我们前期介绍了Llama 3大模型,以及本地部署了Llama 3 8b模型,但是想体验一下llama3-70b的模型的话,需要很大的计算资源,且要求极高的内存。llama3-8b的模型约4.7G ,而llama3-70b的模型约40G,若想在自己的电脑上面加载llama3-70b的模型,可想而知需要多少的内存,多少的显卡资源。

Meta llama 3
Llama 3是Meta AI开源的第三代Llama系列模型,其新的 8B 和 70B 参数 Llama 3 模型在Llama 2的基础上,实现了更大性能的提升。由于预训练和训练后的技术改进,其Llama 3模型是当今 8B 和 70B 参数规模的最佳模型。Llama 3模型的改进大大降低了错误拒绝率,改善了一致性,并增加了模型响应的多样性。Llama 3模型在推理、代码生成和指令跟踪等功能也得到了极大的改善。

Nvidia
无论是大语言模型,还是文生视频,文生图模型,都需要大量的显卡资源,而Nvidia的显卡一定是研发团队考虑的重点显卡配置。随着Llama系列开源以来,而Nvidia也拿出了自己的诚意,在自己官方网站上线了Llama系列的模型,不仅搭建了完美的UI界面供大家使用,而且还是免费的使用资源。

llama3-70b Nvidia
在Nvidia官方界面,可以很容易的使用llama3-70b模型。界面提供2种使用llama3-70b的方式,一是可以直接在界面聊天框中输入内容,跟llama3-70b模型聊天,另外要给是使用Nvidia提供的API接口。
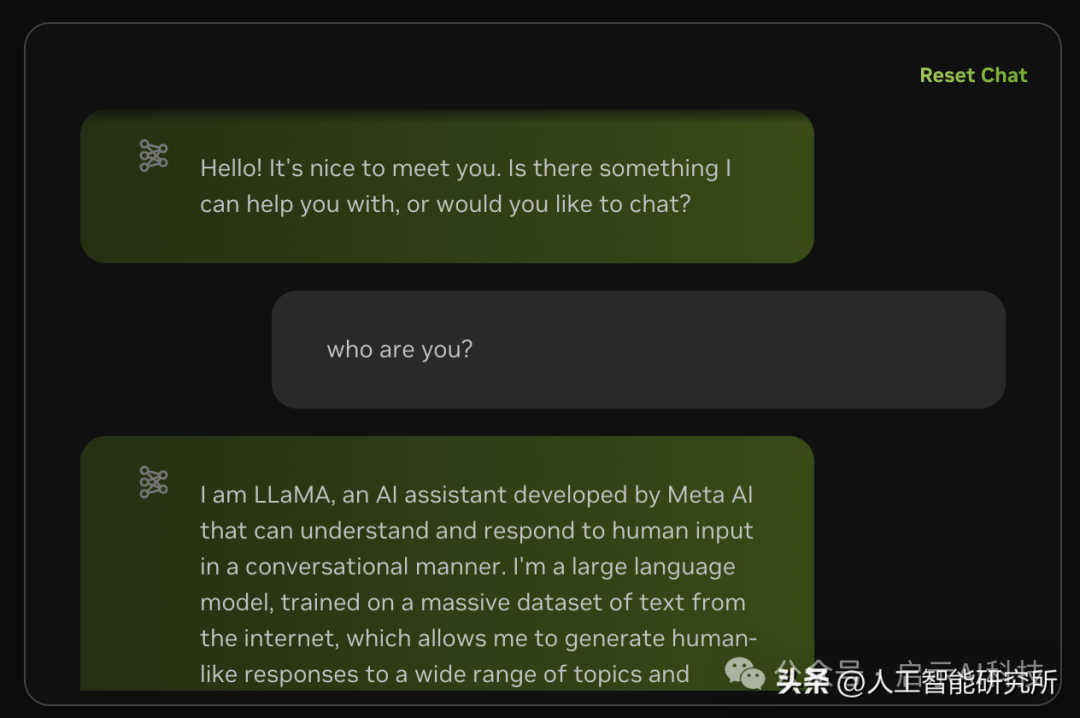
llama3-70b模型
llama3-70b模型在Nvidia网站上面跑的速度还是极快的,而在自己电脑上面跑llama3-8b的模型有时还出现卡顿的现象,特别是一些稍微复杂的问题。
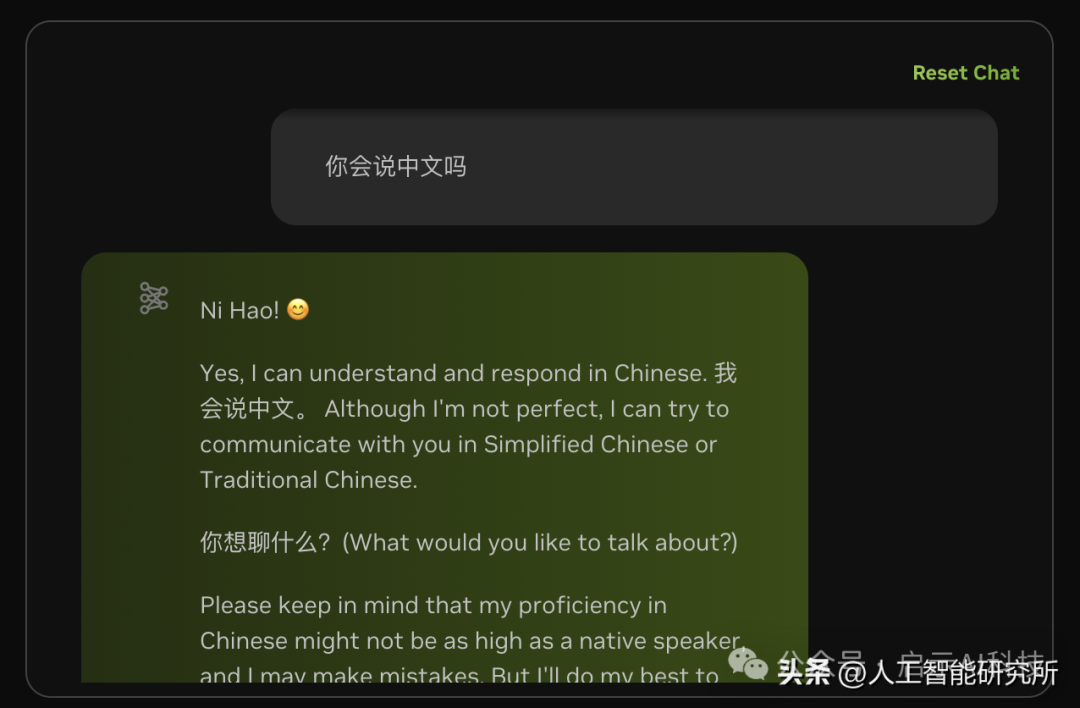
llama3 70b 中文能力
让他说中文,感觉回复的是英文,然后再翻译成中文,但是回复的内容中,其中文还是占少数,主要是英文为主。这在介绍llama3时也有介绍,其官方目前的训练数据还是以英文为主。
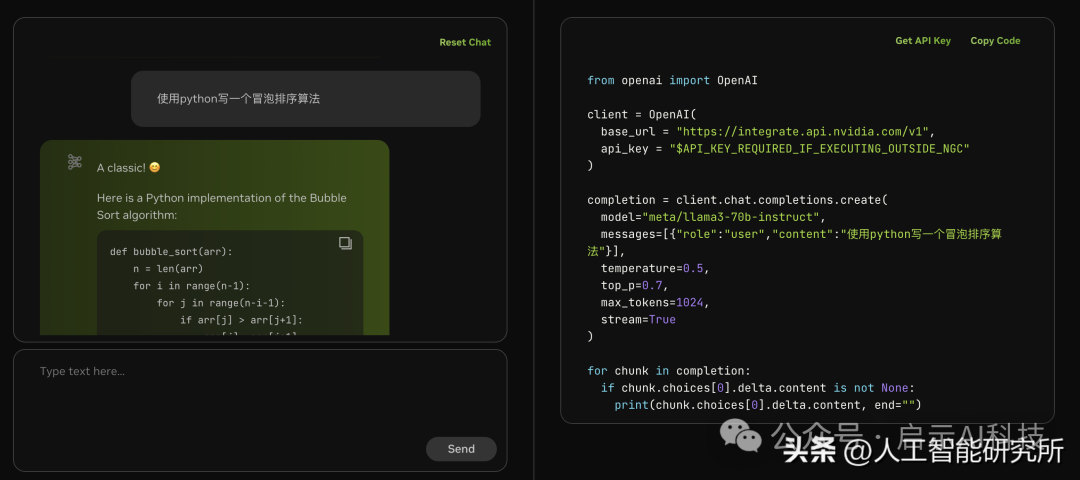
llama3 70b 编程能力
不得不说,各大模型对编码的处理还是很符合人意的,毕竟编程语言是固定的,且都是英文的形式,训练数据也可以直接用GitHub的数据。
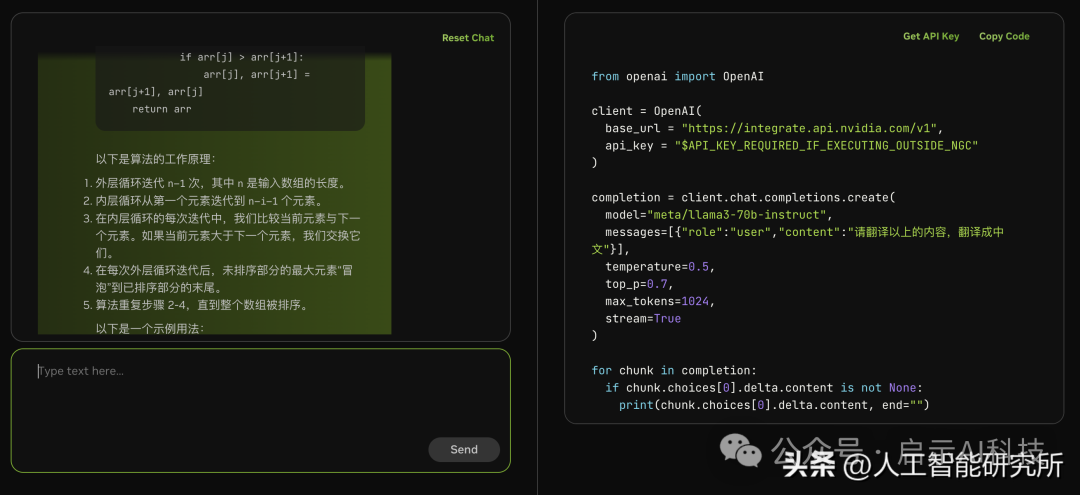
llama3 70b 上下文记忆能力
