一、什么是MVCC?
mvcc,也就是多版本并发控制,是为了在读取数据时不加锁来提高读取效率和并发性的一种手段。
数据库并发有以下几种场景:
- 读-读:不存在任何问题。
- 读-写:有线程安全问题,可能出现脏读、幻读、不可重复读。
- 写-写:有线程安全问题,可能存在更新丢失等。
mvcc解决的就是读写时的线程安全问题,线程不用去争抢读写锁。
mvcc所提到的读是快照读,也就是普通的select语句。快照读在读写时不用加锁,不过可能会读到历史数据。
还有一种读取数据的方式是当前读,是一种悲观锁的操作。它会对当前读取的数据进行加锁,所以读到的数据都是最新的。主要包括以下几种操作:
- select lock in share mode(共享锁)
- select for update(排他锁)
- update(排他锁)
- insert(排他锁)
- delete(排他锁)
二、MVCC的实现
1.回顾事务的特性
- 原子性:通过undolog实现。
- 持久性:通过redolog实现。
- 隔离性:通过加锁(当前读)&MVCC(快照读)实现。
- 一致性:通过undolog、redolog、隔离性共同实现。
2.回顾事务的隔离级别
- 读未提交:允许读取尚未提交的数据变更。可能会导致脏读、幻读或不可重复读。
- 读已提交:允许读取已经提交的数据。可能会导致幻读和不可重复读。
- 可重复读:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改。可能会导致幻读。
- 可串行化:最高隔离级别。
在读已提交和可重复读隔离级别下的快照读,都是基于MVCC实现的!
3.mvcc实现原理
mvcc的实现,基于undolog、版本链、readview。
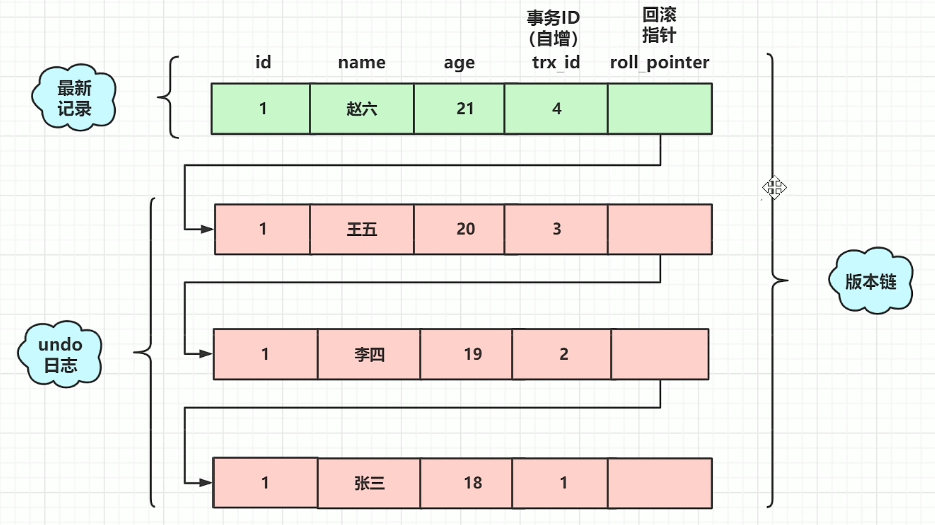
在mysql存储的数据中,除了我们显式定义的字段,mysql会隐含的帮我们定义几个字段。
-
trx_id:事务id,每进行一次事务操作,就会自增1。
-
roll_pointer:回滚指针,用于找到上一个版本的数据,结合undolog进行回滚。
什么是readview呢?
当我们用select读取数据时,这一时刻的数据会有很多个版本(例如上图有四个版本),但我们并不知道读取哪个版本,这时就靠readview来对我们进行读取版本的限制,通过readview我们才知道自己能够读取哪个版本。
在一个readview快照中主要包括以下这些字段:

对readview中的参数做一些解释
m_ids:活跃的事务就是指还没有commit的事务。
max_trx_id:例如m_ids中的事务id为(1,2,3),那么下一个应该分配的事务id就是4,max_trx_id就是4。
creator_trx_id:执行select读这个操作的事务的id。
readview如何判断版本链中的哪个版本可用呢?(重点!)

从上到下分别为(1)(2)(3)(4),依次进行解释
trx_id表示要读取的事务id
(1)如果要读取的事务id等于进行读操作的事务id,说明是我读取我自己创建的记录,那么为什么不可以呢。
(2)如果要读取的事务id小于最小的活跃事务id,说明要读取的事务已经提交,那么可以读取。
(3)max_trx_id表示生成readview时,分配给下一个事务的id,如果要读取的事务id大于max_trx_id,说明该id已经不在该readview版本链中了,故无法访问。
(4)m_ids中存储的是活跃事务的id,如果要读取的事务id不在活跃列表,那么就可以读取,反之不行。
4.mvcc如何实现RC和RR的隔离级别
(1)RC的隔离级别下,每个快照读都会生成并获取最新的readview。
(2)RR的隔离级别下,只有在同一个事务的第一个快照读才会创建readview,之后的每次快照读都使用的同一个readview,所以每次的查询结果都是一样的。
5.幻读问题
- 快照读:通过mvcc,RR的隔离级别解决了幻读问题,因为每次使用的都是同一个readview。
- 当前读:通过next-key锁(行锁+gap锁),RR隔离级别并不能解决幻读问题。