注意力机制最初是一种在编码器-解码器结构中使用到的机制,在多种任务中使用:机器翻译、图像转换等。如今,注意力机制在深度学习模型中无处不在,而不仅仅是在编码器-解码器上下文中使用。
注意力机制
Encoder-Decoder机制
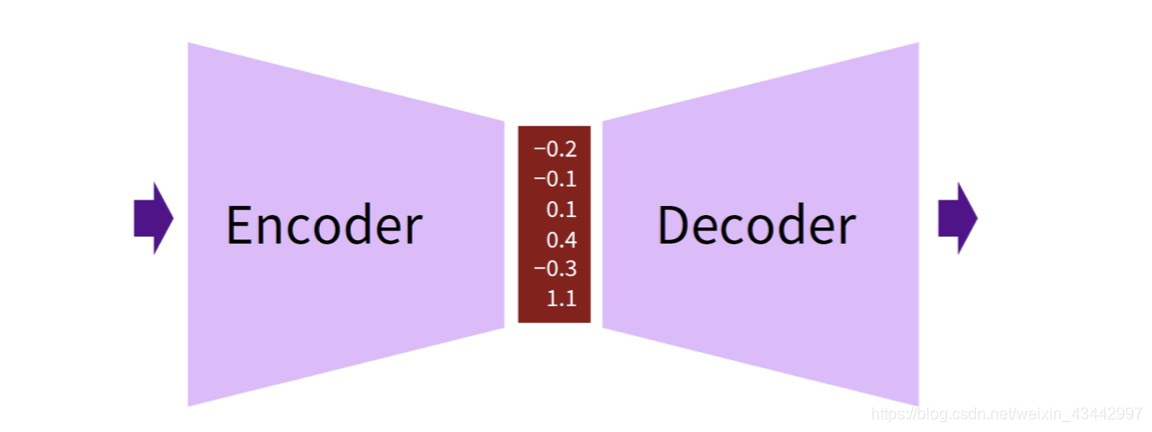
如上图所示,编码器将输入嵌入为一个向量, 解码器根据这个向量得到输出。由于这种结构一般的应用场景(机器翻译等),其输入输出都是序列, 因此也被称为序列到序列的模型Seq2Seq。
原始输入首先通过一个神经网络被编码为一个向量,以RNN为例,在每个时间步t,将前向和后向的句子嵌入连接起来,以获得双向RNN的内部表示形式:
h t = [ h t → ; h t ← ] h_t=[\overrightarrow{h_t};\overleftarrow{h_t}] ht=[ht;ht]
注意力机制允许解码器在每一个时间步t处考虑整个编码器输出的隐藏状态序列 ( h 1 , h 2 , ⋯ , h T x ) (h_1,h_2,⋯,h_{Tx}) (h1,h2,⋯,hTx),从而编码器将更多的信息分散地保存在所有隐藏状态向量中,解码器在使用这些隐藏向量时, 就能决定对哪些向量更关心。
解码器得到的目标序列 ( h 1 , h 2 , ⋯ , h T y ) (h_1,h_2,⋯,h_{Ty}) (h1,h2,⋯,hTy)中的输出 y t y_t yt, 都是基于以下的条件分布:
h t ~ = t a n h ( W c [ c t ; h t ] ) \tilde{h_t}=tanh(W_c[c_t;h_t]) ht~=tanh(Wc[ct;ht])
P [ y t ∣ { y 1 , … , y t − 1 } , c t ] = s o f t m a x ( W s h t ~ ) P[y_t|\{y_1, …, y_{t-1}\}, c_t]=softmax(W_s\tilde{h_t}) P[yt∣{
y1,…,yt−1},ct]=softmax(Wsht~)
其中, h t ~ \tilde{h_t} ht~为隐藏状态向量; c t c_t ct是上下文向量,可由全局和局部两种计算方法得到; W s W_s Ws和 W c W_c W