我们需要的相关数据信息储存到某个文件(一般比如商品/搜索标题/点赞人数/购买人数) 这里示例是将别人的评论抓取
first_box = soup.find('ol').find_all('p')
words = []
for elem in first_box:
words.append(elem.text)
这样评论就被采集到了words里面,然后可以储存给我们后面其他的逻辑分析使用。直接读取标签页面里面的文本。如果是获取属性,一般是url attr 获取即可。
实现的代码如下: