目录
第四门课 卷积神经网络(Convolutional Neural Networks)
第四周 特殊应用:人脸识别和神经风格转换(Special applications: Face recognition &Neural style transfer)
4.9 内容代价函数(Content cost function)
风格迁移网络的代价函数有一个内容代价部分,还有一个风格代价部分。
𝐽(𝐺) = 𝛼𝐽content(𝐶, 𝐺) + 𝛽𝐽style(𝑆, 𝐺)
J
(
G
)
=
α
J
c
o
n
t
e
n
t
(
C
,
G
)
+
β
J
s
t
y
l
e
(
S
,
G
)
J(G) = \alpha J_{content}(C,G) + \beta J_{style}(S,G)
J(G)=αJcontent(C,G)+βJstyle(S,G)
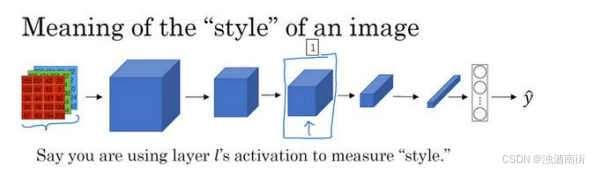
我们先定义内容代价部分,不要忘了这就是我们整个风格迁移网络的代价函数,我们看看内容代价函数应该是什么。
假如说,你用隐含层𝑙来计算内容代价,如果𝑙是个很小的数,比如用隐含层 1,这个代价函数就会使你的生成图片像素上非常接近你的内容图片。然而如果你用很深的层,那么那就会问,内容图片里是否有狗,然后它就会确保生成图片里有一个狗。所以在实际中,这个层𝑙在网络中既不会选的太浅也不会选的太深。因为你要自己做这周结束的编程练习,我会让你获得一些直觉,在编程练习中的具体例子里通常𝑙会选择在网络的中间层,既不太浅也不很深,然后用一个预训练的卷积模型,可以是 VGG 网络或者其他的网络也可以。
现在你需要衡量假如有一个内容图片和一个生成图片他们在内容上的相似度,我们令这个
a
[
l
]
[
C
]
和
a
[
l
]
[
G
]
a^{[l][C]}和a^{[l][G]}
a[l][C]和a[l][G],代表这两个图片𝐶和𝐺的𝑙层的激活函数值。如果这两个激活值相似,那么就意味着两个图片的内容相似。


我们定义这个: J c o n t e n t ( C , G ) = 1 2 ∣ ∣ a [ l ] [ C ] − a [ l ] [ G ] ∣ ∣ 2 J_{content}(C,G) =\frac{1}{2}||a^{[l][C]} − a^{[l][G]}||^2 Jcontent(C,G)=21∣∣a[l][C]−a[l][G]∣∣2,为两个激活值不同或者相似的程度,我们取𝑙层的隐含单元的激活值,按元素相减,内容图片的激活值与生成图片相比较,然后取平方,也可以在前面加上归一化或者不加,比如 1 2 \frac{1}{2} 21或者其他的,都影响不大,因为这都可以由这个超参数 α 来调整( J ( G ) = α J c o n t e n t ( C , G ) + β J s t y l e ( S , G ) J(G) = \alpha J_{content}(C,G) + \beta J_{style}(S,G) J(G)=αJcontent(C,G)+βJstyle(S,G))。
要清楚我这里用的符号都是展成向量形式的,这个就变成了这一项(KaTeX parse error: Expected '}', got 'EOF' at end of input: a^{[l][C]} )减这一项( a [ l ] [ C ] a^{[l][C]} a[l][C])的𝐿2范数的平方,在把他们展成向量后。这就是两个激活值间的差值平方和,这就是两个图片之间𝑙层激活值差值的平方和。后面如果对𝐽(𝐺)做梯度下降来找𝐺的值时,整个代价函数会激励这个算法来找到图像𝐺,使得隐含层的激活值和你内容图像的相似。
这就是如何定义风格迁移网络的内容代价函数,接下来让我们学习风格代价函数。
4.10 风格代价函数(Style cost function)
在上节视频中,我们学习了如何为神经风格迁移定义内容代价函数,这节课我们来了解风格代价函数。那么图片的风格到底是什么意思呢?
