参考资源:https://blog.csdn.net/sinat_29957455/article/details/79028730 https://blog.csdn.net/cymy001/article/details/78275886
目录
1.3用一个字典构成的列表list of dicts来构建DataFrame
三、info()、describe()、head()、tail()函数及缺省值填充
五、使用pandas 的read_csv、read_table、read_fwf、read_excel读取数据
一、创建一个DataFrame:
1.1用字典dict,字典值value是列表list
import pandas as pd
population={'city':['Beijing','Shanghai','Guangzhou','Shenzhen','Hangzhou','Chongqing'],
'year':[2016,2017,2016,2017,2016,2016],
'population':[2100,2300,1000,700,500,500]
}#字典
population=pd.DataFrame(population,columns=['year','city','population'],
index=['one','two','three','four','five','six'])
#改变行index索引和列名columns 将字典转化为dataframe对象
print(population)

1.2用Series构建DataFrame
import pandas as pd
cities={'Beijing':55000,'Shanghai':60000,'shenzhen':50000,'Hangzhou':20000,'Guangzhou':45000,'Suzhou':None}
apts=pd.Series(cities,name='income')
apts['shenzhen']=70000 #更换深圳的值
less_than_50000=(apts<50000)#返回bool类型的列表
apts[less_than_50000]=40000#使满足小于50000的都改为40000
apts2=pd.Series({'Beijing':10000,'Shanghai':8000,'shenzhen':6000,'Tianjin':40000,'Guangzhou':7000,'Chongqing':30000})
# print(apts2)
apts=apts+apts2
apts[apts.isnull()]=apts.mean()#使NAN值变为apts的平均值
# print(apts)
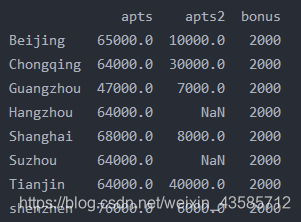
df=pd.DataFrame({'apts':apts,'apts2':apts2}) ###
print(df)
此外还有一个广播特性,若添加df['bonus']=2000 ,表格会添加一列:名为bonus,值全为2000
1.3用一个字典构成的列表list of dicts来构建DataFrame
data=[{'JackMa':99999999999,'Han':5000,'David':10000},
{'JackMa':99999999998,'Han':4000,'David':11000}]
pdl=pd.DataFrame(data,index=['salary1','salary2'])
print(pdl)
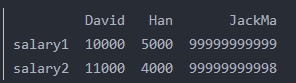
注意:与方法一不同,方法一是字典转为dataframe,每个键对应一个值(列表),相当于表格列列划分;方法三是将列表转为dataframe,列表中的每个元素是字典,相当于表格行行划分。
二、定位DataFrame里的元素
2.1利用表达式boolean定位
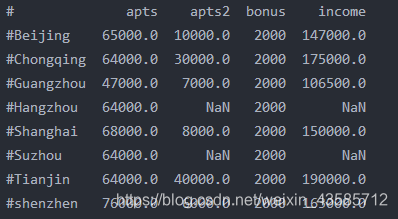
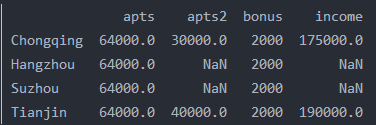
df['income']=df['apts']*2+df['apts2']*1.5+df['bonus']
print(df)
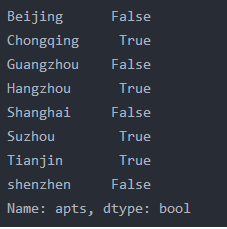
print(df.apts==64000)
print(df['apts']==64000) #boolean条件,两个等价的
print(df[df['apts']==64000]) #对行做选择,就是把apts列等于64000的行取出来
2.2利用loc,iloc,ix函数定位
loc函数主要通过行标签索引行数据,划重点,标签!标签!标签!
iloc 主要是通过行号获取行数据,划重点,序号!序号!序号!