而在Nvidia官网上使用的llama3 70b模型也支持上下文记忆,模型可以记录以前的聊天记录,若模型回复英文的答案,可以让模型进行翻译,其翻译效果还是很强大。
英文:
Here is a Python implementation of the Bubble Sort algorithm:
def bubble_sort(arr):
n = len(arr)
for i in range(n-1):
for j in range(n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
Here's an explanation of how the algorithm works:
The outer loop iterates n-1 times, where n is the length of the input array.
The inner loop iterates from the first element to the n-i-1-th element.
In each iteration of the inner loop, we compare the current element with the next element. If the current element is greater than the next element, we swap them.
After each iteration of the outer loop, the largest element in the unsorted portion of the array "bubbles" up to the end of the sorted portion.
The algorithm repeats steps 2-4 until the entire array is sorted.
Here's an example usage:
arr = [5, 2, 8, 3, 1, 6, 4]
arr = bubble_sort(arr)
print(arr) #[1, 2, 3, 4, 5, 6, 8]
Note that Bubble Sort has a time complexity of O(n^2), which makes it less efficient than other sorting algorithms like QuickSort or MergeSort for large datasets. However, it's still a simple and easy-to-understand algorithm that can be useful for small datasets or educational purposes.
中文翻译:
以下是 Python 实现的冒泡排序算法:
def bubble_sort(arr):
n = len(arr)
for i in range(n-1):
for j in range(n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
以下是算法的工作原理:
外层循环迭代 n-1 次,其中 n 是输入数组的长度。
内层循环从第一个元素迭代到 n-i-1 个元素。
在内层循环的每次迭代中,我们比较当前元素与下一个元素。如果当前元素大于下一个元素,我们交换它们。
在每次外层循环迭代后,未排序部分的最大元素“冒泡”到已排序部分的末尾。
算法重复步骤 2-4,直到整个数组被排序。
以下是一个示例用法:
arr = [5, 2, 8, 3, 1, 6, 4]
arr = bubble_sort(arr)
print(arr) #[1, 2, 3, 4, 5, 6, 8]
注意冒泡排序的时间复杂度为 O(n^2),这使得它对于大型数据集来说不如快速排序或归并排序那样高效。然而,它仍然是一个简单易懂的算法,对于小型数据集或教育目的来说非常有用。

代码实现llama3
当然,也可以使用官方提供的API搭建自己的聊天机器人,只需申请API key,输入如下代码,并把API key替换成自己的key即可。
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC")
completion = client.chat.completions.create(
model="meta/llama3-70b-instruct",
messages=[{"role":"user","content":"请翻译以上的内容,翻译成中文"}],
temperature=0.5,
top_p=0.7,
max_tokens=1024,
stream=True)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
`https://build.nvidia.com/meta/llama3-70b Inference: Engine: Triton Test Hardware: `
`H100-80G`
` `
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