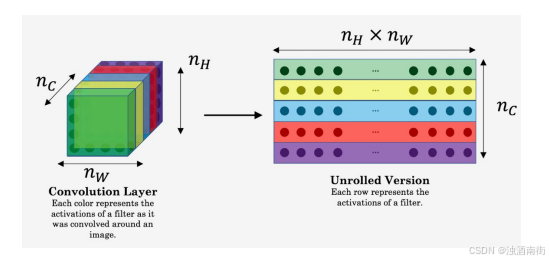
这么说吧,比如你有这样一张图片,你可能已经对这个计算很熟悉了,它能算出这里是否含有不同隐藏层。现在你选择了某一层𝑙(编号 1),比如这一层去为图片的风格定义一个深度测量,现在我们要做的就是将图片的风格定义为𝑙层中各个通道之间激活项的相关系数。
我来详细解释一下,现在你将𝑙层的激活项取出,这是个
n
H
×
n
W
×
n
C
n_H × n_W × n_C
nH×nW×nC的激活项,它是一个三维的数据块。现在问题来了,如何知道这些不同通道之间激活项的相关系数呢?

为了解释这些听起来很含糊不清的词语,现在注意这个激活块,我把它的不同通道渲染成不同的颜色。在这个例子中,假如我们有 5 个通道为了方便讲解,我将它们染成了五种颜色。一般情况下,我们在神经网络中会有许多通道,但这里只用 5 个通道,会更方便我们理解。
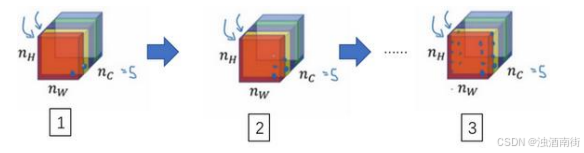
为了能捕捉图片的风格,你需要进行下面这些操作,首先,先看前两个通道,前两个通道(编号 1、2)分别是图中的红色和黄色部分,那我们该如何计算这两个通道间激活项的相关系数呢?

举个例子,在视频的左下角在第一个通道中含有某个激活项,第二个通道也含有某个激活项,于是它们组成了一对数字(编号 1 所示)。然后我们再看看这个激活项块中其他位置的激活项,它们也分别组成了很多对数字(编号 2,3 所示),分别来自第一个通道,也就是红色通道和第二个通道,也就是黄色通道。现在我们得到了很多个数字对,当我们取得这两个
n
H
×
n
W
n_H × n_W
nH×nW的通道中所有的数字对后,现在该如何计算它们的相关系数呢?它是如何决定图片风格的呢?
我们来看一个例子,这是之前视频中的一个可视化例子,它来自一篇论文,作者是Matthew Zeile 和 Rob Fergus 我之前有提到过。我们知道,这个红色的通道(编号 1)对应的是这个神经元,它能找出图片中的特定位置是否含有这些垂直的纹理(编号 3),而第二个通道也就是黄色的通道(编号 2),对应这个神经元(编号 4),它可以粗略地找出橙色的区域。什么时候两个通道拥有高度相关性呢?如果它们有高度相关性,那么这幅图片中出现垂直纹理的地方(编号 2),那么这块地方(编号 4)很大概率是橙色的。如果说它们是不相关的,又是什么意思呢?显然,这意味着图片中有垂直纹理的地方很大概率不是橙色的。而相关系数描述的就是当图片某处出现这种垂直纹理时,该处又同时是橙色的可能性。
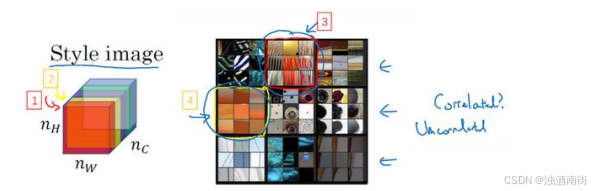
相关系数这个概念为你提供了一种去测量这些不同的特征的方法,比如这些垂直纹理,这些橙色或是其他的特征去测量它们在图片中的各个位置同时出现或不同时出现的频率。
如果我们在通道之间使用相关系数来描述通道的风格,你能做的就是测量你的生成图像中第一个通道(编号 1)是否与第二个通道(编号 2)相关,通过测量,你能得知在生成的图像中垂直纹理和橙色同时出现或者不同时出现的频率,这样你将能够测量生成的图像的风格与输入的风格图像的相似程度。