ix:通过行标签或者行号索引行数据(基于loc和iloc 的混合)不建议使用
print(df.loc['Hangzhou']) #定位选某一行

print(df.loc[df['apts']==64000,['apts2','apts','bonus']])
#前面的部分是对行做选择,后面的部分是对列做选择
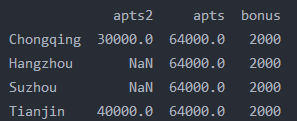
print(df.iloc[0:5])
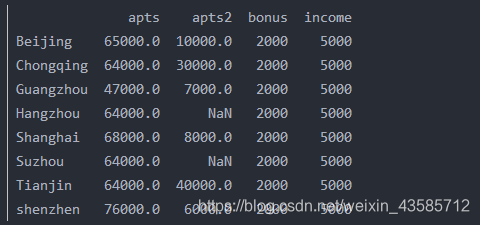
df.loc[:,'income']=5000 #将income的所有值变成5000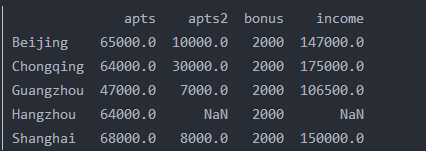
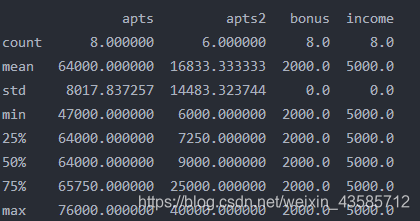
三、info()、describe()、head()、tail()函数及缺省值填充
df.info() #df的详细信息
df.describe() #总结数据集分布的中心趋势,分散和形状,不包括NaN值
df.head(2)#df的前两行
df.tail(2)#df的后两行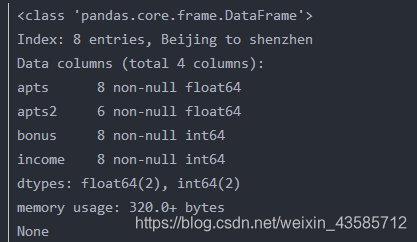
dff=df.fillna(value=0) #df没变,dff是将NaN变成0
dff=df.fillna(value=0, inplace=True)#df改变,dff为None
dffr=df.fillna(method='ffill') #新生成的补NaN前向拷贝,df没变,NaN由前一行的对应元素代替
dfba=df.fillna(method='bfill') #新生成的补NaN后向拷贝,df没变,NaN由后一行的对应元素代替四、层次化的index
层次化索引(hierarchical indexing)是pandas的一个重要的功能,它可以在一个轴上有多个(两个以上)的索引,这就表示着,它能够以低维度形式来表示高维度的数据。
4.1series的层次化索引
建立具有层次化索引的series对象,对层次化索引切片
# Series的层次化索引,索引是一个二维数组,相当于两个索引决定一个值
# 有点类似于DataFrame的行索引和列索引
s = Series(np.arange(1,10),index=[["a","a","a","b","b","c","c","d","d"],
[1,2,3,1,2,3,1,2,3]])
print(s)
'''
a 1 1
2 2
3 3
b 1 4
2 5
c 3 6
1 7
d 2 8
3 9
'''
#显示层次化索引
print(s.index)
'''
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],
labels=[[0, 0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 1, 2, 0, 1, 2]])
'''
#选取第一个索引为a的数据
print(s["a"])
'''
1 1
2 2
3 3
'''
#层次化索引的切片,包括右端的索引
print(s["c":"d"])#等价于s.ix[["c","d"]]
'''
c 3 6
1 7
d 2 8
3 9
'''
具有层次化索引的series对象和dataframe对象的转化
unstack方法,可以将Series变成一个DataFrame
stack方法,可以将DataFrame变成Series,它是unstack的逆运算
print(type(s))
#<class 'pandas.core.series.Series'>
print(type(s.unstack()))
#<class 'pandas.core.frame.DataFrame'>
#数据的类型以及数据的输出结构都变成了DataFrame,对于不存在的位置使用NaN填充
print(s.unstack())
'''
1 2 3
a 1.0 2.0 3.0
b 4.0 5.0 NaN
c 7.0 NaN 6.0
d NaN 8.0 9.0
'''
print(type(s.unstack().stack()))
#<class 'pandas.core.series.Series'>
print(s.unstack().stack())
'''
a 1 1.0
2 2.0
3 3.0
b 1 4.0
2 5.0
c 1 7.0
3 6.0
d 2 8.0
3 9.0
'''
4.2DataFrame的层次化索引
#DataFrame的行和列都是用层次化索引
#也就是四个索引来决定一个值,将一个二维数据变成了一个四维数据
data = DataFrame(np.arange(12).reshape(4,3),
index=[["a","a","b","b"],[1,2,1,2]],
columns=[["A","A","B"],["Z","X","C"]])
print(data)
'''
A B
Z X C
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
'''
#选取列,参数只能选取"A"或"B"
print(data["A"])#等价于data.ix[:,"A"]
'''
Z X
a 1 0 1
2 3 4
b 1 6 7
2 9 10
'''
#选取行
print(data.ix["a"])
'''
A B
Z X C
1 0 1 2
2 3 4 5
'''
4.3重排分级顺序
#对每一个级别设置一个名称
#设置行级别的名称
data.index.names=["row1","row2"]
#设置列级别的名称
data.columns.names=["column1","column2"]
print(data)
'''
column1 A B
column2 Z X C
row1 row2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
'''
#通过swaplevel,调整行的顺序
print(data.swaplevel("row1","row2"))
'''
column1 A B
column2 Z X C
row2 row1
1 a 0 1 2
2 a 3 4 5
1 b 6 7 8
2 b 9 10 11
'''
#对指定级别中的值进行排序
#对级别名称为row2中的值进行排序
print(data.sortlevel(1))#等价于data.swaplevel(0,1).sortlevel(0)
'''
column1 A B
column2 Z X C
row1 row2
a 1 0 1 2
b 1 6 7 8
a 2 3 4 5
b 2 9 10 11
'''
4.4根据级别汇总统计
#指定行级别的名称进行求和
print(data.sum(level="row1"))
'''
column1 A B
column2 Z X C
row1
a 3 5 7
b 15 17 19
'''
#指定列级别的名称进求和
print(data.sum(level="column1",axis=1))
'''
column1 A B
row1 row2
a 1 1 2
2 7 5
b 1 13 8
2 19 11
'''
五、使用pandas 的read_csv、read_table、read_fwf、read_excel读取数据
read_csv/read_table/read_fwf/read_excel的部分参数:
- path:表示位置的字符串。
- sep:分隔符,默认为','。
- header:用作列名的行号,默认为0(第一行),如果没有header行,需设置header=None。
- index_col:用作行索引的列编号或列名,可以是单个名称或数组,也可是由多个名称或数组组成的列表。
- names:用于结果的列名列表,结合header=None使用。
- skiprows:要忽略的行数(从文件开始处算起),或需要跳过(即不忽略)的行号列表(从0开始)。
- na_value:规定什么样的值是NA 值。
- nrows:需要读取的行数。
- thousand:千位符符号,如‘,’或‘.’。
- decimal:小数点符号,默认为‘.’。