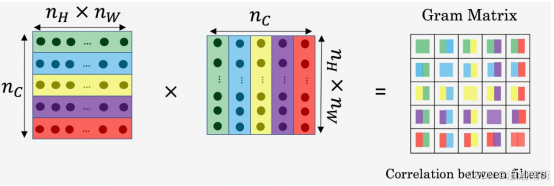
现在我们来证实这种说法,对于这两个图像,也就是风格图像与生成图像,你需要计算一个风格矩阵,说得更具体一点就是用𝑙层来测量风格。
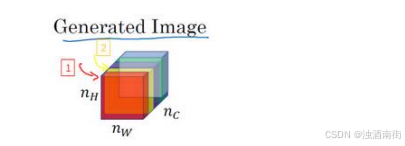
我们设
a
i
,
j
,
k
[
l
]
a_{i,j,k}^{[l]}
ai,j,k[l] ,设它为隐藏层𝑙中(𝑖,𝑗, 𝑘)位置的激活项,𝑖,𝑗,𝑘分别代表该位置的高度、宽度以及对应的通道数。现在你要做的就是去计算一个关于𝑙层和风格图像的矩阵,即
G
[
l
]
(
S
)
G^{[l](S)}
G[l](S)(𝑙表示层数,𝑆表示风格图像),这(
G
[
l
]
(
S
)
G^{[l](S)}
G[l](S))是一个𝑛𝑐 × 𝑛𝑐的矩阵,同样地,我们也对生成的图像进行这个操作。
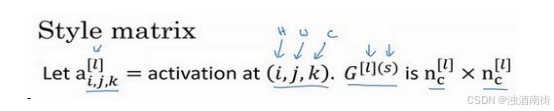
但是现在我们先来定义风格图像,设这个关于𝑙层和风格图像的,𝐺是一个矩阵,这个矩阵的高度和宽度都是𝑙层的通道数。在这个矩阵中𝑘和𝑘′元素被用来描述𝑘通道和𝑘′通道之间的相关系数。具体地:
用符号𝑖,𝑗表示下界,对𝑖,𝑗,𝑘位置的激活项 a i , j , k [ l ] a_{i,j,k}^{[l]} ai,j,k[l],乘以同样位置的激活项,也就是𝑖,𝑗,𝑘′位置的激活项,即 a i , j , k ′ [ l ] a_{i,j,k'}^{[l]} ai,j,k′[l],将它们两个相乘。然后𝑖和𝑗分别加到 l 层的高度和宽度,即 n H [ l ] n_H^{[l]} nH[l]和 n W [ l ] n_W^{[l]} nW[l],将这些不同位置的激活项都加起来。(𝑖,𝑗, 𝑘)和(𝑖,𝑗, 𝑘′)中𝑥坐标和𝑦坐标分别对应高度和宽度,将𝑘通道和𝑘′通道上这些位置的激活项都进行相乘。我一直以来用的这个公式,严格来说,它是一种非标准的互相关函数,因为我们没有减去平均数,而是将它们直接相乘。
这就是输入的风格图像所构成的风格矩阵,然后,我们再对生成图像做同样的操作。

𝑎𝑖, 𝑗, 𝑘𝑙和𝑎𝑖,𝑗,𝑘𝑙中的上标(𝑆)和(𝐺)分别表示在风格图像 S 中的激活项和在生成图像𝐺的激活项。我们之所以用大写字母𝐺来代表这些风格矩阵,是因为在线性代数中这种矩阵有时也叫 Gram 矩阵,但在这里我只把它们叫做风格矩阵。
所以你要做的就是计算出这张图像的风格矩阵,以便能够测量出刚才所说的这些相关系数。更正规地来表示,我们用 a i , j , k [ l ] a_{i,j,k}^{[l]} ai,j,k[l] 来记录相应位置的激活项,也就是𝑙层中的𝑖,𝑗, 𝑘位置,所以𝑖代表高度,𝑗代表宽度,𝑘代表着𝑙中的不同通道。之前说过,我们有 5 个通道,所以𝑘就代表这五个不同的通道。
对于这个风格矩阵,你要做的就是计算这个矩阵也就是 G [ l ] G^{[l]} G[l]矩阵,它是个𝑛𝑐 × 𝑛𝑐的矩阵,也就是一个方阵。记住,因为这里有 n c n_c nc个通道,所以矩阵的大小是𝑛𝑐 × 𝑛𝑐。以便计算每一对激活项的相关系数,所以 G k k ′ [ l ] G_{kk′}^{[l]} Gkk′[l] 可以用来测量𝑘通道与𝑘′通道中的激活项之间的相关系数,𝑘和𝑘′会在 1 到𝑛𝑐之间取值,𝑛𝑐就是𝑙层中通道的总数量。
当在计算𝐺[𝑙]时,我写下的这个符号(下标𝑘𝑘’)只代表一种元素,所以我要在右下角标明是𝑘𝑘′元素,和之前一样𝑖,𝑗从一开始往上加,对应(𝑖,𝑗, 𝑘)位置的激活项与对应(𝑖,𝑗, 𝑘′)位置的激活项相乘。记住,这个𝑖和𝑗是激活块中对应位置的坐标,也就是该激活项所在的高和宽,所以𝑖会从 1 加到
n
H
[
l
]
n_H^{[l]}
nH[l],𝑗会从 1 加到
n
W
[
l
]
n_W^{[l]}
nW[l],𝑘和𝑘′则表示对应的通道,所以𝑘和𝑘′值的范围是从1 开始到这个神经网络中该层的通道数量
n
c
[
l
]
n_c^{[l]}
nc[l]。这个式子就是把图中各个高度和宽度的激活项都遍历一遍,并将𝑘和𝑘′通道中对应位置的激活项都进行相乘,这就是
G
k
k
′
[
l
]
G_{kk'}^{[l]}
Gkk′[l]的定义。通过对𝑘和𝑘′通道中所有的数值进行计算就得到了𝐺矩阵,也就是风格矩阵。
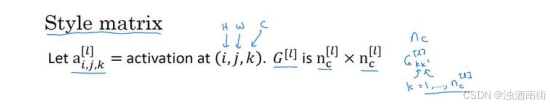
G
k
k
′
[
l
]
=
∑
i
=
1
n
H
[
l
]
∑
j
=
1
n
W
[
l
]
a
i
,
j
,
k
[
l
]
a
i
,
j
,
k
′
[
l
]
G_{kk'}^{[l]} = \sum_{i=1}^{n_H^{[l]}}\sum_{j=1}^{n_W^{[l]}}{a_{i,j,k}^{[l]} a_{i,j,k'}^{[l]}}
Gkk′[l]=i=1∑nH[l]j=1∑nW[l]ai,j,k[l]ai,j,k′[l]
要注意,如果两个通道中的激活项数值都很大,那么𝐺𝑘𝑘′[𝑙] 也会变得很大,对应地,如果他们不相关那么𝐺𝑘𝑘′[𝑙] 就会很小。严格来讲,我一直使用这个公式来表达直觉想法,但它其实是一种非标准的互协方差,因为我们并没有减去均值而只是把这些元素直接相乘,这就是计算图像风格的方法。
G
k
k
′
[
l
]
(
S
)
=
∑
i
=
1
n
H
[
l
]
∑
j
=
1
n
W
[
l
]
a
i
,
j
,
k
[
l
]
(
S
)
a
i
,
j
,
k
′
[
l
]
(
S
)
G_{kk'}^{[l](S)} = \sum_{i=1}^{n_H^{[l]}}\sum_{j=1}^{n_W^{[l]}}{a_{i,j,k}^{[l](S)} a_{i,j,k'}^{[l](S)}}
Gkk′[l](S)=i=1∑nH[l]j=1∑nW[l]ai,j,k[l](S)ai,j,k′[l](S)
你要同时对风格图像𝑆和生成图像𝐺都进行这个运算,为了区分它们,我们在它的右上角加一个(𝑆),表明它是风格图像𝑆,这些都是风格图像 S 中的激活项,之后你需要对生成图像也做相同的运算。
G
k
k
′
[
l
]
(
G
)
=
∑
i
=
1
n
H
[
l
]
∑
j
=
1
n
W
[
l
]
a
i
,
j
,
k
[
l
]
(
G
)
a
i
,
j
,
k
′
[
l
]
(
G
)
G_{kk'}^{[l](G)} = \sum_{i=1}^{n_H^{[l]}}\sum_{j=1}^{n_W^{[l]}}{a_{i,j,k}^{[l](G)} a_{i,j,k'}^{[l](G)}}
Gkk′[l](G)=i=1∑nH[l]j=1∑nW[l]ai,j,k[l](G)ai,j,k′[l](G)
和之前一样,再把公式都写一遍,把这些都加起来,为了区分它是生成图像,在这里放一个(𝐺)。
现在,我们有 2 个矩阵,分别从风格图像𝑆和生成图像𝐺。
再提醒一下,我们一直使用大写字母𝐺来表示矩阵,是因为在线性代数中,这种矩阵被称为 Gram 矩阵,但在本视频中我把它叫做风格矩阵,我们取了 Gram 矩阵的首字母𝐺来表示这些风格矩阵。(过程见下图)
最后,如果我们将𝑆和𝐺代入到风格代价函数中去计算,这将得到这两个矩阵之间的误差,因为它们是矩阵,所以在这里加一个𝐹(Frobenius 范数,编号 1 所示),这实际上是计算两个矩阵对应元素相减的平方的和,我们把这个式子展开,从𝑘和𝑘′开始作它们的差,把对应的式子写下来,然后把得到的结果都加起来,作者在这里使用了一个归一化常数,也就是
1
2
n
H
[
l
]
n
W
[
l
]
n
C
[
l
]
\frac{1}{2n_H^{[l]}n_W^{[l]}n_C^{[l]}}
2nH[l]nW[l]nC[l]1,再在外面加一个平方,但是一般情况下你不用写这么多,一般我们只要将它乘以一个超参数𝛽就行。


最后,这是对𝑙层定义的风格代价函数,和之前你见到的一样,这是两个矩阵间一个基本的 Frobenius 范数,也就是𝑆图像和𝐺图像之间的范数再乘上一个归一化常数,不过这不是很重要。实际上,如果你对各层都使用风格代价函数,会让结果变得更好。如果要对各层都使用风格代价函数,你可以这么定义代价函数,把各个层的结果(各层的风格代价函数)都加起来,这样就能定义它们全体了。我们还需要对每个层定义权重,也就是一些额外的超参数,我们用 λ [ l ] \lambda^{[l]} λ[l]来表示,这样将使你能够在神经网络中使用不同的层,包括之前的一些可以测量类似边缘这样的低级特征的层,以及之后的一些能测量高级特征的层,使得我们的神经网络在计算风格时能够同时考虑到这些低级和高级特征的相关系数。这样,在基础的训练中你在定义超参数时,可以尽可能的得到更合理的选择。
为了把这些东西封装起来,你现在可以定义一个全体代价函数:
J ( G ) = α J c o n t e n t ( C , G ) + β J s t y l e ( S , G ) J(G) = \alpha J_{content}(C,G) + \beta J_{style}(S,G) J(G)=αJcontent(C,G)+βJstyle(S,G)
之后用梯度下降法,或者更复杂的优化算法来找到一个合适的图像𝐺,并计算𝐽(𝐺)的最小值,这样的话,你将能够得到非常好看的结果,你将能够得到非常漂亮的结果。
这节神经风格迁移的内容就讲到这里,希望你能愉快地在本周的基础训练中进行实践。在本周结束之前,还有最后一节内容想告诉你们,就是如何对 1D 和 3D 的数据进行卷积,之前我们处理的都是 2D 图片,我们下节视频再见。